SpiderFlow可视化爬虫教程4(获取水情信息为例子)
第一步:浏览网站,查看数据结构
直接找有有id属性的最小父元素,那就是id为Marquee_4_3的这个div元素。
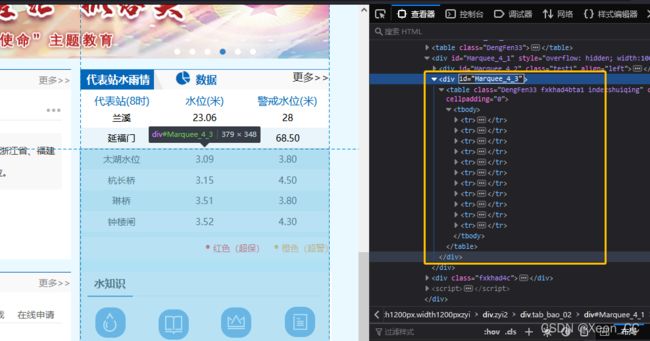
第二步 检查输出是否正常
点击小虫,设置URL
![]()
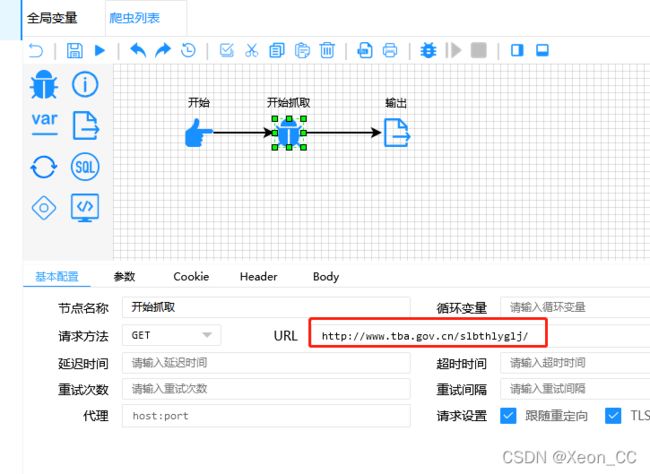
点击输出,看能不能输出那个id为Marquee_4_3的最小父元素。
输出项:test_output
输出值:${resp.xpaths('//*[@id="Marquee_4_3"]')}

点击启动爬虫按钮以后发现如下图:
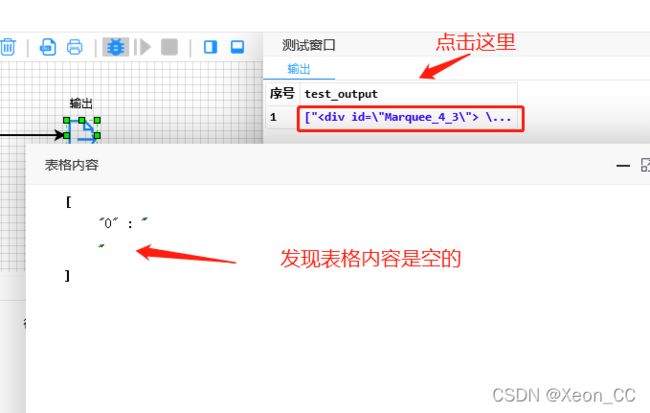
这种现象说明,想要的数据不是直接从网页URL里面来的。
第三步:套路都一样,查看浏览器网络请求,查看哪些数据跟你想要的数据对得上
如果第二步不行,直接跳过,看第三步。
先打开火狐浏览器,火狐浏览器是中文的,那就用火狐吧。
按F12以后调出控制台,点击网络->点击XHR

然后,刷新页面,刷新完成之后,看一看到3个POST请求。

逐个点开看看,查看它们的响应数据长什么样。我直接点最后一个好了,因为最后一个是我们想要的数据。
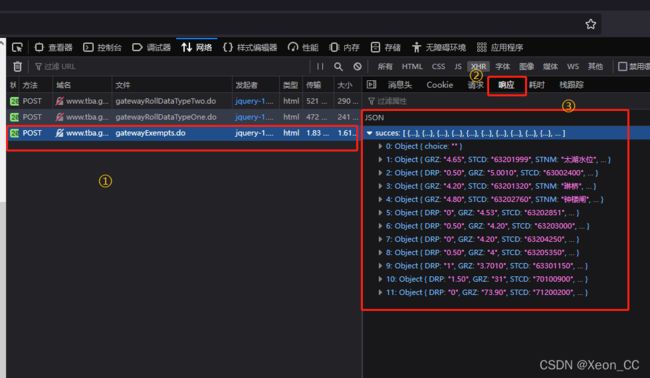
展开数据看一看,数据是一 一对应的,那就没错了,就是它了。
点击消息头,然后复制URL地址,这个URL地址才是我们真正需要爬虫的地方。

查看有没有请求参数(这是一个好习惯,每次要检查一下有没有请求参数)
我们发现这里是有两个请求参数,待会要在spiderflow里面设置。
请求参数:
参数名 参数值
LY Get_Water
TM 2022-01-27

第四步:开始使用spiderflow配置参数
点击小虫设置URL地址:
URL:http://www.tba.gov.cn/TrueCMS/gatewayController/gatewayExempts.do
并设置超时时间: 600000
设置重试间隔:3000

还是点击小虫,选择下面的 “参数“ 选项
参数名 参数值
LY Get_Water
TM 2022-01-27

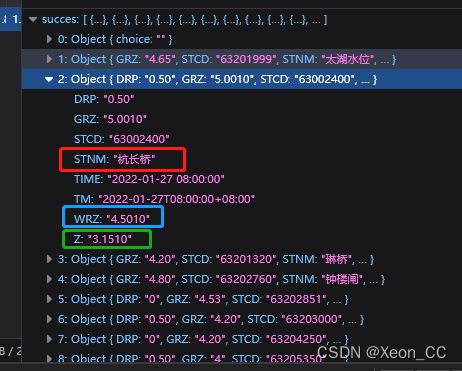
查看返回的数据结构长什么样子,整个红框记


认识Json对象的构成:
例如这样一个对象:
{"name": "小明", "age": "18", "hobby": ["玩游戏", "打篮球", "阅读"]}
花括号内”东西”,全部都是用逗号隔开的键值对表示,”aaa“: "bbb" 这样表示一个键值对。
中括号内的“东西”,全部都是单个的,即有外层包裹着的,例如一个字符串 “hello” , 一个列表 ["a","b","c"] , 一个对象{“xxx”:"yyy", "ccc": "bbb"} ,总之可以看多一个整体的,都可以放到这种花括号以内,并且用逗号隔开。
凡是 “xxx”:“yyy” 这种格式的,看起来分裂的,有点不顺眼的,统一都放在花括号里面,并且用逗号隔开。
看到下面这个数据结构,大家一定要习惯性把整体看作一个json_obj,
乍一看,这个对象有一个succes属性,它的值是一个包含12个对象的列表。
只要是对象,最外层一定是一个键值对。

配置变量
变量名 变量值
json_str ${resp.html}
json_obj ${json.parse(json_str)}
items ${json_obj['succes']}

配置第二个变量
变量名:item
变量值:${items[i+1]}
循环变量:i
循环次数:${items.size()-1}
因为在这个json对象中,第一个对象是没有内容的,从第二个开始才有我们想要的数据,所以i是从第二个开始,所以要i+1, 自然,循环次数就 ${items.size()-1}了

配置输出项:
输出项 输出值
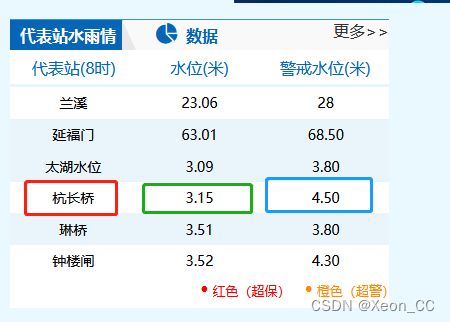
代表站 ${item['STNM']}
水位 ${item['Z']}
警戒水位 ${item['WRZ']}


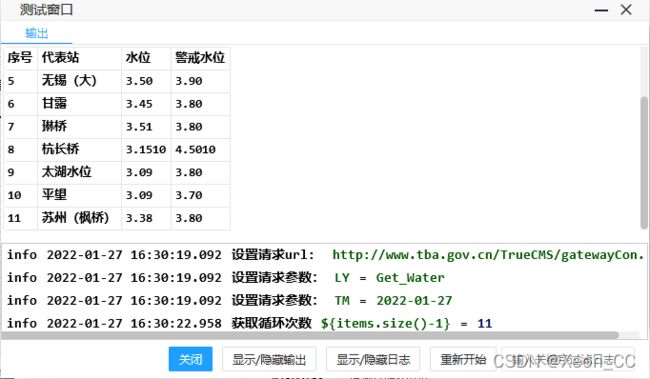
点击启动爬虫
如果发现请求失败,可以尝试设置重试间隔和超时时间,单位是毫秒。
1000毫秒=1秒

爬取成功
第五步:配置并写入数据库
配置数据源:
数据源名称(随意):水利部太湖流域管理局
DriverClassName:com.mysql.jdbc.Driver
数据库连接:jdbc:mysql://localhost:3306/rain_db
用户名:root
密码:root
测试连接通过以后保存。

设计表以后保存。
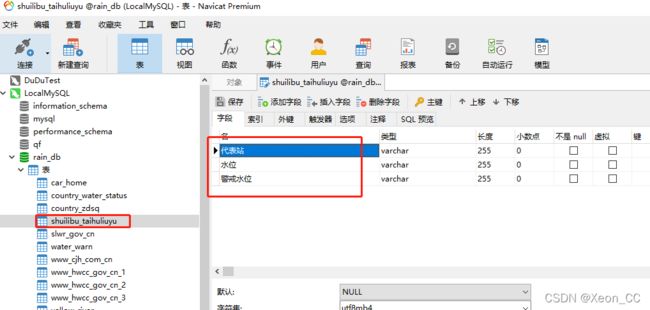

点击启动爬虫的按钮,然后数据已经写入到数据库:
