两种分词标准

实践中的应用

常用的方案

采用机械分词的方法,不足以消除切分中的歧义,这里将语言模型应用到词切分中,提高了分词的准确率。如二元模型。
二元模型(一阶马尔科夫链)

命名实体识别

中文分词的流程

分词会有很多不同的结果,确定分词结果

对于分词图中,权重最小的路径,概率最大,分词结果最有可能性。再进行第四步,应用后处理规则,识别特殊组合的名词性结构。
在分词流程中,每一步的具体细节再看看书。
朴素贝叶斯,属于产生式模型,即计算的是p(x|y)。x是由a1,a2等特征组成的特征向量。


两个不同的onehot向量点积结果是零,没有相关性。
信息熵
通俗理解信息熵

熵的性质:

随机变量的不确定性:假设p = P(X=n),如果p等于0,说明随机变量取n值得可能性为0,也就是说,X一定不取n。如果p等于1,说明X一定等于n。上面两个例子,对于X的取值是确定的。
如果p在0-1之间,说明p是不确定性的。比如,p=0.00001,说明X只有很小的可能取n,此时的不确定性比较小,X基本不会等于n。同理p=0.5,则不确定性很大了。
对应到例子上来,就是:




上述也说明,在X服从的分布中,平均分布的不确定性最大。这一点也很好理解,比如对于正态分布,X基本可以确定会落在中间。但对于平均分布,X并不能确定会落在哪个区间。
信息是用来消除不确定性的东西。
——Shannon 信息论奠基人
互信息

x的后验概率与先验概率比值的对数,为y对x的互信息两。


就相当于从p(X)换成了p(X,Y)。

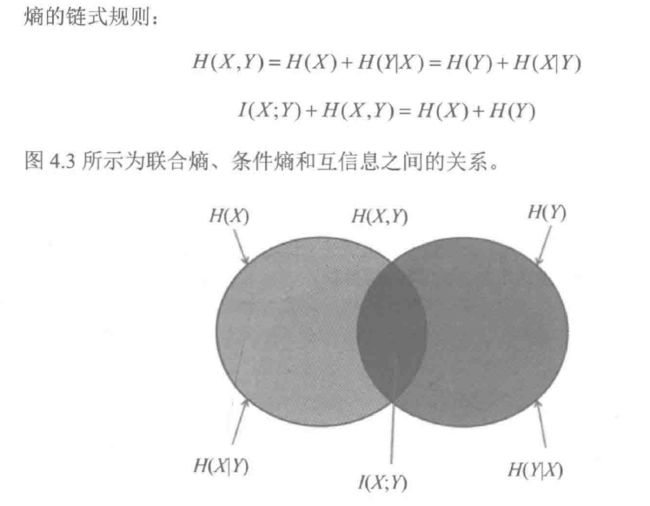
跟集合交并集类似。
对于熵的进一步理解,可以参考熵的理解



三个基本问题:模型的表示,模型的学习,模型的预测。
图表示理论,图模型有两种表示方法:贝叶斯网络和马尔科夫随机场。
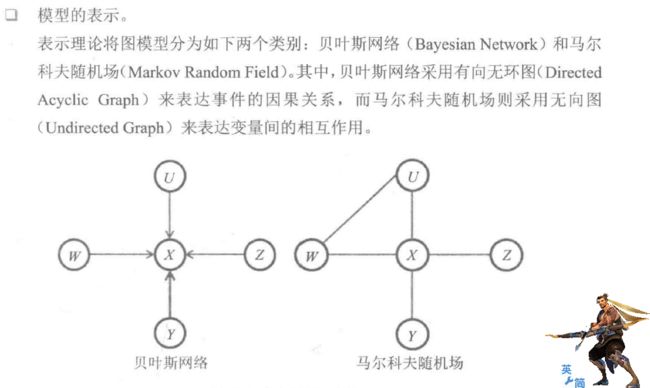

隐马尔科夫模型,最大熵模型和条件随机场都是从马尔科夫模型发展出来的。
模型的学习:

模型的预测:

朴素贝叶斯模型--NB
隐马尔科夫模型--HMM
最大熵模型--ME
条件随机场--CRF
统计语言模型:用来计算句子中某种语言模式出现概率的统计模型。
一个长度为n的句子,位置为k的词出现的概率与其前面的所有的词都相关,也就是说,与它前面k-1个词都相关,其k元语言模型可以表示为:

其中w 可以看做wk-1
嗯。。。这块书中应该是出现错误了。
二元模型

这本书中对于n-grams介绍很一般,更多的还是要查询资料。
对于n-grams模型的理解:
参考自然语言处理中n-gram模型学习笔记
马尔科夫假设:在一段文本中,第N个词的出现只与前面n-1个词相关,而与其他任何词都不相关。
基于这样一种假设,可以评估文本中每一个词出现的概率:
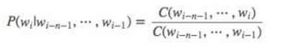
即p(a2|a1) = (a1在a2前面,二者一起出现的次数)/a1出现的次数
句子中,在a1条件下,词a2出现的概率可以根据上面求出,同样,可以求出p(a3|a2) ,一直到最后,那么一整个句子出现的模型就可以表示为
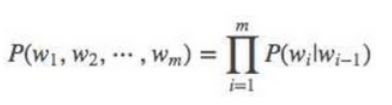



是不是说,在预训练过程中,没有损失函数,只需要统计各种语言模式一起出现的次数,然后计算频率保存就行了?
那就是说,没有要学习的参数啊。。在预测的时候,直接提取存储好的然后计算就行了。
上面说到,n-gram需要事先计算并保存所有的概率值。
可以不用这么做,我们用极大似然的思想,最终要求得参数theta,找到一个参数theta,使得能够获得语言模型的最大值。
对下面一段话的理解。
在用n-grams模型时,已知单词w和单词的上下文context(w)时,是可以根据文本统计出概率p的。
而这里我们不用n-grams模型,在已知w和context(w)时,能够得到特定的p,于是我们认为F是这两个值的函数,函数F由参数theta来控制。一旦确定了theta,那么F也就被确定了,就可以用F来求出p了。


接下来的几个模型,就是,我们要构造一个函数F,利用极大似然估计的原理来确定参数theta,得到参数theta以后,我们就可以得到概率最大的模型了。
马尔科夫链的理解:
只需要知道:1、下一步状态只与当前状态有关。
2、下一步状态可以由当前状态乘以转移矩阵得到。
参考:通俗理解马尔科夫链
对于HMM的解释,书中解释的还算是容易理解的,深入理解再看一下我爱自然语言处理中的课件。
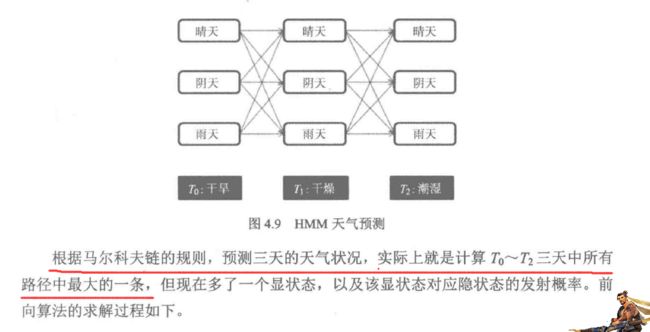
上图中红线的解释:预测最可能的状态,每次只挑最大的状态。第一天,最大的
第二天,在第一天的基础上挑最大的,
第三天,在第二天的基础上挑最大的。

隐马尔可夫模型 (Hidden Markov Model) 是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步的分析。
隐马尔科夫模型有两条链,一个是马尔科夫链,一个是可观测序列。马尔科夫链序列上的状态是不可观察的所以叫做隐藏状态。
HMM的五个参数都是数据统计的结果,以语音识别为例,每一个字都被看做一个隐藏状态。初始概率向量和隐藏转移概率矩阵都是从大量的文章统计出来的。观察状态就是语音信号的特征向量。这也是HMM的应用。就跟书中的例子一样,想要得到每天的天气,而在语音识别中想要得到每个单词的最大可能性,找出最有可能的链接。
HMM的识别方法就是一步步的链接,找出最有可能的链接。
HMM与nlp的应用之一自然语言处理1-马尔科夫链和隐马尔科夫模型(HMM)
这篇文章中所讲,在两个转移矩阵不能直接被(估计)测量时,就用前向-后向算法来学习AB矩阵的参数。这是实际应用中常见的情况,但是直接用前向-后向算法进行学习的准确性不是非常高,所以目前通用的算法是通过人工标注语料生成HMM。尽管工作量较大。
HMM模型的缺点,与引入最大熵模型。

