重塑 DataFrame 是数据科学中一项重要且必不可少的技能。在本文中,我们将探讨 Pandas Melt() 以及如何使用它进行数据处理。
最简单的melt
最简单的melt()不需要任何参数,它将所有列变成行(显示为列变量)并在新列值中列出所有关联值。
df_wide.melt()
这个输出通常没有多大意义,所以一般用例至少指定了 id_vars 参数。例如, id_vars = 'Country' 会告诉 pandas 将 Country 保留为一列,并将所有其他列转换为行。
df_wide.melt(
id_vars='Country',
)
现在行数为 15,因为 Country 列中的每个值都有 5 个值(3 X 5 = 15)。
显示自定义名称
“变量”和“值”是列名。我们可以通过 var_name 和 value_name 参数指定自定义名称:
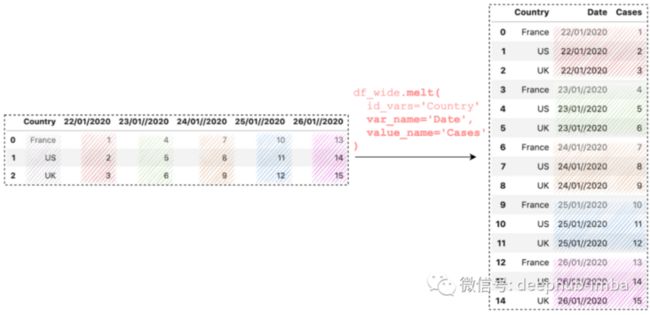
df_wide.melt(
id_vars='Country',
var_name='Date',
value_name='Cases'
)
指定多个 ID
Melt() 最有用的特性之一是我们可以指定多个 id 以将它们保留为列。例如,如果我们想保留 Country、Lat 和 Long 作为列以便更好地参考:
df_wide.melt(
id_vars=['Country', 'Lat', 'Long'],
var_name='Date',
value_name='Cases'
)
指定melt的列
Pandas的melt() 函数默认情况下会将所有其他列(除了 id_vars 中指定的列)转换为行。在实际项目中可能只关心某些列,例如,如果我们只想查看“24/01/2020”和“25/01/2020”上的值:
df_wide.melt(
id_vars=['Country', 'Lat', 'Long'],
value_vars=["24/01//2020", "25/01//2020"],
var_name='Date',
value_name='Cases'
)
Pandas melt
我们也可以直接从 Pandas 模块而不是从 DataFrame 调用melt()。但是,这些是相同的。

重塑 COVID-19 时间序列数据
有了到目前为止我们学到的知识,让我们来看看一个现实世界的问题:约翰霍普金斯大学 CSSE Github 提供的 COVID-19 时间序列数据。
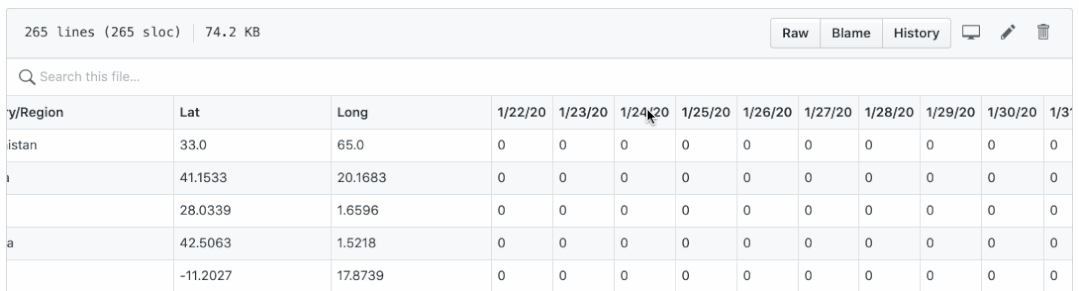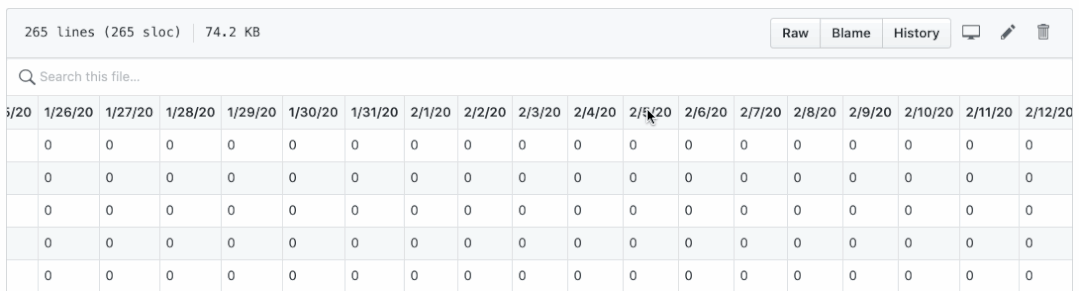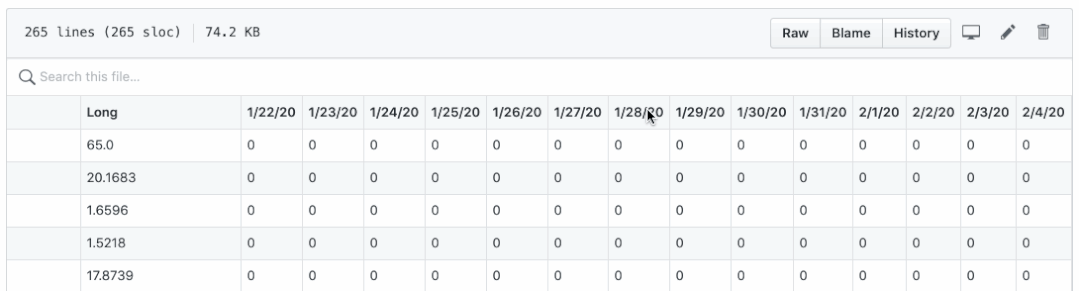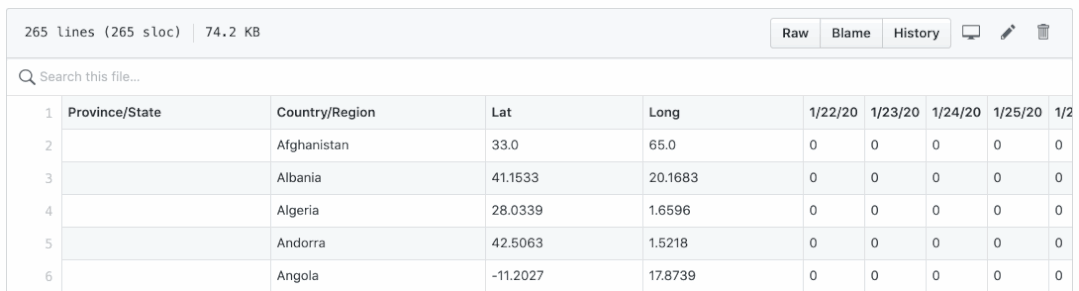
有两个问题:
- 确认、死亡和恢复保存在不同的 CSV 文件中。将它们绘制在一张图中并不简单。
- 日期显示为列名,它们很难执行逐日计算,例如计算每日新病例、新死亡人数和新康复人数。
让我们重塑 3 个数据集并将它们合并为一个 DataFrame。
读取数据集
confirmed_df = pd
.read_csv('time_series_covid19_confirmed_global.csv')
deaths_df = pd
.read_csv('time_series_covid19_deaths_global.csv')
recovered_df = pd
.read_csv('time_series_covid19_recovered_global.csv')将它们从宽格式改造成长格式
通过运行confirmed_df.columns、deaths_df.columns 和recovered_df.columns,它们都应该输出如下相同的结果:

请注意,列都是从第 4 列开始的日期,并获取确认的日期列表 df.columns [4:]

在合并之前,我们需要使用melt() 将DataFrames 从当前的宽格式逆透视为长格式。换句话说,我们将所有日期列转换为值。使用“省/州”、“国家/地区”、“纬度”、“经度”作为标识符变量。我们稍后将它们进行合并。
confirmed_df_long = confirmed_df.melt(
id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'],
value_vars=dates,
var_name='Date',
value_name='Confirmed'
)
deaths_df_long = deaths_df.melt(
id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'],
value_vars=dates,
var_name='Date',
value_name='Deaths'
)
recovered_df_long = recovered_df.melt(
id_vars=['Province/State', 'Country/Region', 'Lat', 'Long'],
value_vars=dates,
var_name='Date',
value_name='Recovered'
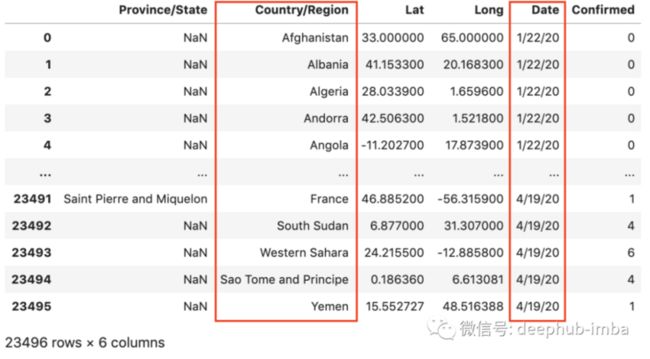
)所有结果都是新的长格式。所有这些都按日期和国家/地区排序,因为原始数据已经按国家/地区排序,并且日期列已经按 ASC 顺序排列。
这是confirmed_df_long的例子
最后,我们使用merge()将3个DataFrame一个接一个合并:
full_table = confirmed_df_long.merge(
right=deaths_df_long,
how='left',
on=['Province/State', 'Country/Region', 'Date', 'Lat', 'Long']
)
full_table = full_table.merge(
right=recovered_df_long,
how='left',
on=['Province/State', 'Country/Region', 'Date', 'Lat', 'Long']
)现在,我们得到一个包含 Confirmed、Deaths 和 Recovered 列的完整表格:

总结
在本文中,我们介绍了 5 个用例和 1 个实际示例,这些示例使用 Pandas 的melt() 方法将 DataFrame 从宽格式重塑为长格式。它非常方便,是数据预处理和探索性数据分析过程中最受欢迎的方法之一。
重塑数据是数据科学中一项重要且必不可少的技能。我希望你喜欢这篇文章并学到一些新的有用的东西。
本文代码:https://github.com/BindiChen/...
作者:B。Chen