本文将会介绍如何使用 Flume、log4j、Kafka进行规范的日志采集。
Flume 基本概念
Flume是一个完善、强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说明不再详细赘述。
Flume包含Source、Channel、Sink三个最基本的概念:
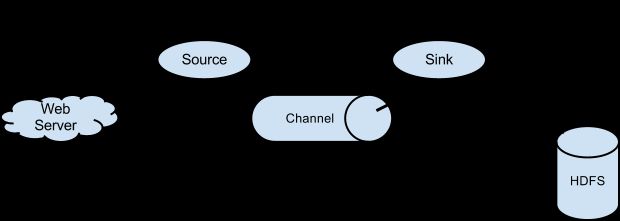
Source——日志来源,其中包括:Avro Source、Thrift Source、Exec Source、JMS Source、Spooling Directory Source、Kafka Source、NetCat Source、Sequence Generator Source、Syslog Source、HTTP Source、Stress Source、Legacy Source、Custom Source、Scribe Source以及Twitter 1% firehose Source。
Channel——日志管道,所有从Source过来的日志数据都会以队列的形式存放在里面,它包括:Memory Channel、JDBC Channel、Kafka Channel、File Channel、Spillable Memory Channel、Pseudo Transaction Channel、Custom Channel。
Sink——日志出口,日志将通过Sink向外发射,它包括:HDFS Sink、Hive Sink、Logger Sink、Avro Sink、Thrift Sink、IRC Sink、File Roll Sink、Null Sink、HBase Sink、Async HBase Sink、Morphline Solr Sink、Elastic Search Sink、Kite Dataset Sink、Kafka Sink、Custom Sink。
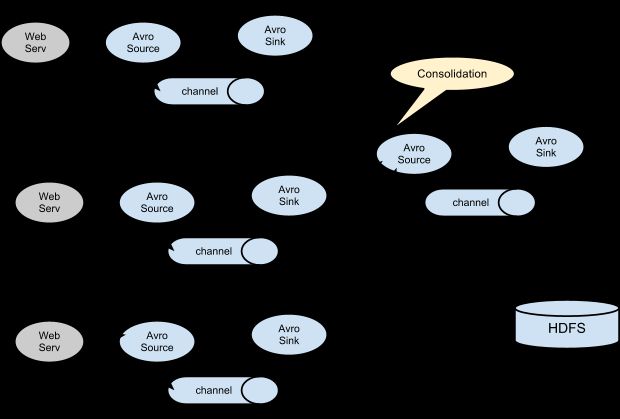
基于Flume的日志采集是灵活的,我们可以看到既有Avro Sink也有Avro Source,既有Thrift Sink也有Thrift Source,这意味着我们可以将多个管道处理串联起来,如下图所示:

串联的意义在于,我们可以将多个管道合并到一个管道中最终输出到同一个Sink中去,如下图:
上面讲述了Source和Sink的作用,而Channel的作用在于处理不同的Sink,假设我们一个Source要对应多个Sink,则只需要为一个Source建立多个Channel即可,如下所示:
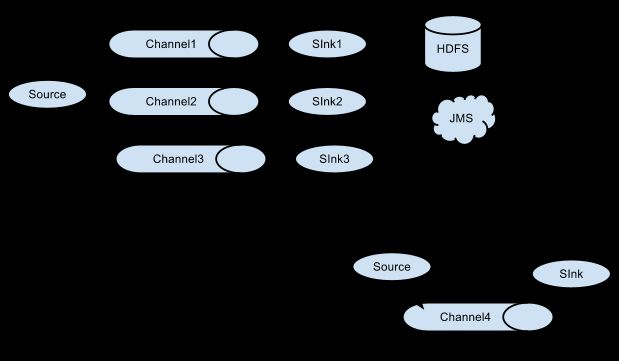
rce如果想要输出到多个Sink中去,就需要建立多个Channel进行介入并最终输出,通过上面这几张图,我们可以很好的理解Flume的运行机制,我们在这里也就点到为止,详细的配置可以在官网或者在网上搜索到、查看到。
一般情况下,我们使用 Exec Source对log文件进行监控,这样做确实是比较简单,但是并不方便,我们需要在每一台要监控的服务器上部署Flume,对运维来讲万一目标日志文件发生IO异常(例如格式改变、文件名改变、文件被锁),也是很痛苦的,因此我们最好能让日志直接通过Socket发送出去,而不是存放在本地,这样一来,不仅降低了目标服务器的磁盘占用,还能够有效的防止文件IO异常,而Kafka就是一个比较好的解决方案,具体的架构如下图所示:
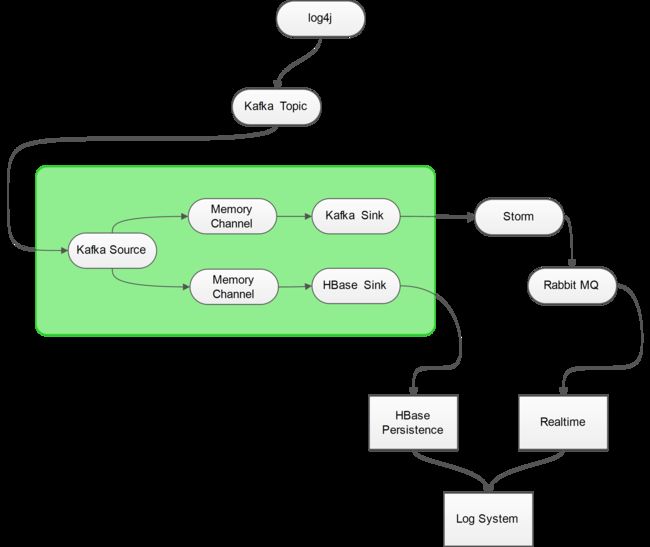
由上图可以看到,日志最终流向了两个地方:HBase Persistence和Realtime Processor,而至于为什么不用Kafka直接与Storm进行通信的原因是为了将Sotrm逻辑和日志源通过Flume进行隔离,在Storm中对日志进行简单的分析后,将结果扔进 Rabbit MQ 中供 WEB APP消费。
HBase Persistence就是将原始的日志记录在HBase中以便回档查询,而Realtime Processor则包含了实时的日志统计以及错误异常邮件提醒等功能。
为了能够准确的捕获到异常数据,我们还需要对程序进行一些规范化的改造,例如提供统一的异常处理句柄等等。
日志输出格式
{"timeMillis" : 1462712870612,"thread" : "main","level" : "FATAL","loggerName" : "com.banksteel.log.demo.log4j2.Demo","message" : "发生了一个可能会影响程序继续运行下去的异常!","thrown": {"commonElementCount" : 0,"localizedMessage" : "错误消息啊","message" : "错误消息啊","name" : "java.lang.Exception","extendedStackTrace": [ {"class" : "com.banksteel.log.demo.log4j2.Demo","method" : "main","file" : "Demo.java","line" : 20,"exact" :true,"location" : "classes/","version" : "?"}, {"class" : "sun.reflect.NativeMethodAccessorImpl","method" : "invoke0","file" : "NativeMethodAccessorImpl.java","line" : -2,"exact" :false,"location" : "?","version" : "1.7.0_80"}, {"class" : "sun.reflect.NativeMethodAccessorImpl","method" : "invoke","file" : "NativeMethodAccessorImpl.java","line" : 57,"exact" :false,"location" : "?","version" : "1.7.0_80"}, {"class" : "sun.reflect.DelegatingMethodAccessorImpl","method" : "invoke","file" : "DelegatingMethodAccessorImpl.java","line" : 43,"exact" :false,"location" : "?","version" : "1.7.0_80"}, {"class" : "java.lang.reflect.Method","method" : "invoke","file" : "Method.java","line" : 606,"exact" :false,"location" : "?","version" : "1.7.0_80"}, {"class" : "com.intellij.rt.execution.application.AppMain","method" : "main","file" : "AppMain.java","line" : 144,"exact" :true,"location" : "idea_rt.jar","version" : "?"} ]
},"endOfBatch" :false,"loggerFqcn" : "org.apache.logging.log4j.spi.AbstractLogger","source": {"class" : "com.banksteel.log.demo.log4j2.Demo","method" : "main","file" : "Demo.java","line" : 23}
}
我们看到,这种格式,无论用什么语言都能轻松解析了。
日志框架的Kafka集成
我们这里只用log4j 1.x 和 log4j 2.x 进行示例。
http://www.linuxidc.com/Linux/2016-05/131402.htm