1. 线程的概念
1.1 Manager_进程通信
# ### Manager ( list 列表 , dict 字典 ) 进程之间共享数据
from multiprocessing import Process , Manager ,Lock
def mywork(data,lock):
# 共享字典
"""
lock.acquire()
data["count"] -= 10
lock.release()
"""
# 共享列表
data[0] += 1
if __name__ == "__main__":
lst = []
m = Manager()
lock = Lock()
# 多进程中的共享字典
# data = m.dict( {"count":5000} )
# print(data , type(data) )
# 多进程中的共享列表
data = m.list( [100,200,300] )
# print(data , type(data) )
""""""
# 进程数超过1000,处理该数据,死机(谨慎操作)
for i in range(10):
p = Process(target=mywork,args=(data,lock))
p.start()
lst.append(p)
# 必须等待子进程所有计算完毕之后,再去打印该字典,否则报错;
for i in lst:
i.join()
print(data)
1.2 线程的概念
线程概念:
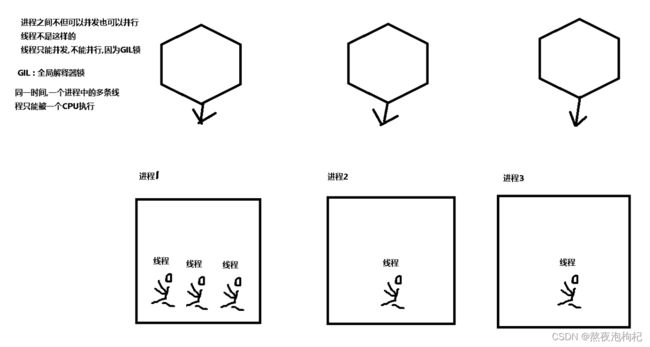
#进程是资源分配的最小单位 #线程是计算机中调度的最小单位 #线程的缘起 资源分配需要分配内存空间,分配cpu: 分配的内存空间存放着临时要处理的数据等,比如要执行的代码,数据 而这些内存空间是有限的,不能无限分配 目前配置高的主机,5万个并发已是上限.线程概念应用而生. #线程的特点 线程是比较轻量级,能干更多的活,一个进程中的所有线程资源是共享的. 一个进程至少有一个线程在工作
线程的缺陷:
#python中的线程可以并发,但是不能并行(同一个进程下的多个线程不能分开被多个cpu同时执行)
#原因:
全局解释器锁(Cpython解释器特有) GIL锁:
同一时间,一个进程下的多个线程只能被一个cpu执行,不能实现线程的并行操作
python是解释型语言,执行一句编译一句,而不是一次性全部编译成功,不能提前规划,都是临时调度
容易造成cpu执行调度异常.所以加了一把锁叫GIL
#想要并行的解决办法:
(1)用多进程间接实现线程的并行
(2)换一个Pypy,Jpython解释器
#程序分为计算密集型和io密集型
对于计算密集型程序会过度依赖cpu,但网页,爬虫,OA办公,这种io密集型的程序里,python绰绰有余
小结:
进程中的线程,同一时间只能有一个cup(单核来回切换进行处理线程)来执行,单核之间可以进程切换 工作,以避免一个单核持续工作,过热导致频率降低。(java可以在同一时间进行多核操作,也就是同步操作) 线程是执行调度的最小单位 一个进程包含多个线程,一个进程至少一个线程 线程在一个进程当中可以共享一份资源 线程的缺陷:不能并行(java可以) 一个程序,至少一个主进程和一个主线程
2. 线程的基本使用
# ### 线程
"""
进程是资源分配的最小单元
线程是cpu执行调度的最小单元
"""
# (1) 一个进程里包含了多个线程,线程之间是异步并发
from threading import Thread
from multiprocessing import Process
import os , time , random
"""
def func(i):
time.sleep(random.uniform(0.1,0.9))
print("当前进程号:{}".format(os.getpid()) , i)
if __name__ == "__main__":
for i in range(10):
t = Thread(target=func,args=(i,))
t.start()
print(os.getpid())
"""
# (2) 并发的多进程和多线程之间,多线程的速度更快
# 多线程速度
def func(i):
print( "当前进程号:{} , 参数是{} ".format(os.getpid() , i) )
"""
if __name__ == "__main__":
lst = []
startime = time.time()
for i in range(10000):
t = Thread(target=func,args=(i,))
t.start()
lst.append(t)
# print(lst)
for i in lst:
i.join()
endtime = time.time()
print("运行的时间是{}".format(endtime - startime) ) # 运行的时间是1.8805944919586182
"""
# 多进程速度
"""
if __name__ == "__main__":
lst = []
startime = time.time()
for i in range(10000):
p = Process(target=func,args=(i,))
p.start()
lst.append(p)
# print(lst)
for i in lst:
i.join()
endtime = time.time()
print("运行的时间是{}".format(endtime - startime) ) # 运行的时间是101.68004035949707
"""
# (3) 多线程之间,数据共享
num = 100
lst = []
def func():
global num
num -= 1
for i in range(100):
t = Thread(target=func)
t.start()
lst.append(t)
for i in lst:
i.join()
print(num)
小提示: 一个线程对变量进行操作的时候,其他的线程就不能在对这个变量进行操作。这个时候用锁把线程锁住。
3. 自定义线程_守护线程
3.1 自定义线程
# ### 用类定义线程
from threading import Thread
import os,time
# (1)必须继承父类Thread,来自定义线程类
"""
class MyThread(Thread):
def __init__(self,name):
# 手动调用父类的构造方法
super().__init__()
# 自定义当前类需要传递的参数
self.name = name
def run(self):
print( "当前进程号{},name={}".format(os.getpid() , self.name) )
if __name__ == "__main__":
t = MyThread("我是线程")
t.start()
print( "当前进程号{}".format(os.getpid()) )
"""
# ### 线程中的相关属性
"""
# 线程.is_alive() 检测线程是否仍然存在
# 线程.setName() 设置线程名字
# 线程.getName() 获取线程名字
# 1.currentThread().ident 查看线程id号
# 2.enumerate() 返回目前正在运行的线程列表
# 3.activeCount() 返回目前正在运行的线程数量
"""
"""
def func():
time.sleep(1)
if __name__ == "__main__":
t = Thread(target=func)
t.start()
# 检测线程是否仍然存在
print( t.is_alive() )
# 线程.getName() 获取线程名字
print(t.getName())
# 设置线程名字
t.setName("抓API接口")
print(t.getName())
"""
from threading import currentThread
from threading import enumerate
from threading import activeCount
def func():
time.sleep(0.1)
print("当前子线程号id是{},进程号{}".format( currentThread().ident ,os.getpid()) )
if __name__ == "__main__":
t = Thread(target=func)
t.start()
print("当前主线程号id是{},进程号{}".format( currentThread().ident ,os.getpid()) )
for i in range(5):
t = Thread(target=func)
t.start()
# 返回目前正在运行的线程列表
lst = enumerate()
print(lst,len(lst))
# 返回目前正在运行的线程数量 (了解)
print(activeCount())
3.2 守护线程
# ### 守护线程 : 等待所有线程全部执行完毕之后,自己在终止程序,守护所有线程
from threading import Thread
import time
def func1():
while True:
time.sleep(1)
print("我是函数func1")
def func2():
print("我是func2 start ... ")
time.sleep(3)
print("我是func2 end ... ")
def func3():
print("我是func3 start ... ")
time.sleep(6)
print("我是func3 end ... ")
if __name__ == "__main__":
t = Thread(target=func1)
t2 = Thread(target=func2)
t3 = Thread(target=func3)
# 设置守护线程 (启动前设置)
t.setDaemon(True)
t.start()
t2.start()
t3.start()
print("主线程执行结束.... ")
4. 线程安全问题
4.1 线程安全问题
# ### 线程中的数据安全问题
from threading import Thread , Lock
import time
n = 0
def func1(lock):
global n
lock.acquire()
for i in range(1000000):
n += 1
lock.release()
def func2(lock):
global n
# with语法可以简化上锁+解锁的操作,自动完成
with lock:
for i in range(1000000):
n -= 1
if __name__ == "__main__":
lst = []
lock = Lock()
start = time.time()
for i in range(10):
t1 = Thread(target=func1 ,args=(lock,) )
t1.start()
t2 = Thread(target=func2 ,args=(lock,) )
t2.start()
lst.append(t1)
lst.append(t2)
for i in lst:
i.join()
# print(lst,len(lst))
end = time.time()
print("主线程执行结束... 当前n结果为{} ,用时{}".format(n , end-start))
4.2 Semaphore_信号量
# ### 信号量 Semaphore (线程)
"""同一时间对多个线程上多把锁"""
from threading import Thread,Semaphore
import time , random
def func(i,sem):
time.sleep(random.uniform(0.1,0.7))
# with语法自动实现上锁 + 解锁
with sem:
print("我在电影院拉屎 .... 我是{}号".format(i))
if __name__ == "__main__":
sem = Semaphore(5)
for i in range(30):
Thread(target=func,args=(i,sem)).start()
print(1)
"""
创建线程是异步的,
上锁的过程会导致程序变成同步;
"""
5. 死锁_互斥锁_递归锁
加一把锁,就对应解一把锁.形成互斥锁. 从语法上来说,锁可以互相嵌套,但不要使用, 不要因为逻辑问题让上锁分成两次.导致死锁 递归锁用于解决死锁,但只是一种应急的处理办法
# ### 互斥锁 死锁 递归锁
from threading import Thread , Lock , RLock
import time
# (1) 语法上的死锁
"""语法上的死锁: 是连续上锁不解锁"""
"""
lock = Lock()
lock.acquire()
# lock.acquire() error
print("代码执行中 ... 1")
lock.release()
lock.release()
"""
"""是两把完全不同的锁"""
lock1 = Lock()
lock2 = Lock()
lock1.acquire()
lock2.acquire()
print("代码执行中 ... 2")
lock2.release()
lock1.release()
# (2) 逻辑上的死锁
""""""
noodles_lock = Lock()
kuaizi_lock = Lock()
def eat1(name):
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
noodles_lock.release()
print("{}吃完了,满意的放下了面条".format(name))
def eat2(name):
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
noodles_lock.release()
print("{}吃完了,满意的放下了面条".format(name))
# kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
if __name__ == "__main__":
lst1 = ["康裕康","张宇"]
lst2 = ["张保张","赵沈阳"]
for name in lst1:
Thread(target=eat1,args=(name,)).start()
for name in lst2:
Thread(target=eat2,args=(name,)).start()
# (3) 使用递归锁
"""
递归锁的提出专门用来解决死锁现象
用于快速解决线上项目死锁问题
即使连续上锁,使用递归锁后也形同虚设,因为递归锁的作用在于解锁;
"""
"""
# 基本语法
rlock = RLock()
rlock.acquire()
rlock.acquire()
rlock.acquire()
rlock.acquire()
print("代码执行中 ... 3")
rlock.release()
rlock.release()
rlock.release()
rlock.release()
"""
"""
noodles_lock = Lock()
kuaizi_lock = Lock()
# 让noodles_lock和kuaizi_lock 都等于递归锁
noodles_lock = kuaizi_lock = RLock()
def eat1(name):
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
noodles_lock.release()
print("{}吃完了,满意的放下了面条".format(name))
def eat2(name):
kuaizi_lock.acquire()
print("{}抢到筷子了 ... ".format(name))
noodles_lock.acquire()
print("{}抢到面条了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
noodles_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
kuaizi_lock.release()
print("{}吃完了,满意的放下了筷子".format(name))
if __name__ == "__main__":
lst1 = ["康裕康","张宇"]
lst2 = ["张保张","赵沈阳"]
for name in lst1:
Thread(target=eat1,args=(name,)).start()
for name in lst2:
Thread(target=eat2,args=(name,)).start()
"""
# (4) 尽量使用一把锁解决问题,(少用锁嵌套,容易逻辑死锁)
"""
lock = Lock()
def eat1(name):
lock.acquire()
print("{}抢到面条了 ... ".format(name))
print("{}抢到筷子了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
print("{}吃完了,满意的放下了筷子".format(name))
print("{}吃完了,满意的放下了面条".format(name))
lock.release()
def eat2(name):
lock.acquire()
print("{}抢到筷子了 ... ".format(name))
print("{}抢到面条了 ... ".format(name))
print("开始享受香菇青菜面 ... ")
time.sleep(0.5)
print("{}吃完了,满意的放下了筷子".format(name))
print("{}吃完了,满意的放下了筷子".format(name))
lock.release()
if __name__ == "__main__":
lst1 = ["康裕康","张宇"]
lst2 = ["张保张","赵沈阳"]
for name in lst1:
Thread(target=eat1,args=(name,)).start()
for name in lst2:
Thread(target=eat2,args=(name,)).start()
"""
6. 线程事件
# ### 事件 Event
from threading import Thread , Event
import time,random
"""
wait : 动态加阻塞 (True => 放行 False => 阻塞)
is_set : 获取内部成员属性值是True 还是 False
set : 把False -> True
clear : 把True -> False
"""
# (1) 基本语法
"""
e = Event()
print(e.is_set())
e.set()
print(e.is_set())
e.wait()
e.clear()
# 最多阻塞三秒,放行
e.wait(3)
print("代码执行中 ... ")
"""
# (2) 模拟连接远程数据库
"""最多连接三次,如果三次都连接不上,直接报错."""
def check(e):
print("目前正在检测您的账号和密码 .... ")
# 模拟延迟的场景
time.sleep(random.randrange(1,7)) # 1 ~ 6
# 把成员属性值从False -> True
e.set()
def connect(e):
sign = False
for i in range(1,4):
e.wait(1)
if e.is_set():
print("数据库连接成功 ... ")
sign = True
break
else:
print("尝试连接数据库第{}次失败了...".format(i))
# 三次都不成功,报错
if sign == False:
# 主动抛出异常 超时错误
raise TimeoutError
# if __name__ == "__main__":
e = Event()
t1 = Thread(target=check,args=(e,))
t1.start()
t2 = Thread(target=connect,args=(e,))
t2.start()
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注脚本之家的更多内容!