HashMap简介
HashMap由数组+链表+ 红黑树(临界值为8)组成的,可以存储null键和null值,线程不安全,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,实现的基于key-value存取的工具类,在JDK1.8之前没有红黑树这一数据结构,在JDK1.8之后对其进行了优化:考虑到发生大量Hash碰撞时链表查询效率低,所以加入了红黑树这一数据结构以提高此种情况的查询效率,通过阈值控制,将链表和红黑树进行相互转化
为什么树化的临界值为8?
通过源码我们得知HashMap源码作者通过泊松分布算出,当桶中结点个数为8时,出现的几率是亿分之6的,因此常见的情况是桶中个数小于8的情况,此时链表的查询性能和红黑树相差不多,因为转化为树还需要时间和空间,所以此时没有转化成树的必要。
HashMap的工作原理
HashMap 的实例有两个参数影响其性能:“初始容量(初始size为16)” 和 “加载因子(默认加载因子是 0.75,)”。
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。在jdk1.8中,如果链表的长度超过了阈值,链表就会转换成红黑树,来提高性能,当红黑树的节点个数小于6的时候,又会转化成链表。如果所有的桶都满了(容量 * 负载因子(0.75) ),这个时候就需要扩容 resize(),并且重新计算Node对象的位置重新排列。
扩容机制
// 默认初始化容量大小,为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量:2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
// 负载因子,在扩容时使用
static final float DEFAULT_LOAD_FACTOR = 0.75f;
扩容(resize)就是重新计算容量,使用一个容量更大的数组来代替已有的容量小的数组,将原有Entry数组的元素拷贝到新的Entry数组里。
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组(jdk1.6,但不超过最大容量),来重新调整map的大小,并将原来的对象放入新的bucket数组中。
当两个对象的hashcode相同会发生什么
当两个对象的hashcode相同的时候,所以它们的bucket位置相同,会发生碰撞,因为hashmap使用链表来存储key ,value的键值对,所以这个Entry (包含有键值对的Map.Entry对象)会存储在链表中。
有什么方法可以减少hash碰撞
- 扰动函数可以减少碰撞,原理是他让内容不同的对象返回不同的hashcode值,这样就会少产生碰撞,也就是在数据结构中链表的结构少了,在取值时,会很少的调用equals方法,提高Map的性能,扰动hash方法的内部算法实现,目的是让不同的对象返回不同的hashcode。
- 使用不可变的,声明为final的对象做键值,如String Integer。不可变使得能够缓存不同键的hashcode。这将提高整个回去对象的速度。因为String是final的,而且已经重写了equals()和hashCode()方法了。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。
HashMap的数组长度为什么一定要是2的幂
答:hashMap的数组长度一定保持2的次幂,数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index分布更加均匀,如果不是2的次幂,也就是低位不是全为1此时,低位有可能是0,计算hash值得时候冲突几率变大,发生hash碰撞,会造成空间的。
HashMap为什么线程不安全
HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
HashTable
底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
初始size为11,扩容:newsize = olesize*2+1
计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
ConcurrentHashMap
底层采用分段的数组+链表实现,线程安全
通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
哈希表的实现
哈希表(Hash table,也叫散列表), 是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hash table(key,value) 的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,
有几种常见的单例模式?对于这几种单例模式synchronized具体锁的是什么东西?
饿汉式:
懒汉式:先声明,用的时候在实例化,所以叫懒汉式
双重校验锁DCL(double checked locking)
、静态内部类实现(也叫类加载方式)的单例模式
、枚举单例
synchronized具体锁的是什么东西?(答案:被锁的代码块叫作临界区,只有获取到锁资源才能进入临界区,进行相应的操作)
Binder的运行机制
Binder
Android系统中,涉及到多进程间的通信底层都是依赖于Binder IPC机制。例如当进程A中的Activity要向进程B中的Service通信,这便需要依赖于Binder IPC。不仅于此,整个Android系统架构中,大量采用了Binder机制作为IPC(进程间通信)方案。
-
为什么用binder
性能方面(Binder数据拷贝只需要一次,而管道、消息队列、Socket都需要2次)
安全方面(Binder机制从协议本身就支持对通信双方做身份校检,因而大大提升了安全性)
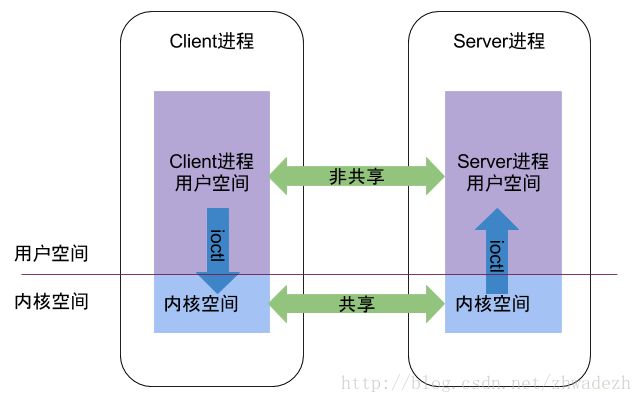
对于用户空间,不同进程之间彼此是不能共享的,而内核空间却是可共享的。Client进程向Server进程通信,恰恰是利用进程间可共享的内核内存空间来完成底层通信工作的,Client端与Server端进程往往采用ioctl等方法跟内核空间的驱动进行交互。
-
Binder原理
Binder通信采用client-server架构,从组件视角来说,包含Client、Server、ServiceManager以及binder驱动,其中ServiceManager用于管理系统中的各种服务。架构图如下所示:
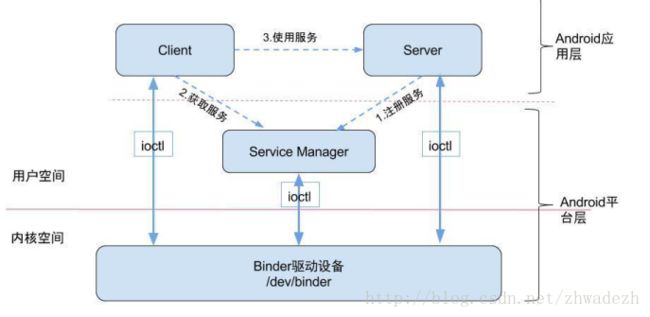
Binder 机制
- 首先需要注册服务端,只有注册了服务端,客户端才有通讯的目标,服务端通过 ServiceManager 注册服务,注册的过程就是向 Binder 驱动的全局链表 binder_procs 中插入服务端的信息,然后向 ServiceManager 的 svcinfo 列表中缓存一下注册的服务。
- 有了服务端,客户端就可以跟服务端通讯了,须先向ServiceManager中获取相应的Service,
- 有了服务端的引用我们就可以向服务端发送请求了,通过 BinderProxy 将我们的请求参数发送给 ServiceManager,通过共享内存的方式使用内核方法 copy_from_user() 将我们的参数先拷贝到内核空间,这时我们的客户端进入等待状态,然后 Binder 驱动向服务端的 todo 队列里面插入一条事务,执行完之后把执行结果通过 copy_to_user() 将内核的结果拷贝到用户空间(这里只是执行了拷贝命令,并没有拷贝数据,binder只进行一次拷贝),唤醒等待的客户端并把结果响应回来,这样就完成了一次通讯。
ClassLoader类加载器
ClassLoader的具体作用就是将class文件加载到jvm虚拟机中去,程序就可以正确运行了。但是,jvm启动的时候,并不会一次性加载所有的class文件,而是根据需要去动态加载。想想也是的,一次性加载那么多jar包那么多class,那内存不崩溃。
热修复原理 andfix
第一步 在服务器生成修复包,打包成dex 给用户下载
第二步
app客户端加载dex包
第三步
找到修复好的class 找到修复好的方法
使用注解标识需要修复的类和方法
通过DexFile 加载手机里面的dex文件
服务器编程方法 需要指定包名和方法,让他知道 需要去修复那个地方。其实这一步就是制造补丁包dex
***class 怎么打包成class?
sdk目录build_tool 下的dx.bat工具
Thinker

思路:从服务器下载修复好的dex包如(class1.dex),替换原有bug的dex
注意事项
1,主包不能有bug 不然启动就闪退,不能加载dex
2,必须是运行的时候补丁包如何生成?
dx.bat 打包dex,
说起热修复就不得不提类的加载机制,和常规的JVM类似,在Android中类的加载也是通过ClassLoader来完成,具体来说就是PathClassLoader 和 DexClassLoader 这两个Android专用的类加载器,这两个类的区别如下:
PathClassLoader:只能加载已经安装到Android系统中的apk文件(/data/app目录),是Android默认使用的类加载器。
DexClassLoader:可以加载任意目录下的dex/jar/apk/zip文件,也就是我们一开始提到的补丁。
这两个类都是继承自BaseDexClassLoader,我们可以看一下BaseDexClassLoader的构造函数
public BaseDexClassLoader(String dexPath, File optimizedDirectory,
String libraryPath, ClassLoader parent) {
super(parent);
this.pathList = new DexPathList(this, dexPath, libraryPath, optimizedDirectory);
}
这个构造函数只做了一件事,就是通过传递进来的相关参数,初始化了一个DexPathList对象。DexPathList的构造函数,就是将参数中传递进来的程序文件(就是补丁文件)封装成Element对象,并将这些对象添加到一个Element的数组集合dexElements中去。
可能有多个dex 使用hashset存放需要修复的dex集合
我们现在要去查找一个名为name的class,那么DexClassLoader将通过以下步骤实现:
在DexClassLoader的findClass 方法中通过一个DexPathList对象findClass()方法来获取class
在DexPathList的findClass 方法中,对之前构造好dexElements数组集合进行遍历,一旦找到类名与name相同的类时,就直接返回这个class,找不到则返回null。
总的来说,通过DexClassLoader查找一个类,最终就是就是在一个数组中查找特定值的操作。
综合以上所有的观点,我们很容易想到一种非常简单粗暴的热修复方案。假设现在代码中的某一个类或者是某几个类有bug,那么我们可以在修复完bug之后,可以将这些个类打包成一个补丁文件,然后通过这个补丁文件封装出一个Element对象,并且将这个Element对象插到原有dexElements数组的最前端,这样当DexClassLoader去加载类时,优先会从我们插入的这个Element中找到相应的类,虽然那个有bug的类还存在于数组中后面的Element中,但由于双亲加载机制的特点,这个有bug的类已经没有机会被加载了,这样一个bug就在没有重新安装应用的情况下修复了。
插件化的原理
通过上面的框架介绍,插件化的原理无非就是这些:
在Android中应用插件化技术,其实也就是动态加载的过程,分为以下几步:
通过DexClassLoader加载。把可执行文件( .so/dex/jar/apk 等)拷贝到应用 APP 内部。
加载可执行文件,更换静态资源
调用具体的方法执行业务逻辑
View和ViewGroup的区别:
可以从两方面来说:
一.事件分发方面的区别;
二.UI绘制方面的区别;
UI绘制主要有五个方法:onDraw(),onLayout(),onMeasure(),dispatchDraw(),drawChild()
1.ViewGroup包含这五个方法,而View只包含onDraw(),onLayout(),onMeasure()三个方法,不包含dispatchDraw(),drawChild()。
Android的UI界面都是由View和ViewGroup及其派生类组合而成的。其中,View是所有UI组件的基类,而ViewGroup是容纳View及其派生类的容器,ViewGroup也是从View派生出来的。一般来说,开发UI界面都不会直接使用View和ViewGroup(自定义控件的时候使用),而是使用其派生类。
Dalvik与ART的区别
(1)在Dalvik下,应用每次运行都需要通过即时编译器(JIT)将字节码转换为机器码,即每次都要编译加运行,这虽然会使安装过程比较快,但是会拖慢应用的运行效率。而在ART 环境中,应用在第一次安装的时候,字节码就会预编译(AOT)成机器码,这样的话,虽然设备和应用的首次启动(安装慢了)会变慢,但是以后每次启动执行的时候,都可以直接运行,因此运行效率会提高。
(2)ART占用空间比Dalvik大(原生代码占用的存储空间更大,字节码变为机器码之后,可能会增加10%-20%),这也是著名的“空间换时间大法"。
(4)预编译也可以明显改善电池续航,因为应用程序每次运行时不用重复编译了,从而减少了 CPU 的使用频率,降低了能耗。
Android开发中怎样用多进程、用多进程的好处、多进程的缺陷、解决方法(转)
四大组件在AndroidManifest文件中注册的时候,有个属性android:process这里可以指定组件的所处的进程。
好处:
1)分担主进程的内存压力。
多进程的缺陷
进程间的内存空间是不可见的。开启多进程后,会引发以下问题:
1)Application的多次重建。
2)静态成员的失效。
3)文件共享问题。
4)SharedPreferences的可靠性下降
Anr的主要原因
ANR一般有三种类型:
1:KeyDispatchTimeout(5 seconds) --主要类型
按键或触摸事件在特定时间内无法得到响应
2:BroadcastTimeout(10 seconds)
BroadcastReceiver在的onRecieve运行在主线程中,短时间内无法处理完成导致
3:ServiceTimeout(20 seconds) --小概率类型
Service的各个声明周期在特定时间内无法处理完成
ANR产生时,系统会生成一个traces.txt的文件放在/data/anr/下。)使用命令导出anr日志
adb pull /data/anr/traces.txt ~/Desktop/
分析关键信息
以每行的重点内容没准,每行自带时间戳
因为主线程被阻塞导致的关键信息。
为什么会超时:事件没有机会处理 & 事件处理超时
怎么避免ANR
ANR的关键
是处理超时,所以应该避免在UI线程,BroadcastReceiver 还有service主线程中,处理复杂的逻辑和计算
而交给work thread操作。
1)避免在activity里面做耗时操作,oncreate & onresume
2)避免在onReceiver里面做过多操作
3)避免在Intent Receiver里启动一个Activity,因为它会创建一个新的画面,并从当前用户正在运行的程序上抢夺焦点。
4)尽量使用handler来处理UI thread & workthread的交互。
常见的内存泄漏。
线程造成的内存泄漏
Handler造成的内存泄漏
单例导致内存泄露
静态变量导致内存泄露
非静态内部类导致内存泄露
未取消注册(BroadcastReceiver )或回调导致内存泄露
Timer和TimerTask导致内存泄露
集合中的对象未清理造成内存泄露
资源未关闭或释放导致内存泄露
属性动画造成内存泄露
WebView造成内存泄露
一些建议
对于生命周期比Activity长的对象如果需要应该使用ApplicationContext
对于需要在静态内部类中使用非静态外部成员变量(如:Context、View ),可以在静态内部类中使用弱引用来引用外部类的变量来避免内存泄漏
对于不再需要使用的对象,显示的将其赋值为null,比如使用完Bitmap后先调用recycle(),再赋为null
保持对对象生命周期的敏感,特别注意单例、静态对象、全局性集合等的生命周期
对于生命周期比Activity长的内部类对象,并且内部类中使用了外部类的成员变量,可以这样做避免内存泄漏:
将内部类改为静态内部类
静态内部类中使用弱引用来引用外部类的成员变量
在涉及到Context时先考虑ApplicationContext,当然它并不是万能的,对于有些地方则必须使用Activity的Context,对于Application,Service,Activity三者的Context的应用场景如下:
主要描述如何检测应用在UI线程的卡顿,目前已经有两种比较典型方式来检测了:
我们先来理一下FPS基本的概念:
60 fps 的意思是说,画面每秒更新60次
这60次更新,是要均匀更新的,不是说一会快,一会慢,那样视觉上也会觉得不流畅
每秒60次,也就是 1/60 ~= 16.67 ms 要更新一次
使用BlockCanary开源方案。其原理是利用Looper中的loop输出的
利用UI线程Looper打印的日志
在Android UI线程中有个Looper,在其loop方法中会不断取出Message,调用其绑定的Handler在UI线程进行执行。
,同样利用了Looper机制,只不过在非UI线程中,如果执行耗时达到我们设置的阈值,则会执行mLogRunnable,打印出UI线程当前的堆栈信息;如果你阈值时间之内完成,则会remove掉该runnable。
msg.target.dispatchMessage(msg);
此行代码的执行时间,就能够检测到部分UI线程是否有耗时操作了。可以看到在执行此代码前后,如果设置了logging,会分别打印出>>>>> Dispatching to和<<<<< Finished to
利用Choreographer
Android系统每隔16ms发出VSYNC信号,触发对UI进行渲染。SDK中包含了一个相关类,以及相关回调。理论上来说两次回调的时间周期应该在16ms,如果超过了16ms我们则认为发生了卡顿,我们主要就是利用两次回调间的时间周期来判断:
Layout Inspector 代替Hierarchy View 检测布局复杂度工具
如何实现启动优化,有什么工具可以使用?
重点提到了systrace、TraceView这两个工具,
Systrace允许你监视和跟踪Android系统的行为(trace)。它会告诉你系统都在哪些工作上花费时间、CPU周期都用在哪里,甚至你可以看到每个线程、进程在指定时间内都在干嘛
TraceView 是 Android SDK 中内置的一个工具,它可以加载 trace 文件,用图形的形式展示代码的执行时间、次数及调用栈,便于我们分析。
而对于内存泄露的检测,常用的工具有LeakCanary、MAT(Memory Analyer Tools)、Android Studio自带的Profiler
性能优化
快:使用时避免出现卡顿,响应速度快,减少用户等待的时间,满足用户期望。
(UI 绘制、应用启动、页面跳转、事件响应,
界面绘制。主要原因是绘制的层级深、页面复杂、刷新不合理,由于这些原因导致卡顿的场景更多出现在 UI 和启动后的初始界面以及跳转到页面的绘制上。
数据处理。导致这种卡顿场景的原因是数据处理量太大,一般分为三种情况,一是数据在处理 UI 线程,二是数据处理占用 CPU 高,导致主线程拿不到时间片,三是内存增加导致 GC 频繁,从而引起卡顿。)
在手机开发者模式下,有一个卡顿检测工具叫做:Profile GPU Rendering,一个图形监测工具,能实时反应当前绘制的耗时
TraceView以分析到每一个方法的执行时间,
稳:减低 crash 率和 ANR 率,不要在用户使用过程中崩溃和无响应。
(提高代码质量。比如开发期间的代码审核,看些代码设计逻辑,业务合理性等。
代码静态扫描工具。常见工具有Android Lint、Findbugs、Checkstyle、PMD等等。
Crash监控。把一些崩溃的信息,异常信息及时地记录下来,以便后续分析解决。
Crash上传机制。在Crash后,尽量先保存日志到本地,然后等下一次网络正常时再上传日志信息。)
省:节省流量和耗电,减少用户使用成本,避免使用时导致手机发烫。
(:Battery Historian。Battery Historian 是一款由 Google 提供的 Android 系统电量分析工具)
小:安装包小可以降低用户的安装成本。
代码混淆。资源优化,图片优化,避免重复功能的库,cdn
android内存的优化
android内存泄露容易导致内存溢出,又称为OOM。
Android内存优化策略:
1)在循环内尽量不要使用局部变量
2)不用的对象即时释放,即指向NULL
3)数据库的cursor即时关闭。
4)构造adapter时使用缓存contentview
5)调用registerReceiver()后在对应的生命周期方法中调用unregisterReceiver()
6)即时关闭InputStream/OutputStream。
7)android系统给图片分配的内存只有8M, 图片尽量使用软引用, 较大图片可通过BitmapFactory缩放后再使用,并及时recycle
8)尽量避免static成员变量引用资源耗费过多的实例。
加载大图片的时候如何防止内存溢出
答: android系统给图片分配的内存只有8M,当加载大量图片时往往会出现OOM。
Android加载大量图片内存溢出解决方案:
使用BitmapRegionDecoder类加载高清巨图方案
最好的解决方案是局部加载,这里就涉及到BitmapRegionDecoder类
BitmapRegionDecoder提供了一系列的newInstance方法来构造对象,支持传入文件路径,文件描述符,文件的inputstrem等。
1)尽量不要使用setImageBitmap或setImageResource或BitmapFactory.decodeResource来设置一张大图,因为这些函数在完成decode后,最终都是通过java层的createBitmap来完成的,需要消耗更多内存,可以通过BitmapFactory.decodeStream方法,创建出一个bitmap,再将其设为ImageView的 source ,decodeStream最大的秘密在于其直接调用JNI
2)使用BitmapFactory.Options对图片进行压缩
InputStream is = this.getResources().openRawResource(R.drawable.pic1);
BitmapFactory.Options options=new BitmapFactory.Options();
options.inJustDecodeBounds = false;
options.inSampleSize = 10; //width,hight设为原来的十分一
Bitmap btp =BitmapFactory.decodeStream(is,null,options);
3)运用Java软引用,进行图片缓存,将需要经常加载的图片放进缓存里,避免反复加载
及时销毁不再使用的Bitmap对象
if(!bmp.isRecycle() ){
bmp.recycle() //回收图片所占的内存
system.gc() //提醒系统及时回收
}
深度优先搜索和广度优先搜索的区别
深度优先搜素算法:类似先序遍历,不全部保留结点,占用空间少;有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先搜索算法:保留全部结点,占用空间大; 无回溯操作(即无入栈、出栈操作),运行速度快。
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。
两种方法最大的区别在于前者从顶点的第一个邻接点一直访问下去再访问顶点的第二个邻接点;后者从顶点开始访问该顶点的所有邻接点再依次向下,一层一层的访问。
Java中常见的锁类型
常见的锁分类大致有:排它锁、共享锁、乐观锁、悲观锁、分段锁、自旋锁、公平锁、非公平锁、可重入锁等。
是Java多线程加锁机制,有两种:
1,Synchronized synchronized是一种互斥锁 一次只能允许一个线程进入被锁住的代码块
当方法(代码块)执行完毕后会自动释放锁,不需要做任何的操作。
当一个线程执行的代码出现异常时,其所持有的锁会自动释放。
2,显式Lock
可以简单概括一下:
Lock方式来获取锁支持中断、超时不获取、是非阻塞的
提高了语义化,哪里加锁,哪里解锁都得写出来
Lock显式锁可以给我们带来很好的灵活性,但同时我们必须手动释放锁
支持Condition条件对象
允许多个读线程同时访问共享资源
为什么wait(), notify(), notifyAll()必须要在synchronized方法/块
synchronized同步块使用了monitorenter和monitorexit指令实现同步,这两个指令,本质上都是对一个对象的监视器(monitor)进行获取,线程执行到monitorenter指令时,会尝试获取对象所对应的monitor所有权,也就是尝试获取对象的锁,而执行monitorexit,就是释放monitor的所有权。
调用wait方法,首先会获取监视器锁,获得成功以后,会让当前线程进入等待状态进入等待队列并且释放锁。
wait方法的语义有两个,一个是释放当前的对象锁、另一个是使得当前线程进入阻塞队列,而这些操作都和监视器是相关的,所以wait必须要获得一个监视器锁。
因为这三个方法都是释放锁的,如果没有synchronize先获取锁就调用会引起异常
死锁产生的4个必要条件
1、互斥:某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。
2、占有且等待:一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源。
3、不可抢占:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
4、循环等待:存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
当以上四个条件均满足,必然会造成死锁,发生死锁的进程无法进行下去,它们所持有的资源也无法释放。这样会导致CPU的吞吐量下降。所以死锁情况是会浪费系统资源和影响计算机的使用性能的。那么,解决死锁问题就是相当有必要的了。
死锁原理
根据操作系统中的定义:死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。
一、死锁的定义
所谓死锁是指多个线程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。
处理死锁的基本方法
1.预防死锁:通过设置一些限制条件,去破坏产生死锁的必要条件
2.避免死锁:在资源分配过程中,使用某种方法避免系统进入不安全的状态,从而避免发生死锁
3.检测死锁:允许死锁的发生,但是通过系统的检测之后,采取一些措施,将死锁清除掉
4.解除死锁:该方法与检测死锁配合使用
内存模型
1、虚拟机栈
2、本地方法栈
3、PC 寄存器
4、堆
5、方法区
Java的堆内存和栈内存
Java把内存划分成两种:一种是堆内存,一种是栈内存。
堆:主要用于存储实例化的对象,数组。由JVM动态分配内存空间。一个JVM只有一个堆内存,线程是可以共享数据的。
栈:主要用于存储局部变量和对象的引用变量,每个线程都会有一个独立的栈空间,所以线程之间是不共享数据的。
栈内存的更新速度要快于堆内存,因为局部变量的生命周期更短,
栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的会被垃圾回收期机制不定时的回收。
GC机制判断对象是否存活的算法:
1、引用计数算法
给对象添加一个引用计数器,当有一个地方引用它时,计数器值就加1;当引用失效时,计数器就减1;任何时候计数器都为0的对象就是不可能再被使用的。引用计数器算法(Reference Counting)实现简单,判定效率也很高,在大部分情况下他都是一个不错的算法。但是,Java语言中没有选用引用计数算法来管理内存,其中最主要的原因是他很难解决对象之间的互相循环引用的问题。
2、根搜索算法
根搜索算法(GC Roots Tracing)的基本思路是通过一系列名为“GC Roots”的对象作为起始点,从这个节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论术语描述就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。在主流的商用程序语言中(Java、C#),都是使用根搜索算法判定对象是否存活的。
常见回收算法
1、标记-清除算法:
标记阶段:先通过根节点,标记所有从根节点开始的可达对象。因此,未被标记的对象就是未被引用的垃圾对象;
清除阶段:清除所有未被标记的对象。
2、复制算法:(新生代的GC)
将原有的内存空间分为两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的存活对象复制到未使用的内存块中,然后清除正在使用的内存块中的所有对象。
3、标记-整理算法:(老年代的GC)
标记阶段:先通过根节点,标记所有从根节点开始的可达对象。因此,未被标记的对象就是未被引用的垃圾对象
整理阶段:将将所有的存活对象压缩到内存的一端;之后,清理边界外所有的空间
4、分代收集算法:
存活率低:少量对象存活,适合复制算法:在新生代中,每次GC时都发现有大批对象死去,只有少量存活(新生代中98%的对象都是“朝生夕死”),那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成GC。
存活率高:大量对象存活,适合用标记-清理/标记-整理:在老年代中,因为对象存活率高、没有额外空间对他进行分配担保,就必须使用“标记-清理”/“标记-整理”算法进行GC。
ViewModel、LiveData及Lifecycles
1、Lifecycler的原理
Lifecycler为每个活动组件添加了一个没有界面的Fragment,利用Fragment周期会根据活动声明周期变化的特性实现的特性,从而实现生命周期的感知,然后根据注解的Event查找执行相应的方法。
添加一个ReportFragment的实例
根据Fragment的每个生命周期的回调,调用dispatch()处理回调事件
Lifecycler的实现主要使用两个主要枚举来跟踪其关联组件的生命周期状态
Event:从框架和Lifecycle类派发的生命周期事件。 这些事件映射到活动和片段中的回调事件。
State:由Lifecycle对象跟踪的组件的当前状态。
2、LiveData原理:
内部保存了LifecycleOwner和Observer,利用LifecycleOwner感知并处理声明中期的变化,Observer在数据改变时遍历Observer,在数据改变时回调所有的观察者
Android程序Crash时的异常上报
https://blog.csdn.net/singwhatiwanna/article/details/17289479
android中有处理这类问题的方法,请看下面Thread类中的一个方法#setDefaultUncaughtExceptionHandler
新建一个类,比如叫CrashHandler.java实现UncaughtExceptionHandler
为ui线程添加默认异常事件Handler,我们推荐大家在Application中添加而不是在Activity中添加。Application标识着整个应用,在Android声明周期中是第一个启动的,早于任何的Activity、Service等。
当crash发生的时候,我们可以捕获到异常信息,把异常信息存储到SD卡中,然后在合适的时机通过网络将crash信息上传到服务器上,这样开发人员就可以分析用户crash的场景从而在后面的版本中修复此类crash。我们还可以在crash发生时,弹出一个通知告诉用户程序crash了,然后再退出,这样做比闪退要温和一点。
Listview条目有很多图片,如果让可见条目的图片快速加载?(面试官提示:定义任务的优先级)
发现它们都是只加载屏幕内的图片,list停止滚动时加载图片 ,停止滚动的时候//设置当前屏幕显示的起始index和结束index
优化:
1.ListView滑动停止后才加载可见项
2.滑动时,取消所有加载项
怎么通过tag来获取对应的ImageView?
通过findViewWithTag方法。
本质上是考察多线程处理策略,对线程池有以下要求,1:可以指定线程优先级,用于响应当前可见item的快速加载。2.可以动态取消线程,以便优化存储,在Fling动作发生时暂停无效item加载。3.就是手势动作优化了
Android中ListView常见优化方案
1、ViewHolder模式提高效率
Viewholder模式利用了ListView的视图缓存机制,避免了每次在调用getView的时候都去通过findViewById实例化数据。
2、耗时操作放到异步线程中
比如说:加载图片
3、item错位
由于耗时操作,而且又用到了view的复用,可能会出现item错位
解决错位方法:可以为每一个item设置一个tag
4、加载数据量大的数据
1.设置本地缓存
2.分页加载:我们不用每次把ListView所有的Item都一次性加载完毕,这样做没必要也很累。我们仅仅需要加载那部分显示在屏幕部分的Item即可,这样所要加载的数据就减少了很多
3、滑动时停止加载:当用户滑动时,显示在屏幕的Item会不断的变化,如果只是加载显示在屏幕的Item,这也没有必要,因此我们应该在停止滑动时再加载数据。
冒泡排序优化
第一种优化方式是(内层循环优化)设置一个标记位,
定义一个flag=0,用来判断有没有进行交换,如果在某次内层循环中没有交换操作,就说明此时数组已经是有序了的,不用再进行判断,这样可以节省时间
第二种 (外层循环优化)如果用一个flag来判断一下,当前数组是否已经有序,如果有序就退出循环,这样可以明显的提高冒泡排序的性能
Android的wrap_content是如何计算的
先处理wrap_content,简单说:在View类中,当该View的布局宽高值为wrap_content,或match_parent时,该View测量的最终大小就是MeasureSpec中的测量大小-->SpecSize。因此,在自定义View时,需要重写onMeasure(w,h)用来处理wrap_content的情况,然后调用setMeasuredDimession(w,h)完成测量。
当布局宽高为wrap_content时,它的测量模式specMode必然为AT_MOST。于是取出宽高的测量模式进行判断,如果布局宽高的不是wrap_content时,就按照View$onMeasure(w,h)中方式处理,也就是用父view给的建议测量大小specSize,作为最终测量大小值。重写onMeasure(w,h)后执行程序,
EventBus
关于观察者模式
EventBus是Android下高效的发布/订阅事件总线机制。是基于JVM内部的数据传输系统,其核心对象为Event和EventHandler。
简介:观察者模式是设计模式中的一种。它是为了定义对象间的一种一对多的依赖关系,即当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
在这个模式中主要包含两个重要的角色:发布者和订阅者(又称观察者)。对应EventBus来说,发布者即发送消息的一方(即调用EventBus.getDefault().post(event)的一方)
,订阅者即接收消息的一方(即调用EventBus.getDefault().register()的一方)。
,通过EventBus的静态方法getDefault来获取一个实例,getDefault本身会调用其内部的构造方法,通过传入一个默认的EventBusBuilder来创建EventBus。
获取了订阅者的class对象,然后SubscriberMethodFinder会找出所有订阅的方法。
//首先从缓存中取出subscriberMethodss,如果有则直接返回该已取得的方法
通过上面的方法把订阅方法找出来了,并保存在集合中,finduserinfo findState
unregister
//遍历所有订阅的事件
调用了EventBus#unsubscribeByEventType,把订阅者以及事件作为参数传递了进去,那么应该是解除两者的联系。
post
通过currentPostingThreadState.get()来获取PostingThreadState,currentPostingThreadState是一个ThreadLocal,而ThreadLocal是每个线程独享的,其数据别的线程是不能访问的,因此是线程安全的。我们再次回到Post()方法,继续往下走,是一个while循环,这里不断地从队列中取出事件,并且分发出去,调用的是EventBus#postSingleEvent方法。
线程切换过程(Scheduler)
RxJava最好用的特点就是提供了方便的线程切换,被观察者切换线程使用observeOn(),观察者切换线程使用subscriberOn(),可切换为多种线程,但它的原理归根结底还是lift,使用subscribeOn()的原理就是创建一个新的Observable,把它的call过程开始的执行投递到需要的线程中;而 observeOn() 则是把线程切换的逻辑放在自己创建的Subscriber中来执行。把对于最终的Subscriber1的执行过程投递到需要的线程中来进行。
subscribeOn()的线程切换发生在 OnSubscribe 中,即在它通知上一级 OnSubscribe 时,这时事件还没有开始发送,因此 subscribeOn() 的线程控制可以从事件发出的开端就造成影响;而 observeOn() 的线程切换则发生在它内建的 Subscriber 中,即发生在它即将给下一级 Subscriber 发送事件时,因此 observeOn() 控制的是它后面的线程。
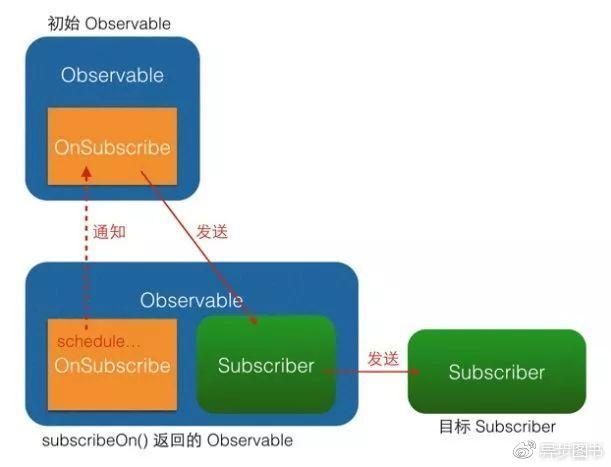
为什么 subscribeOn()只有第一个有效?
举个例子,subscribeOn2从通知开始将后面的执行全部投递到需要的线程2来执行,但是之后的投递会受到在subscribeOn2的上级subscribeOn1的的影响,subscribeOn1又会把执行投递到线程1中去,这样执行就不受到subscribeOn2的控制了。所以只有第一个subscribeOn有效。
什么是Retrofit
Retrofit是针对于Android/Java的、基于okHttp的、一种轻量级且安全的、Retrofit采用注解方式开发。通过注解构建不同的请求和请求的参数,
首先通过构造者模式获取Retrofit对象,然后通过动态代理获取到所定义的接口实例,得到实例后就可以调用接口的方法来获取Call对象最后进行网络请求操作
调用call对象的enqueue方法,并且传入Callback参数,实现onResponse方法和onFailure方法,表示请求成功和失败时候的回调。
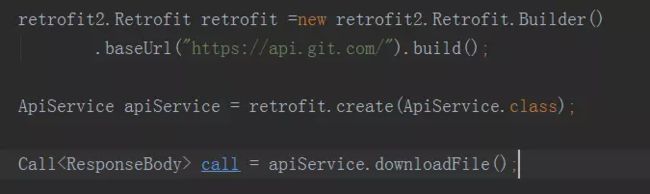
获得了这个call对象就可以开始访问网络了。Call接口提供enqueue(Callback callback)方法,其中泛型T即Call的泛型,在这里就是ResponseBody。Callback接口包含两个方法,OnResponse和onFailure,分别在请求成功和失败的时候回调。于是call调用的形式如下:
ButterKnife 原理解析
原理解析
首先得到要绑定的 Activity 对应的 Class,然后用根据 Class 得到一个继承了Unbinder的Constructor,最后通过反射constructor.newInstance(target, source)得到Unbinder子类的一个实例,
BINDINGS是一个LinkedHashMap:
缓存了对应的 Class 和 Constructor 以提高效率!
所以最终bind()方法返回的是MainActivity_ViewBinding类的实例
核心就是把findRequiredView()得到的 View 转成指定类型的 View ,如果 xml 中定义的 View 和 Activity 中通过注解绑定的 View 类型不一致,就会抛出上边方法的异常
apk的打包过程分7步:
打包流程
1、打包资源文件,生成R.java文件
2、处理aidl文件,生成相应java 文件
3、编译工程源代码,生成相应class 文件
4、转换所有class文件,生成classes.dex文件
5、打包生成apk6、对apk文件进行签名
7、对签名后的apk文件进行对齐处理
Android 异步消息处理机制 让你深入理解 Looper、Handler、Message三者关系
三者关系
1、首先Looper.prepare()在本线程中保存一个Looper实例,然后该实例中保存一个MessageQueue对象;因为Looper.prepare()在一个线程中只能调用一次,所以MessageQueue在一个线程中只会存在一个。
2、Looper.loop()会让当前线程进入一个无限循环,不端从MessageQueue的实例中读取消息,然后回调msg.target.dispatchMessage(msg)方法。
3、Handler的构造方法,会首先得到当前线程中保存的Looper实例,进而与Looper实例中的MessageQueue想关联。
4、Handler的sendMessage方法,会给msg的target赋值为handler自身,然后加入MessageQueue中。
5、在构造Handler实例时,我们会重写handleMessage方法,也就是msg.target.dispatchMessage(msg)最终调用的方法。
好了,总结完成,大家可能还会问,那么在Activity中,我们并没有显示的调用Looper.prepare()和Looper.loop()方法,为啥Handler可以成功创建呢,这是因为在Activity的启动代码中,已经在当前UI线程调用了Looper.prepare()和Looper.loop()方法。
主线程中的Looper.loop()一直无限循环为什么不会造成ANR?
造成ANR的原因一般有两种:
- 当前的事件没有机会得到处理(即主线程正在处理前一个事件,没有及时的完成或者looper被某种原因阻塞住了)
- 当前的事件正在处理,但没有及时完成
ActivityThread的main方法主要就是做消息循环,一旦退出消息循环,那么你的应用也就退出了。因为Android 的是由事件驱动的,looper.loop() 不断地接收事件、处理事件,每一个点击触摸或者说Activity的生命周期都是运行在 Looper.loop() 的控制之下,如果它停止了,应用也就停止了。只能是某一个消息或者说对消息的处理阻塞了 Looper.loop(),而不是 Looper.loop() 阻塞它。
总结:Looer.loop()方法可能会引起主线程的阻塞,但只要它的消息循环没有被阻塞,能一直处理事件就不会产生ANR异常。
Android加密算法有多种多样,常见的有MD5、RSA、AES、3DES四种。
Android加密
MD5是不可逆的加密算法,也就是无法解密,主要用于客户端的用户密码加密。
RSA算法在客户端使用公钥加密,在服务端使用私钥解密。这样一来,即使加密的公钥被泄露,没有私钥仍然无法解密。(注意:使用RSA加密之前必须在AndroidStudio的libs目录下导入bcprov-jdk的jar包)
SurfaceView和View最本质的区别在于,
surfaceView是在一个新起的单独线程中可以重新绘制画面. 而View必须在UI的主线程中更新画面。那么在UI的主线程中更新画面 可能会引发问题,比如你更新画面的时间过长,那么你的主UI线程会被你正在画的函数阻塞。那么将无法响应按键,触屏等消息。 当使用surfaceView 由于是在新的线程中更新画面所以不会阻塞你的UI主线程。但这也带来了另外一个问题,就是事件同步。比如你触屏了一下,你需要surfaceView中thread处理,一般就需要有一个event queue的设计来保存touch event,这会稍稍复杂一点,因为涉及到线程同步。
Serilizeable和Parcelable的区别?
Serializable使用IO读写存储在硬盘上,
Serializable的作用是将数据对象存入字节流当中,在需要时重新生成对象,主要应用是利用外部存储设备保存对象状态,以及通过网络传输对象等。
implements Serializable接口的的作用就是给对象打了一个标记,系统会自动将其序列化。
实现Parcelable接口
而Parcelable是直接在内存中读写,很明显内存的读写速度通常大于IO读写,所以在Android中通常优先选择Parcelable。
a、在使用内存的时候,Parcelable比Serializable性能高,所以推荐使用Parcelable类。
b、Serializable在序列化的时候会产生大量的临时变量,从而引起频繁的GC。
使用Serilizeable序列化的时候,有一个序列化id,它的作用是什么?
关于serialVersionUID最好显式定义,表明类的版本,即根据类型和成员变量生成一个64位Hash值
反序列化时就可以根据这个id校验类版本
文件断点续传的简单实现
传输开始之前发送方先向接收方发送一个确认信息,然后再向接收方发送准备发送的文件的文件名
接收方收到确认信息之后,接收从发送方发送过来的文件名,接收完之后向发送方发送一个确认信息表示文件名接收完毕,然后接收方根据收到的文件名创建一个“.temp”File对象和一个“.temp”RandomAccessFile对象。获取这个File对象所对应文件的长度(大小)(这个长度就是接收方已经接受的长度,如果之前没有接收过这个文件,长度就为0),并把文件长度发送给发送方。
发送方收到确认信息之后,接收接受方发送的文件长度,然后向接收方发送准备发送的文件的总长度,并向接收方发送一个确认信息。然后根据接收方发送的文件长度,从文件对应长度的位置开始发送。
接收方收到确认信息之后,接受发送方发送过来的数据,然后从此文件的末尾写入。接受完成之后再将“.temp”文件重命名为正常的文件名。
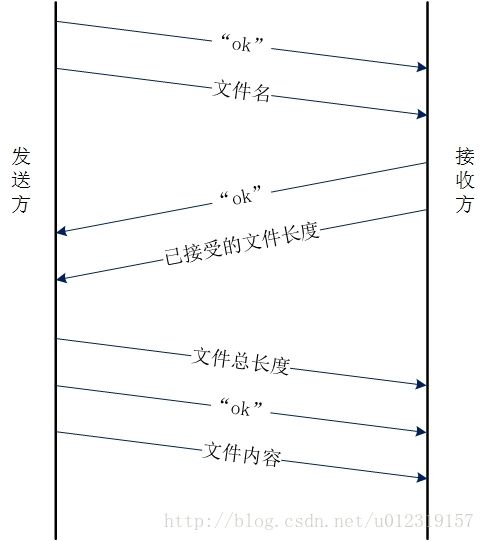
ok”表示确认信息
能够实现断点续传的关键就是使用了RandomAccessFile,此类的实例支持对随机访问文件的读取和写入。
Java通过ThreadpoolExecutors创建线程池,
总共有四类
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
newFixedThreadPool创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
。newScheduledThreadPool创建一个定长线程池,支持定时和周期性任务执行
newSingleThreadExecutor创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO,LIFO,优先级)执行。
i++和++i的线程安全分为两种情况:
1、如果i是局部变量(在方法里定义的),那么是线程安全的。因为局部变量是线程私有的,别的线程访问不到,其实也可以说没有线程安不安全之说,因为别的线程对他造不成影响。
2、如果i是全局变量(类的成员变量),那么是线程不安全的。因为如果是全局变量的话,同一进程中的不同线程都有可能访问到。
平衡二叉树,
它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1
5.0到9.0 新特性
Android 5.0(Android Lollipop)开始,android迎来了扁平化时代,使用一种新的Material Design 设计风格,设计了全新的通知中心,
Android 6.0引入了动态权限管理,指纹识别
7.0分屏多任务,新通知消息,通知消息快捷回复,夜间模式
8.0 画中画功能, 在Android 8.0“奥利奥”中,应用图标的右上角有一个小点,它代表未读通知,通知延时提醒,自动填充
9.0 刘海设计,黑白模式切换,加入长截图,允许定制主屏搜索栏,应用多开