Python正则表达式总结
1,正则表达式是用来简洁表述一组字符串的表达式,开头导入re库 import re
2,正则表达式常用操作符
 ,
,

3,


4,re的match对象
match对象是一次匹配的结果,包含匹配的很多信息



5,Re库的贪婪匹配和最小匹配
Re库默认采用贪婪匹配,即匹配最长字串

最小匹配 后面加?
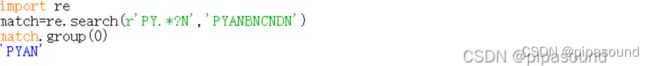
实例1,淘宝商品比价定向爬虫
import re
import requests
def gethtmltext(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
def parsepage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
# eval()除去单双引号
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printgoodlist(ilt):
tplt = "{:4}\t{:8}\t{:16}"
# 限制长度
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count+1
print(tplt.format(count, g[0], g[1]))
def main():
depth = 2
goods = '书包'
start_url = 'https://s.taobao.com/search?q='+goods
infolist = []
for i in range(depth):
try:
url = start_url+'$s='+str(44*i)
html = gethtmltext(url)
parsepage(infolist, html)
except:
continue
printgoodlist(infolist)
main()
匹配Email地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配腾讯QQ号:[1-9][0-9]{4,}
匹配日期,只能是 2004-10-22 格式:^\d{4}\-\d{1,2}-\d{1,2}$
匹配国内电话号码:^\d{3}-\d{8}|\d{4}-\d{7,8}$
评注:匹配形式如 010-12345678 或 0571-12345678 或 0831-1234567
匹配中国邮政编码:^[1-9]\d{5}(?!\d)$
匹配身份证:\d{14}(\d{4}|(\d{3}[xX])|\d{1})
匹配中文字符:[\x80-\xff]+ 或者 [\xa1-\xff]+
只能输入汉字:^[\x80-\xff],{0,}$
匹配网址 URL :[a-zA-z]+://[^\s]*
匹配 IP 地址:
((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)
匹配完整域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
只能输入至少n位数字:^\d{n,}$
以上内容转载
实例2,股票数据定向爬虫
import re
from bs4 import BeautifulSoup
import requests
import traceback
def gethtmltext(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
def getstocklist(lst,stockurl):
html=gethtmltext(stockurl)
# 解析a标签
soup=BeautifulSoup(html,'html.parser')# html.parser是html解析器,使代码能看懂
a=soup.find_all('a')
for i in a:
try:
href=i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}",href[0]))
except:
continue
def getstockinfo(lst,stockurl,fpath):
for stock in lst:
url=stockurl+stock+".html"
html=gethtmltext(url)
try:
if html=="":
continue
infodict={}
soup=BeautifulSoup(html,'html.parser')
stockinfo=soup.find('div',attrs={'class':'stock-bets'})
name=stockinfo.find_all(attrs={'class':'bets-name'})[0]
infodict.update({'股票名称':name.text.split()[0]})
keylist=stockinfo.find_all('dt')
valuelist=stockinfo.find_all('dd')
for i in range(len(keylist)):
key=keylist[i].text
val=valuelist[i].text
infodict[key]=val
with open(fpath,'a',encoding='utf-8') as f:
f.write(str(infodict)+'\n')
except:
traceback.print_exc()
continue
def main():
# 获取股票链接的主体部分
stock_list_url='http://quote.eastmoney.com/stocklist.html'
stock_info_url="https://gupiao.baidu.com/stock/"
output_file='D://BaiduStockInfo.txt'
# 股票信息
slist=[]
getstocklist(slist,stock_list_url)
getstockinfo(slist,stock_info_url,output_file)
main()