Pod 资源管理主要有两个指标:CPU Request与Memory Request。
- 在未定义指标时,K8s任务改Pod所需资源很少,所以会被调度到任意节点上。这样会导致,在内存不充足情况下,Pod负载增加,导致某些Node资源严重不足。
- K8s为了避免系统挂掉,通过清理某些Pod来,维持系统平衡。通过一些规则来清理Pod:
◎ 通过资源限额来确保不同的Pod只能占用指定的资源。
◎ 允许集群的资源被超额分配,以提高集群的资源利用率。
◎ 为Pod划分等级,确保不同等级的Pod有不同的服务质量(QoS),资源不足时,低等级的Pod会被清理,以确保高等级的Pod稳定运行。
资源限制确保Pod占用资源,允许超额分配资源,通过Qos,清理低等级Pod。
- 计算资源,主要从CPU和Memory角度,配置包括request和limit。
- 如果只配置CPU或者Memory之一,那么Pod会处于不稳定状态,可能会出现超用现象。如果四个都配置,会相对稳定一些。所以需要Qos进行管理。
- 其次,我们还需要检查,配置是否合理,同时还得手工检查不同租户(Namespace)下的Pod的资源使用量是否超过限额。Kubernetes提供了另外两个相关对象:LimitRange及ResourceQuota,前者解决request与limit参数的默认值和合法取值范围等问题,后者则解决约束租户的资源配额问题。
10.4.1 计算资源管理
1.详解Requests和Limits参数
Pod的Requests或Limits是指该Pod中所有容器的Requests或Limits的总和(对于Pod中没有设置Requests或Limits的容器,该项的值被当作0或者按照集群配置的默认值来计算)。
(1). CPU
CPU的资源值是绝对值,而不是相对值,比如0.1CPU在单核或多核机器上是一样的,都严格等于0.1 CPU core。
(2).Memory
Kubernetes的计算资源单位是大小写敏感的。
内存的Requests和Limits计量单位是字节数。使用整数或者定点整数加上国际单位制(InternationalSystem of Units)来表示内存值。国际单位制包括十进制的E、P、T、G、M、K、m,或二进制的Ei、Pi、Ti、Gi、Mi、Ki。KiB与MiB是以二进制表示的字节单位,常见的KB与MB则是以十进制表示的字节单位,比如:
◎ 1 KB(KiloByte)= 1000 Bytes = 8000 Bits;
◎ 1 KiB(KibiByte)= 210Bytes = 1024 Bytes = 8192 Bits。因此,128974848、129e6、129M、123Mi的内存配置是一样的。
2.基于Requests和Limits的Pod调度机制
- 调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值。
- 可能某节点上的实际资源使用量非常低,但是已运行Pod配置的Requests值的总和非常高,再加上需要调度的Pod的Requests值,会超过该节点提供给Pod的资源容量上限,这时Kubernetes仍然不会将Pod调度到该节点上。如果Kubernetes将Pod调度到该节点上,之后该节点上运行的Pod又面临服务峰值等情况,就可能导致Pod资源短缺。
3.Requests和Limits的背后机制
kubelet在启动Pod的某个容器时,会将容器的Requests和Limits值转化为相应的容器启动参数传递给容器执行器(Docker或者rkt)。
如果是docker 容器:
a.spec.container[].resources.requests.cpu: 会转化为docker 的--cpu-share
b. spec.container[].resources.limits.cpu: 会转为docker的--cpu-quota
c. spec.container[].resources.requests.memory: 这个参数值只提供给Kubernetes调度器作为调度和管理的依据,不会作为任何参数传递给Docker。
d. spec.container[].resources.limits.memory: 会转为--memory
4.计算资源使用情况监控
apiVersion: v1
kind: LimitRange
metadata:
name: mylimits
spec:
limits:
- type: Pod # pod 的max、min、maxLimitRequestRatio
max:
cpu: "4"
memory: 2Gi
min:
cpu: 200m
memory: 6Mi
maxLimitRequestRatio:
cpu: "3"
memory: "2"
- type: Container #container 级别的default、defaultRequest、max、min、maxLimitRequestRatio
default:
cpu: 300m
memory: 200Mi
defaultRequest:
cpu: 200m
memory: 100Mi
max:
cpu: "2"
memory: 1Gi
min:
cpu: 100m
memory: 3Mi
maxLimitRequestRatio:
cpu: "5"
memory: "4"
#创建方式
kubectl create -f --namespace=
a. container 的参数:
max、min: 指的是单个container 的最大值和最小值限制
maxLimitRequestRatio: 指的是MaxLimit/Requests Ratio的比值。
可以设置Default Request和Default Limit参数,值得是默认Pod中所有未指定Request/Limits值的容器的默认Request/Limits值。
Min ≤ Default Request ≤ Default Limit ≤Max。
b. Pod 参数:
max、min: 指的是Pod中所有容器的Requests值的总和最大值和最小值。
maxLimitRequestRatio:Pod中所有容器的Limits值总和与Requests值总和的比例上限。
Pod不能设置Default Request和Default Limit参数。
注意:
a.Container 设置了max ,容器必须设置limits。Pod内容器未设置Limits,将使用Default Limit,如果也未设置Default,则无法成功创建。
设置了max,那么容器需要limits > DefaultsLimits > 无法成功创建。
b. Container 设置了Min,集群中容器必须设置Requests,如果未设置Request,将使用defaultRequest,如果也为配置DefaultRequest,会默认等于该容器的Limits,如果Limits也未定义,就会报错。
设置了min, 那么 需要Requests > DefaultRequest> Limits > 报错。依次使用字段。
c. Pod里任何容器的Limits与Requests的比例都不能超过Container的Max Limit/RequestsRatio;Pod里所有容器的Limits总和与Requests的总和的比例不能超过Pod的Max Limit/RequestsRatio。
执行效果
- 命名空间中LimitRange只会在Pod创建或者更新时执行检查。如果手动修改LimitRange为一个新的值,那么这个新的值不会去检查或限制之前已经在该命名空间中创建好的Pod。
- 如果在创建Pod时配置的资源值(CPU或者内存)超过了LimitRange的限制,那么该创建过程会报错,在错误信息中会说明详细的错误原因。
10.4.3 资源服务质量管理(Resource QoS)
Kubernetes是根据Pod的Requests和Limits配置来实现针对Pod的不同级别的资源服务质量控制(QoS)。
Requests是Kubernetes调度时能为容器提供的完全可保障的资源量(最低保障),而Limits是系统允许容器运行时可能使用的资源量的上限(最高上限)。
a. Pod 的Requests 等于 limits ===> 完全可靠
b. Pod的Requests值小于Limits值: 两部分资源
◎ 完全可靠的资源,资源量的大小等于Requests值;
◎ 不可靠的资源,资源量最大等于Limits与Requests的差额,这份不可靠的资源能够申请到多少,取决于当时主机上容器可用资源的余量。
通过这种机制,Kubernetes可以实现节点资源的超售(Over Subscription)
超售机制能有效提高资源的利用率,同时不会影响容器申请的完全可靠资源的可靠性。
1.Requests和Limits对不同计算资源类型的限制机制
根据前面的内容可知,容器的资源配置满足以下两个条件:
◎ Requests<=节点可用资源;
◎ Requests<=Limits。
Kubernetes根据Pod配置的Requests值来调度Pod,Pod在成功调度之后会得到Requests值定义的资源来运行;而如果Pod所在机器上的资源有空余,则Pod可以申请更多的资源,最多不能超过Limits的值。
Requests和Limits针对不同计算资源类型的限制机制的差异。这种差异主要取决于计算资源类型是可压缩资源还是不可压缩资源。
1)可压缩资源
目前支持的可压缩资源是CPU。
- a. Pod能获取配置的CPU的Request值,但实际能否超过Requests取决于系统负载和调度。目前只支持Container级别的CPU隔离,Pod级别的隔离还不支持。
- b.空闲CPU资源按照容器Requests值的比例分配。
- c. 如果Pod使用了超过在Limits 10中配置的CPU用量,那么cgroups会对Pod中的容器的CPU使用进行限流(Throttled);如果Pod没有配置Limits 10,那么Pod会尝试抢占所有空闲的CPU资源(Kubernetes从1.2版本开始默认开启--cpu-cfs-quota,因此在默认情况下必须配置Limits)。
2)不可压缩资源
目前支持的是Memory
几种情况:
- a. Pod 内存< Reuest, Pod可以正常运行(除非出现操作系统级别内存不足)
- b. Pod 内存< Request ,Pod可能被K8s杀掉。
b1: Request- c. Pod 内存> Limit,操作系统内核会杀掉Pod所有容器的所有进程中内存最多的一个,知道内存不超过limits为止。
2.对调度策略的影响
◎ Kubernetes的kubelet通过计算Pod中所有容器的Requests的总和来决定对Pod的调度。
◎ 不管是CPU还是内存,Kubernetes调度器和kubelet都会确保节点上所有Pod的Requests的总和不会超过在该节点上可分配给容器使用的资源容量上限。
3.服务质量等级(QoS Classes)
在一个超用(Over Committed,容器Limits总和大于系统容量上限)系统中,由于容器负载的波动可能导致操作系统的资源不足,最终可能导致部分容器被杀掉。在这种情况下,我们当然会希望优先杀掉那些不太重要的容器,那么如何衡量重要程度呢?
Kubernetes将容器划分成3个QoS等级:Guaranteed(完全可靠的)、Burstable(弹性波动、较可靠的)和BestEffort(尽力而为、不太可靠的),这三种优先级依次递减。
| QoS | 特点 | 备注 |
|---|---|---|
| Guaranteed(完全可靠的) | Pod中所有容器的所有资源的Request、Limits 均设置,并且Request=limits,且不为0 | 只定义limits,默认request值为limits |
| Burstable(弹性波动、较可靠的) | 两种, 1. request 小于limits 2. Pod中部分中期未定义资源。 注意:在容器未定义Limits时,Limits值默认等于节点资源容量的上限。 |
|
| BestEffort(尽力而为、不太可靠的) | Pod中所有容器都未定义资源配置(Requests和Limits都未定义) |
Kubernetes QoS的工作特点
CPU是可以压缩资源,所以在CPU不够的时候会压缩限流。
内存是不可压缩资源,所以QoS主要用于内存限制。
a. BestEffort, 优先级最低,内存不足时最先被杀掉,内存充足时由于没有设置资源limits,可以充分使用资源。
b. Burstable, 优先级适中,这类Pod初始时会分配较少的可靠资源,但可以按需申请更多的资源。在没有BestEffort时,资源不足情况下会被杀掉。
c. Guaranteed Pod的优先级最高,而且一般情况下这类Pod只要不超过其资源Limits的限制就不会被杀掉。当然,如果整个系统内存紧缺,又没有其他更低优先级的容器可以被杀掉以释放资源,那么这类Pod中的进程也可能会被杀掉。
OOM计分系统

oom_killer首先终止QoS等级最低,且超过请求资源最多的容器。这意味着与burstable或BestEffort QoS类别的容器相比,具有更好QoS类别(如“Guaranteed”)的容器被杀死的可能性更低。
但是,并非所有情况都如此。由于oom_killer还考虑了内存使用量与请求的关系,因此,由于内存使用量过多,具有更好QoS类的容器可能具有更高的oom_score,因此可能首先被杀死。
QoS的演进
(1)内存Swap的支持。当前的QoS策略都是假定主机不启用内存Swap。如果主机启用了Swap,那么上面的QoS策略可能会失效。举例说明:两个Guaranteed Pod都刚好达到了内存Limits,那么由于内存Swap机制,它们还可以继续申请使用更多的内存。如果Swap空间不足,最终这两个Pod中的进程就可能会被杀掉。由于Kubernetes和Docker尚不支持内存Swap空间的隔离机制,所以这一功能暂时还未实现。
(2)更丰富的QoS策略。当前的QoS策略都是基于Pod的资源配置(Requests和Limits)来定义的,而资源配置本身又承担着对Pod资源管理和限制的功能。两种不同维度的功能使用同一个参数来配置,可能会导致某些复杂需求无法满足,比如当前Kubernetes无法支持弹性的、高优先级的Pod。自定义QoS优先级能提供更大的灵活性,完美地实现各类需求,但同时会引入更高的复杂性,而且过于灵活的设置会给予用户过高的权限,对系统管理也提出了更大的挑战。
10.4.4 资源配额管理(Resource Quotas)
- 如果一个Kubernetes集群被多个用户或者多个团队共享,就需要考虑资源公平使用的问题,因为某个用户可能会使用超过基于公平原则分配给其的资源量。
- 通过ResourceQuota对象,我们可以定义资源配额,这个资源配额可以为每个命名空间都提供一个总体的资源使用的限制:它可以限制命名空间中某种类型的对象的总数目上限,也可以设置命名空间中Pod可以使用的计算资源的总上限。
解决不同命名空间总体资源限制
典型的资源配额使用方式如下。
◎ 不同的团队工作在不同的命名空间下,目前这是非约束性的,在未来的版本中可能会通过ACL(Access Control List,访问控制列表)来实现强制性约束。
◎ 集群管理员为集群中的每个命名空间都创建一个或者多个资源配额项。
◎ 当用户在命名空间中使用资源(创建Pod或者Service等)时,Kubernetes的配额系统会统计、监控和检查资源用量,以确保使用的资源用量没有超过资源配额的配置。
◎ 如果在创建或者更新应用时资源使用超过了某项资源配额的限制,那么创建或者更新的请求会报错(HTTP 403 Forbidden),并给出详细的出错原因说明。
◎ 如果命名空间中的计算资源(CPU和内存)的资源配额启用,那么用户必须为相应的资源类型设置Requests或Limits;否则配额系统可能会直接拒绝Pod的创建。这里可以使用LimitRange机制来为没有配置资源的Pod提供默认资源配置。
在使用资源配额时,需要注意以下两点。
◎ 如果集群中总的可用资源小于各命名空间中资源配额的总和,那么可能会导致资源竞争。资源竞争时,Kubernetes系统会遵循先到先得的原则。
◎ 不管是资源竞争还是配额的修改,都不会影响已经创建的资源使用对象。
1.在Master中开启资源配额选型
资源配额可以通过在kube-apiserver的--admission-control参数值中添加ResourceQuota参数进行开启。如果在某个命名空间的定义中存在ResourceQuota,那么对于该命名空间而言,资源配额就是开启的。一个命名空间可以有多个ResourceQuota配置项。
1)计算资源配额(Compute Resource Quota)
资源配额可以限制一个命名空间中所有Pod的计算资源的总和。
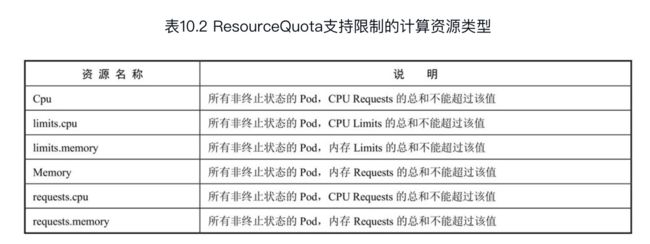
2)存储资源配额(Volume Count Quota)
可以在给定的命名空间中限制所使用的存储资源(Storage Resources)的总量
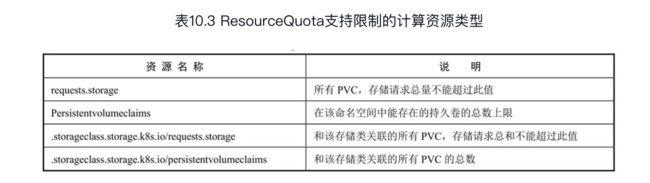
3)对象数量配额(Object Count Quota)
指定类型的对象数量可以被限制
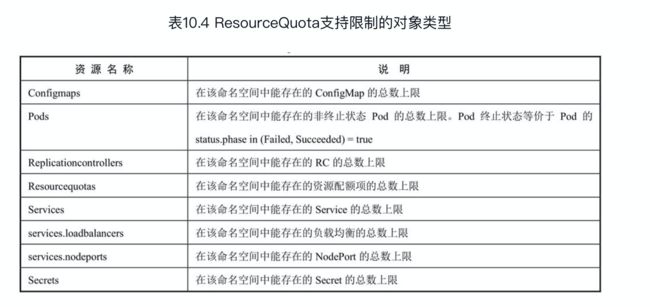
例如,我们可以通过资源配额来限制在命名空间中能创建的Pod的最大数量。这种设置可以防止某些用户大量创建Pod而迅速耗尽整个集群的Pod IP和计算资源。
2.配额的作用域(Quota Scopes)

其中,BestEffort作用域可以限定资源配额来追踪pods资源的使用,Terminating、NotTerminating和NotBestEffort这三种作用域可以限定资源配额来追踪以下资源的使用。
◎ cpu
◎ limits.cpu
◎ limits.memory
◎ memory
◎ pods
◎ requests.cpu
◎ requests.memory
3.在资源配额(ResourceQuota)中设置Requests和Limits
资源配额也可以设置Requests和Limits。
如果在资源配额中指定了requests.cpu或requests.memory,那么它会强制要求每个容器都配置自己的CPU Requests或CPU Limits(可使用LimitRange提供的默认值)。
同理,如果在资源配额中指定了limits.cpu或limits.memory,那么它也会强制要求每个容器都配置自己的内存Requests或内存Limits(可使用LimitRange提供的默认值)。
4.资源配额的定义

kubectl get create compute-resources.yaml --namespace=myspace
kubectl describe quota compute-resources.yaml --namespace=myspace
2.资源配额与集群资源总量的关系
2.资源配额与集群资源总量的关系资源配额与集群资源总量是完全独立的。资源配额是通过绝对的单位来配置的,这也就意味着如果在集群中新添加了节点,那么资源配额不会自动更新,而该资源配额所对应的命名空间中的对象也不能自动增加资源上限。在某些情况下,我们可能希望资源配额支持更复杂的策略,如下所述。
◎ 对于不同的租户,按照比例划分整个集群的资源。
◎ 允许每个租户都能按照需要来提高资源用量,但是有一个较宽容的限制,以防止意外的资源耗尽情况发生。
◎ 探测某个命名空间的需求,添加物理节点并扩大资源配额值。这些策略可以通过将资源配额作为一个控制模块、手动编写一个控制器来监控资源使用情况,并调整命名空间上的资源配额来实现。资源配额将整个集群中的资源总量做了一个静态划分,但它并没有对集群中的节点做任何限制:不同命名空间中的Pod仍然可以运行在同一个节点上。
举例:
需要实现的功能如下。
◎ 限制运行状态的Pod的计算资源用量。
◎ 限制持久存储卷的数量以控制对存储的访问。
◎ 限制负载均衡器的数量以控制成本。
◎ 防止滥用网络端口这类稀缺资源。
◎ 提供默认的计算资源Requests以便于系统做出更优化的调度。