作者
吕亚霖,2019年加入作业帮,作业帮基础架构-架构研发团队负责人,在作业帮期间主导了云原生架构演进、推动实施容器化改造、服务治理、GO微服务框架、DevOps的落地实践。
张浩然,2019年加入作业帮,作业帮基础架构-高级架构师,在作业帮期间,推动了作业帮云原生架构演进、负责多云k8s集群建设、k8s组件研发、linux内核优化调优、底层服务容器化相关工作。
背景
大规模检索系统一直都是各个公司平台业务的底层基石,往往是以千台裸金属服务器级别的超大规模集群的方式运行,数据量巨大,对于性能、吞吐、稳定性要求极为苛刻,故障容忍度很低。 除了运行层面外,超大规模集群和海量数据场景下的数据迭代和服务治理也往往是一个巨大的挑战:增量和全量的数据分发效率,短期和长期的热点数据追踪等都是需要深入研究的问题 本文将介绍作业帮内部设计实现的基于 fluid 计算存储分离架构,能够显著降低大规模检索系统类服务的复杂度,使得大规模检索系统可以像正常在线业务一样平滑管理。
大规模检索系统所面临的问题
作业帮的众多学习资料智能分析和搜索功能中都依赖于大规模数据检索系统,我们的集群规模在千台以上,总数据量在百 TB 级别以上,整个系统由若干分片组成,每个分片由若干服务器加载相同的数据集,运行层面上我们要求性能达到 P99 1.Xms,吞吐量高峰百 GB 级,稳定性要求 99.999% 以上。
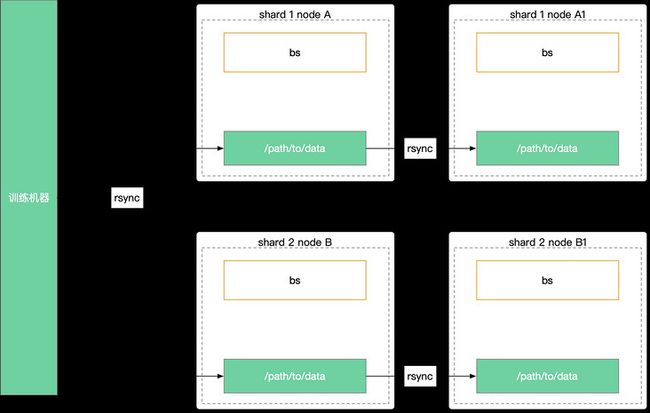
以往环境中为了提高数据读取效率和稳定性,更多的在考虑数据本地化存储,我们的检索系统每日产生索引项并需要进行 TB 级别的数据更新,这些数据通过离线建库服务产出之后,需要分别更新到对应的分片中,这种模式下带来了许多其他挑战,比较关键的问题集中在数据迭代和扩展性上:
- 数据集合的离散:由于实际运行中,每个分片的每个节点都需要复制下来本分片所有数据,由此带来了同步数据下发困难的问题。实际运行中如果要同步数据到单服务器节点,需要使用分级下发,先下发一级(十级)由一级分发给二级(百级)再分发给三级(千级),这个分发周期长且需要层层校验来保证数据准确性。
- 业务资源弹性扩缩较弱:原先的系统架构采用的是计算和存储紧耦合,数据存储和算力资源紧密捆绑,资源灵活扩展能力不高,扩容往往需要以小时为单位进行,缺乏应对突发峰值流量扩容能力。
- 单分片数据扩展性不足:单分片数据上限受分片集群内的单机存储上限限制。如果达到存储上限,往往需要拆分数据集,而这种拆分不是由业务需求驱动的。
而数据迭代和扩展性的问题又不得不带来了成本压力和自动化流程上的薄弱。
通过对检索系统运行和数据更新流程的分析,当前面临的关键问题是由于计算和存储的耦合所带来的,因此我们考虑如何去解耦计算和存储,只有引入计算存储分离的架构才能够从根本上解决复杂度的问题 计算存储分离最主要的就是将每个节点存储本分片全量数据的方式拆分开,将分片内的数据存储在逻辑上的远程机器上 但是计算存储分离又带来了其他的问题,比如稳定性问题,大数据量下的读取方式和读取速度,对业务的入侵程度等等问题,虽然存在这些问题,但是这些问题都是可解决以及易解决的 基于此我们确认计算存储分离一定是该场景下的良方,可以从根本上解决系统复杂度的问题。
计算存储分离架构解决复杂度问题
为了解决上述计算存储分离所需要考虑的问题,新的计算存储分离架构必须能达到以下目标:
- 读取的稳定性,计算存储分离终究是通过各种组件配合替换掉了原始文件读取,数据加载方式可以替换,但是数据读取的稳定性依然需要和原始保持同等水平。
- 每个分片千节点同时数据更新场景下,需要最大限度的提升读取速度,同时对网络的压力需要控制在一定程度内。
- 支持通过 POSIX 接口读取数据,POSIX 是最具备对各种业务场景的适应性的方式,这样无需侵入业务场景下,屏蔽了下游变动对上游的影响。
- 数据迭代的流程的可控性,对于在线业务来说,数据的迭代理应被视为和服务迭代等同的 cd 流程,那么数据迭代的可控性就及其重要,因为本身就是 cd 流程的一部分。
- 数据集合的可伸缩性,新的架构需要是一套可复制,易扩展的模式,这样才能面对数据集合的伸缩、集群规模的伸缩具备良好的应对能力。
为了达成上述目标,我们最终选用了 Fluid 开源项目作为整个新架构的关键纽带。
组件介绍
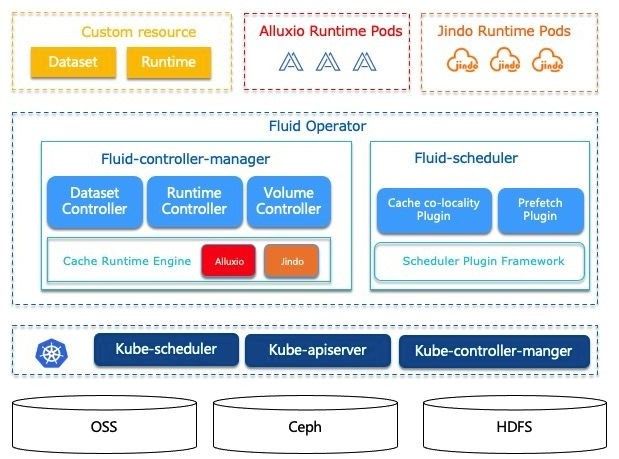
Fluid 是一个开源的 Kubernetes 原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI应用等。通过 Kubernetes 服务提供的数据层抽象,可以让数据像流体一样在诸如 HDFS、OSS、Ceph 等存储源和 Kubernetes 上层云原生应用计算之间灵活高效地移动、复制、驱逐、转换和管理。而具体数据操作对用户透明,用户不必再担心访问远端数据的效率、管理数据源的便捷性,以及如何帮助 Kuberntes 做出运维调度决策等问题。
用户只需以最自然的 Kubernetes 原生数据卷方式直接访问抽象出来的数据,剩余任务和底层细节全部交给 Fluid 处理。Fluid 项目当前主要关注数据集编排和应用编排这两个重要场景。
数据集编排可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点,而应用编排将指定该应用调度到可以或已经存储了指定数据集的节点上。这两者还可以组合形成协同编排场景,即协同考虑数据集和应用需求进行节点资源调度。
我们选择使用 fluid 的原因
- 检索服务已经完成容器化改造,天然适合 fluid。
- Fluid 作为数据编排系统,使得上层无需知道具体的数据分布就可以直接使用,同时基于数据的感知调度能力,可以实现业务的就近调度,加速数据访问性能。
- Fluid 实现了 pvc 接口,使得业务 pod 可以无感知的挂载进入 pod 内部,让 pod 内可以像使用本地磁盘一样无感知。
- Fluid 提供元数据和数据分布式分层缓存,以及高效文件检索功能。
- Fluid+alluxio 内置了多种缓存模式(回源模式,全缓存模式),不同的缓存策略(针对小文件场景的优化等)和存储方式(磁盘,内存),对于不同的场景具备良好的适应性,无需太多修改即可满足多种业务场景。
落地实践
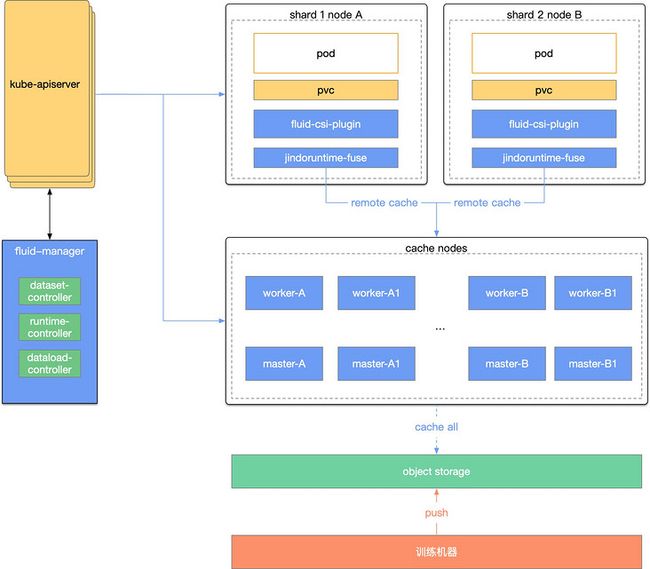
- 缓存节点和计算节点的分离: 虽然使用 fuse 和 worker 结合部署可以获得更好的数据本地性能,但是在在线场景下,我们最终选用了缓存和计算节点分离的方案,原因是通过延长一定的启动时间换来更优的弹性是值得的,以及我们并不希望业务节点稳定性问题和缓存节点的稳定性问题纠缠在一起。Fluid 支持 dataset 的可调度性,换言之就是缓存节点的可调度性,我们通过指定 dataset 的 nodeAffinity 来进行数据集缓存节点的调度,从而保证缓存节点可高效,弹性化的提供缓存服务。
在线场景的高要求: 对于在线业务场景,鉴于系统对于数据的访问速度、完整性和一致性有较高的要求,因此不能出现数据的部分更新、非预期的回源请求等; 所以对数据缓存和更新策略的选择就会很关键。
- 合适的数据缓存策略: 基于以上需求,我们选择使用 Fluid 的全缓存模式。在全缓存模式下,所有请求只会走缓存,而不在回源到数据源,这样就避免了非预期的长耗时请求。同时 dataload 的过程则由数据更新流程来把控,更安全和标准化。
- 结合权限流的更新流程: 在线业务的数据更新也是属于 cd 的一种,同样也需要更新流程来管控,通过结合了权限流程的 dataload 模式,使得线上数据发版更安全和标准化。
- 数据更新的原子性: 由于模型是由许多文件组成,只有所有的文件全部缓存起来之后,才是一份可以被使用的完整的模型;所以在全缓存无回源的前提下,就需要保证 dataload 过程的原子性, 在数据加载的过程中过,新版本数据不能被访问到,只有在数据加载完成之后,才可以读取到新版本数据。
以上方案和策略配合我们自动化的建库和数据版本管理功能,大大提高了整体系统的安全性和稳定性,同时使得整个过程的流转更加智能和自动化。
总结
基于 Fluid 的计算存储分离架构,我们成功地实现:
- 分钟级百 T 级别的数据分发。
- 数据版本管理和数据更新的原子性,使得数据分发和更新成为一种可管控,更智能的自动化流程。
- 检索服务能够像正常无状态服务一样,从而能够轻松通过 TKE HPA 实现横向扩展,更快捷的扩缩带来了更高的稳定性和可用性。
展望
计算和存储分离的模式使得以往我们认为非常特殊的服务可以被无状态化,可以像正常服务一样被纳入 Devops 体系中,而基于 Fluid 的数据编排和加速系统,则是实践计算和存储分离的一个切口,除了用于检索系统外,我们也在探索基于 Fluid 的 OCR 系统模型训练和分发的模式。
在未来工作方面,我们计划继续基于 Fluid 优化上层作业的调度策略和执行模式,并进一步扩展模型训练和分发,提高整体训练速度和资源的利用率,另一方面也帮助社区不断演进其可观测性和高可用等,帮助到更多的开发者。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》