准备工作
首先应当安装有Python3环境的机器,还要安装requests,lxml库,编译器呢我选择的是PyCharm。
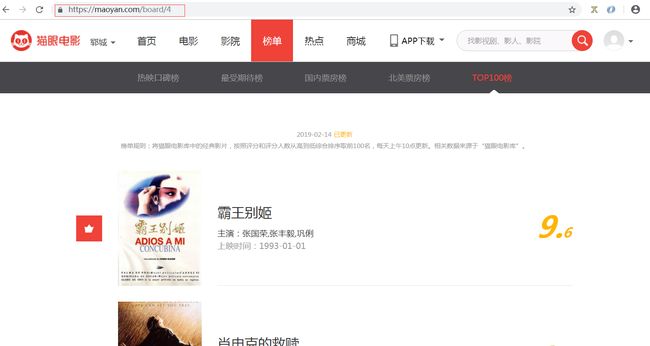
这里是猫眼网Top100榜的界面
代码部分
首先定义一个类,然后定义一个发送请求的方法,利用requests库模拟发送请求,并加上简单的反爬机制.
import requests
class Spider(object):
def start_requests(self):
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0"}
response = requests.get("https://maoyan.com/board/4",headers=headers)
print(response.text)
spider=Spider()
spider.start_requests()
然后我们就能得到返回的网页信息,截取其中我们需要的信息.
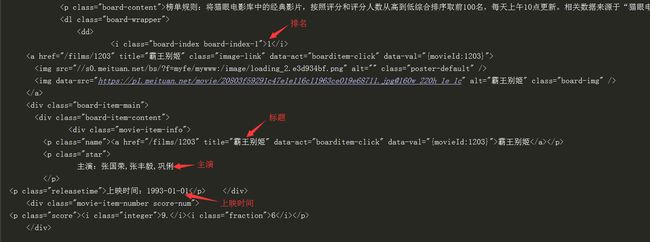
然后分析源码,写出对应的xpath语法来获取我们所需要的信息,使用xpath语法需要导入lxml库,这个就不再过多叙述,直接看代码
import requests
from lxml import etree
class Spider(object):
def start_requests(self):
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0"}
response = requests.get("https://maoyan.com/board/4",headers=headers)
html = etree.HTML(response.text)
ranking_list = html.xpath('//dl[@class="board-wrapper"]/dd/i/text()')
print(ranking_list)
title_list = html.xpath('//div[@class="movie-item-info"]/p[1]/a/text()')
print(title_list)
star_list = html.xpath('//div[@class="movie-item-info"]/p[2]/text()')
print(star_list)
releasetime_list = html.xpath('//div[@class="movie-item-info"]/p[3]/text()')
print(releasetime_list)
spider = Spider()
spider.start_requests()
这时我们就已经获得了需要的数据

这时的数据并未一一对应,所以我们使用zip方法使他们一一对应起来,然后进行输出,可是Python3中zip的使用方法稍有改变,想要输出zip中的数据
需要将其转换为列表,否则输出的是一个对象,详情参见Python3 zip()函数.
print(list(zip(ranking_list, title_list, star_list, releasetime_list)))

可是这时候就又有一个新的问题出现了,主演前面有"\n"和空格字符,不要急,一会就使用一个方法把字符切掉。
下面我们将数据已json的格式进行储存,不要忘记导入json库
for ranking, title, star, releasetime in zip(ranking_list, title_list, star_list, releasetime_list):
items = {"排名:": ranking,"标题:":title,"主演:":star.strip(),"上映时间:":releasetime}
content = json.dumps(items, ensure_ascii=False) + "\n"
with open("maoyantop.json","a",encoding="utf-8") as f:
f.write(content)
嘿嘿,同学们发现什么不一样的地方了吗,就是strip()方法来去除多余字符
这样我们就成功拿到了第一页的数据,生成了一个名为maoyantop的json文件
[图片上传失败...(image-ea168e-1553136318441)]
可是我们要拿到所有的数据那,这时候我们观察一下换页时链接的规律
[图片上传失败...(image-2209ad-1553136318441)]
由此我们发现点击第二页是链接中多出了offset=10,第三页中offset=20,我们就找到了规律,所以使用range()函数和for循环进行多页数据的处理
完整代码如下
import requests
from lxml import etree
import json
class Spider(object):
def multipage(self):
for i in range(0,91,10):
url = 'https://maoyan.com/board/4?offset=' + str(i)
self.start_requests(url)
def start_requests(self,url):
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0"}
response = requests.get(url,headers=headers)
html = etree.HTML(response.text)
ranking_list = html.xpath('//dl[@class="board-wrapper"]/dd/i/text()')
title_list = html.xpath('//div[@class="movie-item-info"]/p[1]/a/text()')
star_list = html.xpath('//div[@class="movie-item-info"]/p[2]/text()')
releasetime_list = html.xpath('//div[@class="movie-item-info"]/p[3]/text()')
print(list(zip(ranking_list, title_list, star_list, releasetime_list)))
for ranking, title, star, releasetime in zip(ranking_list, title_list, star_list, releasetime_list):
items = {"排名:": ranking,"标题:":title,"主演:":star.strip(),"上映时间:":releasetime}
content = json.dumps(items, ensure_ascii=False) + "\n"
with open("maoyantop.json","a",encoding="utf-8") as f:
f.write(content)
spider = Spider()
spider.multipage()
爬取数据如下
[图片
总结
到此我们的程序大工告成,其中最主要的部分就是requests库的使用和对xpath语法.
有什么问题欢迎在下方留言哦!