第一阶段 hadoop ,参考《hadoop权威指南》(第3版本中文翻译)
hadoop是什么?
面对数据爆炸性增长,传统的技术架构越来越不适应当前海量数据的处理要求,Hadoop就是为应对这方面问题而产生的适合大数据的分布式存储和计算平台,并已经成为海量数据处理的事实标准。
hadoop基于google的google file system和Map-Reduce两篇论文设计,hadoop核心内容包括两部分:分布式文件系统子项目(HDFS)和MapReduce分布式计算的编程模型
hadoop发展进程
- 起源于Apache Nutch(开源的网络搜索引擎,Lucene的子项目)
- 引入新的框架(google相关的gfs和mr)
- 雅虎使用hadoop(2005)
- apache hadoop顶级项目(2008)
HDFS
Hdfs是为以流式数据访问模式存储超大文件而设计的文件系统。
- hdfs并适合一些情形
- 低延迟,要求毫秒范围内的响应
- 大量小文件
- 多用户写,任意修改
hdfs文件系统设计
数据存储最小单位:块
块是hdfs单独的存储单元,要存储在HDFS上的文件,必须以块为大小分块后存储。
分块的优点
1. 一个文件可以超过磁盘的最大容量,文件不需要存在同一个磁盘
2. 简化存储子系统
3. HDFS的块默认64M,大于磁盘块(512个字节),目的是为了减少寻址开销。HDFS文件系统
包括两种节点:一个名称节点和多个数据节点。
名称节点name node:管理文件系统的命名空间。维护这文件系统树和树内的所有的文件和索引目录,也记录每个文件的每个块所在的数据节点。没有名称节点,文件系统将无法工作因此名称节点需要做备份
数据节点data node:存储并提供块的服务,并定时向名称节点发送它存储的块的列表。-
数据流:从hdfs读取数据文件
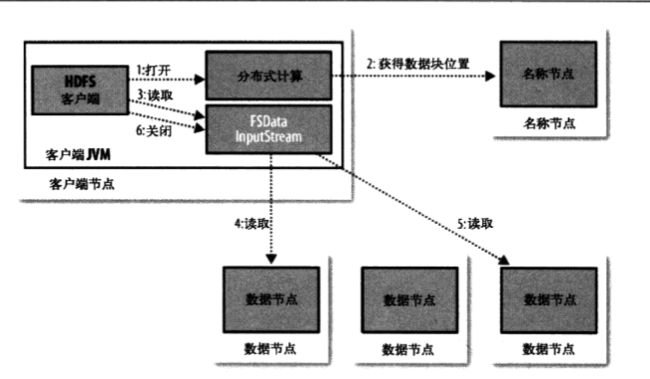 image.png
image.png -
数据流:把文件写入hdfs
 image.png
image.png
MapReduce简介
MapReduce时一种用于数据处理的编程模型,优势在于处理大型数据集,提供并行计算机制,最早由google提出。
MapReduce的工作分为两个阶段:map阶段(映射)和reduce阶段(规约),每个阶段都有键值对作为输入和输出。
MapReduce工作原理
- 客户端提交MapReduce作业 (Job),Hadoop把作业分成若干个小任务(task):map任务和reduce任务
- jobtracker协调作业的运行,通过调度任务在tasktracker上运行任务,jobtracker知道任务执行的进度情况,如果任务执行失败,则重新调度,分配任务到另一个tasktracker
- tasktracker运行具体的任务,并汇报进度给jobtracker。
- 分布式文件系统(一般为hdfs)用来在其他实体间共享作业文件。
备注:map任务把输出写入本地磁盘,而不是hdfs
实践 hadoop安装并运行example
以下内容来自网络学习,包括但不限于
http://dblab.xmu.edu.cn/blog/install-hadoop/
https://blog.csdn.net/qazwsxpcm/article/details/78637874
安装环境:vmware centos6.6虚拟机,hadoop2.8
- jdk1.8安装
- oracle官网下载jdk,然后上传到虚拟机(先安装rz,sz:yum install lrzsz)
- 安装jdk,配置环境变量
解压 tar -xvf jdk1.8_xxx ;
移动 mv jdk1.8_xxx /usr/local/
建立软连接 ln -s jdk1.8_xxx jdk
cd jdk ,配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=/usr/local/jdk/jre
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source /etc/profile #刷新环境变量
java -version
- hadoop单机版和伪分布式安装
参考:http://dblab.xmu.edu.cn/blog/install-hadoop/
https://blog.csdn.net/qazwsxpcm/article/details/78637874
创建hadoop用户和密码
useradd -m hadoop #创建用户hadoop
passwd hadoop #创建用户的密码,比如123456
visudo ,并在文件最近添加sudoer用户 #给用户授予sudo权限
切换到Hadoop用户,安装SSH、配置SSH无密码登陆
centos默认已安装ssh(client和server)
1.修改ssh的配置文件
sudo vi /etc/ssh/sshd_config
把以下3行删除注释符号“#”
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
2.重启sshd服务
service sshd restart
3.非必须,需要修改下安全配置,即关闭selinux
vi /etc/selinux/config
修改以下内容:
将
SELINUX=enforcing
修改为
SELINUX=disabled
4.ssh权限设置
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
5.更改.ssh权限(这一步不能忽略)
chmod -R 700 ~/.ssh
6.访问集群slave
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以删掉了
- hadoop安装
把hadoop2.8.tar.gz mv到/usr/local
# 解压 ,必须要加sudo权限
sudo tar -zxf hadoop-2.8.4.tar.gz
sudo ln -s hadoop-2.8.4 hadoop
# 增加权限
sudo chown -R hadoop ./hadoop
sudo chown -R hadoop ./hadoop-2.8.4
cd /usr/local/hadoop
./bin/hadoop version
# 把hadoophome加入环境变量
vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
执行单机版
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
#最后删除output目录
rm -r ./output
伪分布式
节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
修改涉及的配置文件: /usr/local/hadoop/etc/hadoop/ 中的core-site.xml 和 hdfs-site.xml 和 hadoop-env.sh
#创建临时目录
mkdir /usr/local/hadoop/tmp
vim /usr/local/hadoop/etc/hadoop/core-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh #修改java_home为实际路径
#core-site.xml 指定临时文件夹 ,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
#hdfs-site.xml 指定复制数量
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
- 启动伪分布式
- 执行 NameNode 的格式化 (第一次启动的时候需要,以后就不需要了)
cd /usr/local/hadoop
./bin/hdfs namenode -format
Exiting with status 0 ,表示成功
2.开启 NameNode 和 DataNode 守护进程
#启动dfs
./sbin/start-dfs.sh #停止命令./sbin/stop-dfs.sh
#jps查看
包括namenode、secondnamenode、datanode
curl http://localhost:50070 检查是否访问成功。
通过局域网访问:http://172.16.12.100:50070 ,如果不能访问,请关闭centos防火墙
centos6.5
servcie iptables stop 临时关闭
chkconfig iptables off 永久关闭
servcie iptables status 查看状态
下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以!
启动yarn
上述通过 ./sbin/start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,
我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
1.配置文件 mapred-site.xml
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml #不启动yarn的时候,需要去掉这个文件
vim mapred-site.xml
#内容
mapreduce.framework.name
yarn
vim yarn-site.xml
#内容
yarn.nodemanager.aux-services
mapreduce_shuffle
启动顺序
1.start-dfs.sh
2../sbin/start-yarn.sh # 启动YARN
./sbin/mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
启动 YARN 之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志信息可以发现,不启用 YARN 时,是 “mapred.LocalJobRunner” 在跑任务,启用 YARN 之后,是 “mapred.YARNRunner” 在跑任务。启动 YARN 有个好处是可以通过 Web 界面查看任务的运行情况
http://172.16.12.100:8088/cluster
停止顺序
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
集群安装
注意
- centos 机器的时间要同步
- 使用ip没有成功,用hostname成功
- hdfs命令使用绝对路径
hadoop任务调度框架
- jobtracker、tasktracker --> yarn
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/