聚合分析简介
聚合分析:英文为Aggregation,是es除搜索功能外提供的针对es数据做统计分析的功能。
- 功能丰富,提供Bucket、Metric、Pipeline等多种分析方式,可以满足大部分的分析需求。
- 实时性高,所有的计算结果都是即时返回的,而hadoop等大数据系统一般都是 T+1级别的。
聚合框架有助于根据搜索查询提供聚合数据。聚合查询是数据库中重要的功能特性,ES作为搜索引擎兼数据库,同样提供了强大的聚合分析能力。它基于查询条件来对数据进行分桶、计算的方法。有点类似于 SQL 中的 group by 再加一些函数方法的操作。聚合可以嵌套,由此可以组成复杂的操作(Bucketing聚合可以包含sub-aggregation)。
聚合分析作为search的一部分,聚合计算的值可以取字段的值,也可是脚本计算的结果。查询请求体中以aggregations节点的语法定义:

聚合分析-分类
Elasticsearch除全文检索功能外提供的针对Elasticsearch数据做统计分析的功能。它的实时性高,所有的计算结果都是即时返回。
Elasticsearch将聚合分析主要分为如下4类:
- Bucket-分桶类型:分桶类型,类似SQL中的GROUP BY语法 (满足特定条件的文档的集合)。
- Metric-指标分析类型:指标分析类型,如计算最大值、最小值、平均值等等 (对桶内的文档进行聚合分析的操作)。
- Pipeline-管道分析类型:管道分析类型,基于上一级的聚合分析结果进行在分析。
- Matrix-矩阵分析类型:矩阵分析类型(聚合是一种面向数值型的聚合,用于计算一组文档字段中的统计信息)。
指标(metric)和 桶(bucket)
虽然Elasticsearch有四种聚合方式,但在一般实际开发中,用到的比较多的就是Metric和Bucket。
桶(bucket)
- a、简单来说桶就是满足特定条件的文档的集合。
- b、当聚合开始被执行,每个文档里面的值通过计算来决定符合哪个桶的条件,如果匹配到,文档将放入相应的桶并接着开始聚合操作。
- c、桶也可以被嵌套在其他桶里面。
指标(metric)
- a、桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档进行一些指标的计算。分桶是一种达到目的地的手段:它提供了一种给文档分组的方法来让我们可以计算感兴趣的指标。
- b、大多数指标是简单的数学运算(如:最小值、平均值、最大值、汇总),这些是通过文档的值来计算的。
metric聚合分析
主要分如下两类:
- 单值分析,只输出一个分析结果
- min、max、avg、sum
- cardinality
其中,Min、Max、Avg、Sum 这些很容易理解,在这里说一下 Cardinality,它是指不同数值的个数,相当于 SQL 中的 distinct。
- 多值分析,输出多个分析结果
- stats、extended stats
- percentile、percentile rank
- top hits
- Stats 是做多样的数据分析,可以一次性得到最大值、最小值、平均值、中值等数据。
- Extended Stats 是对 Stats 的扩展,包含了更多的统计数据,比如方差、标准差等。
- Percentiles 和 Percentile Ranks 是百分位数的一个统计。
- Top Hits 一般用于分桶后获取桶内最匹配的顶部文档列表,即详情数据。
Metric聚合分析-Min
返回数值类字段的最小值
GET /book/_search
{
"size":0,
"aggs":{
"min_price":{
"min":{
"field":"price"
}
}
}
}
Metric聚合分析-Max
返回数值类字段的最大值
GET /book/_search
{
"size":0,
"aggs":{
"max_price":{
"max":{
"field":"price"
}
}
}
}
Metric聚合分析-Sum
返回数值类字段的和
GET /book/_search
{
"size":0,
"aggs":{
"sum_price":{
"sum":{
"field":"price"
}
}
}
}
一次性返回多个结果集
GET /book/_search
{
"size":0,
"aggs":{
"min_price":{
"min":{
"field":"price"
}
},
"max_price":{
"max":{
"field":"price"
}
}
}
}
Metric聚合分析-Avg
返回数值类字段的平均值
GET /book/_search
{
"size":0,
"aggs":{
"avg_price":{
"avg":{
"field":"price"
}
}
}
}
值统计
Value Count Aggregation,值计数聚合。计算聚合文档中某个值(可以是特定的数值型字段,也可以通过脚本计算而来)的个数。该聚合一般域其它 single-value 聚合联合使用,比如在计算一个字段的平均值的时候,可能还会关注这个平均值是由多少个值计算而来。
GET /book/_search
{
"size":0,
"aggs":{
"count_of_tags":{
"value_count":{
"field":"tags"
}
}
}
}
Metric聚合分析-Cardinality
Cardinality:意为集合的势,或者基数,是指不同数值的个数,类似SQL中的distinct count概念。
GET /book/_search
{
"size":0,
"aggs":{
"count_of_tags":{
"cardinality":{
"field":"tags"
}
}
}
}
Metric聚合分析-Stats
返回一系列数值类型的统计值,包含min、max、avg、sum和count。
GET /book/_search
{
"size":0,
"aggs":{
"stats_price":{
"stats":{
"field":"price"
}
}
}
}
Metric聚合分析-Extended Stats
Extended Stats Aggregation,扩展统计聚合。它属于multi-value,比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间。
GET /book/_search
{
"size":0,
"aggs":{
"stats_price":{
"extended_stats":{
"field":"price"
}
}
}
}
Metric聚合分析-Percentile
百分位数统计:
Percentiles Aggregation,百分比聚合。它属于multi-value,对指定字段(脚本)的值按从小到大累计每个值对应的文档数的占比(占所有命中文档数的百分比),返回指定占比比例对应的值。默认返回[ 1, 5, 25, 50, 75, 95, 99 ]分位上的值。
GET /book/_search
{
"size":0,
"aggs":{
"percents_price":{
"percentiles":{
"field":"price"
}
}
}
}
Metric聚合分析-Percentile Rank
百分位数统计:
Percentile Ranks Aggregation,统计价格小于40和价格小于60的文档的占比,这里需求可以使用。
GET /book/_search
{
"size":0,
"aggs":{
"gge_perc_rank":{
"percentile_ranks":{
"field":"price",
"values": [
40,
60
]
}
}
}
}
Metric聚合分析-Top Hits
Top Hits Aggregation,最高匹配权值聚合。获取到每组前n条数据,相当于sql 中Top(group by 后取出前n条)。它跟踪聚合中相关性最高的文档,该聚合一般用做 sub-aggregation,以此来聚合每个桶中的最高匹配的文档,较为常用的统计。
GET /book/_search
{
"query": {
"match_all": {}
},
"aggs": {
"all_interests": {
"terms": {
"field": "name",
"size": 2
},
"aggs": {
"top_tag_hits": {
"top_hits": {
"size": 2
}
}
}
}
}
}
一般用于分桶后获取该桶内最匹配的顶部文档列表,即详情数据
GET /book/_search
{
"size":0,
"aggs": {
"top_tags": {
"terms": {
"field": "name", #根据name进行分组 每组显示前3个文档
"size": 3
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"sort": [
{
"timestamp": {
"order": "desc" #按照时间进行倒叙排序
}
}
],
"_source": {
"includes": [ "name", "price" ] #只显示文档指定字段
},
"size" : 1
}
}
}
}
}
}
Geo Bounds Aggregation
Geo Bounds Aggregation,地理边界聚合。基于文档的某个字段(geo-point类型字段),计算出该字段所有地理坐标点的边界(左上角/右下角坐标点)。
GET index/type/_search?search_type=count
{
"query": {
"match_all": {}
},
"aggs": {
"viewport": {
"geo_bounds": {
"field": "location",
"wrap_longitude": true //是否允许地理边界与国际日界线存在重叠
}
}
}
}
{//返回,
...
"aggregations": {
"viewport": {
"bounds": {
"top_left": { //这个矩形区域左上角坐标
"lat": 80.45,
"lon": -160.22
},
"bottom_right": {//这个矩形区域右下角坐标
"lat": 40.65,
"lon": 42.57
}
}
}
}
}
Geo Centroid Aggregation
Geo Centroid Aggregation,地理重心聚合。基于文档的某个字段(geo-point类型字段),计算所有坐标的加权重心。
GET index/type/_search?search_type=count
{
"query" : {
"match" : { "crime" : "burglary" }
},
"aggs" : {
"centroid" : {
"geo_centroid" : {
"field" : "location"
}
}
}
}
{//输出
...
"aggregations": {
"centroid": {
"location": { //重心经纬度
"lat": 80.45,
"lon": -160.22
}
}
}
}
Bucket桶聚合分析
Bucket Aggregations,桶聚合。
它执行的是对文档分组的操作(与sql中的group by类似),把满足相关特性的文档分到一个桶里,即桶分,输出结果往往是一个个包含多个文档的桶(一个桶就是一个group)。
它有一个关键字(field、script),以及一些桶分(分组)的判断条件。执行聚合操作时候,文档会判断每一个分组条件,如果满足某个,该文档就会被分为该组(fall in)。
它不进行权值的计算,他们对文档根据聚合请求中提供的判断条件(比如:{"from":0, "to":100})来进行分组(桶分)。桶聚合还会额外返回每一个桶内文档的个数。
它可以包含子聚合——sub-aggregations(权值聚合不能包含子聚合,可以作为子聚合),子聚合操作将会应用到由父聚合产生的每一个桶上。
它根据聚合条件,可以只定义输出一个桶;也可以输出多个(multi-bucket);还可以在根据聚合条件动态确定桶个数(比如:terms aggregation)。
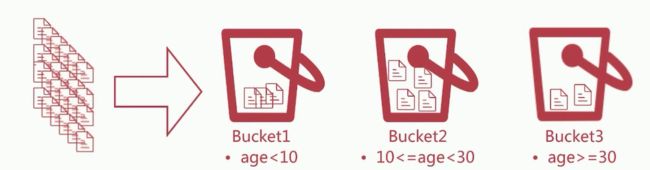
按照Bucket的分桶策略,常见的Bucket聚合分析如下:
- Terms
- Range
- Date Range
- Histogram
- Date Histogram
Bucket聚合分析-Terms
Terms Aggregation,词聚合。基于某个field,该 field 内的每一个【唯一词元】为一个桶,并计算每个桶内文档个数。默认返回顺序是按照文档个数多少排序。它属于multi-bucket。当不返回所有 buckets 的情况(它size控制),文档个数可能不准确。
该分桶策略最简单,直接按照term来分桶,如果是text类型,则按照分词后的结果分桶。
GET /book/_search
{
"aggs" : {
"age_terms" : {
"terms" : {
"field" : "name",
"size" : 10, #size用来定义需要返回多个 buckets(防止太多),默认会全部返回。
"order" : { "_count" : "asc" }, #根据文档计数排序,根据分组值排序({ "_key" : "asc" })
"min_doc_count": 10, #只返回文档个数不小于该值的 buckets
"include" : ".*sport.*", #包含过滤
"exclude" : "water_.*", #排除过滤
"missing": "N/A"
}
}
}
}
GET /book/_search
{
"aggs": {
"age_terms": {
"terms": {
"field": "price",
"size": 5,
"shard_size": 20,
"show_term_doc_count_error": true
}
}
}
}
Bucket聚合分析- Range
Range Aggregation,范围分组聚合。基于某个值(可以是 field 或 script),以【字段范围】来桶分聚合。范围聚合包括 from 值,不包括 to 值(区间前闭后开)。它属于multi-bucket。
GET /book/_search
{
"size":0,
"aggs": {
"price_range": {
"range": {
"field": "price",
"ranges": [
{
"to":20
},
{
"from": 20,
"to": 40
},
{
"from": 60
}
]
},
"aggs": {
"bmax": {
"max": {
"field": "price"
}
}
}
}
}
}
Bucket聚合分析- Date Range
Date Range Aggregation,日期范围聚合。基于日期类型的值,以【日期范围】来桶分聚合。期范围可以用各种 Date Math 表达式。同样的,包括 from 的值,不包括 to 的值。它属于multi-bucket。
GET /book/_search
{
"aggs": {
"range": {
"date_range": {
"field": "timestamp",
"format": "MM-yyy",
"ranges": [
{
"to": "now-10M/M"
},
{
"from": "now-10M/M"
}
]
}
}
}
}
Bucket聚合分析- Histogram 时间柱状聚合
直方图,以固定间隔的策略来分割数据。
你要先了解下Histogram Aggregation,直方图聚合。基于文档中的某个【数值类型】字段,通过计算来动态的分桶。它属于multi-bucket。
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price", //字段,必须为数值类型
"calendar_interval" : 50, //分桶间距
"min_doc_count" : 1, //最少文档数桶过滤,只有不少于这么多文档的桶才会返回
"extended_bounds" : { //范围扩展
"min" : 0,
"max" : 500
},
"order" : { "_count" : "desc" },//对桶排序,如果 histogram 聚合有一个权值聚合类型的"直接"子聚合,那么排序可以使用子聚合中的结果
"keyed":true, //hash结构返回,默认以数组形式返回每一个桶
"missing":0 //配置缺省默认值
}
}
}
}
GET /book/_search
{
"aggs" : {
"salary_hist" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"min_doc_count" : 1,
"extended_bounds" : {
"min" : 0,
"max" : 50
},
"order" : { "_count" : "desc" },
"keyed":true,
"missing":0
}
}
}
}
Bucket聚合分析- Date Histogram
针对日期的直方图或者柱状图,是时序数据分析中常用的聚合分析类型。
Date Histogram Aggregation,日期直方图聚。基于日期类型,以【日期间隔】来桶分聚合。可用的时间间隔类型为:year、quarter、month、week、day、hour、minute、second,其中,除了year、quarter 和 month,其余可用小数形式。
GET /book/_search
{
"aggs" : {
"articles_over_time" : {
"date_histogram" : {
"field" : "timestamp",
"calendar_interval" : "month",
"format" : "yyyy-MM-dd",
"time_zone": "+08:00"
}
}
}
}
Missing Aggregation
Missing Aggregation,缺失值的桶聚合
GET /book/_search
{
"aggs" : {
"account_without_a_age" : {
"missing" : { "field" : "name" }
}
}
}
IP范围聚合
IP Range Aggregation,基于一个 IPv4 字段,对文档进行【IPv4范围】的桶分聚合。和 Range Aggregation 类似,只是应用字段必须是 IPv4 数据类型。它属于multi-bucket。
GET /ip_addresses/_search
{
"size": 10,
"aggs" : {
"ip_ranges" : {
"ip_range" : {
"field" : "ip",
"ranges" : [
{ "to" : "10.0.0.5" },
{ "from" : "10.0.0.5" }
]
}
}
}
}
bucket和metric聚合分析
Bucket聚合分析允许通过添加子分析来进一步进行分析,该子分析可以是Bucket也可以是Metric,这也使得es的聚合分析能力变得异常强大
分桶之后再分桶:
GET /book/_search
{
"size":0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags",
"size": 5
},
"aggs" : {
"price_range" : {
"range": {
"field" : "price",
"ranges": [
{"to":20},
{"from": 20,"to": 50},
{"from": 80}
]
}
}
}
}
}
}


分桶后进行数据分析:
GET /book/_search
{
"size":0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags",
"size": 5
},
"aggs" : {
"price" : {
"stats": {
"field" : "price"
}
}
}
}
}
}

Nested Aggregation
Nested Aggregation,嵌套类型聚合。基于嵌套(nested)数据类型,把该【嵌套类型的信息】聚合到单个桶里,然后就可以对嵌套类型做进一步的聚合操作。
矩阵聚合
Matrix,矩阵聚合。此功能是实验性的,在将来的版本中可能会完全更改或删除。
它对多个字段进行操作并根据从请求的文档字段中提取的值生成矩阵结果的聚合系列。与度量聚合和桶聚合不同,此聚合系列尚不支持脚本编写。
pipeline聚合分析
Pipeline,管道聚合。它对其它聚合操作的输出(桶或者桶的某些权值)及其关联指标进行聚合,而不是文档,是一种后期对每个分桶的一些计算操作。管道聚合的作用是为输出增加一些有用信息。
管道聚合不能包含子聚合,但是某些类型的管道聚合可以链式使用(比如计算导数的导数)。
管道聚合大致分为两类:
parent:它输入是其【父聚合】的输出,并对其进行进一步处理。一般不生成新的桶,而是对父聚合桶信息的增强。
sibling:它输入是其【兄弟聚合】的输出。并能在同级上计算新的聚合。
管道聚合通过 buckets_path 参数指定他们要进行聚合计算的权值对象,bucket_path语法:
聚合分隔符:">",指定父子聚合关系,如:"my_bucket>my_stats.avg"
权值分隔符: ".",指定聚合的特定权值
聚合名称:,直接指定聚合的名称
权值:,直接指定权值
完整路径:agg_name[> agg_name]*[. metrics],综合利用上面的方式指定完整路径
特殊值:"_count",输入的文档个数
特殊情况:
- 要进行 pipeline aggregation 聚合的对象名称或权值名称包含小数点,"buckets_path": "my_percentile[99.9]"
- 处理对象中包含空桶(无文档的桶分),参数 gap_policy,可选值有 skip、insert_zeros
Pipeline的分析结果会输出到原结果中,根据输出位置的不同,分为以下两类
Parent结果内嵌到现有的聚合分析结果中
* Derivative:求导导数
* Moving Average:平均
* Cumulative Sum-Sibling:累计求和
结果与现有聚合分析结果同级
* Max/Min/Avg/Sum Bucket
* Stats/Extended Stats Bucket
* Percentiles Bucket
Avg Max Min Sum:sibliing
Avg Bucket Aggregation,桶均值聚合。基于兄弟聚合的某个权值,求所有桶的权值均值。使用规则:用于计算的兄弟聚合必须是多桶聚合。用于计算的权值必须是数值类型。
Max Bucket Aggregation,桶最大值聚合。基于兄弟聚合的某个权值,输出权值最大的那一个桶。
Min Bucket Aggregation,桶最小值聚合。基于兄弟聚合的某个权值,输出权值最小的一个桶。
Sum Bucket Aggregation,桶求和聚合。基于兄弟聚合的权值,对所有桶的权值求和。
Pipeline聚合分析Sibling-Min Bucket
找出所有Bucket中值最小的Bucket名称和值:
GET /book/_search
{
"size": 0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags"
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
},
"min_price": {
"min_bucket": {
"buckets_path": "tags>price_avg"
}
}
}
}
Pipeline聚合分析Sibling-Max Bucket
找出所有Bucket中值最大的Bucket名称和值:
GET /book/_search
{
"size": 0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags"
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
},
"max_price": {
"max_bucket": {
"buckets_path": "tags>price_avg"
}
}
}
}
Pipeline聚合分析Sibling-Avg Bucket
计算所有Bucket的平均值:
GET /book/_search
{
"size": 0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags"
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_price": {
"avg_bucket": {
"buckets_path": "tags>price_avg"
}
}
}
}
Pipeline聚合分析Sibling-Sum Bucket
计算所有Bucket的值的总和:
GET /book/_search
{
"size": 0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags"
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_price": {
"sum_bucket": {
"buckets_path": "tags>price_avg"
}
}
}
}
Pipeline聚合分析Sibling-Stats Bucket
Stats Bucket Aggregation,桶统计信息聚合。基于兄弟聚合的某个权值,对【桶的信息】进行一些统计学运算(总计多少个桶、所有桶中该权值的最大值、最小等)。用于计算的权值必须是数值类型。用于计算的兄弟聚合必须是多桶聚合类型。
计算所有Bucket的值的Stats分析值:
GET /book/_search
{
"size": 0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags"
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
},
"stats_price": {
"stats_bucket": {
"buckets_path": "tags>price_avg"
}
}
}
}
Pipeline聚合分析Sibling-Percentiles Bucket
计算所有Bucket的值的百分位数:
GET /book/_search
{
"size": 0,
"aggs" : {
"tags" : {
"terms": {
"field" : "tags"
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
}
}
},
"percentiles_price": {
"percentiles_bucket": {
"buckets_path": "tags>price_avg"
}
}
}
}
Derivative Aggregation:parent
Derivative Aggregation,求导聚合。基于父聚合(只能是histogram或date_histogram类型)的某个权值,对权值求导。用于求导的权值必须是数值类型。封闭直方图(histogram)聚合的 min_doc_count 必须是 0。
计算Bucket值得导数:
GET /book/_search
{
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "timestamp",
"calendar_interval" : "month"
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
},
"sales_deriv": {
"derivative": {
"buckets_path": "sum_price"
}
}
}
}
}
}
Moving Average Aggregation:parent
Moving Average Aggregation,窗口平均值聚合。基于已经排序过的数据,计算出处在当前出口中数据的平均值。比如窗口大小为 5 ,对数据 1—10 的部分窗口平均值如下:
- (1 + 2 + 3 + 4 + 5) / 5 = 3
- (2 + 3 + 4 + 5 + 6) / 5 = 4
- (3 + 4 + 5 + 6 + 7) / 5 = 5
- etc
GET /book/_search
{
"size": 0,
"aggs": {
"my_date_histo":{
"date_histogram":{
"field":"timestamp",
"calendar_interval":"1M"
},
"aggs":{
"the_sum":{
"sum":{ "field": "price" }
},
"the_movavg":{
"moving_avg":{
"buckets_path": "the_sum",
"window" : 30,
"model" : "simple"
}
}
}
}
}
}
Pipeline聚合分析Parent-Cumulative Sum
计算Bucket的值的累加和:
GET /book/_search
{
"size": 0,
"aggs" : {
"my_date_histo":{
"date_histogram":{
"field":"timestamp",
"calendar_interval":"year",
"min_doc_count": 0
},
"aggs": {
"price_avg": {
"avg": {
"field": "price"
}
},
"cumulative_sum_price": {
"cumulative_sum": {
"buckets_path": "price_avg"
}
}
}
}
}
}
作用范围
es聚合分析默认作用范围是query的结果集,可以通过如下的方式改变其作用范围:
- filter
- post_filter
- global

filter Aggregation 作用范围
Filter Aggregation,过滤聚合。基于一个条件,来对当前的文档进行过滤的聚合。
为某个聚合分析设定过滤条件,从而在不更改整体query语句的情况下修改了作用范围
GET /book/_search
{
"size": 0,
"aggs": {
"price": {
"filter": {
"range":{
"price": {
"to":50
}
}
},
"aggs": {
"tags": {
"terms": {
"field": "tags"
}
}
}
}
}
}
Filters Aggregation 作用范围
Filters Aggregation,多过滤聚合。基于多个过滤条件,来对当前文档进行【过滤】的聚合,每个过滤都包含所有满足它的文档(多个bucket中可能重复),先过滤再聚合。它属于multi-bucket。
GET /book/_search
{
"size": 0,
"aggs": {
"messages": {
"filters": { // 配置过滤条件,支持 HASH 或 数组格式
"filters": {
"errors": {
"match": {
"body": "error"
}
},
"warnings": {
"match": {
"body": "warning"
}
}
}
}
}
}
}
作用范围-post_filter
作用于文档过滤,但在聚合分析后生效
GET /book/_search
{
"size": 0,
"aggs": {
"tags": {
"terms": {
"field": "tags"
}
}
},
"post_filter": {
"match":{
"tags":"java spring"
}
}
}
作用范围 Global aggregators
Global aggregators全局汇总:在搜索执行上下文中定义所有文档的单个存储桶。此上下文由您要搜索的索引和文档类型定义,但不受搜索查询本身的影响。
作用于文档过滤,但在聚合分析后生效
GET /book/_search
{
"size": 0,
"query": {
"match": {
"name": "java 程序员"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"all":{
"global":{},
"aggs": {
"all_brand_avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
GET /book/_search
{
"query": {
"match": { "name": "java 程序员" }
},
"aggs": {
"all_products": {
"global": {},
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
},
"java 程序员": { "avg": { "field": "price" } }
}
}
Bucket Script Aggregation:parent
Bucket Script Aggregation,桶脚本聚合。基于父聚合的【一个或多个权值】,对这些权值通过脚本进行运算。用于计算的父聚合必须是多桶聚合。用于计算的权值必须是数值类型。执行脚本必须要返回数值型结果。
Bucket Selector Aggregation:parent
Bucket Selector Aggregation,桶选择器聚合。基于父聚合的【一个或多个权值】,通过脚本对权值进行计算,并决定父聚合的哪些桶需要保留,其余的将被丢弃。用于计算的父聚合必须是多桶聚合。用于计算的权值必须是数值类型。运算的脚本必须是返回 boolean 类型,如果脚本是脚本表达式形式给出,那么允许返回数值类型。
Serial Differencing Aggregation:parent
Serial Differencing Aggregation,串行差分聚合。基于父聚合(只能是histogram或date_histogram类型)的某个权值,对权值值进行差分运算,(取时间间隔,后一刻的值减去前一刻的值:f(X) = f(Xt) – f(Xt-n))。用于计算的父聚合必须是多桶聚合。
Extended Stats Bucket Aggregation:sibliing
Extended Stats Bucket Aggregation,扩展桶统计聚合。基于兄弟聚合的某个权值,对【桶信息】进行一系列统计学计算(比普通的统计聚合多了一些统计值)。用于计算的权值必须是数值类型。用于计算的兄弟聚合必须是多桶聚合类型。
Percentiles Bucket Aggregation:sibliing
Percentiles Bucket Aggregation,桶百分比聚合。基于兄弟聚合的某个权值,计算权值的百分比。用于计算的权值必须是数值类型。用于计算的兄弟聚合必须是多桶聚合类型。对百分比的计算是精确的(不像Percentiles Metric聚合是近似值),所以可能会消耗大量内存。
小结:ES默认给 大多数字段启用doc values,所以在一些搜索场景大大的节省了内存使用量,但是需要注意的是只有不分词的 string 类型的字段才能使用这种特性。使聚合运行在 not_analyzed 字符串而不是 analyzed 字符串,这样可以有效的利用 doc values 。
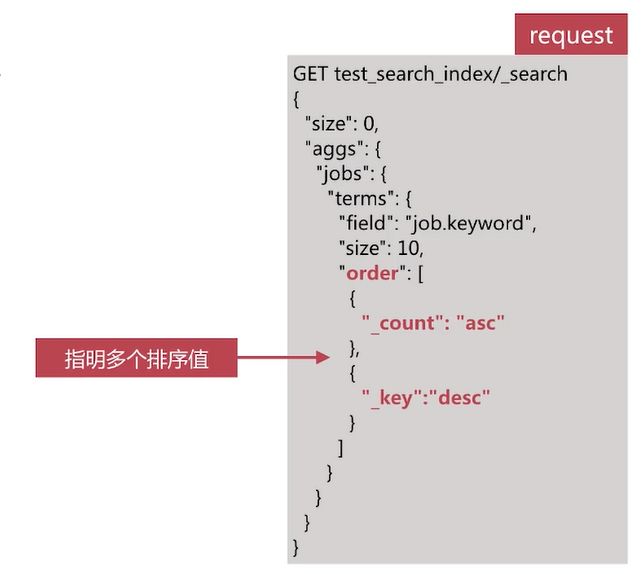
聚合分析排序
可以使用自带的关键数据进行排序,比如:
- _count文档数
- _key按照key值排序

原理与精准度问题
Min聚合得执行流程

Terms聚合的执行流程

Terms并不永远准确
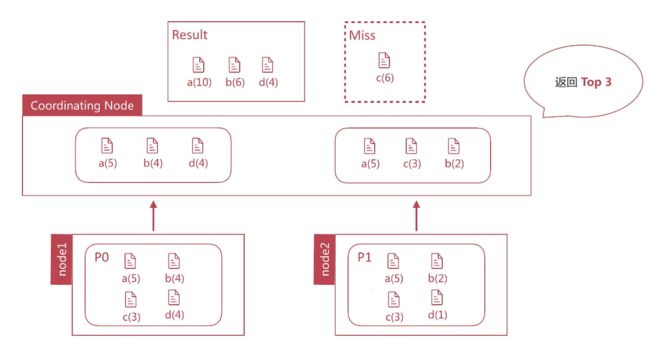
数据分散在多Shard上,Coordinating Node无法得悉数据全貌;所以不准确。
Terms不准确的解决办法
- 设置Shard数为1,消除数据分散的问题,但无法承载大数据量。
- 合理设置Shard Size大小,即每次从Shard上额外多获取数据,以提升准确度。

Shard_Size大小的设定方法
terms聚合返回结果中有如下两个统计值:
- doc_count_error_upper_bound被遗漏的term可能的最大值
- sum_other_other_doc_count返回结果bucket的term外其他term的文档总数

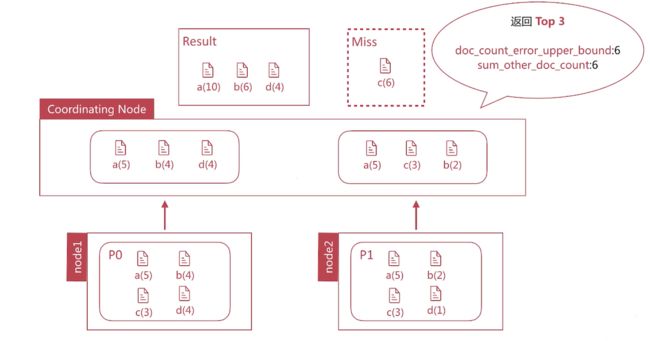
设定show_term_doc_count_error可以查看每个bucket误算的最大值


-
Shard Size默认大小如下:
- shard size = (size x 1.5) +10
-
通过调整Shard Size的大小降低doc_count_error_upper_bound来提升准确度
- 增大了整体的计算量,从而降低了响应时间
近似统计算法

在ES的聚合分析中, Cardinality和Percentile分析使用的是近似统计算法
- 结果是近似准确的,但不一定精准
- 可以通过参数的调整使其结果精准,但同时也意味着更多的计算时间和更大的性能消耗
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
https://blog.csdn.net/alex_xfboy/article/details/86100037
https://blog.csdn.net/bingdianone/article/details/86611509
https://zhuanlan.zhihu.com/p/115362603
https://www.cnblogs.com/qdhxhz/p/11556764.html