简介
Reactor响应式编程(Reactive Programming):
Reactor is a fully non-blocking reactive programming foundation for the JVM, with efficient demand management (in the form of managing “backpressure”). It integrates directly with the Java 8 functional APIs, notably CompletableFuture, Stream, and Duration. It offers composable asynchronous sequence APIs — Flux (for [N] elements) and Mono (for [0|1] elements) — and extensively implements the Reactive Streams specification.
翻译一下就是:Reactor是JVM的一个完全无阻塞的响应式编程基础,具有高效的需求管理(以管理“背压”的形式)。它直接与Java 8功能api集成,尤其是CompletableFuture、Stream和Duration。它提供了可组合的异步序列api——Flux(用于[N]元素)和Mono(用于[0|1]元素)——并且广泛地实现了反应流规范。
背景
我们服务端的项目大多采用了Spring WebFlux,reactor是 Spring WebFlux 的首选反应库,WebFlux 需要 Reactor 作为核心依赖项。Reactor 存在一定的学习成本,在开发中我们遇到了些bug,相当一部分是因为我们不够了解 reactor ,踩了很多坑。所以在本文档中我们主要针对的是一些学习过程容易让新人感到迷茫的知识点(map、flatMap、异步、并发),期望能让新人更好上手 Spring WebFlux。
Mono
Mono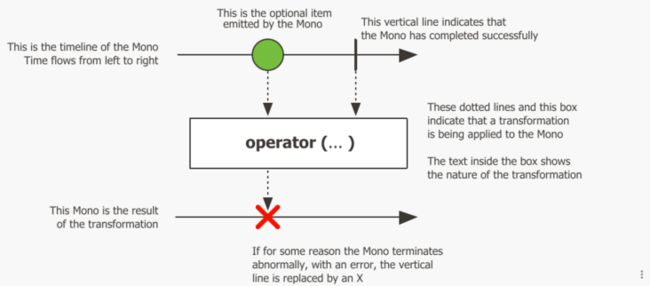
Flux
Flux
map 、flatMap 以及 flatMapSequential 区别:
方法签名
//Map 的方法签名
Flux map(Function mapper)
//FlatMap的方法签名
Flux flatMap(Function> mapper) map:通过对每个元素应用同步函数来转换此Flux发出的元素, 并且是一对一的转换流元素。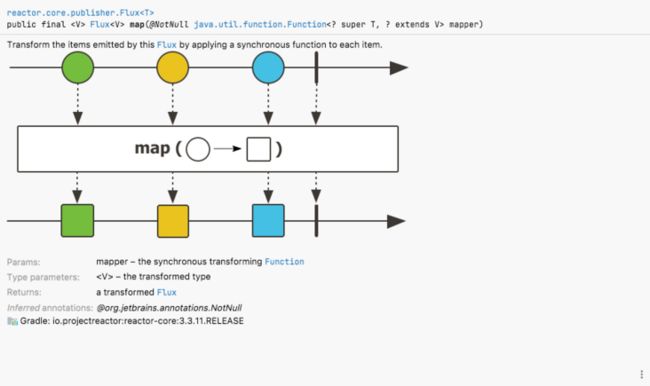
flatMap: 将此Flux发出的元素异步转换为 Publisher,然后通过合并将这些内部发布者扁平化为单个Flux 。Flux可能包含N个元素,所以flatMap是一对多的转换。将各个 publisher 合并的过程不会保持 源Flux发布 的顺序,可能出现交错。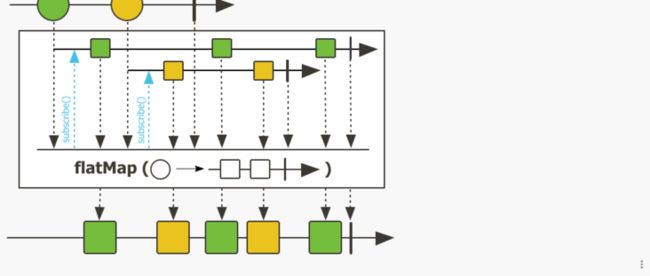
flatMapSequential: 将此Flux发出的元素异步转换为 Publisher,然后通过合并将这些内部发布者扁平化为单个Flux 。于 flatMap 不同的是 flatMapSequential 在合并 publisher 时会 按源元素的顺序合并它们。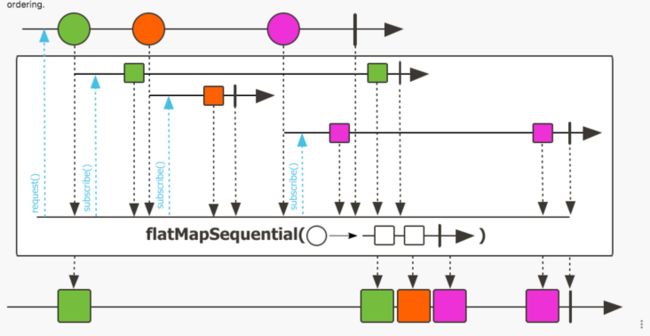
map是一个同步运算符,它只是一种将一个值转换为另一个值的方法。
flatMap可以是同步的,也可以是异步的,这取决于flatMap中调用的方法是否使用。
示例1:
void demo() {
//1. Flux.interval 按时生产Long的无限流
final Flux flux = Flux.interval(Duration.of(100, ChronoUnit.MILLIS))
.map(log()) //2. 调用方法log,订阅后log()会在当前线程执行
.flatMap(logOfFlux()); //3. 通过flatMap调用 log(), 会在当前线程执行
//完成flux的定义,调用subscribe后才会真正开始执行
flux.subscribe();
}
Function log() {
return aLong -> {
log.info("num is {}", aLong);
return aLong;
};
}
Function> logOfFlux() {
return aLong -> {
log.info("num is {}", aLong);
return Flux.just(aLong);
};
} 在我们的示例代码中,该 flatMap 操作是同步的,因为我们使用Flux.just()方法发出元素。下面我们会介绍如何在 flatMap 中实现异步操作。
上边代码中讲到了 Publisher 调用 subscribe 后才会真正开始执行,但是 subscribe 中的代码并不一定会执行。
当 Mono 是空序列时 :
void monoOfEmpty() {
Mono.empty()
.map(m -> func())
.subscribe(message -> {
responseObserver.onNext(message);
responseObserver.onCompleted();
);
}会有同学喜欢在 subscribe 中处理响应(例如rpc),但这个场景中responseObserver.onCompleted() 不会被执行。
正确的做法应该是:
void monoOfEmpty() {
Mono.empty()
.map(m -> func())
.doOnSuccess(message -> responseObserver.onCompleted())
.subscribe(responseObserver::onNext);
}异步与多线程
Reactor被视为与并发无关的。也就是说,获得Flux或Mono并不一定意味着它在专用线程中运行。 取而代之的是,大多数Operator会继续在执行前一个Operator的线程中工作。除非指定,否则最顶层的Operator(源)本身运行在进行subscribe()调用的线程上。
先分享一个案例:
在 Growing 查询服务 olap 中由于使用错误的操作符带来性能问题
现象:在查看某些看板时,响应时间会超时(一分钟)。
经过分析发现这些看板中的单图查询时间段包含“今天”,由于需要保证实时数据,olap在处理包含“今天”的查询时不会生成缓存;通过日志发现olap在查询clickhouse时一直都是一个线程在提交。
对应代码:
//queries sql List
Flux.fromArray(queries.values())
//需要使用flatMapSequential 保证Flux订阅时返回的顺序
.flatMapSequential(query -> {
//执行sql
return executor.getFromCacheOrExecute(...);
});
})
Mono getFromCacheOrExecute() {
return existsCache(hashing)
.flatMap(exists-> {
if(exists) {
//查询缓存
}else{
//查询clickhouse
return writeCache(hashing, doExecute(...))
}
});
}
//查询缓存
public Mono existsKey(String key) {
return stringRedisTemplate.hasKey(key);
}
//提交查询至clickhouse
Mono doExecute(...) {
return Mono.fromCallable(() -> execute(...));
} 代码中没有使用subscriptOn或者publishOn操作符,stringRedisTemplate.hasKey(key) 会使后续的操作符都在 lettuce-1 线程中执行 并且整个流的执行都是串行的,我们需要将查询过程改为异步查询,多个sql 可以并发查询。下面就介绍实现异步并发的一些方法,及GrowingIO应用于这个场景的选择。
Reactor提供了两种在流中切换执行上下文(或Scheduler)的方式:
我们可以通过这两种方式达到异步执行的目的
publishOn : 此运算符影响线程上下文,它下面的链中的其余运算符将在其中执行,直到新出现的publishOn。
void demo() {
final Flux flux = Flux.interval(Duration.of(100, ChronoUnit.MILLIS))
.map(log())//1
.publishOn(Schedulers.parallel())//2
.map(log())//3
.publishOn(Schedulers.elastic())//4
.flatMap(logOfMono());//5
flux.subscribe();
}
- 会在调用flux.subscribe()的线程上执行
引用- 指定后续的运算符执行的上下文
引用- 会在parallel线程上执行
引用- 指定后续的运算符执行的上下文
引用- 会在elastic线程上执行
subscribeOn :整个流在指定的Scheduler的Scheduler.Worker上运行 ,直至出现publishOn ,publishOn后续的操作符由 publishOn 决定执行上下文。
void demo() {
final Flux flux = Flux.interval(Duration.of(100, ChronoUnit.MILLIS))
.map(log())//1
.publishOn(Schedulers.parallel())
.map(log())//2
.subscribeOn(Schedulers.elastic())
.flatMap(logOfMono());
flux.subscribe();
}
- 会在elastic线程执行
引用- 会在parallel线程上执行,publishOn会“覆盖”subscribeOn的行为
这样我们就可以异步的去执行方法了。这里有一个误区,刚接触reactor的小伙伴会误认为Flux中多个元素经过log()或者 logOfMono() 会分别打印在不同线程上
Flux依次发出了1,2,3三个元素
无论是subscribeOn、还是publishOn,经过flatMap 都会在 parallel-1 线程上执行,也就是说Flux中的所有元素只是从主线程发出,在另一个线程中执行。
在调用一些阻塞方法时(rpc、redis、io),我们期望每个元素经过 flatMap 中时可以运行在不同线程上(串行-> 并发),应该怎么做?
将Flux转为ParallelFlux,使用runOn来指明需要的线程池
要获得ParallelFlux,可以在Flux 上使用parallel()运算符。
为了告诉ParallelFlux在哪里运行每个元素,必须使用runOn(Scheduler)。如果并行处理后,您想恢复到“正常”状态 Flux并以顺序方式应用运算符链的其余部分,可以使用sequential()
void demo() {
final Flux flux = Flux.fromIterable(Lists.newArrayList(3L, 1L, 2L))
.parallel().runOn(Schedulers.elastic())
.flatMap(logOfMono())
.sequential();
flux.subscribe();
} - fluxMap中调用的方法需要在内部通过publishOn表明执行上下文。
void demo() {
Flux.fromIterable(Lists.newArrayList(3L, 1L, 2L))
.flatMap(this::blockFunction)
.subscribe();
}
//通过publishOn 来表明 blockFunction() 的上下文
Mono blockFunctionAsync(Long i) {
return Mono.just(i).publishOn(Schedulers.elastic()).flatMap(this::blockFunction);
}
Mono blockFunction(Long i) {
Thread.sleep(i * 1000);
return Mono.just(i);
} - 使用 Mono.fromFuture() 创建流
Mono.fromFuture(CompletableFuture.supplyAsync(() -> blockFunction()));Mono.fromFuture() 创建一个Mono ,使用提供的 CompletableFuture 产生它的值。
CompletableFuture.supplyAsync() 返回一个 CompletableFuture,它将在ForkJoinPool.commonPool() 上运行任务,异步完成。
ForkJoinPool一个全局线程池,主要应用于计算密集型的场景。
- 使用Mono.create() 、Flux.create() 方法创建流
//自定义线程池
final Executor executor = new ThreadPoolExecutor(...);
//创建Mono、Flux时 指明上下文
Mono.create(sink -> executor.execute(() -> {
sink.success(blockFunction());
}));目前我们推荐使用 这种方法来创建Mono、Flux来实现异步
这样做的好处:
Reactor对新手来说有一定理解成本,在调用一个返回值为 Publisher 的类型的方法时,不点进去无法知道这是同步方法还是异步方法,避免对于调用者造成的心智负担。
更方便得使用自定义线程池
我们针对 olap 查询业务场景 采取合适的方法:
方法一 : ParallelFlux 不能保证sql返回顺序,不满足该业务场景。
方法二: Reactor对新手来说有一定理解成本,在调用一个返回值为 Publisher 的类型的方法时,不点进去无法知道这是同步方法还是异步方法,对于调用者存在心智负担。
方法三:无法指定自定义线程池
我们采用了第4种方式来实现异步。
reactor提供的线程池
- 当前线程执行(Schedulers.immediate()): 在处理时,将直接执行提交的Runnable,从而在当前线程上有效地运行它们(可以视为“空对象”或无操作调度程序)。
- 单个可重用线程(Schedulers.single())。请注意,此方法对所有调用方都使用相同的线程,直到调度程序被释放为止。如果需要每次调用一个专用线程,请对每个调用使用Schedulers.newSingle()。
- 无限制的弹性线程池(Schedulers.elastic())。它根据需要创建新的工作池并重用空闲的工作池,随着Flux中元素的增多,会无限制创建线程去执行,存在安全隐患,不推荐使用。
- 有界弹性线程池(Schedulers.boundedElastic())。根据需要创建新的工作池并重用空闲的工作池。闲置时间过长(默认值为60s)的工作池也将被丢弃。与elastic()有所不同,它对可以创建的线程数进行限制(默认为CPU核心数x 10)。达到上限后,最多可再提交10万个任务,并在有线程可用时重新调度(当任务被设置延迟执行时,延迟计时是在线程可用时开始)。这是I/O阻塞任务的更好选择。Schedulers.boundedElastic()是一种为阻塞处理提供自己的线程的简便方法,这样它就不会占用其他资源。缺点是这个线程池是全局的,假设有两个阻塞方法 getFiles、getData ,期望分别使用不同线程池去方便管理,就不适合用 boundedElastic 了。
- 为并行工作而调整的固定工作线程池(Schedulers.parallel())。它创建的工作线程数量与CPU内核数量一样多。
处理错误
在响应式流中,错误(error)是终止(terminal)事件。当有错误发生时,它会导致流序列停止, 并且错误信号会沿着操作链条向下传递,直至遇到定义的 Subscriber 及其 onError 方法。
在 try-catch 代码块中处理异常的几种方法。常见的包括如下几种:
- 捕获并返回一个静态的缺省值。
- 捕获并执行一个异常处理方法。
- 捕获并动态计算一个候补值来顶替。
- 捕获,并再包装为某一个 业务相关的异常,然后再抛出业务异常。
- 捕获,记录错误日志,然后继续抛出。
- 使用 finally 来清理资源
以上所有这些在 Reactor 都有等效的 操作符处理方式。
与第 (1) 条(捕获并返回一个静态的缺省值)对应的是 onErrorReturn:
Flux.just(10)
.flatMap(this::function)
.onErrorReturn("Error");//返回一个静态的缺省值根据错误类型返回对应值
Flux.just(10)
.flatMap(this::function)
.onErrorReturn(e -> e.getMessage().equals("boom-1"), "Error-1");与第 (2、3、4) 条(捕获并执行一个异常处理方法)对应的是 onErrorResume
Flux.just(10)
.flatMap(m -> function(k).onErrorResume(e -> handleErr(k)));
Flux.just(10)
.flatMap(m -> function(k).onErrorResume(e -> errFunc(k)));
Flux.just(10)
.flatMap(m -> function(k)
.onErrorResume(e -> Flux.error(new Exception(k)))
);对应第 (5) 条(捕获,记录错误日志,并继续抛出)
Flux.just(10)
.flatMap(k -> function(k))
.doOnError(e ->
log.error(e.getLocalizedMessage(), e);
});对应(6)doFinally 在序列终止(无论是 onComplete、onError还是取消)的时候被执行, 并且能够判断是什么类型的终止事件
Flux.just(10)
.doFinally(type -> {
if (type == SignalType.CANCEL){
log.info("a log");
}
})我需要哪个运算符
官方文档
A.1. 创建一个新序列
发出一个 T ,当已经有值(不需要再去IO): just
基于一个 Optional
基于一个可能为 null 的 T:Mono.justOrEmpty(T)
发出一个 T ,且还是由 just 返回
但是需要 “懒”创建的:使用 Mono.fromSupplier 或用 defer 包装 just
//会起到延迟执行的作用,在订阅时才去执行 func()
Mono.defer(()-> Mono.just(func()));
发出许多 T,这些元素我可以明确列举出来:Flux.just(T...)
基于迭代数据结构:
一个数组:Flux.fromArray
一个集合或 iterable:Flux.fromIterable
一个 Integer 的 range:Flux.range
一个 Stream 提供给每一个订阅:Flux.fromStream(Supplier
基于一个参数值给出的源:
一个 Supplier
一个任务:Mono.fromCallable,Mono.fromRunnable
一个 CompletableFuture
直接完成:empty
立即生成错误: error
但是“懒”创建的方式生成 Throwable.error(Supplier
什么都不做:never
依赖一个可回收的资源:using
可编程地生成事件(可以使用状态):
同步且逐个的:Flux.generate
异步(也可同步)的,每次尽可能多发出元素:Flux.create (Mono#create 也是异步的,只不过只能发一个)
A.2. 对现有序列进行转化
我想转化一个序列:
1对1地转化(比如字符串转化为它的长度): map
类型转化:cast
为了获得每个元素的序号:Flux.index
1对n地转化(如字符串转化为一串字符):flatMap + 使用一个工厂方法
1对n地转化可自定义转化方法和/或状态:handle
对每一个元素执行一个异步操作(如对 url 执行 http 请求): flatMap+ 一个异步的返回类型为 Publisher的方法
忽略一些数据:在 flatMap lambda 中根据条件返回一个 Mono.empty()
保留原来的序列顺序:Flux.flatMapSequential(对每个元素的异步任务会立即执行,但会将结果按照原序列顺序排序)
当 Mono 元素的异步任务会返回多个元素的序列时:Mono.flatMapMany
我想添加一些数据元素到一个现有的序列:
在开头添加:Flux#startWith(T...)
在最后添加:Flux#concatWith(T...)
我想将 Flux转化为集合(一下都是针对 Flux的)
转化为 List:collectList,collectSortedList
转化为 Map:collectMap,collectMultiMap
转化为自定义集合:collect
计数:count
reduce 算法(将上个元素的reduce结果与当前元素值作为输入执行reduce方法,如sum) reduce
将每次 reduce 的结果立即发出:scan
转化为一个 boolean 值:
对所有元素判断都为true:all
对至少一个元素判断为true:any
判断序列是否有元素(不为空):hasElements
判断序列中是否有匹配的元素:hasElement
我想合并 publishers…
按序连接: Flux.concat 或者 concatWith(other)
即使有错误,也会等所有的 publishers 连接完成:Flux.concatDelayError
按订阅顺序连接(这里的合并仍然可以理解成序列的连接):Flux.mergeSequential
按元素发出的顺序合并(无论哪个序列的,元素先到先合并): Flux.merge 或者 Flux.mergeWith(other)
元素类型会发生变化:Flux.zip / Flux.zipWith
将元素组合:
2个 Mono 组成1个 Tuple2:Mono.zipWith
n个 Monos 的元素都发出来后组成一个 Tuple:Mono#zip
在终止信号出现时“采取行动”:
在 Mono 终止时转换为一个 Mono
当 n 个 Mono 都终止时返回 Mono
返回一个存放组合数据的类型,对于被合并的多个序列:
每个序列都发出一个元素时:Flux.zip
任何一个序列发出元素时:Flux.combineLatest
只取各个序列的第一个元素:Flux#first,Mono#first,mono.or (otherMono).or(thirdMono),`flux.or(otherFlux).or(thirdFlux)
由一个序列触发(类似于 flatMap,不过“喜新厌旧”):switchMap
由每个新序列开始时触发(也是“喜新厌旧”风格):switchOnNext
我想重复一个序列: repeat
以一定的间隔重复:Flux.interval(duration).flatMap(tick -> myExistingPublisher)
我有一个空序列,但是…
我想要一个缺省值来代替:defaultIfEmpty
我想要一个缺省的序列来代替:switchIfEmpty
我有一个序列,但是我对序列的元素值不感兴趣: ignoreElements
…并且我希望用 Mono 来表示序列已经结束:then
…并且我想在序列结束后等待另一个任务完成:thenEmpty
…并且我想在序列结束之后返回一个 Mono:Mono#then(mono)
…并且我想在序列结束之后返回一个值:Mono#thenReturn(T)
…并且我想在序列结束之后返回一个 Flux:thenMany
我有一个 Mono 但我想延迟完成…
…当有1个或N个其他 publishers 都发出(或结束)时才完成: Mono.delayUntilOther
…使用一个函数式来定义如何获取“其他 publisher”:Mono.delayUntil(Function)
我想基于一个递归的生成序列的规则扩展每一个元素,然后合并为一个序列发出:
…广度优先:expand(Function)
…深度优先:expandDeep(Function)
A.3. “窥视”(只读)序列
在不对序列造成改变的情况下,我想:
得到通知或执行一些操作:
发出元素:doOnNext
序列完成:Flux#doOnComplete,Mono#doOnSuccess
因错误终止:doOnError
取消:doOnCancel
订阅时:doOnSubscribe
请求时:doOnRequest
完成或错误终止: doOnTerminate(Mono的方法可能包含有结果)
但是在终止信号向下游传递 之后 :doAfterTerminate
所有类型的信号(Signal):Flux.doOnEach
所有结束的情况(完成complete、错误error、取消cancel):doFinally
记录日志:log
我想知道所有的事件:
每一个事件都体现为一个 single 对象:
执行 callback:doOnEach
每个元素转化为 single对象: materialize
…在转化回元素:dematerialize
转化为一行日志:log
A.4. 过滤序列
我想过滤一个序列
基于给定的判断条件: filter
…异步地进行判断:filterWhen
仅限于指定类型的对象:ofType
忽略所有元素:ignoreElements
去重:
对于整个序列:Flux#distinct
去掉连续重复的元素:Flux#distinctUntilChanged
我只想要一部分序列:
只要 N 个元素:
从序列的第一个元素开始算: Flux.take(long)
…取一段时间内发出的元素:Flux.take(Duration)
…只取第一个元素放到 Mono 中返回:Flux.next()
…使用 request(N) 而不是取消:Flux.limitRequest(long)
从序列的最后一个元素倒数:Flux.takeLast
直到满足某个条件(包含):Flux.takeUntil(基于判断条件),Flux#takeUntilOther(基于对 publisher 的比较)
直到满足某个条件(不包含):Flux.takeWhile
最多只取 1 个元素:
给定序号:Flux.elementAt
最后一个: .takeLast(1)
…如果为序列空则发出错误信号:Flux.last()
…如果序列为空则返回默认值:Flux.last(T)
跳过一些元素:
从序列的第一个元素开始跳过: Flux.skip(long)
…跳过一段时间内发出的元素:Flux.skip(Duration)
跳过最后的 n 个元素:Flux.skipLast
直到满足某个条件(包含):Flux.skipUntil(基于判断条件),Flux.skipUntilOther (基于对 publisher 的比较)
直到满足某个条件(不包含):Flux.skipWhile
采样:
给定采样周期: Flux.sample(Duration)
取采样周期里的第一个元素而不是最后一个:sampleFirst
基于另一个 publisher:Flux.sample(Publisher)
基于 publisher“超时”:Flux.sampleTimeout (每一个元素会触发一个 publisher,如果这个 publisher 不被下一个元素触发的 publisher 覆盖就发出这个元素)
我只想要一个元素(如果多于一个就返回错误)…
如果序列为空,发出错误信号:Flux.single()
如果序列为空,发出一个缺省值:Flux.single(T)
如果序列为空就返回一个空序列:Flux.singleOrEmpty
A.5. 错误处理
我想创建一个错误序列: error
…替换一个完成的 Flux:.concat(Flux.error(e))
…替换一个完成的 Mono:.then(Mono.error(e))
…如果元素超时未发出:timeout
…“懒”创建:error(Supplier
我想要类似 try/catch 的表达方式:
抛出异常:error
捕获异常:
然后返回缺省值:onErrorReturn
然后返回一个 Flux 或 Mono:onErrorResume
包装异常后再抛出:.onErrorMap(t -> new RuntimeException(t))
finally 代码块:doFinally
Java 7 之后的 try-with-resources 写法:using 工厂方法
我想从错误中恢复…
返回一个缺省的:
的值:onErrorReturn
Publisher:Flux.onErrorResume 和 Mono.onErrorResume
重试: retry
…由一个用于伴随 Flux 触发:retryWhen
我想处理背压错误(向上游发出“MAX”的 request,如果下游的 request 比较少,则应用策略)…
抛出 IllegalStateException:Flux#onBackpressureError
丢弃策略: Flux.onBackpressureDrop
…但是不丢弃最后一个元素:Flux.onBackpressureLatest
缓存策略(有限或无限): Flux.onBackpressureBuffer
…当有限的缓存空间用满则应用给定策略:Flux.onBackpressureBuffer 带有策略 BufferOverflowStrategy
A.6. 基于时间的操作
我想将元素转换为带有时间信息的 Tuple2
从订阅时开始:elapsed
记录时间戳:timestamp
如果元素间延迟过长则中止序列:timeout
以固定的周期发出元素:Flux.interval
在一定的延迟后发出 0:static Mono.delay
我想引入延迟:
对每一个元素:Mono.delayElement,Flux.delayElements
延迟订阅:delaySubscription
A.7. 拆分 Flux
我想将一个 Flux
以个数为界: window(int)
…会出现重叠或丢弃的情况:window(int, int)
以时间为界: window(Duration)
…会出现重叠或丢弃的情况:window(Duration, Duration)
以个数或时间为界:windowTimeout(int, Duration)
基于对元素的判断条件: windowUntil
…触发判断条件的元素会分到下一波(cutBefore 变量):.windowUntil(predicate, true)
…满足条件的元素在一波,直到不满足条件的元素发出开始下一波:windowWhile (不满足条件的元素会被丢弃)
通过另一个 Publisher 的每一个 onNext 信号来拆分序列:window(Publisher),windowWhen
我想将一个 Flux
拆分为一个一个的 List:
以个数为界: buffer(int)
…会出现重叠或丢弃的情况:buffer(int, int)
以时间为界: buffer(Duration)
…会出现重叠或丢弃的情况:buffer(Duration, Duration)
以个数或时间为界:bufferTimeout(int, Duration)
基于对元素的判断条件: bufferUntil(Predicate)
…触发判断条件的元素会分到下一个buffer:.bufferUntil(predicate, true)
…满足条件的元素在一个buffer,直到不满足条件的元素发出开始下一buffer:bufferWhile(Predicate)
通过另一个 Publisher 的每一个 onNext 信号来拆分序列:buffer(Publisher),bufferWhen
拆分到指定类型的 "collection":buffer(int, Supplier
我想将 Flux
A.8. 回到同步的世界
我有一个 Flux
在拿到第一个元素前阻塞: Flux.blockFirst
…并给出超时时限:Flux.blockFirst(Duration)
在拿到最后一个元素前阻塞(如果序列为空则返回 null): Flux#blockLast
…并给出超时时限:Flux.blockLast(Duration)
同步地转换为 Iterable
同步地转换为 Java 8 Stream
我有一个 Mono
在拿到元素前阻塞: Mono.block
…并给出超时时限:Mono#block(Duration)
转换为 CompletableFuture