一、基础知识
PCM(pulse code modulation) ,即脉冲编码调制,是将模拟信号转为数字信号的一种编码系统。而模数转换主要分两步,首先对连续的模拟信号进行采样,然后把采样得到的数据转化为数值,即量化。
设x xx为输入信号,F ( x ) F(x)F(x)为量化后的信号,则F ( x ) F(x)F(x)既可以是线性的,也可以是非线性的。在audioop中,主要提供三种编码支持,分别是a-Law,μ-Law以及ADPCM。

在中国和欧洲主要实用的编码方式为A-Law,其表达式为:
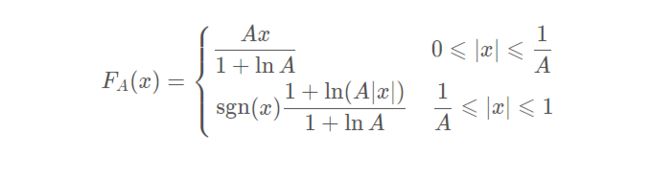
其中A AA为压缩系数,在G.726标准中建议87.56。
ADPCM(Adaptive Differential PCM),即自适应差分PCM。
由于模拟信号的连续性,一般来说相邻时间单位的信号往往具有较高的线性度,甚至彼此相差无几,从而可以被高效率的压缩。然而,也存在跳跃幅度较大的信号,如果完全以缓变为原则,那么必然会丢失这部分数据。为了均衡这种差异,就需要进行自适应量化。
audioop中支持的Intel/DVI ADPCM算法可以在网上找到,但是信息并不多而且都很老旧,貌似不太重要的样子,甚至知网都搜不到,所以这里就不详细解读了。
二、转换函数
audioop提供了ADPCM、A-Law和μ-Law和线性采样之间的转换函数
| 采样 | ADPCM | A-Law | μ-Law |
|---|---|---|---|
| lin2lin | lin2adpcm | lin2alaw | lin2ulaw |
| adpcm2lin | alaw2lin | ulaw2lin |
其中,与A-Law和μ-Law有关的转换函数的输入参数为(fragment, width),分别代表待处理片段和位宽;adpcm则会多一个state元组作为第三个参数,表示编码器状态。
lin2lin是将线性片段在1、2、3 和 4 字节格式之间转换的函数,其输入参数为(fragment, width, newwidth)。
下面新建一些数据来测试一下编码转换函数,
#下面代码来自于test_audioop.py
import audioop
import sys
import unittest
pack = lambda width, data :b''.join(
v.to_bytes(width, sys.byteorder, signed=True) for v in data)
packs = {w: (lambda *data, width=w: pack(width, data)) for w in (1, 2, 3, 4)}
unpack = lambda width, data: [int.from_bytes(
data[i: i + width], sys.byteorder, signed=True)
for i in range(0, len(data), width)]
datas = {
1: b'\x00\x12\x45\xbb\x7f\x80\xff',
2: packs[2](0, 0x1234, 0x4567, -0x4567, 0x7fff, -0x8000, -1),
3: packs[3](0, 0x123456, 0x456789, -0x456789, 0x7fffff, -0x800000, -1),
4: packs[4](0, 0x12345678, 0x456789ab, -0x456789ab,
0x7fffffff, -0x80000000, -1),
}
则datas的值为:
>>> for key in datas : print(datas[key])
...
b'\x00\x12E\xbb\x7f\x80\xff'
b'\x00\x004\x12gE\x99\xba\xff\x7f\x00\x80\xff\xff'
b'\x00\x00\x00V4\x12\x89gEw\x98\xba\xff\xff\x7f\x00\x00\x80\xff\xff\xff'
b'\x00\x00\x00\x00xV4\x12\xab\x89gEUv\x98\xba\xff\xff\xff\x7f\x00\x00\x00\x80\xff\xff\xff\xff'
>
则其转换函数测试如下:
>>> datas[1]
b'\x00\x12E\xbb\x7f\x80\xff' #将要处理的1位线性码
>>> unpack(1,datas[1])
[0, 18, 69, -69, 127, -128, -1] #转为整型
# 将1字节线性码转为2字节线性码
>>> datas1_2 = audioop.lin2lin(datas[1], 1, 2)
>>> print(datas1_2)
b'\x00\x00\x00\x12\x00E\x00\xbb\x00\x7f\x00\x80\x00\xff'
>>> unpack(2,datas1_2) #转为整型,其值为datas[1]*256
[0, 4608, 17664, -17664, 32512, -32768, -256]
# 将1字节线性码转为1字节u-Law码
>>> datas1_u = audioop.lin2ulaw(datas[1], 1)
>>> unpack(1,datas1_u) #转为整型,这个数和u-law的公式对不上,可能是其他算法
[-1, -83, -114, 14, -128, 0, 103]
三、片段特征函数
下表中函数的输入为(fragment, width),分别代表待统计片段和位宽。
| 返回值 | |
|---|---|
| avg | 片段采样值的均值 |
| avgpp | 片段采样值的平均峰峰值 |
| max | 片段采样值的最大绝对值 |
| maxpp | 声音片段中的最大峰峰值 |
| minmax | 由片段采样值中最小和最大值组成的元组 |
| rms | 片段的均方根 |
| cross | 片段穿越零点的次数 |
getsample(fragment, width, index),顾名思义用于采样,返回段中采样值索引index的值。
findfactor(fragment, reference),返回一个系数F使得rms(add(fragment, mul(reference, -F)))最小,即返回的系数乘以reference后与fragment最匹配。两个片段都应包含 2 字节宽的采样。
findfit(fragment, reference),尽可能尝试让 reference 匹配 fragment 的一部分。
findmax(fragment, length),在fragment中搜索所有长度为length的采样切片中,能量最大的那一个切片,即返回 i 使得 rms(fragment[i*2:(i+length)*2]) 最大。
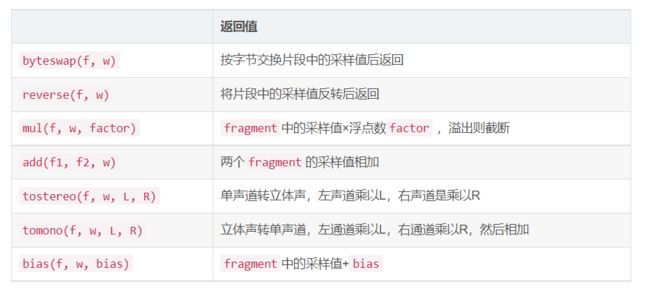
四、片段操作
其返回值均为片段,下表的参数中,f表示fragment,w表示width,L表示lfactor,R表示rfactor
audioop.ratecv(f, w, nchannels, inrate, outrate, state[, weightA[, weightB]])
可用于转换输入片段的帧速率,其中
- state为元组,表示转换器状态
- weightA和weightB是简单数字滤波器的参数,默认为 1 和 0。
到此这篇关于如何利用python处理原始音频数据的文章就介绍到这了,更多相关利用python处理原始音频数据内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!