本地缓存之王-Caffeine
引言
随着业务体量的增长,使用的缓存方案一般会经过:1)无缓存直接查DB;2)数据同步+Redis;3)多级缓存 三个阶段。
第1阶段直接查DB只能用于小流量场景,随着QPS升高,需要引入缓存来减轻DB压力。
第2阶段一般会通过消息队列将数据同步到Redis,并在数据发生变更时同步更新Redis,业务查询时直接查Redis,如果Redis无数据再去查DB。该方案的缺点是如果Redis发生故障,缓存雪崩会直接将流量打到DB,可能会进一步将DB打挂,导致业务事故。
第3阶段将Redis缓存作为二级缓存,在其上再加一层本地缓存,本地缓存未命中再查Redis,Redis未命中再查DB。使用本地缓存的优点是不受外部系统影响,稳定性好。缺点是没法像分布式缓存那样做到实时更新,而且由于内存有限需要设置缓存大小、制定缓存淘汰策略,因此会有命中率问题。
本篇将主要介绍一个本地缓存解决方案-Caffeine(一个高性能、高命中率、接近最优的本地缓存,被称为”新一代缓存“或”现代缓存之王“。从Spring5开始,Caffeine将取代Guava Cache成为Spring默认的缓存组件)。
缓存之道
本地缓存是在同一个进程内的内存空间中缓存数据,数据读写都是在同一个进程内完成;而分布式缓存是一个独立部署的进程并且一般都是与应用进程部署在不同的机器,故需要通过网络来完成分布式缓存数据读写操作的数据传输。相对于分布式缓存,本地缓存访问速度快,但存在不支持大数据量存储、数据更新时不好保证各节点数据一致性、数据随应用进程的重启而丢失的缺点。
缓存一般是一种key-value键值对的数据结构,对应Java中的HashMap和ConcurrentHashMap。由于HashMap是线程不安全的(并发put会死循环),因此一般用CHM作为本地缓存实现。使用CHM可以实现一个简单的本地缓存,但是由于内存有限,仅适用于小数据量的场景。随着数据量的增长内存会无限膨胀,因此需要使用淘汰策略将用不到的缓存淘汰掉。
常见的淘汰算法有FIFO(First In First Out)、LRU(Least Recently Used)、LFU(Least Frequently Used)等。FIFO先进先出比较符合常规思维,先来的先服务,在操作系统的设计中也常见该思想,但在缓存中使用时会出现将先到的高频数据被淘汰而保留了后到的低频数据的问题,导致缓存命中率低。LRU最近最少使用,如果一个数据在最近一段时间内没有被访问那么它在接下来被访问的可能性也很小,当空间已满的时候优先将最近最少被访问的数据淘汰。这里存在的问题是如果一个数据在1分钟之前被大量访问,这1分钟内没有访问,那么这个热点数据就会被淘汰。LFU最近最少频率使用,如果一个数据在最近一段时间内使用次数很少那么它在接下来被使用的概率也很小。与LRU的区别是,LRU基于访问时间,LFU基于访问频率。LFU利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰,解决了LRU不能处理时间段的问题。这三种算法的命中率一个比一个好,但实现成本也一个比一个高,实际实现中一般选择中间的LRU。
实际使用中,上诉淘汰算法依然存在以下问题:a) 锁竞争严重;b) 不支持过期时间;c) 不支持自动刷新。针对这些问题,Guava Cache应运而生。Guava Cache与Java1.7中的CHM类似,使用分段加锁减小锁粒度加大并发。Guava Cache提供读后过期和写后过期两种过期策略,对于过期的元素没有立即过期而是在读写操作的时候进行处理,以避免后台线程扫描时进行全局加锁。自动刷新是在查询时判断是否满足刷新条件。除此之外,Guava Cache 还有按引用回收、移除监听器、优雅的Api等特性。
Guava Cache的功能强大、提供的Api容易使用,但其本质上仍然是对LRU算法的封装,在缓存命中率上是存在天生缺陷的。Caffeine提出了一种更高效的近似LFU准入策略的缓存结构TinyLFU及其变种W-TinyLFU,并借鉴Guava Cache的设计经验,得到了功能强大且性能更优的新一代本地缓存。
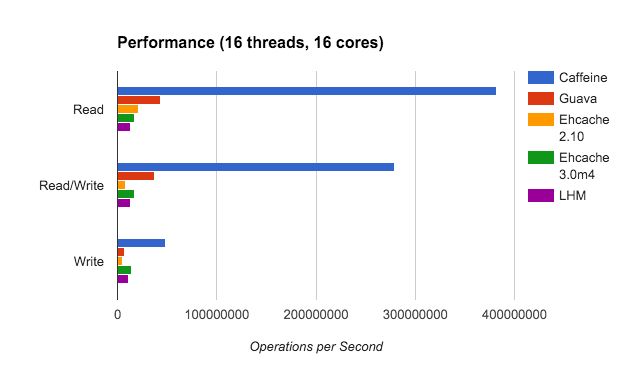
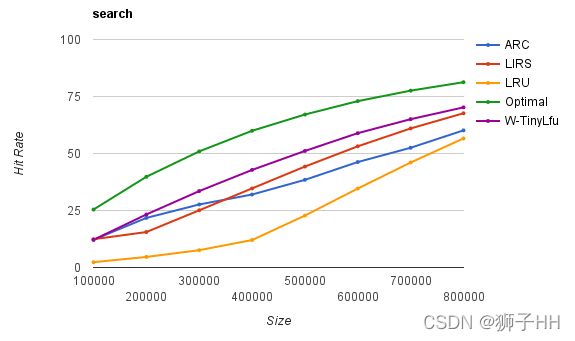
惊艳的算法
引言
缓存可以工作的最直观原因是在计算机科学的很多领域数据访问普遍存在着一定程度的局部性(locality)。通过概率分布来捕获数据的局部性是一种常见方式,然而在很多领域概率分布是相当倾斜的,也就是说被高频访问的只是其中少部分对象。而且,在不少场景中,访问模式及其对应的概率分布是随着时间的变化而变化的,即具有时间局部性(time locality)。
如果数据访问模式对应的概率分布不随时间变化,那使用LFU就可以获得最高的缓存命中率。但是LFU存在两个局限性:第一需要维护大量复杂的元数据(用于维护哪些元素应该写入缓存哪些应该被淘汰的空间叫做缓存的元数据);第二在实际场景中访问频率随时间的推移发生根本变化,如热播剧在火了一段时间之后可能就无人问津了。针对上诉问题,出现了多种LFU的变种,主要采用老化机制或有限大小的采样窗口,目的是为了限制元数据的尺寸并将缓存和淘汰决策聚焦于最近流行的元素,Window LFU(WLFU)就是其中之一。
在绝大多数情况下,新访问的数据总是被直接插入到缓存中,缓存设计者仅关注于驱逐策略,这是因为维护当前不在缓存中的对象的元数据被认为是不切实际的。在LFU的已有实现中,都只维护了缓存中元素的频率直方图,这种LFU叫做In-Memory LFU。与之对应的是Perfect LFU(PLFU),维护所有访问过的对象的频率直方图,效果最佳但维护成本也高到令人望而却步。
LRU是一个很常见的用来替代LFU的算法,LRU的淘汰最近最少使用的元素,相较于LFU会有更加高效的实现,并自动适应突发的访问请求;然而基于LRU的缓存,要获得和LFU一样的缓存命中率通常需要更多的空间开销。
针对上述背景和问题,Ben Manes等人在论文 TinyLFU: A Highly Efficient Cache Admission Policy 中阐明了一种近似LFU准入策略的缓存结构/算法的有效性,为Caffeine缓存组件的合理性做了理论和实验论证。其具体贡献如下:
- 提出了一种缓存结构,只有在准入策略认为将其替换进入缓存会提高缓存命中率的情况下才会被插入;
- 提出了一种空间利用率很高的新的数据结构——TinyLFU,可以在较大访问量的场景下近似的替代LFU的数据统计部分;
- 通过形式化的证明和模拟,证明了TinyLFU获得的Freq排序与真实的访问频率排序是几乎近似的;
- 以优化的形式将TinyLFU实现在了Caffeine项目中:W-TinyLFU;
- 与其他几种缓存管理策略进行了实验比较,包括ARC、LIRC等。
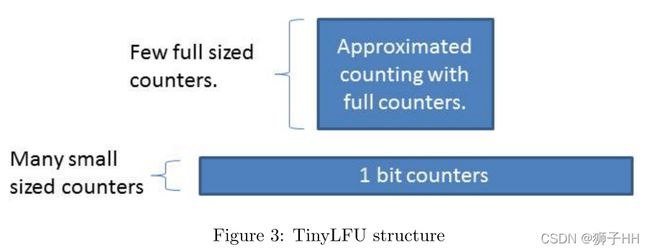
TinyLFU结构
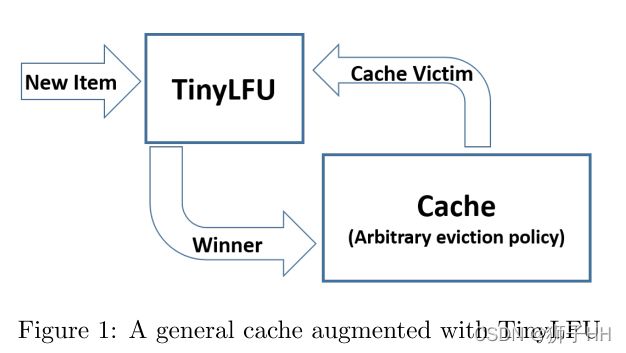
TinyLFU的结构如图所示,对于被缓存驱逐策略判定为淘汰的元素,TinyLFU根据用新元素取代旧元素进入缓存是否有助于提高缓存命中率的原则来判断是否要进行替换。为此,TinyLFU需要维护一份相当大的历史访问频率统计数据,这份开销是非常大的,因此TinyLFU使用了一些高效的近似计算技术来逼近这些统计数据.
近似计算
布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的二进制向量数据结构,它具有很好的空间和时间效率(插入/查询时间都是常数),被用来检测一个元素是不是集合中的一个成员。如果检测结果为是,该元素不一定在集合中;但如果检测结果为否,该元素一定不在集合中。由于布隆过滤器不需要存储元素本身,因此也适用于对保密要求严格的场景。其缺点是随元素数量的增加,误算率随之增加,另外一点是不能删除元素,因为多个元素哈希的结果可能是同一位,删除一个比特位可能影响多个元素的检测。
计数式布隆过滤器Counting Bloom Filter(CBF)是在标准布隆过滤器的每一位上都额外增加了一个计数器,插入元素时给对应的k(哈希函数个数)个计数器分别加1,删除元素时分别减1.
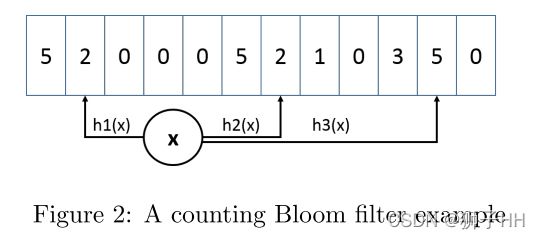
最小增量(Minimal Increment) CBF是一种增强的计数式布隆过滤器,支持添加和评估(Estimate)两种方法。评估方法先对key计算k个不同的hash值,以hash值作为索引读取对应的计数器,将这些计数器的最小值作为返回值。添加方法与此类似,读到k个计数器后只增加最小的计数器。如下图所示,3个hash函数对应到3个计数器,读取到{2,2,5},添加操作只会将2增加为3,5保持不变,以此对高频元素进行一个较好的估计,因为高频元素的计数器不太可能被很多低频元素增长。最小增量CBF不支持衰减,但经验表明这种方式可以减少高频计数的误差。
CM-Sketch是另一种流行的近似计数方案,它在精度和空间之间做了权衡,以较小的精度损失换来了更小的空间占用和更快的速度。而且,后文介绍的空间优化和老化机制可以直接适用于CM-Sketch.
新鲜度机制
目前已知的维护近似sketch(A sketch of a large amount of data is a small data structure that lets you calculate or approximate certain characteristics of the original data)的新鲜度的方式是使用一个包含m个不同的sketch的有序列表来进行滑动采样,新元素被插到第一个sketch,在一定数量的插入后最后一个sketch被清空并移到列表头,以此来将老的元素丢弃掉。这种方式有两个缺点:a) 为了评估一个元素的频率需要读取m个不同的近似sketch,导致许多内存访问和hash计算;b) 因为要在m个不同的sketch中存储相同的元素并为每个元素分配更多计数器,所以空间开销增大了。
这对这两个问题,提出Reset方法来维护sketch的新鲜度。Reset方法在每次将元素加到近似sketch时增加一个计数器,一旦计数器达到采样大小W,就将近似sketch中的所有计数器都除以2。这种直接除的方式有两个优点:首先不需要额外的空间开销,因为它的内存开销是一个占据Log(W)位的单个计数器;其次增加了高频元素的精确度。这种方案的缺点是需要遍历所有计数器将其除以2,然而除2操作可以用移位寄存器在硬件上高效的实现,而且在软件实现时可以用移位和掩码来同时对多个小计数器执行此操作。因此,除2操作的均摊复杂度是常数级别的,可适用于多种应用场景。
空间优化
空间优化有两种方式,一是降低sketch中每个计数器的大小,二是减少sketch内分配的计数器总数。
小计数器
近似sketch的实现一般用Long计数器,如果一个sketch要容纳W个请求,它要求计数器的最大值要达到W,每个计数器要占用Log(W)位,这种开销是很大的。考虑到频率直方图只需要知道待淘汰元素是否比当前被访问元素更受欢迎,而不必知道缓存中所有项之间的确切顺序,而且对于大小为C的缓存,所有访问频率在1/C以上的元素都应该属于缓存(合理假设被访问的元素总数大于C),因此对于给定的采样大小W,可将计数器的上限设置为W/C.
看门人机制
在很多场景尤其是长尾场景中,不活跃元素占据了相当大的比例,如果对每个元素统计访问次数就会出现大多数计数器被分配给了不太可能出现多次的元素,为了进一步缩减计数器的数量,使用看门人(Doorkeeper)机制来避免为尾部对象分配计数器。
Doorkeeper是一个放置于近似计数策略之前的常规布隆过滤器。当访问元素时,首先判断该元素是否在Doorkeeper中,如果不在则将该元素写入Doorkeeper,否则写入主结构。当查询元素时综合Doorkeeper和主结构一起计算,如果在Doorkeeper中,则将主结构中元素的次数加1,不在则直接返回主结构中次数。当进行Reset操作时,会将主结构中所有计数器减半并同时清空Doorkeeper。通过这种方式可以清除所有第一次计数器的信息(也会使截断错误加1)。
在内存方面,尽管Doorkeeper需求额外的空间,但它通过限制写入主结构中的元素数量使得主结构更小,尤其是在长尾场景中,大部分长尾元素只占用了Doorkeeper中的1bit计数器,因此该优化会极大的降低TinyLFU的内存开销。Doorkeeper在TinyLFU中的结构如图所示。
W-TinyLFU优化
TinyLFU在大多数场景下表象良好,但对于有稀疏爆发流量的场景,当新爆发的流量不能累积足够的次数以使得它留在缓存中时,就会导致这些元素被淘汰,会出现反复miss的情况。该问题在将TinyLFU集成到Caffeine中时通过引入W-TinyLFU结构予以补救。
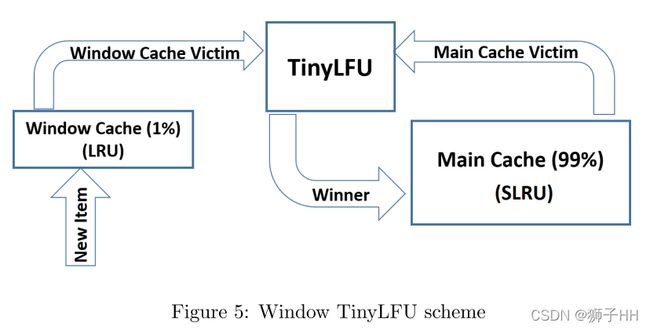
W-TinyLFU的结构如图所示,它由两个缓存单元组成,主缓存使用SLRU驱逐策略和TinyLFU准入策略,window cache仅使用LRU驱逐策略无准入策略。主缓存中的SLRU策略的A1和A2区域被静态划分开来,80%空间被分配给热点元素(A2),被驱逐者则从20%的非热项(A1)中选取。任何到来的元素总是允许进入window cache,window cache的淘汰元素有机会进入主缓存,如果被主缓存接受,那么W-TinyLFU的淘汰者就是主缓存的淘汰者,否则则是window cache的淘汰者。
在Caffeine中,window cache占总缓存的1%,主缓存占99%。W-TinyLFU背后的动机是以TinyLFU的方式处理LFU的工作,同时仍然能够利用LRU应对突发流量的优势。因为99%的缓存分配给主缓存,所以对LFU工作的性能影响是微不足道的。另一方面,在适用于LRU的场景中,W-TinyLFU比TinyLFU更好。总的来说,W-TinyLFU在各种业务场景都是首要选择,因此将其引入Caffeine所带来的复杂度是可以接受的。
优雅的实现
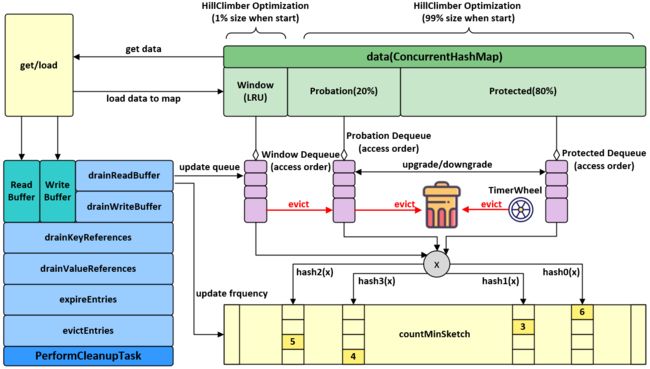
Caffeine的主要功能如图所示。支持手动/自动、同步/异步多种缓存加载方式,支持基于容量、时间及引用的驱逐策略,支持移除监听器,支持缓存命中率、加载平均耗时等统计指标。

使用简介
Caffeine支持4种缓存加载策略:手动加载、自动加载、手动异步加载和自动异步加载,各类缓存的使用姿势如下所示。
/** 手动加载 */
Cache<Key, Graph> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
Graph graph = cache.getIfPresent(key);
graph = cache.get(key, k -> createExpensiveGraph(key));
cache.put(key, graph);
cache.invalidate(key);
/** 自动加载 */
LoadingCache<Key, Graph> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> createExpensiveGraph(key));
Graph graph = cache.get(key);
Map<Key, Graph> graphs = cache.getAll(keys);
/** 手动异步加载 */
AsyncCache<Key, Graph> cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.buildAsync();
CompletableFuture<Graph> graph = cache.getIfPresent(key);
graph = cache.get(key, k -> createExpensiveGraph(key));
cache.put(key, graph);
cache.synchronous().invalidate(key);
/** 自动异步加载 */
AsyncLoadingCache<Key, Graph> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
// 可以选择: 去异步的封装一段同步操作来生成缓存元素
.buildAsync(key -> createExpensiveGraph(key));
// 也可以选择: 构建一个异步缓存元素操作并返回一个future
.buildAsync((key, executor) -> createExpensiveGraphAsync(key, executor));
// 查找缓存元素,如果其不存在,将会异步进行生成
CompletableFuture<Graph> graph = cache.get(key);
// 批量查找缓存元素,如果其不存在,将会异步进行生成
CompletableFuture<Map<Key, Graph>> graphs = cache.getAll(keys);
整体设计
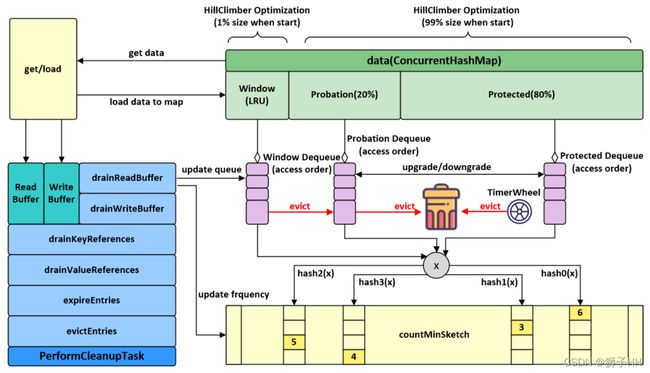
Ref: caffeine wiki: Design
顺序访问队列
访问队列(Access order queue)是一个双向链表,其将所有HashTable中的元素有序排列在其中。一个元素可以在O(1)的时间复杂度内从HashMap中找到并操作队列中与其相邻的元素。访问顺序被定义为缓存中的元素被创建、更新或访问的顺序。最近最少被使用的元素将会在队首,而最近被使用的元素将会在队列末尾。这为基于容量的驱逐策略(maximumSize)和基于空闲时间的过期策略(expireAfterAccess)的实现提供了帮助。这里的问题在于,每次访问都会对队列进行更改,因此无法通过高效的并发操作来实现。
顺序写队列
写顺序被定义为缓存中的元素被创建和更新的顺序。和访问队列类似,写队列的操作也都是基于O(1)的时间复杂度。这个队列为基于存活时间的驱逐策略(expireAfterWrite)的实现提供帮助。
分层时间轮
分层时间轮是一个用hash和双向链表实现的以时间作为优先级的优先队列,其操作也是O(1)的时间复杂度。这个队列为基于指定时间的驱逐策略(expireAfter(Expiry))的实现提供帮助。
读缓冲
典型的缓存实现会为每个操作加锁,以便能够安全的对每个访问队列的元素进行排序。一种替代方案是将每个重新排序的操作加入到缓冲区中进行批处理操作。这可以当作页面置换(page replacement)策略的预写日志。当缓冲区满的时候,将会尝试获取锁并挂起,如果持有了锁则线程会立即返回。
读缓冲是一个带状环形缓冲区(striped ring buffer)。带状的设计是为了减少线程之间的资源竞争,一个线程通过hash对应到一个带上。环形缓冲是一个定长数组,提供高效的性能并最大程度上减少GC开销。而环形队列的具体数量可以根据竞争预测算法进行动态调整。
写缓冲
与读缓冲类似,写缓冲是为了重放写事件。读缓冲中的事件主要是为了优化驱逐策略的命中率,因此允许一定程度的有损。但是写缓冲并不允许数据的丢失,因此其必须实现为一个高效的有界队列。由于每次向写缓冲填充的时候都要清空写缓冲中的内容,因此通常情况下写缓冲的容量都为空或者很小。
写缓冲区由一个可扩展至最大大小的环形数组所实现。当调整数组大小的时候将会直接分配内存生成一个新的数组。而前置数组将会指向新的数组以便消费者可以访问,这允许旧的数组访问后可以直接释放。这种分块机制允许缓冲区可以拥有一个较小的初始大小,较低的读写成本并且产生较小的垃圾。当缓冲区被写满并无法扩容的时候,缓冲区的生产者将会尝试自旋并触发维护操作,并在短暂的时间后返回可执行状态。这样可以使消费者线程通过重放驱逐策略上的写入来确定优先级并清空缓存区。
锁均摊
传统缓存会给每个操作加锁,而Caffeine则通过批处理将加锁开销分摊到各个线程中。这样,锁带来的副作用将由各线程均摊而避免加锁竞争带来的性能开销。维护操作将会分发给所配置的线程池进行执行,在任务被拒绝或者指定调用线程执行策略下,也可以由使用者线程进行维护操作。
批处理的一个优势在于,由于锁的排他性,同一时间将只会有一个线程处理缓冲区内的数据。这将使得基于多生产者/单消费者的消费模型缓冲区实现更加高效。这也将更好地利用CPU缓存优势来更适应硬件特性。
元素状态转换
当缓存不被一个排他锁保护的时候,针对缓存的操作可能以错误的顺序进行重放。在并发竞争条件下,一个创建-读取-更新-删除的顺序操作可能无法以正确顺序写入缓存。如果要保证顺序正确,可能需要更粗粒度的锁从而导致性能下降。
与典型的并发数据结构一样,Caffeine使用原子状态转变来解决这一难题。一个缓存元素具有存活,退休,死亡三种状态。存活状态是指某一元素同时存在与Hash表和访问/写队列中。而一个元素从Hash表中被移除的时候,其状态也将变为退休并需要从队列中移除。当从队列中也被移除后,一个元素的状态将会被视为死亡并在GC中被回收。
Relaxed reads and writes
Caffeine 对充分利用volatile操作花费了很多精力。 内存屏障 提供了一种从硬件角度出发的视角来代替从语言层面思考volatile的读写。通过了解哪些屏障被建立以及它们对硬件和数据可见性的影响,将具有实现更好性能的潜力。
当在锁下进行独占访问的时候,Caffeine使用relaxed reads, 因为数据的可见性可以通过锁的内存屏障获取。这在数据竞争无法避免的情况下(比如在读取元素时校验是否过期来模拟缓存丢失)是可以接受的。
Caffeine 以相似的方式使用relaxed writes。当一个元素在锁定状态进行排他写,那么这次写入可以搭载在解锁时释放的内存屏障上返回。这也可以用来支持解决写偏序问题,比如在读取一个数据的时候更新其时间戳。
驱逐策略
Caffeine 使用 Window TinyLfu策略提供了几乎最优的命中率。访问队列被分为两个部分:TinyLfu策略将会从缓存的准入窗口中选择元素驱逐到缓存的主空间当中。TinyLfu会比较窗口中的受害者和主空间的受害者之间的访问频率,选择保留两者之间之前被访问频率更高的元素。频率将在CountMinSketch中通过4位存储,这将为每个元素占用8个字节去计算频率。这些设计允许缓存能够以极小的代价基于访问频率和就近程度去对缓存中的元素进行O(1)时间复杂度的驱逐操作。
自适应性
准入窗口的大小和主空间的大小将会基于缓存的工作负载特征动态调节。当更加偏向就近度的时候,窗口将会更大,而偏向频率的时候窗口则将更小。Caffeine使用了hill climbing算法去采样命中率来调整,并将其配置为最佳的平衡状态。
快速处理模式
当缓存的大小还未超过总容量的 50%,驱逐策略也未用的时候,用来记录频率的sketch将不会初始化以减小内存开销,因为缓存可能人为地给了一个较高的阈值进行加载。当没有其他特性要求的时候,访问将不会被记录,以避免读缓冲上的竞争和重放读缓冲上的访问事件。
HashDoS 保护
当key之间的hash值相同,或者hash到了同一个位置,这类的hash冲突可能会导致性能降低。hash表采用将链表降级为红黑树的方法来解决该问题。
一种针对TinyLFU的攻击是利用hash冲突来人为地提高驱逐策略下的元素的预估频率。这将导致所有后续进入的元素被频率过滤器所拒绝,导致缓存失效。一种解决方案是加入少量抖动使得最后的结果具有一定的不确定性。这可通过随机录取约1%的被拒绝的候选人来实现。
代码生成
Cache 有许多不同的配置,只有使用特定功能的子集的时候,相关字段才有意义。如果默认情况下所有字段都存在,将会导致缓存和每个缓存中的元素的内存开销的浪费。使用代码生成将会减少运行时的内存开销,其代价是需要在磁盘上存储更大的二进制文件。
这项技术有通过算法优化的潜力。也许在构造的时候用户可以根据用法指定最适合的特性。一个移动应用可能更需要更高的并发率,而服务器可能需要在一定内存开销下更高的命中率。也许不需要通过不断尝试在所有用法中选择最佳的平衡,而可以通过驱动算法进行选择。
被封装的hash map
缓存通过在ConcurrentHashMap之上进行封装来添加所需要的特性。缓存和hash表的并发算法非常复杂。通过将两者分开,可以更便利地应用hash表的设计的优秀之处,也可以避免更粗粒度的锁覆盖全表和驱逐所引发的问题。
这种方式的成本是额外的运行时开销。这些字段可以直接内联到表中的元素上,而不是通过包装容纳额外的元数据。缺少包装可以提供单次表操作的快速路径(比如lambdas)而不是多次map调用和短暂存活的对象实例。
源码解析
以一个实际业务场景为例,用户在拼多多上购物时,点击商品需要展示商品所属的店铺的名称和Logo信息,这些是比较稳定的不会频繁变更的信息。由于C端用户体量很大,每秒浏览商品的人数很多,如果这些流量直接达到数据库可能会把数据库打挂,因此考虑将其提前放到缓存中,需要的时候从缓存中取。用Caffeine实现这样一个查询接口的代码片段如下所示:
// 定义一个自动加载的缓存:最大可容纳1万个店铺,在写入缓存30小时后自动失效
LoadingCache<QueryMallBasicRequest, MallVO> mallBasicLocalCache = Caffeine.newBuilder()
.initialCapacity(10_000)
.maximumSize(10_000)
.expireAfterWrite(Duration.ofHours(30))
.recordStats(CatStatsCounter::new)
.build(this::queryMallBasicInfo);
// 查询一个店铺的基本信息
MallVO mallVO = mallBasicLocalCache.get(request);
这里get()方法做的事情的直观表现是如果本地缓存中有值则直接返回,如果没有则通过指定的queryMallBasicInfo方法查到值后设置到缓存中并返回。实际背后的逻辑则复杂的多,我们从get方法出发来追踪下Caffeine在背后所做的事情,以此将前述的算法原理和框架设计落实到具体的代码实现上。
Class diagram
查看cache package下的类图,蓝色实线表示继承,绿色虚线表示接口实现。
- LocalCache
居中部分是LocalCache接口的两个实现:BoundedLocalCache有界缓存和UnboundedLocalCache无界缓存。
LocalCache继承了ConcurrentMap,对其进行了扩展作为整个Caffeine项目的框架,提供线程安全和原子保障。
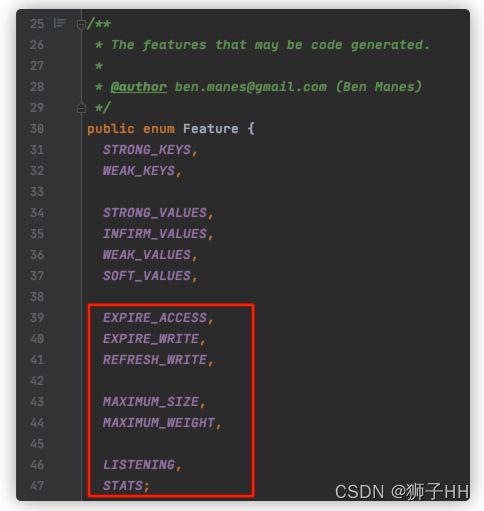
BoundedLocalCache下面有WS、SI、SS、WI 4个子类(W表示WeakKeys,I表示InfirmValues,第1个S表示StrongKeys,第2个S表示StrongValues),这4个子类每个下面又有7个子类,子类生子类,最终有一大坨,这些大写的类都是用Javapoet自动生成的代码。针对建造者模式提前将用户可用的feature组合都生成成对应的类,当用户定义好Caffeine.builder后根据定义的feature组合直接加载对应的生成的类来使用,提高性能。对应代码可查阅LocalCacheFactory#newBoundedLocalCache方法。
这里多唠叨下为什么4个子类下每个又有7个子类。Caffeine支持的可选feature如下所示,首先是最重要的key、value的引用类型,这里value定义了4种类型,实际generateLocalCaches只用了Strong和Infirm,因此key-value组合后生成4个子类,每个子类都要遍历其他feature,除了key和value的引用,还有剩下7种feature,因此每个下面又生出来7个子类。如果想了解代码生成逻辑,可github下载源码看javaPoet package部分的代码,简单了解可查阅LocalCacheFactoryGenerator#getFeatures方法。
- Node
左下方是Node部分,Node是缓存中的一个元素/条目(entry),包括key、value、weight、access和write元数据。Node是个抽象类,实现了AccessOrder和WriteOrder。Node有FS、FD、PD、PS、PW、FW 6个子类(F-WeakKeys,P-StrongKeys,S-StrongValues, D-SoftValues, W-WeakValues),每个子类下面又有一堆子类,不再赘述。
- MPSC
左上角是MPSC相关的数据结构,这部分参考了JCTools 里的MpscGrowableArrayQueue ,是针对 MPSC(Multi-Producer & Single-Consumer 多生产者单消费者)场景的高性能实现。Caffeine中的写是把数据放入MpscGrowableArrayQueue 阻塞队列中的,多个生产者同时并发地写入队列是线程安全的,但是同一时刻只允许一个消费者消费队列。
- 其他
右下角是一些比较独立的功能类/接口,比较重要的如:RemovalListener、FrequencySketch、TimerWheel、Scheduler、Policy、Expiry、Caffeine、CaffeineSpec等。
Caffeine类
跟进Caffeine类的源码可知,Caffeine类是 建造者模式 中的建造者,通过组合如下特性可以构造出 Cache, LoadingCache, AsyncCache 和 AsyncLoadingCache 实例。
- automatic loading of entries into the cache, optionally asynchronously
- size-based eviction when a maximum is exceeded based on frequency and recency
- time-based expiration of entries, measured since last access or last write
- asynchronously refresh when the first stale request for an entry occurs
- keys automatically wrapped in weak references
- values automatically wrapped in weak or soft references
- writes propagated to an external resource
- notification of evicted (or otherwise removed) entries
- accumulation of cache access statistics
这些特性都是可选的,可以全用也可以都不用,默认创建的缓存没有驱逐策略。
跟进build()方法的实现,可知根据所选特性构造出来的缓存主要分为有界(BoundedLocalCache)和无界(UnboundedLocalCache)两类。我们上述查店铺信息的例子中指定了maximumSize,因此是有界缓存。Caffeine中的核心逻辑也是关于有界缓存的,因此后续我们仅对BoundedLocalCache进行分析。
@NonNull
public <K1 extends K, V1 extends V> LoadingCache<K1, V1> build(
@NonNull CacheLoader<? super K1, V1> loader) {
requireWeightWithWeigher();
@SuppressWarnings("unchecked")
Caffeine<K1, V1> self = (Caffeine<K1, V1>) this;
return isBounded() || refreshAfterWrite()
? new BoundedLocalCache.BoundedLocalLoadingCache<>(self, loader)
: new UnboundedLocalCache.UnboundedLocalLoadingCache<>(self, loader);
}
// 有界?无界
boolean isBounded() {
return (maximumSize != UNSET_INT)
|| (maximumWeight != UNSET_INT)
|| (expireAfterAccessNanos != UNSET_INT)
|| (expireAfterWriteNanos != UNSET_INT)
|| (expiry != null)
|| (keyStrength != null)
|| (valueStrength != null);
}
boolean refreshAfterWrite() {
return refreshAfterWriteNanos != UNSET_INT;
}
BoundedLocalCache类
跟进上诉例子中的get方法,定位到LoadingCache接口,其具体实现位于BoundedLocalCache中的computeIfAbsent()方法。
final ConcurrentHashMap<Object, Node<K, V>> data;
@Override
public @Nullable V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction,
boolean recordStats, boolean recordLoad) {
requireNonNull(key);
requireNonNull(mappingFunction);
long now = expirationTicker().read();
// An optimistic fast path to avoid unnecessary locking
Node<K, V> node = data.get(nodeFactory.newLookupKey(key));
if (node != null) {
V value = node.getValue();
if ((value != null) && !hasExpired(node, now)) {
if (!isComputingAsync(node)) {
tryExpireAfterRead(node, key, value, expiry(), now);
setAccessTime(node, now);
}
afterRead(node, now, /* recordHit */ recordStats);
return value;
}
}
if (recordStats) {
mappingFunction = statsAware(mappingFunction, recordLoad);
}
Object keyRef = nodeFactory.newReferenceKey(key, keyReferenceQueue());
return doComputeIfAbsent(key, keyRef, mappingFunction, new long[] { now }, recordStats);
}
这里的逻辑是先查key对应的Node是否存在,如果存在则进一步判断node中的value是否存在以及node是否过期,未过期且需要同步计算则tryExpireAfterRead并setAccessTime,之后进行读后的后处理工作,并返回查到的值。
如果缓存不存在,则进行doComputeIfAbsent逻辑。
@Nullable V doComputeIfAbsent(K key, Object keyRef,
Function<? super K, ? extends V> mappingFunction, long[/* 1 */] now, boolean recordStats) {
@SuppressWarnings("unchecked")
V[] oldValue = (V[]) new Object[1];
@SuppressWarnings("unchecked")
V[] newValue = (V[]) new Object[1];
@SuppressWarnings("unchecked")
K[] nodeKey = (K[]) new Object[1];
@SuppressWarnings({"unchecked", "rawtypes"})
Node<K, V>[] removed = new Node[1];
int[] weight = new int[2]; // old, new
RemovalCause[] cause = new RemovalCause[1];
Node<K, V> node = data.compute(keyRef, (k, n) -> {
if (n == null) {
newValue[0] = mappingFunction.apply(key);
if (newValue[0] == null) {
return null;
}
now[0] = expirationTicker().read();
weight[1] = weigher.weigh(key, newValue[0]);
n = nodeFactory.newNode(key, keyReferenceQueue(),
newValue[0], valueReferenceQueue(), weight[1], now[0]);
setVariableTime(n, expireAfterCreate(key, newValue[0], expiry(), now[0]));
return n;
}
synchronized (n) {
nodeKey[0] = n.getKey();
weight[0] = n.getWeight();
oldValue[0] = n.getValue();
if ((nodeKey[0] == null) || (oldValue[0] == null)) {
cause[0] = RemovalCause.COLLECTED;
} else if (hasExpired(n, now[0])) {
cause[0] = RemovalCause.EXPIRED;
} else {
return n;
}
writer.delete(nodeKey[0], oldValue[0], cause[0]);
newValue[0] = mappingFunction.apply(key);
if (newValue[0] == null) {
removed[0] = n;
n.retire();
return null;
}
weight[1] = weigher.weigh(key, newValue[0]);
n.setValue(newValue[0], valueReferenceQueue());
n.setWeight(weight[1]);
now[0] = expirationTicker().read();
setVariableTime(n, expireAfterCreate(key, newValue[0], expiry(), now[0]));
setAccessTime(n, now[0]);
setWriteTime(n, now[0]);
return n;
}
});
if (node == null) {
if (removed[0] != null) {
afterWrite(new RemovalTask(removed[0]));
}
return null;
}
if (cause[0] != null) {
if (hasRemovalListener()) {
notifyRemoval(nodeKey[0], oldValue[0], cause[0]);
}
statsCounter().recordEviction(weight[0], cause[0]);
}
if (newValue[0] == null) {
if (!isComputingAsync(node)) {
tryExpireAfterRead(node, key, oldValue[0], expiry(), now[0]);
setAccessTime(node, now[0]);
}
afterRead(node, now[0], /* recordHit */ recordStats);
return oldValue[0];
}
if ((oldValue[0] == null) && (cause[0] == null)) {
afterWrite(new AddTask(node, weight[1]));
} else {
int weightedDifference = (weight[1] - weight[0]);
afterWrite(new UpdateTask(node, weightedDifference));
}
return newValue[0];
}
这里的主要逻辑是,先按用户提供的方法来构建Node,如果node为null则返回null,否则计算新值并返回。由于要考虑定时失效、权重、后处理、指标统计、移除监听器等问题,这里的代码显得比较复杂。这些功能先跳过到后面再单独介绍。
下面来系统的看下BoundedLocalCache类,上述介绍的原理和设计都可以在这类中找到。强烈建议该类开头的注释要自行阅读下,以更好的理解作者的意图。BoundedLocalCache类的代码是比较规整的,分为多块,限于篇幅这里仅对核心内容进行介绍。结合Caffeine的整体设计图更好理解。
- An in-memory cache implementation that supports full concurrency of retrievals, a high expected concurrency for updates, and multiple ways to bound the cache.
- This class is abstract and code generated subclasses provide the complete implementation for a particular configuration. This is to ensure that only the fields and execution paths necessary for a given configuration are used.
- This class performs a best-effort bounding of a ConcurrentHashMap using a page-replacement algorithm to determine which entries to evict when the capacity is exceeded.
/** The number of CPUs */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/** The initial capacity of the write buffer. */
static final int WRITE_BUFFER_MIN = 4;
/** The maximum capacity of the write buffer. */
static final int WRITE_BUFFER_MAX = 128 * ceilingPowerOfTwo(NCPU);
/** The number of attempts to insert into the write buffer before yielding. */
static final int WRITE_BUFFER_RETRIES = 100;
/** The maximum weighted capacity of the map. */
static final long MAXIMUM_CAPACITY = Long.MAX_VALUE - Integer.MAX_VALUE;
/** The initial percent of the maximum weighted capacity dedicated to the main space. */
static final double PERCENT_MAIN = 0.99d;
/** The percent of the maximum weighted capacity dedicated to the main's protected space. */
static final double PERCENT_MAIN_PROTECTED = 0.80d;
/** The difference in hit rates that restarts the climber. */
static final double HILL_CLIMBER_RESTART_THRESHOLD = 0.05d;
/** The percent of the total size to adapt the window by. */
static final double HILL_CLIMBER_STEP_PERCENT = 0.0625d;
/** The rate to decrease the step size to adapt by. */
static final double HILL_CLIMBER_STEP_DECAY_RATE = 0.98d;
/** The maximum number of entries that can be transfered between queues. */
static final int QUEUE_TRANSFER_THRESHOLD = 1_000;
/** The maximum time window between entry updates before the expiration must be reordered. */
static final long EXPIRE_WRITE_TOLERANCE = TimeUnit.SECONDS.toNanos(1);
/** The maximum duration before an entry expires. */
static final long MAXIMUM_EXPIRY = (Long.MAX_VALUE >> 1); // 150 years
final ConcurrentHashMap<Object, Node<K, V>> data; // 使用一个CHM来保存所有数据
@Nullable final CacheLoader<K, V> cacheLoader;
final PerformCleanupTask drainBuffersTask; // PerformCleanupTask
final Consumer<Node<K, V>> accessPolicy;
final Buffer<Node<K, V>> readBuffer;
final NodeFactory<K, V> nodeFactory;
final ReentrantLock evictionLock;
final CacheWriter<K, V> writer;
final Weigher<K, V> weigher;
final Executor executor;
final boolean isAsync;
// The collection views
@Nullable transient Set<K> keySet;
@Nullable transient Collection<V> values;
@Nullable transient Set<Entry<K, V>> entrySet;
/* --------------- Shared --------------- */
/**
* accessOrderWindowDeque, accessOrderProbationDeque, accessOrderProtectedDeque 三个双向队列
* 对应整体设计图中的紫色队列部分
*/
@GuardedBy("evictionLock")
protected AccessOrderDeque<Node<K, V>> accessOrderWindowDeque() {
throw new UnsupportedOperationException();
}
@GuardedBy("evictionLock")
protected AccessOrderDeque<Node<K, V>> accessOrderProbationDeque() {
throw new UnsupportedOperationException();
}
@GuardedBy("evictionLock")
protected AccessOrderDeque<Node<K, V>> accessOrderProtectedDeque() {
throw new UnsupportedOperationException();
}
@GuardedBy("evictionLock")
protected WriteOrderDeque<Node<K, V>> writeOrderDeque() {
throw new UnsupportedOperationException();
}
/* --------------- Stats Support --------------- */
// StatsCounter, Ticker
/* --------------- Removal Listener Support --------------- */
// RemovalListener
/* --------------- Reference Support --------------- */
// ReferenceQueue
/* --------------- Expiration Support --------------- */
// TimerWheel
/* --------------- Eviction Support --------------- */
// FrequencySketch
// evictEntries: evictFromWindow, evictFromMain, admit
// expireEntries: expirationTicker, expireAfterAccessEntries, expireAfterWriteEntries, expireVariableEntries
// climb
// drainKeyReferences, drainValueReferences
// drainReadBuffer, drainWriteBuffer
/* --------------- Concurrent Map Support --------------- */
// clear, removeNode, containsKey, containsValue, get, put, remove, replace ...
/* --------------- Manual Cache --------------- */
/* --------------- Loading Cache --------------- */
/* --------------- Async Cache --------------- */
/* --------------- Async Loading Cache --------------- */
FrequencySketch类
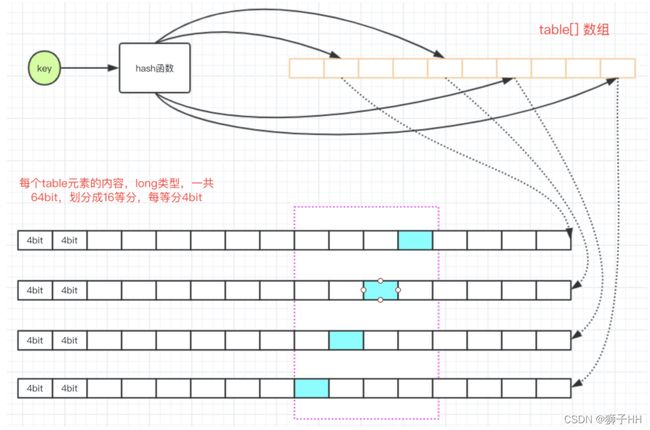
FrequencySketch类对应算法部分的「近似计算」部分,为TinyLFU准入算法提供元素的近似频数统计。具体实现是一个带周期性老化机制的4bit的CM-Sketch ,CM-Sketch高效的时间和空间效率使得估计流式数据中元素的频率变得成本很低。
static final long[] SEED = new long[] { // A mixture of seeds from FNV-1a, CityHash, and Murmur3
0xc3a5c85c97cb3127L, 0xb492b66fbe98f273L, 0x9ae16a3b2f90404fL, 0xcbf29ce484222325L};
static final long RESET_MASK = 0x7777777777777777L;
static final long ONE_MASK = 0x1111111111111111L;
int sampleSize;
int tableMask;
long[] table; // 存储数据的一维Long数组
int size;
/**
* Increments the popularity of the element if it does not exceed the maximum (15). The popularity
* of all elements will be periodically down sampled when the observed events exceeds a threshold.
* This process provides a frequency aging to allow expired long term entries to fade away.
*
* @param e the element to add
*/
public void increment(@NonNull E e) {
if (isNotInitialized()) {
return;
}
int hash = spread(e.hashCode()); // 获取key的hashCode后再做一次hash,担心hashCode不够均匀分散,再打散一次
// table中每位是一个Long占64bit,划分为16个counter,每个占4bit。start用于表示每等分的开始位置
int start = (hash & 3) << 2; // hash值末两位左移2位,得到一个小于16的值
// Loop unrolling improves throughput by 5m ops/s
// 计算hash值在4种不同hash算法下对应的table的下标
int index0 = indexOf(hash, 0);
int index1 = indexOf(hash, 1);
int index2 = indexOf(hash, 2);
int index3 = indexOf(hash, 3);
// table中4个hash算法对应的不同位置的计数器+1
boolean added = incrementAt(index0, start);
added |= incrementAt(index1, start + 1);
added |= incrementAt(index2, start + 2);
added |= incrementAt(index3, start + 3);
// 当计数器达到采样大小时,执行reset操作将所有计数器除2
if (added && (++size == sampleSize)) {
reset();
}
}
/**
* Increments the specified counter by 1 if it is not already at the maximum value (15).
*
* @param i the table index (16 counters) 在table中的位置
* @param j the counter to increment 在分段中的计数器的位置
* @return if incremented
*/
boolean incrementAt(int i, int j) {
int offset = j << 2; // j * 2^2 转为相对偏移量
long mask = (0xfL << offset); // 1111 左移offset位
if ((table[i] & mask) != mask) { // 不等于15时计数器+1
table[i] += (1L << offset);
return true;
}
return false;
}
/** Reduces every counter by half of its original value. */
// reset方法除2的正确性论证见论文3.3.1章节
void reset() {
int count = 0;
for (int i = 0; i < table.length; i++) {
count += Long.bitCount(table[i] & ONE_MASK);
table[i] = (table[i] >>> 1) & RESET_MASK;
}
size = (size >>> 1) - (count >>> 2);
}
/**
* Returns the table index for the counter at the specified depth.
*
* @param item the element's hash
* @param i the counter depth
* @return the table index
*/
int indexOf(int item, int i) {
long hash = (item + SEED[i]) * SEED[i];
hash += (hash >>> 32);
return ((int) hash) & tableMask;
}
/**
* Returns the estimated number of occurrences of an element, up to the maximum (15).
*
* @param e the element to count occurrences of
* @return the estimated number of occurrences of the element; possibly zero but never negative
*/
@NonNegative
public int frequency(@NonNull E e) {
if (isNotInitialized()) {
return 0;
}
// 获取hash值、等分坐标 同 increment
int hash = spread(e.hashCode());
int start = (hash & 3) << 2;
int frequency = Integer.MAX_VALUE;
// 循环获取4种hash方法对应的计数器的最小值
for (int i = 0; i < 4; i++) {
int index = indexOf(hash, i);
// 定位到table[index] + 等分的位置,再根据mask取出计数值
int count = (int) ((table[index] >>> ((start + i) << 2)) & 0xfL);
frequency = Math.min(frequency, count);
}
return frequency;
}
(Ref: https://albenw.github.io/posts/a4ae1aa2/ )
TimerWheel类
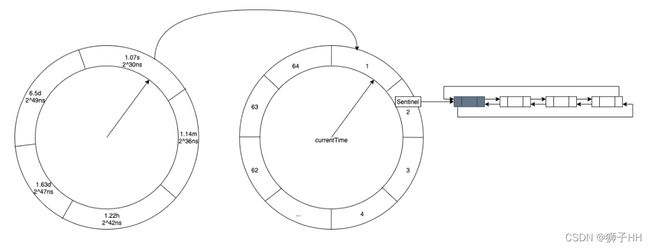
TimerWheel是时间轮算法的实现,本质是一个分层计时器,可在O(1)的均摊时间复杂度下完成过期事件的添加、删除或触发。时间轮的具体实现为一个二维数组,其数组的具体位置存放的则为一个待执行节点的链表。
时间轮的二维数组的第一个维度是具体的时间间隔,分别是秒、分钟、小时、天、4天,但并没有严格按照时间单位来区分单位,而是根据以上单位最接近的2的整数次幂作为时间间隔,因此在其第一个维度的时间间隔分别是1.07s,1.14m,1.22h,1.63d,6.5d。
final class TimerWheel<K, V> {
// 时间轮每层wheel的bucket数量
static final int[] BUCKETS = { 64, 64, 32, 4, 1 };
// 时间轮每层wheel的时间跨度
static final long[] SPANS = {
ceilingPowerOfTwo(TimeUnit.SECONDS.toNanos(1)), // 1.07s = 2^30ns = 1,073,741,824 ns
ceilingPowerOfTwo(TimeUnit.MINUTES.toNanos(1)), // 1.14m = 2^36ns = 68,719,476,736 ns
ceilingPowerOfTwo(TimeUnit.HOURS.toNanos(1)), // 1.22h = 2^42ns = 4,398,046,511,104 ns
ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)), // 1.63d = 2^47ns = 140,737,488,355,328 ns
BUCKETS[3] * ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)), // 6.5d = 2^49ns = 562,949,953,421,312 ns
BUCKETS[3] * ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)), // 6.5d = 2^49ns = 562,949,953,421,312 ns
};
// 时间轮每层wheel的位移偏量
static final long[] SHIFT = {
Long.numberOfTrailingZeros(SPANS[0]), // 30
Long.numberOfTrailingZeros(SPANS[1]), // 36
Long.numberOfTrailingZeros(SPANS[2]), // 42
Long.numberOfTrailingZeros(SPANS[3]), // 47
Long.numberOfTrailingZeros(SPANS[4]), // 49
};
final BoundedLocalCache<K, V> cache;
final Node<K, V>[][] wheel;
long nanos;
// 初始化wheel,一个二维数组
@SuppressWarnings({"rawtypes", "unchecked"})
TimerWheel(BoundedLocalCache<K, V> cache) {
this.cache = requireNonNull(cache);
// wheel中每个元素是个Node,第一维是BUCKETS的数量即5,表示时间轮的层数
wheel = new Node[BUCKETS.length][1];
for (int i = 0; i < wheel.length; i++) {
// 第二维表示每层时间轮的bucket数量,分别是64, 64, 32, 4, 1
wheel[i] = new Node[BUCKETS[i]];
// wheel中存储的是双向链表的哨兵Sentinel(用来简化边界问题的虚设对象)
for (int j = 0; j < wheel[i].length; j++) {
wheel[i][j] = new Sentinel<>();
}
}
}
/**
* 向前推进时间并将已失效元素驱逐出去
*/
public void advance(long currentTimeNanos) {
long previousTimeNanos = nanos;
try {
nanos = currentTimeNanos;
// If wrapping, temporarily shift the clock for a positive comparison
if ((previousTimeNanos < 0) && (currentTimeNanos > 0)) {
previousTimeNanos += Long.MAX_VALUE;
currentTimeNanos += Long.MAX_VALUE;
}
for (int i = 0; i < SHIFT.length; i++) {
// 无符号右移(>> sign-propagating, >>> zero-fill right shift)
long previousTicks = (previousTimeNanos >>> SHIFT[i]);
long currentTicks = (currentTimeNanos >>> SHIFT[i]);
// 如果当前时间和之前的时间落在同一个bucket中或滞后于之前的时间,说明无需向前推进,结束
if ((currentTicks - previousTicks) <= 0L) {
break;
}
// 处理previous和当前tick之间的bucket中的元素,失效元素或将仍存活的元素放到合适的bucket中
expire(i, previousTicks, currentTicks);
}
} catch (Throwable t) {
nanos = previousTimeNanos;
throw t;
}
}
/**
* Expires entries or reschedules into the proper bucket if still active.
*
* @param index the wheel being operated on
* @param previousTicks the previous number of ticks
* @param currentTicks the current number of ticks
*/
void expire(int index, long previousTicks, long currentTicks) {
Node<K, V>[] timerWheel = wheel[index];
int mask = timerWheel.length - 1;
int steps = Math.min(1 + Math.abs((int) (currentTicks - previousTicks)), timerWheel.length);
int start = (int) (previousTicks & mask);
int end = start + steps;
for (int i = start; i < end; i++) {
Node<K, V> sentinel = timerWheel[i & mask];
Node<K, V> prev = sentinel.getPreviousInVariableOrder();
Node<K, V> node = sentinel.getNextInVariableOrder();
sentinel.setPreviousInVariableOrder(sentinel);
sentinel.setNextInVariableOrder(sentinel);
while (node != sentinel) {
Node<K, V> next = node.getNextInVariableOrder();
node.setPreviousInVariableOrder(null);
node.setNextInVariableOrder(null);
try {
if (((node.getVariableTime() - nanos) > 0)
|| !cache.evictEntry(node, RemovalCause.EXPIRED, nanos)) {
schedule(node);
}
node = next;
} catch (Throwable t) {
node.setPreviousInVariableOrder(sentinel.getPreviousInVariableOrder());
node.setNextInVariableOrder(next);
sentinel.getPreviousInVariableOrder().setNextInVariableOrder(node);
sentinel.setPreviousInVariableOrder(prev);
throw t;
}
}
}
}
/**
* Schedules a timer event for the node.
*
* @param node the entry in the cache
*/
public void schedule(@NonNull Node<K, V> node) {
Node<K, V> sentinel = findBucket(node.getVariableTime());
link(sentinel, node);
}
/**
* Reschedules an active timer event for the node.
*
* @param node the entry in the cache
*/
public void reschedule(@NonNull Node<K, V> node) {
if (node.getNextInVariableOrder() != null) {
unlink(node);
schedule(node);
}
}
/**
* Removes a timer event for this entry if present.
*
* @param node the entry in the cache
*/
public void deschedule(@NonNull Node<K, V> node) {
unlink(node);
node.setNextInVariableOrder(null);
node.setPreviousInVariableOrder(null);
}
/**
* Determines the bucket that the timer event should be added to.
*
* @param time the time when the event fires
* @return the sentinel at the head of the bucket
*/
Node<K, V> findBucket(long time) {
// 事件触发时间与当前时间轮转动时间的差
long duration = time - nanos;
int length = wheel.length - 1;
for (int i = 0; i < length; i++) {
// 1.07s, 1.14m, 1.22h, 1.63d, 6.5d 依次判断
// 如果时间差比下一个时间轮的跨度小则落在当前时间轮,比如时间差是20s,小于1.14m,落在第一层wheel[0]中
if (duration < SPANS[i + 1]) {
// 计算应该落在第一层的哪个bucket中,通过hash函数映射到其中一个
long ticks = (time >>> SHIFT[i]);
int index = (int) (ticks & (wheel[i].length - 1));
return wheel[i][index];
}
}
// 没有合适的位置就放最高层
return wheel[length][0];
}
/** Adds the entry at the tail of the bucket's list. */
// 带哨兵节点的双链表尾插法
void link(Node<K, V> sentinel, Node<K, V> node) {
node.setPreviousInVariableOrder(sentinel.getPreviousInVariableOrder());
node.setNextInVariableOrder(sentinel);
sentinel.getPreviousInVariableOrder().setNextInVariableOrder(node);
sentinel.setPreviousInVariableOrder(node);
}
/** Removes the entry from its bucket, if scheduled. */
void unlink(Node<K, V> node) {
Node<K, V> next = node.getNextInVariableOrder();
if (next != null) {
Node<K, V> prev = node.getPreviousInVariableOrder();
next.setPreviousInVariableOrder(prev);
prev.setNextInVariableOrder(next);
}
}
/** Returns the duration until the next bucket expires, or {@link Long.MAX_VALUE} if none. */
@SuppressWarnings("IntLongMath")
public long getExpirationDelay() {
for (int i = 0; i < SHIFT.length; i++) {
Node<K, V>[] timerWheel = wheel[i];
long ticks = (nanos >>> SHIFT[i]);
long spanMask = SPANS[i] - 1;
int start = (int) (ticks & spanMask);
int end = start + timerWheel.length;
int mask = timerWheel.length - 1;
for (int j = start; j < end; j++) {
Node<K, V> sentinel = timerWheel[(j & mask)];
Node<K, V> next = sentinel.getNextInVariableOrder();
if (next == sentinel) {
continue;
}
long buckets = (j - start);
long delay = (buckets << SHIFT[i]) - (nanos & spanMask);
delay = (delay > 0) ? delay : SPANS[i];
for (int k = i + 1; k < SHIFT.length; k++) {
long nextDelay = peekAhead(k);
delay = Math.min(delay, nextDelay);
}
return delay;
}
}
return Long.MAX_VALUE;
}
}
时间轮整体结构
| 层(wheel) | 刻度(bucket) | 每层时间跨度(span) | 偏移位数(shift) | 滴答一次时间(tick) |
|---|---|---|---|---|
| 1 | 64 | 1.07s = 2^30ns = 1,073,741,824 ns | 30 | 2^30 /64 = 2^24 ns = 16.7ms |
| 2 | 64 | 1.14m = 2^36ns = 68,719,476,736 ns | 36 | 2^36 /64 = 2^30 ns = 1.07s |
| 3 | 32 | 1.22h = 2^42ns = 4,398,046,511,104 ns | 42 | 2^42 /32 = 2^37 ns = 2.29m |
| 4 | 4 | 1.63d = 2^47ns = 140,737,488,355,328 ns | 47 | 2^47 /4 = 2^45 ns = 9.77h |
| 5 | 1 | 6.5d = 2^49ns = 562,949,953,421,312 ns | 49 | 2^49 /1 = 6.5d |
未完待续…
总结
TODO