音频
- 声音是波,靠物体振动产生。
- 声波三要素:
1、频率:表示音阶的高低。
2、振幅:表示响度。
3、波形:表示音色。在同样的频率和响度下,不同物体发出的声音不一样,比如钢琴和古筝声音就完全不同。波形的形状决定了声音的音色。不同的介质所产生的波形不同,音色也就不同。 - 分贝(decibel):度量声音强度的单位(dB)。
数字化音频
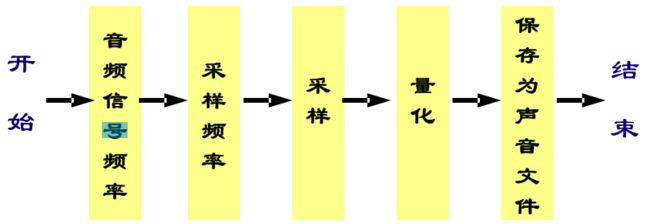
概念:将模拟信号转换为数字信号的过程。
采样->量化->编码
-
模拟信号
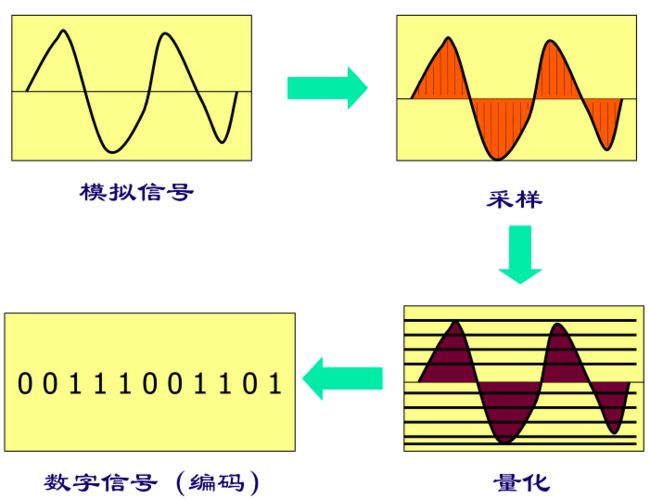
模拟信号:把在时间和幅度上都连续的信号称为模拟信号。
-
音频采样
采样:在某些特定的时刻对这种 模拟信号 进行测量叫做采样。得到的信号称为 离散时间信号。
根据 奈斯特定理(采样定理) 按照比声音最高频率高2倍以上的频率进行采样。这个过程称为AD转换。
比如,高质量音频信号频率范围是20Hz-20KHz。所以采样频率一般是44.1KHz。这样可以保证采样声音达到20KHz也能被数字化。而且经过数字化处理后的声音音质也不会降低。44.1KHZ指的是1秒会采样44100次。
-
量化
量化:把信号幅度取值的数目加以限定,由有限个数值组成的信号称为 离散幅度信号。
是声音波形数据是多少位的二进制数据。通常用bit做单位。
比如16比特的二进制信号来表示声音的一个量化。它的取值范围[-32768,32767],一共有65536个值。如16bit、24bit。16bit量化级记录声音的数据是用16位的二进制数。因此,量化级也是数字声音质量的重要指标。我们形容数字声音的质量,通常就描述为24bit(量化级)、48KHz采样,比如标准CD音乐的质量就是16bit、44.1KHz采样。
-
数字信号
把时间和幅度都用离散的数字表示的信号就称为 数字信号。
-
编码
编码:按照一定的格式记录 采样 和 量化 后的数据。
音频编码的格式有很多种,而通常所说的音频裸数据指的是 脉冲编码调制(PCM) 数据.
如果想要描述一份PCM数据,需要从如下几个方向出发:
1、量化格式(sampleFormat)
2、采样率(sampleRate)
3、声道数(channel)
-
声道数
单声道(mono):信号一次产生一组声波数据。
双声道(stereo):一次产生两组声波数据。双声道在硬件中占有两条线路,一条是左声道,一条是右声道。
立体声不仅音质、音色好,而且能产生逼真的空间感。但是立体声数字化后所占的空间比单声道多一倍。
以CD音质为例,量化格式为16bite,采样率为44100,声道数为2。这些信息描述CD音质。那么可以CD音质数据,比特率bit/s(单位:bps):
44100 * 16 * 2 = 1378.125kbps
那么一分钟的,这类CD音质数据需要占用存储空间:
1378.125 * 60 /8/1024 = 10.09MB
音频编码
CD音质的数据采样,每分钟需要存储空间为10.09MB。从存储的角度或者网络实时传播的角度,这个数据量都是太大了,对于存储和传输都是非常具有挑战的。所以我们需要通过压缩编码。
压缩编码的基本指标就是 压缩比,压缩比 通常小于1(如果等于或者大于1,是不是就失去的压缩的意义了,压缩目的就是为了减少数据体量)。压缩算法分为2种,有损压缩 和 无损压缩。
- 无损压缩:解压后的数据可以完全复原。在常用的压缩格式中,用的较多的都是有损压缩。
- 有损压缩:解压后的数据不能完全复原,会丢失一部分信息。压缩比越小,丢失的信息就会越多,信号还原的失真就会越大。
需要根据不同的场景(考虑因素包括存储设备,传输网络环境,播放设备等),可以选用不同压缩编码算法。
压缩编码的原理实际上就是压缩冗余的信号。冗余信号就是指不能被人耳感知的信号。包括人耳听觉范围之外的音频信号以及被掩盖掉的音频信号。
编码分类:
-
1、波形编码
波形编码:不利用生成音频信号的任何参数,直接将 时间域信号 变换为 数字代码,使重构的语音波形尽可能地与原始语音信号的 波形形状 保持一致。
波形编码的基本原理:在 时间轴 上对模拟语音信号按一定的速率抽样,然后将幅度样本分层量化,并用代码表示。
优点:波形编码方法简单、易于实现、适应能力强并且语音质量好。
缺点:压缩比相对较低,导致较高的编码率。
-
2、参数编码
参数编码:从语音 波形信号 中提取生成语音的参数,使用这些参数通过语音生成模型重构出语音,使重构的语音信号尽可能地保持原始语音信号的语意。也就是说,参数编码是把语音信号产生的数字模型作为基础,然后求出数字模型的模型参数,再按照这些参数还原数字模型,进而合成语音。
优点:编码率较低,保密性好。
缺点:可能会失真比较大,音质低。
-
3、混合编码
混合编码是指同时使用两种或两种以上的编码方法进行编码。这种编码方法克服了波形编码和参数编码的弱点,并结合了波形编码高质量和参数编码的低编码率,能够取得比较好的效果。
常用压缩编码格式:
-
1、WAV编码(波形编码)
WAV是编码的一种实现方式(其实它有非常多实现方式,但都是不会进行压缩操作)。就是在源 PCM 数据格式的前面加上44个字节。分别用来描述 PCM 的采样率、声道数、数据格式等信息。
特点:音质非常好,大量软件都支持其播放。
适合场合:多媒体开发的中间文件,保存音乐和音效素材。
-
2、MP3编码
MP3编码具有不错的压缩比,而且听感也接近于WAV文件,当然在不同的环境下,应该调整合适的参数来达到更好的效果。
特点:音质在128Kbit/s以上表现不错,压缩比比较高。大量软件和硬件都支持。兼容性高。
适合场合:高比特率下对兼容性有要求的音乐欣赏。
-
3、AAC编码
AAC是目前比较热门的有损压缩编码技术,并且衍生了LC-AAC、HE-AAC、HE-AAC v2 三种主要编码格式。
LC-AAC:是比较传统的AAC,主要应用于中高码率的场景编码(>= 80Kbit/s)
HE-AAC: 主要应用于低码率场景的编码(<= 48Kbit/s)
特点:在小于128Kbit/s的码率下表现优异,并且多用于视频中的音频编码
适合场景:于128Kbit/s以下的音频编码,多用于视频中的音频轨的编码。
-
4、Ogg编码(有损)
Ogg编码是一种非常有潜力的编码,在各种码率下都有比较优秀的表现。尤其在低码率场景下。Ogg除了音质好之外,Ogg的编码算法也是非常出色。可以用更小的码率达到更好的音质。128Kbit/s的Ogg比192Kbit/s甚至更高码率的MP3更优质.但目前由软件还是硬件支持问题,都没法达到与MP3的使用广度.
特点:可以用比MP3更小的码率实现比MP3更好的音质,高中低码率下均有良好的表现,兼容不够好,流媒体特性不支持。
适合场景:语言聊天的音频消息场景。
参考文章 音频编码