数据结构与算法-java笔记一 更新中
数据结构与算法-java笔记一 更新中
- 数据结构与算法
-
- 什么是数据结构、算法
-
- 数据结构学了有什么用:
- 线性结构
-
- 数组
-
- 特点
- 应用
- 链表
-
- 存储结构
- 链表类型
-
- 单链表
- 双向链表
- 双向循环链表
- 链表与数组的性能比较
- LinkedList和ArrayList的比较
- Tree
-
- 特点
- 基本术语
- 二叉树
-
- 二叉树的性质
- 二叉查找树,完全二叉树,满二叉树
-
- 代码实现
- 平衡二叉树与红黑树
-
- 二叉查找树存在的问题
- 解决方案
- 平衡二叉树
- 扩展
-
-
- TreeSet-自然排序与比较器排序
-
- 特性
- 自然排序
- 比较器排序
- 遍历方法
-
数据结构与算法
什么是数据结构、算法
数据结构与算法 数据结构(英语:data structure)是计算机中存储、组织数据的方式。 数据结构是一种具有一定逻辑关系,在计算机中应用某种存储结构,并且封装了相应操作的数据元素集合。它包含三方面的内容,逻辑关系、存储关系及操作
数据结构是指数据对象集以及在计算机中的组织方式,即逻辑结构与物理存储结构,也可以说是一组数据的存储结构。
算法指操作数据的方法,使得数据操作效率更高,更加节省资源。
个人理解:
数据结构是数据在实体计算机中的存储结构,数据本身是一个抽象的概念,包括一切实体或者人为构建出来的事物,可以说是文本,多媒体,用来表示世界各物信息的一种载体,在计算机中数据存储本质上就是一串0与1构成的数据信息。不同数据结构在使用场景中优缺点不同,人类世界是复杂的,不能单单用一种或者几种结构来表示,更多的是针对不同场景下,多种结构混合使用。
例如:学了顺序表和链表,你就知道,在查询操作更多的程序中,应该用顺序表;而在修改操作更多的程序中,应该使用链表;有时候突然发现单向链表不方便怎么办,每次都从头到尾,好麻烦啊,怎么办?你这时就会想到双向链表和循环链表。
学了栈之后,很多涉及后入先出的问题,例如函数递归就用到栈,很多类似的东西,你就会第一时间想到:我会用这东西(数据结构)来去写算法实现这个功能。
算法也就随之而来,表示算法好坏,主要体现在时间复杂度与空间复杂度上,也就是数据已经准备好了,我使用什么方法用它更高效。例如:夏天很热,女朋友给我买了一个大西瓜,有的人选择用刀去切开,这样省时省力;有的人选择横切,拿勺子吃,这样不用担心吃的满脸都是;而有的人选择空手劈西瓜,你不能说人家吃西瓜的方式不对,而是在不同情况下(没有工具)怎么可以吃这个西瓜,怎么让自己更开心得去吃西瓜。算法也是这样,千人千算法,别人用一个快排就能解决的事,你搁那用一堆for做出来,而且还没有人家程序跑的快,消耗资源少。
Tip:要多思考,总结出自己的知识体系。
数据结构学了有什么用:
我感觉有用,但是基本没用上,标准的搬运工。
为什么要学这个,因为面试,考证,学后置技术要用到。
很简单的理,因为需要,不得不学。
线性结构
数组、链表、栈、队列都是线性结构,其特点表现为数据的存储结构像一条长线,每个数据对象最多只有前后两个对象。
就像排队一样,有素质按一条线排队,为线性
树、堆、图等是非线性结构
一堆人, 你挤我,我挤你,人堆人。
数组
数组是一种线性数据结构,是指用一组连续的内存空间,来存储一组具有相同数据类型的数据。
特点
- 高效的随机访问
因为数组元素的访问是通过下标来访问的,计算机可以通过数组的首地址与寻址公式,就能快速找到要访问的元素。
- 低效插入与删除
因为数组内部是一段连续的存储单元,因此为了保证数组的连续性,使得数组的插入与删除效率变得很低。
应用
-
ArrayList
ArrayList可以将数组操作的很多细节封装起来,比如数组插入、删除等,还支持动态扩容。
因为数组本身在创建时候,必须指定大小,因为需要分配连续的存储空间,如果有新的元素插入时,需要重新分配一块更大的空间,将旧数据复制过去。但是,如果使用ArrayList,就可以不需要关心底层的扩容逻辑,ArrayList在存储空间不够的时候,它会自动扩容1.5倍大小,但是因为扩容操作涉及内存申请和数据搬移,所以比较耗时,所以如果事先能确定需要存储空间的大小,最好在创建ArrayList时候,事先指定数据大小。
-
ArrayList源码分析
ArrayList底层是采用数组来进行数据的存储,其次ArrayList提供了相关的方法,来对底层数组中的元素进行操作,包括数据的获取,数据的插入,数据的删除等。
// 实例化ArrayList对象,并赋值,观察其存储方式
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
list.add(10);
}

private void grow(int minCapacity){
// 初始容量
int odlCapacity = elementData.length;
// 1 + 1 / 2 = 1.5 倍 每次按照1.5倍扩容
int newCapacity = odlCapacity + (odlCapacity >> 1);
// 判断是否扩容
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 数组拷贝
elementData = Arrays.copyOf(elementData, newCapacity);
}
链表
Linked List ,是一种物理存储单元上的非连续、非顺序的存储结构。元素的逻辑顺序是通过链表的指针链接实现的,每个结点包括两个部分,一个存储数据元素,一个存储下一个元素的地址。
存储结构
数组:需要一块连续的存储空间,对内存的要求比较高,比如要申请一个1000MB的数组,如果内存中没有连续的足够大的存储空间,即使内存剩余可用空间大于1000MB,仍然会申请失败。
链表:与数组相反,链表不需要一块连续的内存空间,他通过指针将一组零散的内存块串联起来使用,所以申请一个1000MB的链表,只要剩余可用空间大于1000MB,就不会申请失败。
链表类型
单链表
第一个结点为头结点,元素位置记录链表的基地址,每个结点的都存有下一个结点(后继)的地址,而最后一个结点(尾结点)的指针指向空地址NULL。
- 插入与删除

双向链表
顾名思义,支持两个方向遍历链表,但是每个结点不只有一个后继指针指向后面的结点,还有一个前驱指针prev指向前一个结点。
使用这种数据结构,我们可以不再拘束于单链表的单向创建于遍历等操作,大大减少了在使用中存在的问题。
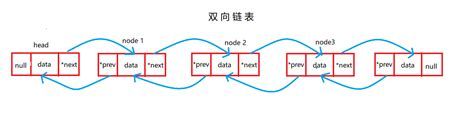
双向循环链表

链表与数组的性能比较
数组简单易用,在实现上使用的连续的内存空间,缺点是大小固定,一经声明就要占用整块连续内存空间,如果数组声明大小过大,系统可能因为没有足够的连续的内存空间分配给他,导致“内存不足”,如果声明数组过小,则可能出现不够用的情况,这时候只能再申请一个更大的内存空间,将原数组拷贝进去,比较耗时。
而链表本身没有大小限制,支持动态扩容。
数组的优势是查询速度非常快,但是增删改慢,而链表的优势是增删改快,查询慢。
LinkedList和ArrayList的比较
-
ArrayList的实现基于数组,LinkedList的实现基于双向链表。
-
对于随机访问,ArrayList优于LinkedList,ArrayList可以根据下标对元素进行随机访问,而LinkedList的每一个元素都依靠地址指针和后一个元素连接在一起,在这种情况下,查找某一个元素只能从链表头开始查询,直到找到为止。
-
对于插入和删除操作,LinkedList优于ArrayList,因为当元素被添加到LinkedList任意位置的时候,不需要想ArrayList那样重新计算大小或者是更新索引。
-
LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。
Tree

特点
(1)每个结点有零个或多个子结点
(2)没有父节点的结点称为根节点
(3)每一个非根结点有且只有一个父节点
(4)除了根结点外,每个子结点可以分为多个不相交的子树。
基本术语
-
结点的度:结点所拥有的子树个数
-
叶子结点:度为0 的结点
-
树的度:结点的最大度
-
层次: 根节点为1,其他依次+1
-
树的高度:树的层级深度
二叉树
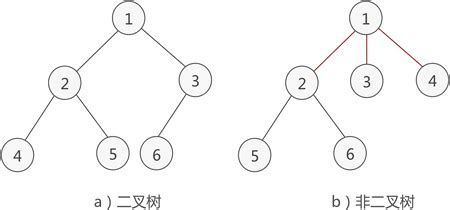
二叉树的性质
-
在二叉树中,第i层的结点树最多为2i-1
-
深度为k的二叉树最多有2k-1个结点
-
包含n个结点的二叉树高度至少为log2n +1
-
n0= n2 +1 (度为0,与度为2)
二叉查找树,完全二叉树,满二叉树
-
二叉查找树
二叉查找树又被称为二叉搜索树
-
若任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值。
-
任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值。
-
任意结点的左、右子树也分别为二叉查找树。
-
没有键值相等的结点。
-
代码实现
import java.util.ArrayList;
import java.util.List;
public class bintree {
public bintree left;
public bintree right;
public bintree root;
// 数据域
private Object data;
// 存节点
public List<bintree> datas;
public bintree(bintree left, bintree right, Object data){
this.left=left;
this.right=right;
this.data=data;
}
// 将初始的左右孩子值为空
public bintree(Object data){
this(null,null,data);
}
public bintree() {
}
public void creat(Object[] objs){
datas=new ArrayList<bintree>();
// 将一个数组的值依次转换为Node节点
for(Object o:objs){
datas.add(new bintree(o));
}
// 第一个数为根节点
root=datas.get(0);
// 建立二叉树
for (int i = 0; i <objs.length/2; i++) {
// 左孩子
datas.get(i).left=datas.get(i*2+1);
// 右孩子
if(i*2+2<datas.size()){//避免偶数的时候 下标越界
datas.get(i).right=datas.get(i*2+2);
}
}
}
//先序遍历
public void preorder(bintree root){
if(root!=null){
System.out.println(root.data);
preorder(root.left);
preorder(root.right);
}
}
//中序遍历
public void inorder(bintree root){
if(root!=null){
inorder(root.left);
System.out.println(root.data);
inorder(root.right);
}
}
// 后序遍历
public void afterorder(bintree root){
if(root!=null){
System.out.println(root.data);
afterorder(root.left);
afterorder(root.right);
}
}
public static void main(String[] args) {
bintree bintree=new bintree();
Object []a={2,4,5,7,1,6,12,32,51,22};
bintree.creat(a);
bintree.preorder(bintree.root);
}
import java.util.Scanner;
public class btree {
private btree left,right;
private char data;
public btree creat(String des){
Scanner scanner=new Scanner(System.in);
System.out.println("des:"+des);
String str=scanner.next();
if(str.charAt(0)<'a')return null;
btree root=new btree();
root.data=str.charAt(0);
root.left=creat(str.charAt(0)+"左子树");
root.right=creat(str.charAt(0)+"右子树");
return root;
}
public void midprint(btree btree){
// 中序遍历
if(btree!=null){
midprint(btree.left);
System.out.print(btree.data+" ");
midprint(btree.right);
}
}
public void firprint(btree btree){
// 先序遍历
if(btree!=null){
System.out.print(btree.data+" ");
firprint(btree.left);
firprint(btree.right);
}
}
public void lastprint(btree btree){
// 后序遍历
if(btree!=null){
lastprint(btree.left);
lastprint(btree.right);
System.out.print(btree.data+" ");
}
}
public static void main(String[] args) {
btree tree = new btree();
btree newtree=tree.creat("根节点");
tree.firprint(newtree);
System.out.println();
tree.midprint(newtree);
System.out.println();
tree.lastprint(newtree);
}
}
输出结果:
des:根节点
a
des:a左子树
e
des:e左子树
c
des:c左子树
1
des:c右子树
1
des:e右子树
b
des:b左子树
1
des:b右子树
1
des:a右子树
d
des:d左子树
f
des:f左子树
1
des:f右子树
1
des:d右子树
1
a e c b d f 先序
c e b a f d 中序
c b e f d a 后序
- 完全二叉树
一棵二叉树中,只有最下面两层结点的度可以小于2,并且最下层的叶结点集中在靠左的若干位置上,这样的二叉树称为完全二叉树。
叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。显然,一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。
如果一棵完全二叉树的结点总数为n,那么叶子结点等于n/2(当n为偶数时)或者(n+1)/2(当n为奇数时)
- 满二叉树
高度为h,并且由2h-1个结点组成的二叉树,称为满二叉树
平衡二叉树与红黑树
二叉查找树存在的问题
在某些极端情况下,二叉查找树有可能变为了链表,树的高度变高了,同时查找效率变低了。
解决方案
- 通过降低树的高度,从而提高查询效率
也就是转换为平衡二叉树
平衡二叉树
平衡二叉树是指,在树中,只能存在一层没有存满的情况,也就是树的各个根节点的左右子树结点树不能超过1.
平衡二叉树就是通过降低树的高度从而提高查询效率。
扩展
TreeSet-自然排序与比较器排序
特性
- TreeSet是有序的(即按照一定的规则排序),是用二叉树实现的。
- TreeSet 的存取顺序无序
自然排序
可以通过comparable接口重写compareTo方法,改写排序规则,来达到按照一定的规则进行排序。
public class Student implements Comparable//该接口强制对实现它的每个类的对象进行强制整体排序
{
private String name;
private int age;
Student (String name,int age){
this.name=name;
this.age =age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public int compareTo(Object obj) {
/* 当this.age > age 时进行升序,反之降序,相等则年龄重复,返回。
*/
if(!(obj instanceof Student))
throw new RuntimeException("不是学生对象");
Student s=(Student)obj;
System.out.println(this.name+"...........compareto..........."+s.name);
if(this.age>s.age)
return 1;
if(this.age==s.age)
{
if(this.age==s.age)
return this.name.compareTo(s.name);//String已经实现了这个CompareTo接口,直接调用方法即可
else
return -1;
}
return -1;
}
}
public class treesetDemo {
public static void main(String[] args) {
TreeSet ts=new TreeSet();
ts.add(new Student("lisi01",19));
ts.add(new Student("lisi02",22));
ts.add(new Student("lisi007",20));
ts.add(new Student("lisi009",19));
ts.add(new Student("lisi01",19));
Iterator it=ts.iterator();
while (it.hasNext()) {
Student s=(Student)it.next();
System.out.println(s.getName()+" "+s.getAge());
}
}
}
比较器排序
构建比较器,通过构造匿名内部类来实现Comparator接口,进行排序。
public static void main(String[] args) {
TreeSet<Student> tree = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int a = o1.getAge() - o2.getAge();
if (a==0){
return o1.getName().compareTo(o2.getName());
//String类型的compareTo()方法
}
return a;
}
});
Student st1 = new Student("小明",10);
Student st2 = new Student("小刚",12);
Student st3 = new Student("小花",13);
Student st4 = new Student("小红",14);
Student st5 = new Student("小强",14);
Student st6 = new Student("小李",16);
tree.add(st1);
tree.add(st2);
tree.add(st3);
tree.add(st4);
tree.add(st5);
tree.add(st6);
for (Student st :tree){
System.out.println(st);
}
}
遍历方法
可以根据根节点的位置,来判断二叉树的排序方式。
- 前序遍历:根 左 右
- 中序遍历:左 根 右
- 后序遍历:左 右 根