Python 玩转数据 - Pandas 抽象数据类型 index series DataFrame
Python 进阶学习 玩转数据系列 之 Pandas 抽象数据类型 index series DataFrame
引言
Pandas 库是一个免费、开源的第三方 Python 库,是 Python 数据分析必不可少的工具之一,它为 Python 数据分析提供了高性能,且易于使用的数据结构,即 Series 和 DataFrame。Pandas 自诞生后被应用于众多的领域,比如金融、统计学、社会科学、建筑工程等。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 库基于 Python NumPy 库开发而来,因此,它可以与 Python 的科学计算库配合使用。Pandas 提供了两种数据结构,分别是 Series(一维数组结构)与 DataFrame(二维数组结构),这两种数据结构极大地增强的了 Pandas 的数据分析能力。
内容提要:
Pandas Resource 资源
Pandas 的优势
Pandas data model 数据结构
Pandas 抽象数据类型:Index Object
Pandas 抽象数据类型:Series
Python 内置的聚合函数zip() 和 Unzip with zip ( *zipped_obj)
Pandas 抽象数据类型:DataFrame
Pandas 属性和核心信息方法
Pandas Resource 资源
导入包并 check version,通常 pd 作为 pandas 的别名,更多信息可参考 pandas 官网。
import pandas as pd
version = pd.__version__
print(version)
输出:
1.1.1
Pandas 的优势
- 高性能,易使用的数据结构或数据模型:
● 1D : Index object
● 1D : Series: Column
● 2D : DataFrame: Table of Rows and Columns (Single Sheet)
● 3D : Panel : Multiple Sheets - 丰富的函数调用
● 数据读写: CSV, JSON, ASCII, HTML, MS Excel, HDF5, SQL, etc.
● 数据处理: joins, aggregation, filtering, etc.
● 数据分析和可视化: basic statistics and graphics - Implementation Perspective:
● Built on top of Cython
● Has less memory overhead
● Acts like an in-memory nosql database
● Runs quicker than Python (but slower than NumPy)
● Adopts some NumPy’isms
● Supports vectorized operations: apply
Pandas data model 数据结构
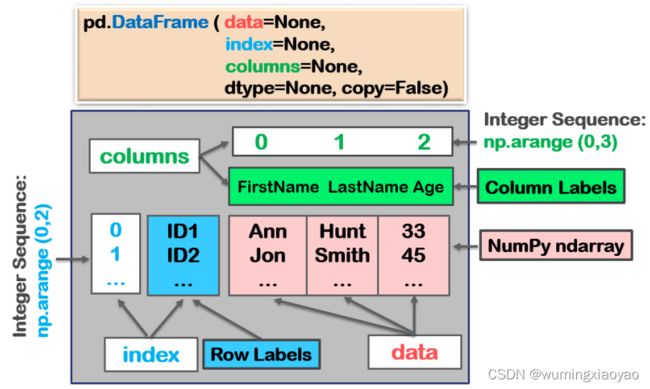
Pandas 抽象数据类型:Index Object
- 类型: Index
1 维不可变数组: 一个有序的,可切分的序列- 用来存储 Pandas objects 的 axis labels 轴标签
- 只能包含
可哈希的对象 hashable objects
pd.Index(data=None, dtype=None, copy=False, ame=None, fastpath=False, tupleize_cols=True, **kwargs)
例如:
import pandas as pd
column_label = pd.Index(['name', 'age', 'salary'])
row_label = pd.Index(['ID'+ str(i) for i in range (1, 3)])
print("column label:{}".format(column_label))
print("the type of column label:{}".format(type(column_label)))
print("row label:{}".format(row_label))
输出:
column label:Index(['name', 'age', 'salary'], dtype='object')
the type of column label:<class 'pandas.core.indexes.base.Index'>
row label:Index(['ID1', 'ID2'], dtype='object')
Pandas 抽象数据类型:Series
- 类型: Series
- 数据: 1 维带轴标签(Index object)的数组 ndarray
array-like, dict, or scalar value - 轴标签: index
● 类型: Panda’s Index or RangeIndex
● 默认: np.arrange(n)
● 不唯一
● 必须是可哈希 hashable 类型 - 索引 Indexing:
● 基于整数 (位置)
● 基于标签 - 缺省 missing: NaN
pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
默认 index 的 Series
Series 默认 index 是 np.arange()
import pandas as pd
s = pd.Series (data = ['Hunt', 'Smith'],name = "Last Name")
print("series:\n{}".format(s))
print("series index:{}".format(s.index))
输出:
series:
0 Hunt
1 Smith
Name: Last Name, dtype: object
series index:RangeIndex(start=0, stop=2, step=1)
带轴标签的 Series
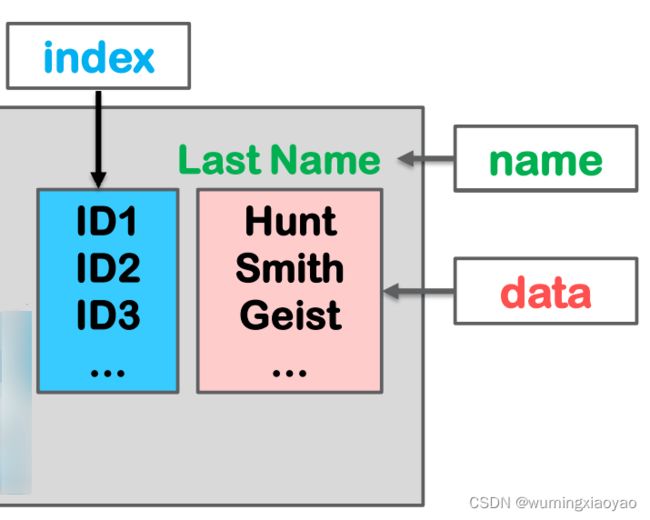
import pandas as pd
row_label = pd.Index(['ID'+ str(i) for i in range (1, 3)])
s = pd.Series (data = ['Hunt', 'Smith'],name = "Last Name", index=row_label)
print("series:\n{}".format(s))
print("series index:{}".format(s.index))
输出:
series:
ID1 Hunt
ID2 Smith
Name: Last Name, dtype: object
series index:Index(['ID1', 'ID2'], dtype='object')
indexing 访问
可以通过位置或标签来访问 pandas 的 series 对象

例如:
import pandas as pd
row_label = pd.Index(['ID'+ str(i) for i in range (1, 3)])
s = pd.Series (data = ['Hunt', 'Smith'],name = "Last Name", index=row_label)
print("series:\n{}".format(s))
# Change
s[0] = ["kelly"]
print("s[0]:{}".format(s[0]))
print("s[1]:{}".format(s[1]))
print("s['ID1']:{}".format(s['ID1']))
print("s['ID1']:{}".format(s['ID2']))
输出:
series:
ID1 Hunt
ID2 Smith
Name: Last Name, dtype: object
s[0]:['kelly']
s[1]:Smith
s['ID1']:['kelly']
s['ID1']:Smith
Python 内置的聚合函数zip() 和 Unzip with zip ( *zipped_obj)
- zip(): zips 多个序列对象(列数据)成一行行数据
- 用 list() 联合多个 tuple:创建 tuple 记录(行数据)的 list
- zip() 用 * 联合操作可以用来解压缩一个 list,将行数据解压成列数据
- 序列对象的size是一样的,每个序列可视为表格的一列数据
- 每个 tuple 记录可视为表格的一行数据
- 表格数据的每行和列可以用来创建 DataFrame 对象
zip() 和 zip ( *zipped_obj) 例子:
import pandas as pd
fnames = ['Ann', 'Jon']
lnames = ['Hunt', 'Smith']
ages = [33, 45]
zipped = list(zip(fnames, lnames, ages)) # list of tuples/records
print("zipped:{}".format(zipped))
# unzip into tuples
f, l, a = zip (*zipped)
print ("unzip f:{}".format(f))
print ("unzip l:{}".format(l))
print ("unzip a:{}".format(a))
输出:
zipped:[('Ann', 'Hunt', 33), ('Jon', 'Smith', 45)]
unzip f:('Ann', 'Jon')
unzip l:('Hunt', 'Smith')
unzip a:(33, 45)
zipping tuples 也是可以的
import pandas as pd
a = (1, 2)
b = (3, 4)
zipped_tuple = list (zip (a,b))
print(zipped_tuple)
输出:
[(1, 3), (2, 4)]
Pandas 抽象数据类型:DataFrame
- 类型: DataFrame
- 数据: 2维大小可以变的, 异类表格数据
● numpy ndarray (structured or homogeneous)
● dictionary
● dict of Series, arrays, constants or list-like objects
● DataFrame - 轴标签: index and columns
● Type: Panda’s Index or RangeIndex
● index: Row labels
● columns: Column labels
● Default: np.arange(n)
● not unique
● must be hashable type - Indexing:
● integer-based (position)
● label-based - Missing: NaN
pd.DataFrame (data=None, index=None, columns=None, type=None, copy=False)
默认 index 和 columns 的 DataFrame
默认的 index 和 columns 是 np.arange()
例如:
import pandas as pd
fnames = ['Ann', 'Jon']
lnames = ['Hunt', 'Smith']
ages = [33, 45]
zipped = list(zip(fnames, lnames, ages))
print("zipped:{}".format(zipped))
df = pd.DataFrame(data = zipped)
print("df:\n{}".format(df))
print("df index:{}".format(df.index))
print("df column:{}".format(df.columns))
输出:
zipped:[('Ann', 'Hunt', 33), ('Jon', 'Smith', 45)]
df:
0 1 2
0 Ann Hunt 33
1 Jon Smith 45
df index:RangeIndex(start=0, stop=2, step=1)
df column:RangeIndex(start=0, stop=3, step=1)
带轴标签的 DataFrame
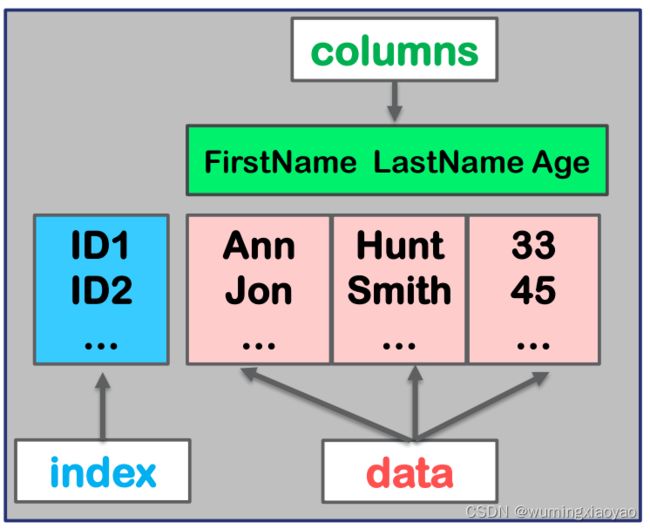
import pandas as pd
fnames = ['Ann', 'Jon']
lnames = ['Hunt', 'Smith']
ages = [33, 45]
zipped = list(zip(fnames, lnames, ages))
row_labels = pd.Index (['ID'+str(i) for i in range (1, 3)])
col_labels = pd.Index (['First Name', 'Last Name', 'Age'])
df = pd.DataFrame(data = zipped, index=row_labels, columns=col_labels)
print("zipped:{}".format(zipped))
print("df:\n{}".format(df))
print("df index:{}".format(df.index))
print("df column:{}".format(df.columns))
输出:
zipped:[('Ann', 'Hunt', 33), ('Jon', 'Smith', 45)]
df:
First Name Last Name Age
ID1 Ann Hunt 33
ID2 Jon Smith 45
df index:Index(['ID1', 'ID2'], dtype='object')
df column:Index(['First Name', 'Last Name', 'Age'], dtype='object')
有序序列: 基于标签 或 整数位置
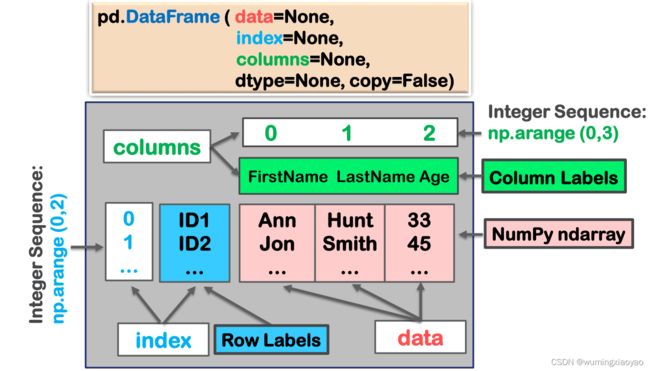
Pandas 抽象数据类型关系
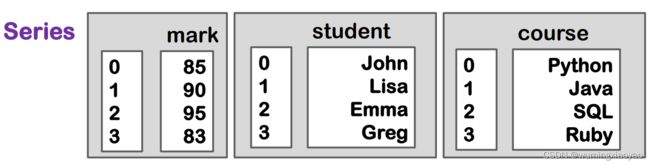

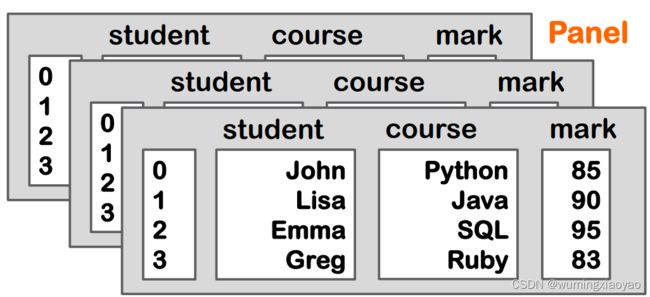
Pandas 数据类型
为最快的速度进行矢量运算,Pandas 数据的类型最好是一样,但不是必须要求一致的类型。
Pandas 的属性和核心方法
属性:
- .shape: 行数和列数
- .axes: 一个 df / Series 的轴
也是 index 和 columns 列表 - .index: the index of the df
- .columns: the columns of the df
不适用于 series - .name: the name of the Series
不适用于 DataFrame
例如:csv 文件有如下数据:
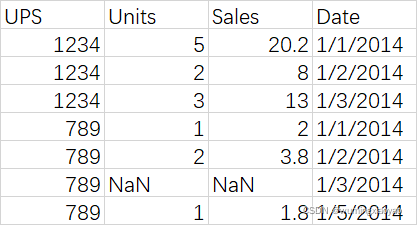
import pandas as pd
sales_df = pd.read_csv("../Python_data_wrangling/Python_data_wrangling_data_raw/data_raw/sales.csv")
print("sales_df:\n{}".format(sales_df))
print("sales_df.shape:{}".format(sales_df.shape))
print("sales_df['Date'].shape:{}".format(sales_df['Date'].shape))
print("sales_df.axes:{}".format(sales_df.axes))
print("sales_df.axes[0]:{}".format(sales_df.axes[0]))
print("sales_df.axes[1]:{}".format(sales_df.axes[1]))
print("sales_df.index:{}".format(sales_df.index))
print("sales_df.columns:{}".format(sales_df.columns))
print("sales_df['UPS'].name:{}".format(sales_df['UPS'].name))
print("sales_df['UPS'].axes:{}".format(sales_df['UPS'].axes))
输出:
sales_df:
UPS Units Sales Date
0 1234 5.0 20.2 1/1/2014
1 1234 2.0 8.0 1/2/2014
2 1234 3.0 13.0 1/3/2014
3 789 1.0 2.0 1/1/2014
4 789 2.0 3.8 1/2/2014
5 789 NaN NaN 1/3/2014
6 789 1.0 1.8 1/5/2014
sales_df.shape:(7, 4)
sales_df['Date'].shape:(7,)
sales_df.axes:[RangeIndex(start=0, stop=7, step=1), Index(['UPS', 'Units', 'Sales', 'Date'], dtype='object')]
sales_df.axes[0]:RangeIndex(start=0, stop=7, step=1)
sales_df.axes[1]:Index(['UPS', 'Units', 'Sales', 'Date'], dtype='object')
sales_df.index:RangeIndex(start=0, stop=7, step=1)
sales_df.columns:Index(['UPS', 'Units', 'Sales', 'Date'], dtype='object')
sales_df['UPS'].name:UPS
sales_df['UPS'].axes:[RangeIndex(start=0, stop=7, step=1)]
核心信息方法:
- .head(): 返回前 n 行数据
- .tail(): 反回尾部 n 行数据
- .info(): 返回 DataFrame 的基本信息
数据类型和列数据的概要
不适合 series
import pandas as pd
sales_df = pd.read_csv("../Python_data_wrangling/Python_data_wrangling_data_raw/data_raw/sales.csv")
print("sales_df:\n{}".format(sales_df))
print("sales_df.head(2):\n{}".format(sales_df.head(2)))
print("sales_df.tail(2):\n{}".format(sales_df.tail(2)))
print("sales_df info =======================")
sales_df.info()
输出:
sales_df:
UPS Units Sales Date
0 1234 5.0 20.2 1/1/2014
1 1234 2.0 8.0 1/2/2014
2 1234 3.0 13.0 1/3/2014
3 789 1.0 2.0 1/1/2014
4 789 2.0 3.8 1/2/2014
5 789 NaN NaN 1/3/2014
6 789 1.0 1.8 1/5/2014
sales_df.head(2):
UPS Units Sales Date
0 1234 5.0 20.2 1/1/2014
1 1234 2.0 8.0 1/2/2014
sales_df.tail(2):
UPS Units Sales Date
5 789 NaN NaN 1/3/2014
6 789 1.0 1.8 1/5/2014
sales_df info =======================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7 entries, 0 to 6
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 UPS 7 non-null int64
1 Units 6 non-null float64
2 Sales 6 non-null float64
3 Date 7 non-null object
dtypes: float64(2), int64(1), object(1)
memory usage: 352.0+ bytes