人工神经元(Artificial Neuron),简称神经元(Neuron),是构成神经网络的基本单元,其主要是模拟生物神经元的结构和特性,接受一组输入信号并产出输出。
生物学家在 20 世纪初就发现了生物神经元的结构。一个生物神经元通常具有多个树突和一条轴突。树突用来接受信息,轴突用来发送信息。当神经元所获得的输入信号的积累超过某个阈值时,它就处于兴奋状态,产生电脉冲。轴突尾端有许多末梢可以给其他个神经元的树突产生连接(突触),并将电脉冲信号传递给其它神经元。
1943 年,心理学家 McCulloch 和数学家 Pitts 根据生物神经元的结构,提出了一种非常简单的神经元模型,MP神经元[McCulloch and Pitts, 1943]。现代神经网络中的神经元和 M-P 神经元的结构并无太多变化。不同的是,MP神经元中的激活函数 f 为 0 或 1 的阶跃函数,而现代神经元中的激活函数通常要求是连续可导的函数。
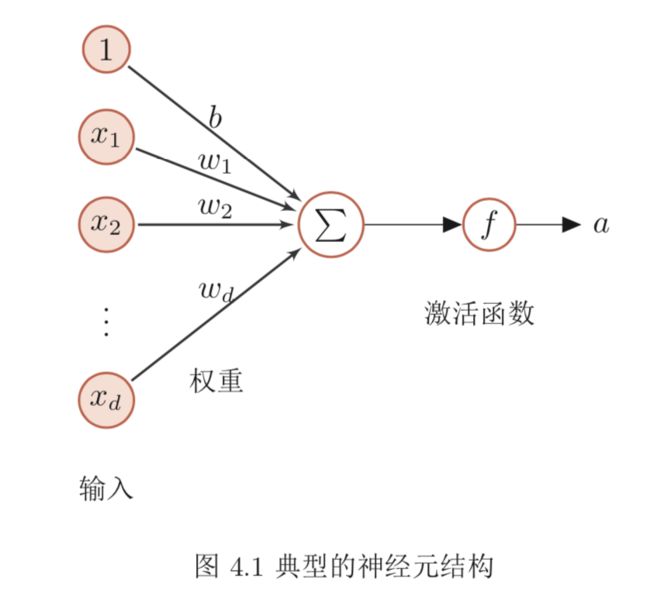
假设一个神经元接受d个输入x1, x2, · · · , xd,令向量x = [x1; x2; · · · ; xd]来表示这组输入,并用净输入(Net Input)z ∈ R表示一个神经元所获得的输入信号 x 的加权和,
其中W = [w1;w2;··· ;wd] ∈ Rd是d维的权重向量,b ∈ R是偏置。
净输入 z 在经过一个非线性函数 f (·) 后,得到神经元的活性值(Activation) a,
其中非线性函数f(·)称为激活函数(Activation Function)。
图4.1给出了一个典型的神经元结构示例。
激活函数 激活函数在神经元中非常重要的。为了增强网络的表示能力和学习能
力,激活函数需要具备以下几点性质:
- 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以 直接利用数值优化的方法来学习网络参数。
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
- 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
下面介绍几种在神经网络中常用的激活函数。
4.1.1 Sigmoid 型激活函数
Sigmoid 型函数是指一类 S 型曲线函数,为两端饱和函数。常用的 Sigmoid 型
函数有 Logistic 函数和 Tanh 函数。

Logistic函数 Logistic函数定义为
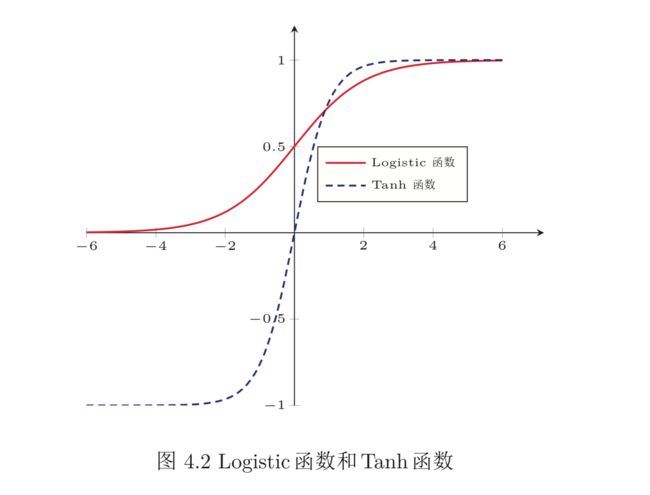
Logistic 函数可以看成是一个“挤压”函数,把一个实数域的输入“挤压”到 (0, 1)。当输入值在 0 附近时,Sigmoid 型函数近似为线性函数;当输入值靠近两端时,对输入进行抑制。输入越小,越接近于0;输入越大,越接近于1。这样的特点也和生物神经元类似,对一些输入会产生兴奋(输出为 1),对另一些输入产生抑制(输出为 0)。和感知器使用的阶跃激活函数相比,Logistic 函数是连续可导的, 其数学性质更好。
因为 Logistic 函数的性质,使得装备了 Logistic 激活函数的神经元具有以下两点性质:
- 其输出直接可以看作是概率分布,使得神经网络可以更好地和统计学习模型进行结合。
- 其可以看作是一个软性门(Soft Gate),用来控制其它神经元输出信息的数量。
Tanh函数 Tanh函数是也一种Sigmoid型函数。其定义为
Tanh 函数可以看作是放大并平移的 Logistic 函数,其值域是 (−1, 1)。
图4.2给出了Logistic函数和Tanh函数的形状。Tanh函数的输出是零中心化的(Zero-Centered),而 Logistic 函数的输出恒大于 0。非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。
4.1.1.1 Hard-Logistic 和 Hard-Tanh 函数
Logistic 函数和 Tanh 函数都是 Sigmoid 型函数,具有饱和性,但是计算开销较大。因为这两个函数都是在中间(0附近)近似线性,两端饱和。因此,这两个函数可以通过分段函数来近似。
以Logistic函数σ(x)为例,其导数为σ′(x) = σ(x)(1 − σ(x))。Logistic函数在0附近的一阶泰勒展开(Taylor expansion)为
用分段来近似 Logistic 函数,得到
同样,Tanh 函数在 0 附近的一阶泰勒展开为
这样Tanh函数也可以用分段函数hard-tanh(x)来近似。
图4.3给出了 hard-Logistic 和 hard-Tanh 函数两种函数的形状。

4.1.2 修正线性单元
修正线性单元(Rectified Linear Unit,ReLU)[Nair and Hinton, 2010],也叫
rectifier函数[Glorot et al., 2011],是目前深层神经网络中经常使用的激活函数。
ReLU 实际上是一个斜坡(ramp)函数,定义为
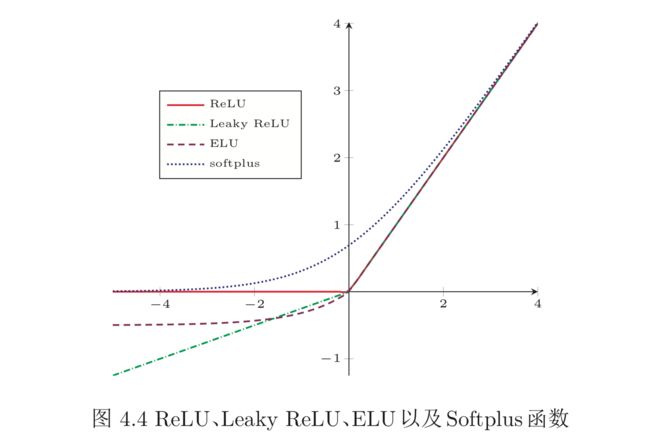
优点 采用ReLU的神经元只需要进行加、乘和比较的操作,计算上更加高效。 ReLU 函数被认为有生物上的解释性,比如单侧抑制、宽兴奋边界(即兴奋程度 也可以非常高)。在生物神经网络中,同时处于兴奋状态的神经元非常稀疏。人脑中在同一时刻大概只有1 ∼ 4%的神经元处于活跃状态。Sigmoid型激活函数会导致一个非稀疏的神经网络,而 ReLU 却具有很好的稀疏性,大约 50% 的神经元 会处于激活状态。
在优化方面,相比于 Sigmoid 型函数的两端饱和,ReLU 函数为左饱和函数, 且在x > 0时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。
缺点 ReLU函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率。此外,ReLU神经元在训练时比较容易“死亡”。在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个 ReLU 神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是 0,在以后的训练过程中永远不能被激活。这种现象称为死亡 ReLU问题(Dying ReLU Problem),并且也有可能会发生在其它隐藏层。
在实际使用中,为了避免上述情况,有几种 ReLU 的变种也会被广泛使用。
4.1.2.1 带泄露的 ReLU
带泄露的ReLU(Leaky ReLU)在输入x < 0时,保持一个很小的梯度。这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活[Maas et al., 2013]。带泄露的ReLU的定义如下:
其中 是一个很小的常数,比如 0.01。当 < 1 时,带泄露的 ReLU 也可以写为
相当于是一个比较简单的 maxout 单元。
4.1.2.2 带参数的 ReLU
带参数的ReLU(Parametric ReLU,PReLU)引入一个可学习的参数,不 同神经元可以有不同的参数[He et al., 2015]。对于第i个神经元,其PReLU的 定义为
其中γi为x ≤ 0时函数的斜率。因此,PReLU是非饱和函数。如果γi = 0,那么 PReLU 就退化为 ReLU。如果 γi 为一个很小的常数,则 PReLU 可以看作带泄露 的 ReLU。PReLU 可以允许不同神经元具有不同的参数,也可以一组神经元共享 一个参数。
4.1.2.3 ELU
指数线性单元(Exponential Linear Unit,ELU)[Clevert et al., 2015]是一个近似的零中心化的非线性函数,其定义为
其中 ≥ 0是一个超参数,决定x ≤ 0时的饱和曲线,并调整输出均值在0附近。
4.1.2.4 Softplus 函数
Softplus函数[Dugas et al., 2001]可以看作是rectifier函数的平滑版本,其 定义为
Softplus 函数其导数刚好是 Logistic 函数。Softplus函数虽然也有具有单侧抑制、
宽兴奋边界的特性,却没有稀疏激活性。
图4.4给出了ReLU、Leaky ReLU、ELU以及Softplus函数的示例。
4.1.3 Swish 函数
Swish函数是一种自门控(Self-Gated)激活函数[Ramachandran et al., 2017],定义为
其中σ(·)为Logistic函数,β为可学习的参数或一个固定超参数。σ(·) ∈ (0,1)可以看作是一种软性的门控机制。当 σ(βx) 接近于 1 时,门处于“开”状态,激活函数的输出近似于 x 本身;当 σ(βx) 接近于 0 时,门的状态为“关”,激活函数的输出近似于 0。
图4.5给出了Swish函数的示例。当β = 0时,Swish函数变成线性函数x/2。 当β = 1时,Swish函数在x > 0时近似线性,在x < 0时近似饱和,同时具有一定的非单调性。当β → +∞时,σ(βx)趋向于离散的0-1函数,Swish函数近似为 ReLU 函数。因此,Swish 函数可以看作是线性函数和 ReLU 函数之间的非线性插值函数,其程度由参数 β 控制。

4.1.4 Maxout 单元
Maxout单元[Goodfellow et al., 2013]也是一种分段线性函数。Sigmoid型函数、ReLU 等激活函数的输入是神经元的净输入 z,是一个标量。而 maxout 单元的输入是上一层神经元的全部原始输入,是一个向量 x = [x1 ; x2 ; · · · , xd ]。
每个maxout单元有K个权重向量wk ∈ Rd和偏置bk (1 ≤ k ≤ K)。对于输 入x,可以得到K个净输入zk,1 ≤ k ≤ K。
其中为第k个权重向量。
Maxout 单元的非线性函数定义为
Maxout 单元不单是净输入到输出之间的非线性映射,而是整体学习输入到 输出之间的非线性映射关系。Maxout 激活函数可以看作任意凸函数的分段线性 近似,并且在有限的点上是不可微的。