大师兄的Python学习笔记(二十七): 爬虫(八)
大师兄的Python学习笔记(二十九): 爬虫(十)
十、Pyspider框架
- Pyspider是由国人binux编写的强大网络爬虫框架。
- 点击查看Pyspider官方文档。
1. 安装Pyspider
- 可以直接通过
pip install pyspider安装。 - 安装后,使用
pyspider all启动验证安装结果。 -
如果发生async=True错误,则是因为你的Python版本高于3.7,在3.7后async成为关键字。
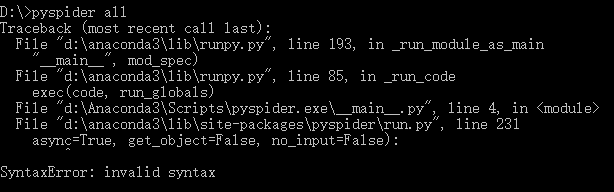
-
解决办法是将以下三个文件中的async关键字替换为其他变量
Lib\site-packages\pyspider\run.py
Lib\site-packages\pyspider\webui\app.py
Lib\site-packages\pyspider\fetcher\tornado_fetcher.py
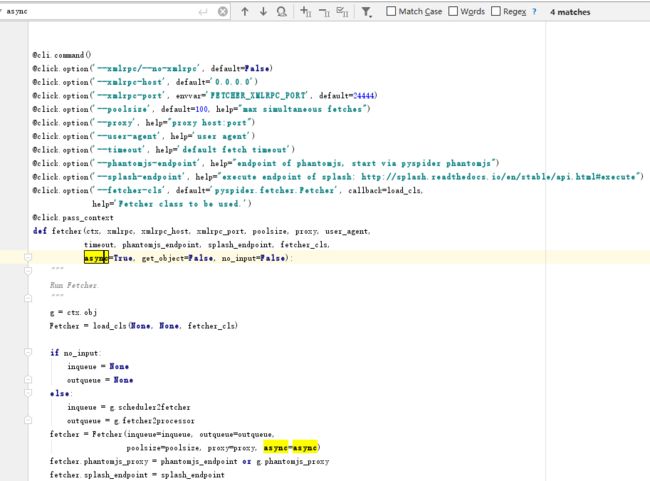

- 如果发生
- Deprecated option 'domaincontroller': use 'http_authenticator.domain_controller' instead.错误,则修改Lib\site-packages\pyspider\webui\webdav.py文件.
将'domaincontroller': NeedAuthController(app),
修改为
'http_authenticator': {
'HTTPAuthenticator': NeedAuthController(app),
},
再使用python -m pip install wsgidav==2.4.1指令将wsgidav版本降为2.4.1
- 如果发生
phantomjs not found, continue running without it.错误,则下载phantomjs.exe并和python.exe放到同一个文件夹下。 -
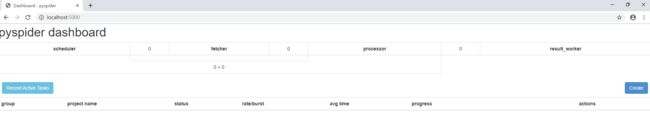
如果一切顺利,则启动一个web服务。

-
浏览器打开本地5000端口,如果打开Pyspider webUI页面,则表示安装成功。
2. Pyspider的基本功能
- 方便易用的WebUI系统,能够可视化地编写和调试爬虫。
- 能够监控爬取进度、查看爬取结果、管理爬虫项目等。
- 支持多种数据库。
- 支持多种消息队列。
- 具备优先级控制、失败重试、定时爬取等功能。
- 对接了PhantomJs,可以抓取js渲染的页面。
- 支持淡季和分布式部署,支持docker部署。
3. 与Scrapy对比
| 维度 | Pyspider | Scrapy |
|---|---|---|
| 可视化 | 支持WebUI | 源生不具备WebUI,需要对接Prtia实现。 |
| 调试 | 使用WebUI调试,非常方便 | 使用parse命令调试,相对复杂 |
| JS页面采集 | 支持PhantomJs进行Js渲染页面的采集 | 需要对接Scrapy-Splash组件 |
| 选择器 | 内置了pyquery选择器 | 对接了Xpath、css选择器以及正则匹配 |
| 扩展度 | 可扩展程度低 | 可以通过对接Middleware、Pipeline、Extension等组件实现非常强大的功能 |
- 如果快速实现一个页面的抓取使用Pyspider,如果应对大规模抓取或爬程度强的页面使用Scrapy。
4. Pyspider的架构
- Pyspider的架构主要分为Scheduler(调度器)、Fetcher(抓取器)和Processer(处理器)三个部分。
-
爬取过程受Monitor(监控器)监控,抓取结果被Result Worker(结果处理器)处理。
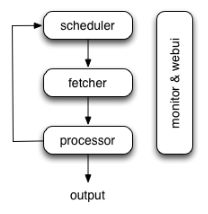
| 组件 | 功能 |
|---|---|
| Scheduler | - 判断是新任务还是需要重新爬取。 - 任务进行优先级分类 - 将任务发送给fetcher - 从processor返回的新任务队列中接收任务 - 处理周期任务,丢失的任务和失败的任务,并且稍后重试。 |
| Fetcher | - 获取web页面 - 将页面发给Processor |
| Processer | - 捕捉异常和记录日志 - 运行脚本解析和提取信息 - 发送状态和新任务给Scheduler - 发送结果给Result Worker |
| Result Worker | - 从Porcess接收结果数据 - 将数据保存到resultdb - 根据需要处理结果 |
| Monitor&Webui | 监控过程并提供webUI界面 |
5. Pyspider的工作流程
第一步:
调用Handler类的on_start()方法生成最初任务,并发送给Scheduler调度。
第二步:
Scheduler将任务发给Fetcher抓取内容,并将内容发给Processer。
第三步:
Processer处理响应并提取出新的URL生成新的抓取任务。
Processer通过消息队列通知Scheduler当前抓取任务的执行情况。
Processer将新的抓取人物发送给Scheduler。
Processer将新的提取结果发给Result Worker处理。
第四步:
Scheduler接收新的抓取任务,查询数据库判断是抓取任务还是重试任务,并发送Fetcher。
不断重复以上内容,知道所有任务执行完毕,抓取结束。
第五步:
回调on_finished()方法,这里可以定义后处理过程。
6. Pyspider的使用
- 以从爬取豆瓣影视区为例。
6.1 启动pyspider
- 命令行输入
pyspider all,启动PhantomJs、ResultWorker、Processer、Fetcher、Scheduler和WebUI。
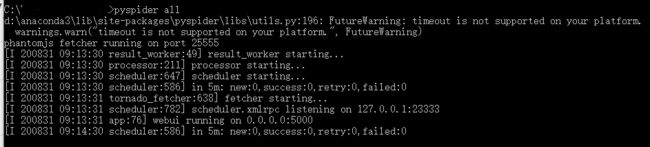
- 浏览器输入地址
http:localhost:port,打开WebUI。

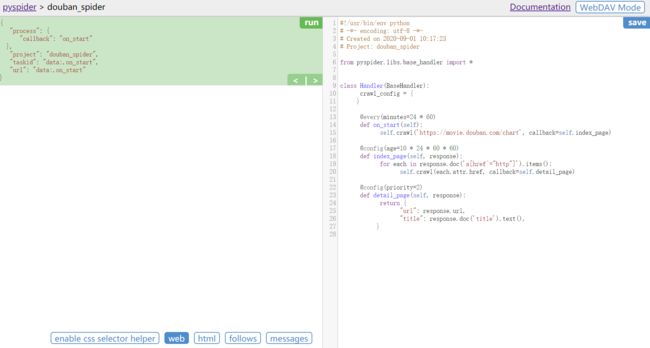
6.2 创建新项目
-
在WebUI创建一个新项目。

-
进入编辑和调试页面,并生成一段代码。
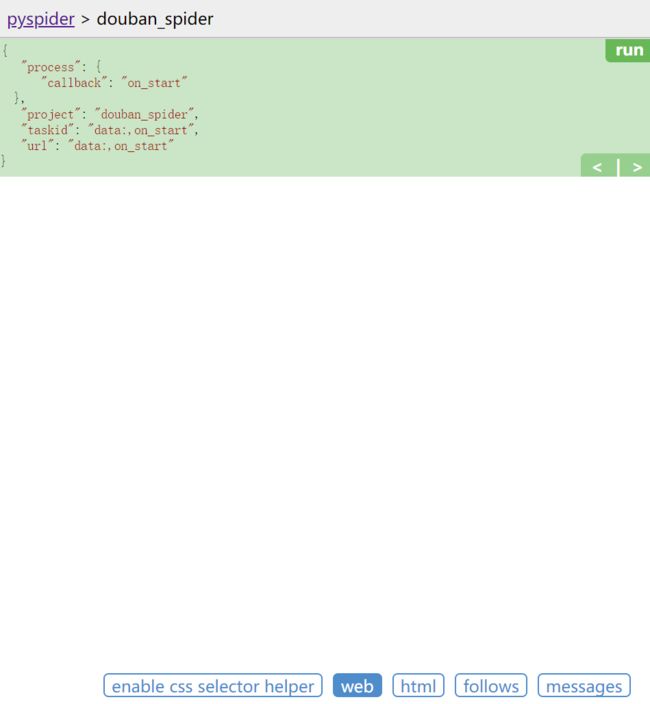
- 编辑页面的左侧是代码的调试页面,左上角的
run可以单步调试爬虫,下方可以预览网页。
-
编辑页面的右侧是代码的编辑页,可以在IDE中写完了再黏贴过来。
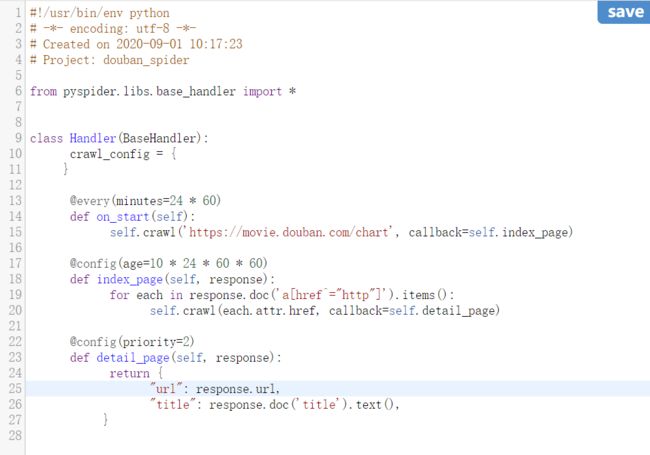
Handler(BaseHandler)是爬虫的主类,可以定义爬取、解析、存储的逻辑。crawl_config用于爬虫的全局配置。on_start()是爬取的入口,调用crawl()方法创建爬取请求,如果爬取成功,则将Response交给index_page()解析。index_page()接收Response参数,并通过pyquery解析页面。同时,还会遍历链接,并通过crawl()生成新的请求。detail_page()接收Response参数,并抓取页面信息,不会生成新的请求。
6.3 爬取首页
- 点击
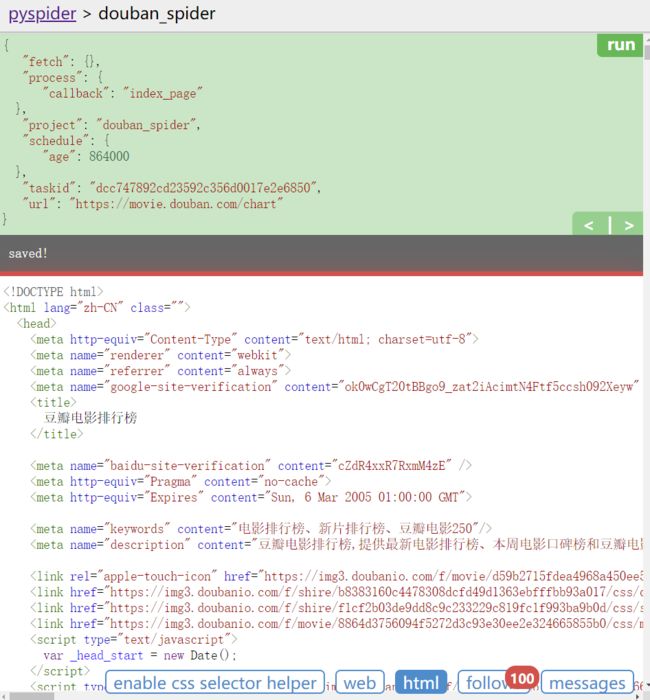
run后,下方的follow会出现标注1,表示有新的爬取请求产生。

- 点击右箭头,执行爬取请求,并通过
index_page()函数解析了内容。
6.4 爬取页面数据
- 为了爬取页面数据,我们需要修改Handler代码。
- 使用pyquery解析页面。
>>>#!/usr/bin/env python
>>># -*- encoding: utf-8 -*-
>>># Created on 2020-09-01 10:17:23
>>># Project: douban_spider
>>>from pyspider.libs.base_handler import *
>>>class Handler(BaseHandler):
>>> crawl_config = {
>>> }
>>> @every(minutes=24 * 60)
>>> def on_start(self):
>>> self.crawl('https://movie.douban.com/chart', callback=self.index_page)
>>> @config(age=10 * 24 * 60 * 60)
>>> def index_page(self, response):
>>> for each in response.doc('table').items():
>>> item = [x for x in each.find('span').items()]
>>> name = item[0].text()
>>> rating = item[2].text()
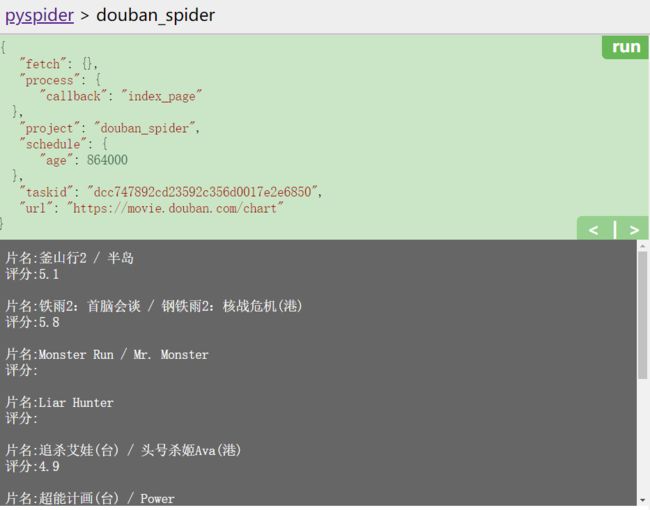
>>> print(f'片名:{name}\n评分:{rating}\n')
-
webUI显示结果:
6.5 爬取子页面
- 修改Handler代码,收集子页面链接,并创建新任务。
>>>#!/usr/bin/env python
>>># -*- encoding: utf-8 -*-
>>># Created on 2020-09-01 10:17:23
>>># Project: douban_spider
>>>import json
>>>from pyspider.libs.base_handler import *
>>>class Handler(BaseHandler):
>>> crawl_config = {
>>> }
>>> @every(minutes=24 * 60)
>>> def on_start(self):
>>> self.crawl('https://movie.douban.com/chart', callback=self.index_page)
>>> @config(age=10 * 24 * 60 * 60)
>>> def index_page(self, response):
>>> urls = set()
>>> for each in response.doc('a[href^="https://movie.douban.com/subject/"]').items():
>>> if each.attr.href not in urls:
>>> self.crawl(each.attr.href,callback=self.detail_page)
>>> urls.add(each.attr.href)
>>> @config(priority=2,fetch_type="js")
>>> def detail_page(self,response):
>>> page = json.loads(response.doc("script[type='application/ld+json']").text())
>>> return {
>>> "url": response.url,
>>> "title": response.doc('title').text(),
>>> "directors": [x.get("name") for x in page.get("director")],
>>> "author":[x.get("name") for x in page.get("author")],
>>> "actors":[x.get("name") for x in page.get("actor")],
>>> "description":page.get("description"),
>>> "rating":page.get("aggregateRating").get("ratingValue")
>>> }
-
在爬去首页后出现了37个新任务。

-
执行第一个任务,爬取第一个子页面内容。
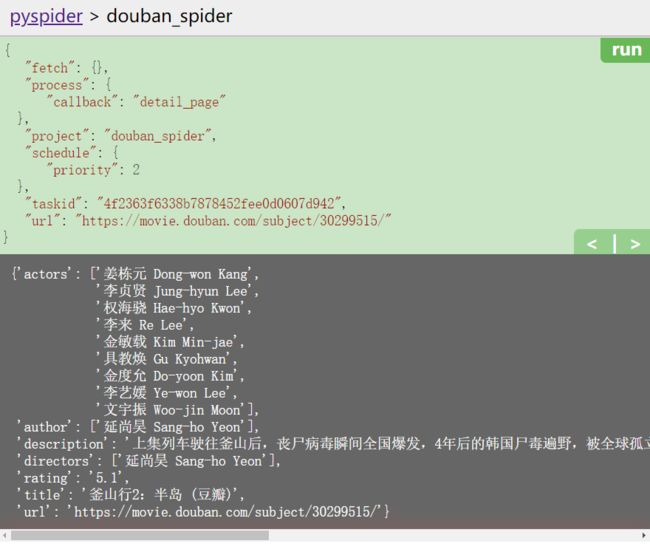 image.png
image.png
6.5 启动爬虫
-
在webUI的项目页面,修改爬虫状态为running或debug。

-
点击run启动爬虫

| 参数 | 含义 |
|---|---|
| rate/burst | 当前爬取速率 |
| rate | 每秒发送请求书 |
| burst | 流量控制中令牌筒算法的令牌数 |
| process | 最近5分钟、1小时、1天和所有的请求情况 蓝色:等待被执行的请求 绿色:成功的请求 黄色:请求失败后等待重试的请求 红色:失败次数过多而被忽略的请求 |
-
点击Active Tasks查看最近请求的详细状况

-
点击Result查看爬取结果

7. Pyspider的方法
7.1 命令行用法
- pyspider命令行有很多可配置参数,完整结构为:
pyspider [OPTIONS] COMMAND [ARGS] - OPTIONS为可选参数,可指定参数如下:
| 参数 | 功能 |
|---|---|
| -c, --config FILENAME | 指定配置文件名称 |
| --logging-config TEXT | 日志配置文件名称,默认: pyspider/pyspider/logging.conf |
| --debug | 开启调试模式 |
| --queue-maxsize INTEGER | 队列的最大长度 |
| --taskdb TEXT | taskdb的数据库连接字符串, default: sqlite |
| --projectdb TEXT | projectdb的数据库连接字符串, default: sqlite |
| --resultdb TEXT | resultdb的数据库连接字符串, default: sqlite |
| --message-queue TEXT | 消息队列连接炙甘草default: multiprocessing.Queue |
| --amqp-url TEXT | [deprecated] amqp url for rabbitmq. please use --message-queue instead. |
| --beanstalk TEXT | [deprecated] beanstalk config for beanstalk queue. please use --message-queue instead. |
| --phantomjs-proxy TEXT | phantomjs使用的代理,ip:port的形式 |
| --data-path TEXT | 数据库存放的路径 |
| --version | pyspider的版本 |
| --help | 显示帮助信息 |
- 可以使用
pyspider scheduler [OPTIONS]单独运行Scheduler组件,OPTIONS参数如下:
| 参数 | 功能 |
|---|---|
| --xmlrpc / --no-xmlrpc | |
| --xmlrpc-host TEXT | |
| --xmlrpc-port INTEGER | |
| --inqueue-limit INTEGER | 任务队列的最大程度,如果满了则新的任务会被忽略 |
| --delete-time INTEGER | 设置为delete标记之前的删除时间 |
| --active-tasks INTEGER | 当前活跃的任务数量配置 |
| --loop-limit INTEGER | 单轮最多调度的任务数量 |
| --scheduler-cls TEXT | scheduler使用的类 |
| --help | 显示帮助信息 |
- 可以使用
pyspider fetcher [OPTIONS]单独运行Fetcher组件,OPTIONS参数如下:
| 参数 | 功能 |
|---|---|
| --xmlrpc / --no-xmlrpc | |
| --xmlrpc-host TEXT | |
| --xmlrpc-port INTEGER | |
| --poolsize INTEGER | 同时请求的个数 |
| --proxy TEXT | 使用的代理 |
| --user-agent TEXT | 使用的User-Agent |
| --timeout TEXT | 超时时间 |
| --fetcher-cls TEXT | Fetcher使用的类 |
| --help | 显示帮助信息 |
- 可以使用
pyspider processor [OPTIONS]单独运行Processor组件,OPTIONS参数如下:
| 参数 | 功能 |
|---|---|
| --processor-cls TEXT | Processor使用的类 |
| --help | 显示帮助信息 |
- 可以使用
pyspider webui [OPTIONS]单独运行WebUI,OPTIONS参数如下:
| 参数 | 功能 |
|---|---|
| --host TEXT | 运行地址 |
| --port INTEGER | 运行端口 |
| --cdn TEXT | js/css的cdn服务器 |
| --scheduler-rpc TEXT | scheduler的xmlrpc路径 |
| --fetcher-rpc TEXT | fetcher的xmlrpc路径 |
| --max-rate FLOAT | 每个项目最大的rate值 |
| --max-burst FLOAT | 每个项目最大的burst值 |
| --username TEXT | Auth验证的用户名 |
| --password TEXT | Auth验证的密码 |
| --need-auth | 是否需要验证 |
| --webui-instance TEXT | 运行时使用的Flash应用 |
| --help | 显示帮助信息 |
7.2 self.crawl()用法
-
self.crawl()方法实现了新请求的生成,参数配置如下:
| 参数 | 功能 |
|---|---|
| url | 目标爬取的url或url列表。 |
| callback | 爬取响应的回调函数。 |
| age | 任务有效时间,如果某个任务在有效时间内且已经被执行,则不会重复执行。 |
| priority | 爬取任务的优先级,默认为0,数值越大越被优先调用。 |
| exetime | 定时任务,默认为0,代表立即执行。 |
| retries | 重试次数,默认为3。 |
| itag | 判断网页节点和上次爬取的是否相同,如果相同则不重复爬取。 |
| auto_recrawl | 如果为True,则任务过期后会重复执行。 |
| method | HTTP请求方式,默认为GET。 |
| params | 用来定义GET请求的参数。 |
| data | 用来传递POST表单数据。 |
| files | 上传的文件。 |
| user_agent | 爬取使用的User-Agent。 |
| headers | 爬取使用的Headers。 |
| cookies | 爬取使用的Cookies。 |
| connect_timeout | 初始化链接等待的最长时间,默认20秒。 |
| timeout | 抓取网页的最长等待时间,默认120秒。 |
| allow_redirects | 是否自动处理重定向,默认为True。 |
| validate_cert | 是否验证HTTPS证书,默认为True。 |
| proxy | 用于配置代理。 |
| fetch_type | 使用fetch_type=js可以开启PhantomJS渲染,用于抓取JavaScript页面。 |
| js_script | 页面加载完毕后执行JS脚本,传入脚本字符串。 |
| js_run_at | JS脚本运行位置,默认document-end。 |
| js_viewport_width/js_viewport_height | JS渲染页面时的窗口大小。 |
| load_images | 加载JS页面时是否加载图片,默认为False。 |
| save | 可以在不同的方法之间传递参数。 |
| cancel | 取消任务。 |
| force_update | 用于强制更新爬虫状态。 |
- 可以使用
crawl_config指定全局配置,配置中的参数会和crawl()方法创建任务时的参数合并。
>>>class Handler(BaseHandler):
>>> crawl_config = {
>>> }
7.3 任务区分
- 可以使用URL的MD5值作为任务的唯一ID,判断是否是重复任务。
>>>import pyspider.libs.utils import md5string
>>>import json
>>>def get_taskid(self,task):
>>> return md5string(task['url']+json.dumps(task['fetch'].get('data','')))
7.4 定时爬取
- 可以通过every属性设置爬取的时间间隔。
- 需要大于有效时间。
# 一小时爬取一次
@every(minutes=60)
def on_start(self):
self.crawl(url,callback=self.index_page)
7.5 项目状态
| 状态 | 含义 |
|---|---|
| TODO | 项目被创建,但未实现。 |
| STOP | 项目停止。 |
| CHECKING | 项目被修改后,或出错需要调整。 |
| DEBUG | 项目未测试通过,但也可以执行。 |
| RUNNING | 项目运行。 |
| PAUSE | 项目遇到错误暂停,等待一定时间后继续爬取。 |
7.6 删除项目
-
如果要删除项目,需要将项目状态设置为STOP,并将分组设置为delete,24小时后项目自动删除。

参考资料
- https://blog.csdn.net/u010138758/article/details/80152151 J-Ombudsman
- https://www.cnblogs.com/zhuluqing/p/8832205.html moisiet
- https://www.runoob.com 菜鸟教程
- http://www.tulingxueyuan.com/ 北京图灵学院
- http://www.imooc.com/article/19184?block_id=tuijian_wz#child_5_1 两点水
- https://blog.csdn.net/weixin_44213550/article/details/91346411 python老菜鸟
- https://realpython.com/python-string-formatting/ Dan Bader
- https://www.liaoxuefeng.com/ 廖雪峰
- https://blog.csdn.net/Gnewocean/article/details/85319590 新海说
- https://www.cnblogs.com/Nicholas0707/p/9021672.html Nicholas
- https://www.cnblogs.com/dalaoban/p/9331113.html 超天大圣
- https://blog.csdn.net/zhubao124/article/details/81662775 zhubao124
- https://blog.csdn.net/z59d8m6e40/article/details/72871485 z59d8m6e40
- https://www.jianshu.com/p/2b04f5eb5785 MR_ChanHwang
- 《Python学习手册》Mark Lutz
- 《Python编程 从入门到实践》Eric Matthes
- 《Python3网络爬虫开发实战》崔庆才
本文作者:大师兄(superkmi)