第一部分:自动内存管理
总图:
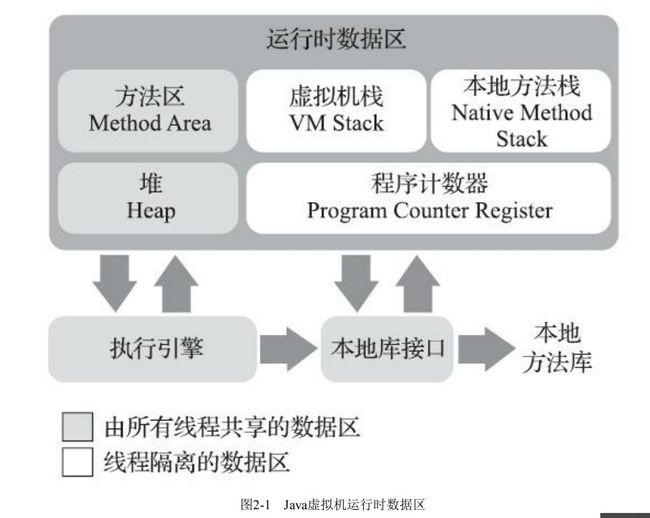
部分名词解释:
slot(槽):指栈中存放局部变量的容器。double、long占2个slot,其他占1个slot。注意:并不用指定一个槽多大。因为局部变量的大小都是确定的。
TLAB:Thread Local Allocation Buffer,线程私有的分配缓冲区。
-
直接内存:Direct Memory,其类似于真实物理内存,是不属于上述运行时数据区的内存分区。保存了对象的实现,而对象的引用可以放在堆内,如此可提高性能。
需要注意配置java堆时(有的jvm必须有最大限制,且有默认值),要考虑上直接内存,否则也会Out Of Memory
OOP:Object Oriented Programming,面向对象编程
Oop: Ordinary Object Pointer,普通对象指针
JMC(Java Mission Control):java任务控制
JFR(Java Flight Recorder):
全限定名:名字里包含了目录,用作接口、类。相对应的是简单名,只是方法或字段的名字。
参数:
-verbose:gc ——打开gc的跟踪日志
-XX:+printGC——打开GC的log的开关,简要日志
-XX:+PrintGCDetails:打印GC的详细信息
-XX:+TraceClassLoading(监控类加载,可以在程序运行时检出哪些类被加载了
-XX:+PrintClassHistogram(加入此参数,在运行时不会有其他东西输出,但是在按下Ctrl+Break后可以打印出类的信息,类的直方图)
-Xmx(最大堆的空间)
-Xms(最小堆的空间)
-Xmn (设置新生代的大小)
-XX:NewRatio(设置新生代和老年代的比值,如果设置为4则表示(eden+from(或者叫s0)+to(或者叫s1)): 老年代 =1:4),即年轻代占堆的五分之一
-XX:SurvivorRatio(设置两个Survivor(幸存区from和to或者叫s0或者s1区)和eden区的比),8表示两个Survivor:eden=2:8,即Survivor区占年轻代的五分之一
-XX:+HeapDumpOnOutOfMemoryError(将OOM时的堆信息导出到文件)
如果系统出现OOM一般情况系统有可能会down掉,但是我们排查问题时需要场景重现是比较困难的,所以当我们输出了OOM的异常时,就可以直接查看,找出导致OOM的原因-XX:+HeapDumpPath=XXXX(导出OOM堆信息文件的路径)
-XX:OnOutOfMemoryError(在系统出现OOM时,执行一个脚本,可以发送邮件,报警或者是重启程序)
-XX:PermSize(设置永久代的初始空间大小)
-XX:MaxParmSize(设置永久代的最大空间)
-Xss(设置栈空间的大小)
可能问题及原因:
-
StackOverFlowError:
当线程调用的栈深度超过jvm所允许也会报。(虚拟机内存容量不够)
或者栈帧太大(一个方法内部的变量太多)时,无法申请足够的空间也会报。
-
OutOfMemory:
某些jvm栈容量是可以动态扩展的。拓展无法申请到足够内存时,会报出此错误。(HotSpot虚拟机不允许栈动态扩展,所以不会出现这种原因的报错,但申请失败时也会报这个错误。)
对于堆来说,一般都是可拓展的,当有线程申请分配,但其内部空间不够,而且堆也无法拓展时,会报错。
对于方法区,当其无法提供新的内存分配需求时,会报错。如运行时添加的常量,也会向方法区申请内存,但如果方法区内存已满,且无法拓展时,变会报内存溢出。
java堆
部分名词解释:
- 指针碰撞:Bump The Pointer,描述java堆分配新内存时的动作。
1.对象的创建
结构:
对象头(header):大小为一个Mark Word,32or64位(同于系统)。包含:对象哈希吗、对象分带年龄、存储锁标志位。(还可能有:类型指针,指向类的元数据(java方法区的常量池中);java数组header会有一个总大小header字段、以此判断该数组对象大小)
// Bit-format of an object header (most significant first, big endian layout belo// // 32 bits: // -------- // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) // size:32 ------------------------------------------>| (CMS free block) // PromotedObject*:29 ---------->| promobits:3 ----->| (CMS promoted object)-
实例数据(Instance Data):包含从父类继承的和本类的数据。排序方式默认为从大到小,即:long\double、int、short...还有一些其他设定,如compactFields,紧凑字段设置,可以将小数据插入其他数据中间。
所以顺序和代码里面的顺序可能不同。
对象填充(Padding):hospot要求每个对象都是8字节对齐。所以在实例数据尾部可能会有填充。(对象头已是8字节对齐)
java栈
StackOverflowError内存泄漏原因:(如下方法是hotspot jvm中,其不可拓展栈帧长度,并设置了栈帧最大值)
①栈深度过深:线程(方法)的栈深度超过jvm限制许可,如我测试时1050左右便不允许再深入。
②栈帧太大/jvm容量不够:一个方法内的变量太多,导致虽然没有达到栈深度限制,但是无法申请足够的内存。
说明:堆栈溢出,说明可能是其本身的问题,并非物理内存不够。和OutOfMemory,内存溢出不相同。
OutOfMemory内存溢出原因:(尤其是在32位系统应用开发时,更应该注意。)
①线程过多:线程创建过多,也类似栈溢出中②的问题,并可能导致操作系统假死。
②jvm容量不够/物理内存也不够:当栈可以拓展时,可能不会出现栈溢出,而是会出现内存溢出的问题。java.lang.OutOfMemoryError: unable to create native thread
方法区(Methods Area)
说明:主要职责在于存放class的信息:如类名、访问修饰符、常量池、字段描述、方法描述等
OutOfMemory内存溢出原因:
①(jdk6及以前)常量池容量不够:可以通过限制常量池大小 -XX:PermSize=6M -XX:MaxPermSize=6M等来限制,并一直向常量池添加数据(可以通过String::intern()来进行),会出现这个报错。但在jdk7以后,永久代渐渐取消、jdk8之后永久代完全放弃,不能得到常量池溢出(会出现堆溢出),因为放在永久代的字符串常量池从方法区转移到了堆中。
CGLib开源项目:http://cglib.sourceforge.net/。
垃圾回收(Garbage Collection)
图示:hotspot的分代垃圾收集器。线相连代表可以一起配合使用。(没有最好,只有适合)下面的组合上有jdk9的,代表已取消支持搭配。(CMS,Concurrent Mark Sweep,也被称为并发低停顿收集器,并行标记扫描;G1,Garbage First,其可处理整个堆中的区域,是收集器技术发展的里程碑;)
parallel 并行:指多条垃圾收集器线程之间的关系,同时有多条线程在协同工作; 主要用于服务器后台,提升吞吐量(运行用户代码时间 /(运行用户代码时间+运行收集器线程时间))。Parallel Scavenge还有一个名称“吞吐量优先收集器”(配合Parallel Old)
Concurrent 并发:指垃圾收集器线程和用户线程之间的关系,说明垃圾收集器线程和用户线程同时运行。如CMS等收集器主要用于客户端,减少用户线程停顿时间,提升服务质量和交互能力。
Shenandoah:是其他公司开发的一个收集器,其目标是low-pause低延迟,并且确实做得好。其也是全堆通用,因为其并没有进行分代,而是想G1将内存划分成多个region。
三大指标:内存占用(footprint)、吞吐量(时间比)、延迟(今后最被重视的指标)
other:https://blogs.oracle.com/jonthecollector/our_collectors。牵挂你的人
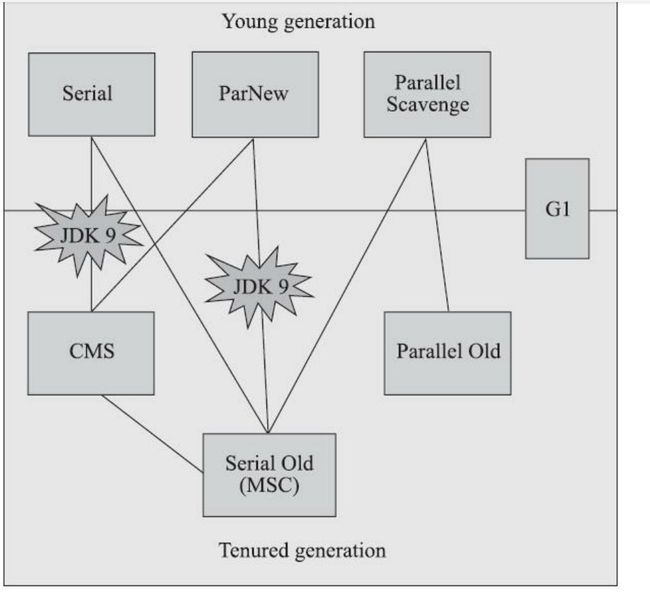
Parallel Scavenge:目标是为了获得最大吞吐量(上述定义),多用于服务器使用。
CMS:目标是为了获得最短暂停时间,多用于客户端或互联网服务器,为了提供短暂的系统停顿时间,提高客户服务。
说明:主要工作解决的问题是:①如何定位应被删除对象;②何时删除对象;③如何删除对象。
GC Roots:
·在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的
参数、局部变量、临时变量等。
·在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
·在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。·在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
·Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如
NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
·所有被同步锁(synchronized关键字)持有的对象。
·反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
垃圾回收算法:Richard Jones撰写的《垃圾回收算法手册》
垃圾收集算法可以划分为“引用计数式垃圾收集”(Reference Counting GC)和“追踪式垃圾收集”(Tracing GC)两大类
分代收集(generational Collection):
说明:其理论建立在两个假说上面:强分代假说(Strong Generational Hypothesis)、弱分代假说(Weak Generational Hypothesis)。
逃过一次GC,年龄就加一,逃过越多次GC的对象,就越难以消除。而绝大多数对象都是朝生夕死的,以此将堆空间分出两个区,强分代的GC频率低、弱分代GC频率高。
以此中和内存空间利用率和GC算法性能(时间)消耗。由分代收集划分出不同内存区域的思想,其后延伸出很多算法和划分方式。
内存划分如:新生代(young generation)、老年代(tenured generation)等,并因其可能会互相引用、而延伸出第三个假说:跨代引用假说(Intergerenational preference hypothesis)。
跨带引用假说:由于将所有老年代作为GC Roots比较耗性能,故在新生代内存区域建立一个记忆集(remembered set)全局数据结构,将老年代分为小块:有对新生代的引用,和没有的。minor GC扫描时只需要将有引用那块的老年代作为GC Roots即可。
GC划分如:Partial GC:{ Minor GC/ Young GC、Major GC / Old GC、Mixed GC } 、 Full GC;
如:minor GC只会对新生代进行扫描;Major GC只针对老年代,但一般的jvm很少会单独手机老年代,只有G1这样做,并且Major在不同jvm中,定义可能不同。
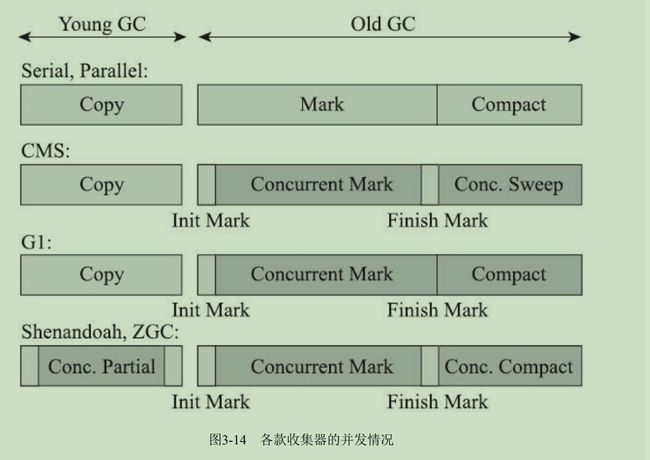
收集器清除算法:
基础算法是1960 Lisp之父提出的Mark-Sweep 标记-清除算法。其后很多算法都是以其为基础,进行改进得到。
标记-清除算法:全部进行标记(可以标记存活或回收的),然后一次清除。
标记-复制算法:通过将内存区域划分为两个区:使用区和空闲区。每次垃圾清除,将存活的对象复制到空闲区,然后清除使用区,并交换两者区域属性。1989年Andrew Appel针对具备“朝生夕灭”特点的对象,提出了一种更优化的半区复制分代策略,现在称为“Appel式回收”。
Appel式回收:将新生代分为1个eden(伊甸园)和2个survivor,一次保留一个survivor不使用。如hotspot中eden和survivor比例为8:1,所以一次使用(8+1)/10=90%的内存区域,不算太浪费。如果survivor不够时,会分配到老年代中,并在eden清空后分配回来。标记-复制算法和appel,其理论依据都是在于新生代对象存活率很低的情况下, 而这一般复合现实的规律。但老年代的存活率很高,其复制开销也会很大,不能用这种算法。
标记-整理算法(Mark-Compact):(compact,紧凑的,v压缩)多用于老年代,和标记-清除算法很像,也是先标记,然后清除,但是其清除后,会对老年代存活对象进行移动,使之紧凑,解决了内存碎片化问题,但由于要移动和更改引用,其间会暂停线程蛮长时间(标记-清除也会,但很短),延迟还是蛮高的。(hotspot 的Parallel Scavenge收集器)
混合算法:对于老年代,可以先采取标记-清除算法,直到内存碎片已经影响内存分配,进行一次标记-清理算法,hotspot的cms算法就是这样做的。
并发:当收集器和其他线程并发时,要避免出现”对象消失“问题:以三色来理解:{ 黑:代表其已被扫描,且所引用的对象都已被扫描。灰:代表自身已被扫描,但其所引用对象还没有(执行ing);白:代表没有被扫描 ;见https://en.wikipedia.org/wiki/Tracing_garbage_collection#Tri-color_marking。}
当并行时,可能出现灰色对象取消白色对象的引用,但之前的黑色对象却又引用了白色对象,此时白色对象会被错误编入待清除对象中。我们要解决这个问题。
“对象消失”问题出现的两个必要:
赋值器插入了一条或多条从黑色对象到白色对象的新引用; (解决方案:增量更新;扫描完后再扫描中途有引用其他对象行为的黑色节点。cms收集器)
赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。(解决方案: 原始快照;中途有删除引用关系的,不直接删除,而是以开始时的快照进行,结束后再进行扫描。G1、Shenandoah收集器)
我们只要中断一个就可以。
计数收集:
java工具
...java/bin/里面,有很多命令行工具,具体看深入理解java虚拟机 4.2.6,
还有http://openjdk.java.net/jeps/320。
还有一些可视化工具、虚拟机插件及工作。(JHSDB、JConsole、Visual VM、BTrace(visual VM插件,也可以独立)、JFR、JMC、HSDIS用于输出汇编代码和JITWacth搭配)
class文件
用hex来查看class文件,用命令行工具javap来翻译class文件:javap -verbose filePath。
- 部分名词解释:
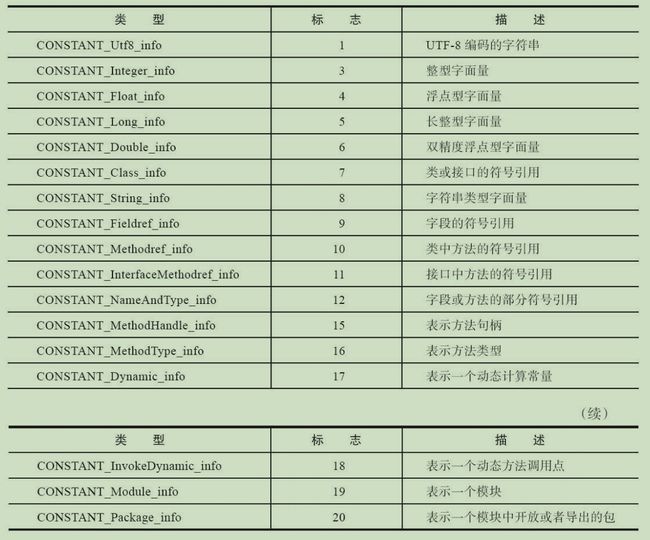
- 类型后缀_info:类型分为无符号类型和表。无符号用u1、u2、u4、u8表示,代码字节个数;表用info表示,里面可能有多个无符号和表数据类型;
格式:固定顺序的:
①(u4-四字节)magic number:标明这个文件的格式。如class文件是:xCAFEBABE
②(u4)minor version(次版本号=2bytes)和majoy version(主版本号=2bytes):主版本号从45开始,次版本号为0~65535.如jdk1 majoy version =45、jdk13 majoy version=57。
③(u2-两字节)constant pool count(常量池里面的数量)。
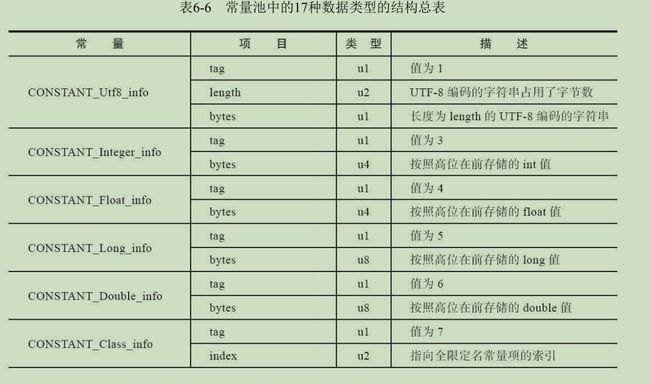
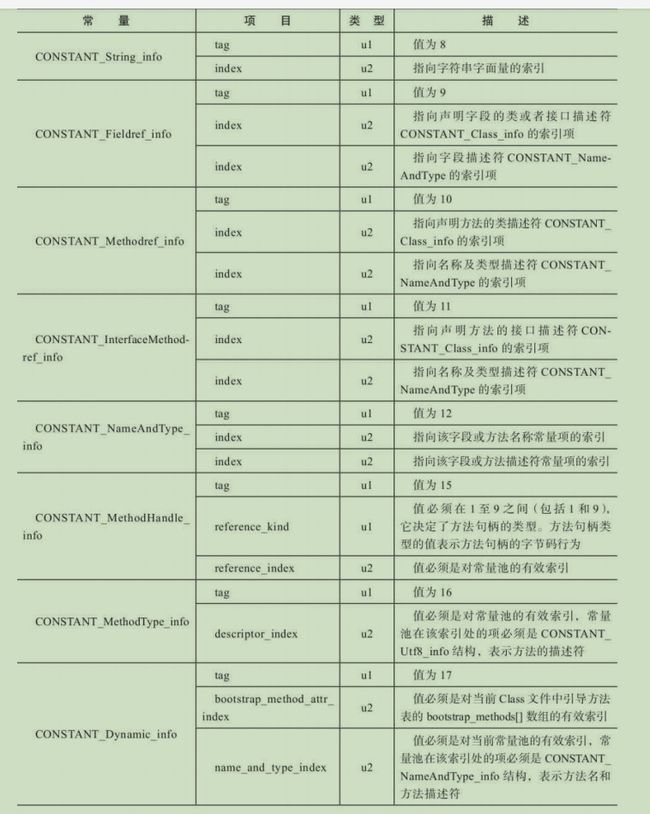
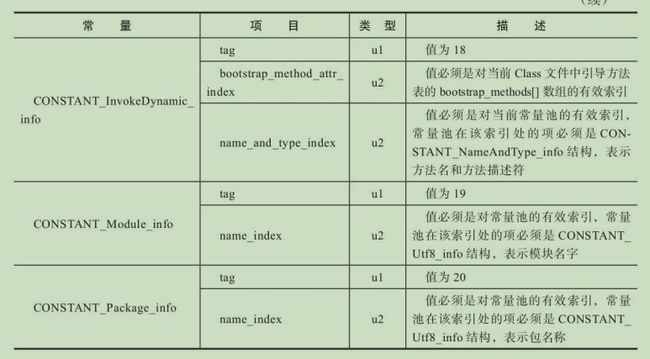
④(中间省略所有常量池的常量....)常量池里面的数据共有十七中结构(到jdk12)几乎都不同,但第一项相同,是标签tag,如下表所示,共有17种。具体常量池的结构看:常量池内容
⑤(u2)Access tag(访问标志):共有16个标志位可用,但当前只有9个被定义了(每个标志位用二进制0/1来标志)。主要用作对方法的标识,如其是否是普通类还是abstract、接口类,or其是否是public等。
⑥(u23)this_class* (类索引)、super_class(父类索引)、interfaces(接口索引):每个2字节,索引的目的地为常量池对象列表,如0x0001,指常量池中第一个对象,也就是上述常量池中第一个常量数据。
⑦( u2)field count:字段表集合数量。
⑧(每字段4对u2+可拓展的属性表):标识该类里面的字段表数据,可能有多个字段。每一个字段表数据有如下结构:
access_flags(u2、类似于上述访问标志,标识该字段的修饰符等类型,如是否是public等)+
name_index(u2、常量池索引) +
descriptor_index(u2、常量池索引):{ 结构:参数列表"(...)" + 返回值:int fun(int x, char []b) = (I[C)I };
attribute_count(u2):表示属性表的数量。
后面还有可能附加attribute_info表,里面是附加信息。如:int x=30;给定的初始值会作为常量池中的常量,而附加属性对其引用。
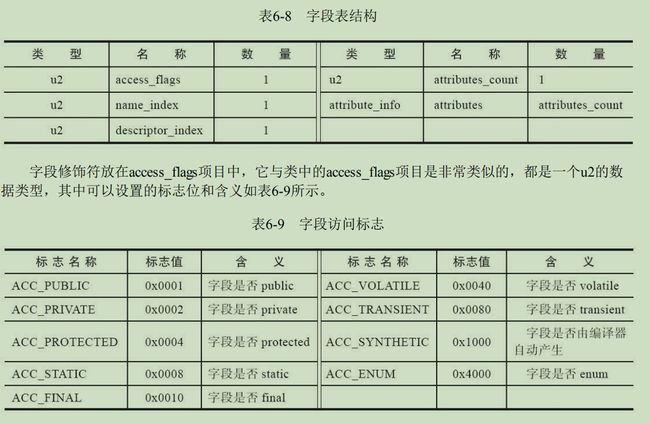
⑨(u2)方法区数量。
⑩(4对u2+属性表集合)方法区:属性表集合拥有很多属性_info,具体看下文
常量池内容
方法表
和字段表很类似。其属性表中会有code
结构为:4个u2+方法的属性表:(顺序)access_flag、name_index、descriptor_index(说明参数和返回值)、属性表个数、n个具体属性表(如Code表,下面有详述)
属性表
属性表通用格式:
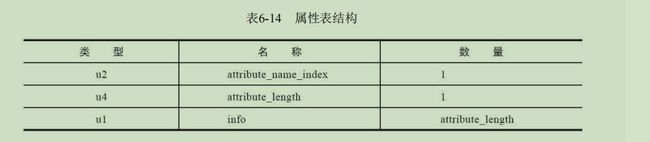
属性表集合:

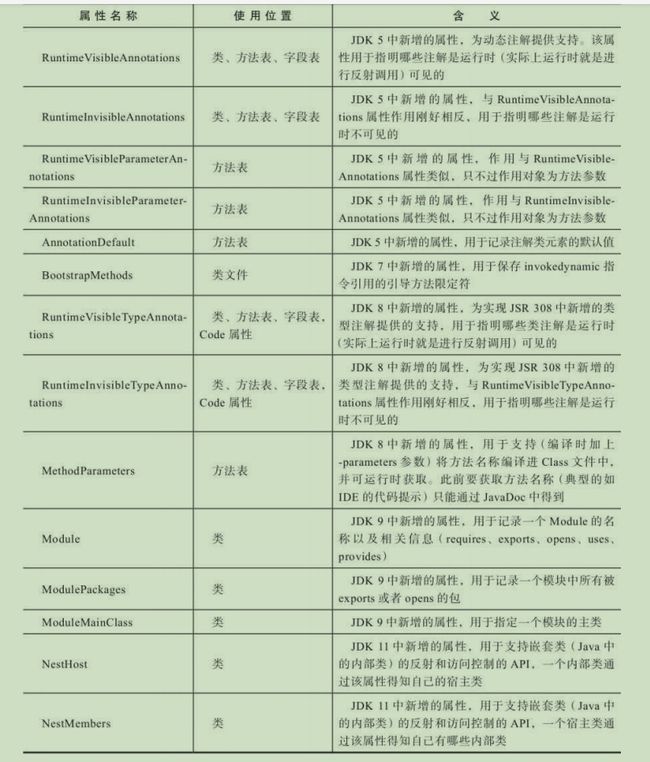
Code属性表:

max_stack:最大栈深度,虚拟机运行时根据这个值来分配栈帧中操作栈深度。
max_locals:最大局部变量的值,定义槽slot的数量,一个槽可以放32位,但只能放一个变量,64位的要两个槽。其所定义的槽数量,并非所有局部变量的数量和,而是同一时间,存活的最大局部变量数量和类型计算出max_locals的值。以节约内存。
code_length:字节码的长度,虽然是u4,但实际上超过65535(u2)字节码就会拒绝编译。如jsp内面和内容,可能会规定到一个方法中,可能会超长编译失败。
code:由length个u1组成,每条指令的第一个字节u1,类似于处理器指令集,指出该指令的意义和该指令的长度等。《java虚拟机规范》定义了越200条编码值对应的指令意义。详情附录C“虚拟机字节码指令表”。
exception_table_length:异常表长度
exception_table:异常表代码,也是用了指令集
Exception属性表
说明:与上述Code属性表中的异常表不同,这个异常属性表,列出的是方法抛出的异常。
格式:
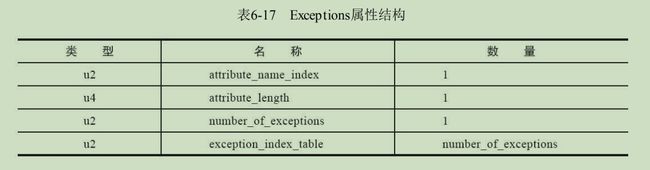
number_of_exceptions :表示异常种类的个数。
exception_index_table:索引常量池中的Constant_Class_info型常量,代表该被检查的异常的类型的名字。
LineNumberTable属性表
功能:主要用于将java源码行号与code字节码偏移量进行关联映射。方便调试操作等,但非必须。javac中编译时,可以输入-g:none、-g:lines来取消关联。
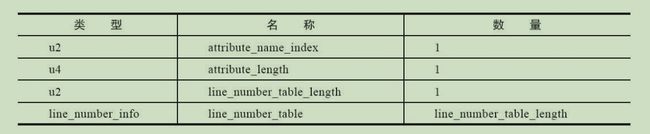
line_number_table:包含多个line_number_info类型的数据。
line_number_info表:包含start_pc和line_number两个u2类型的数据项,前者是字节码行号,后者是Java源
码行号。
LocalVariableTable及LocalVariableTypeTable属性表
功能:将java源码局部变量与栈帧中局部变量联系起来。当别人引用这个方法时,参数名也会存在,如果取消此关联,可能外部引用时,局部变量名字会丢失,用args0、args1代替,虽然不影响运行,但不方便调试;编译时可用javac -g:none或 -g:vars来关闭。
格式:
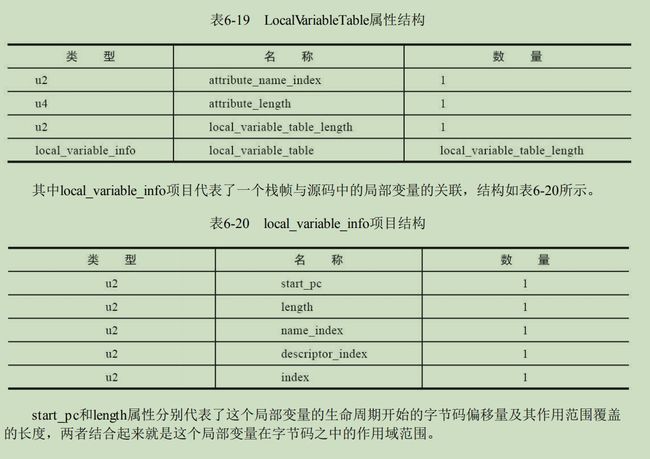
name_index和description_index:都是对常量池进行索引,得到变量名,参数和返回类型。
index:是变量槽中的偏移量。如果是64位,其对应的值时index和index+1。
LocalVariableTypeTable:这个新增的属性结构与LocalVariableTable非常相似,仅仅是把记录的字段描述
符的descriptor_index替换成了字段的特征签名(Signature)。对于非泛型类型来说,描述符和特征签名
能描述的信息是能吻合一致的,但是泛型引入之后,由于描述符中泛型的参数化类型被擦除掉[3],描
述符就不能准确描述泛型类型了。因此出现了LocalVariableTypeTable属性,使用字段的特征签名来完
成泛型的描述。
SourceFile、SourceDebugExtension属性表
功能:生成.class文件的源文件名,一般类名和源文件名都是一样的。
关闭:-g: none \ -g:source
格式:(u2)属性名索引、(u4)属性长度、(u2)常量池索引(得到.java源文件名)
SoureceDebugExtension:为了方便在编译器和动态生成的Class中加入供程序员使用的自定义内容,在JDK 5时,新增了 SourceDebugExtension属性用于存储额外的代码调试信息。典型的场景是在进行JSP文件调试时,无法通过Java堆栈来定位到JSP文件的行号。JSR 45提案为这些非Java语言编写,却需要编译成字节码并运行在Java虚拟机中的程序提供了一个进行调试的标准机制,使用SourceDebugExtension属性就可以用于存储这个标准所新加入的调试信息,譬如让程序员能够快速从异常堆栈中定位出原始JSP中出现问题的行号。
格式:

ConstantValue 属性表
innerClasses 属性表
说明:一个类包含了内部类,则会生成该属性表,用于记录内部类和宿主类之间的关联。
[图片上传失败...(image-782504-1594430035540)]
inner_class_info_index和outer_class_info_index:分别代表内部类和宿主类在常量池中的类型为CONSTANT_Class_info符号引用。
inner_name_index:指向常量池中CONSTANT_Utf8_info型常量的索引,代表这个内部类的名称,如果是匿名内部类,这项值为0。
inner_class_access_flags:内部类的访问标志,类似于类的access_flags,它的取值范围如表6-26所示。
Deprecated、Synthetic属性表
Deprecated:(弃用的)通过在方法、字段前添加@Deprecated来设置。编译时,会在属性表中进行简单描述。
SYnthetic:(人造的)标识该方法、字段、类是编译器自动生成的,非从源代码中来。
格式:
(u2)属性名常量池索引 + (u4)属性长度(恒定为0x00000000)。
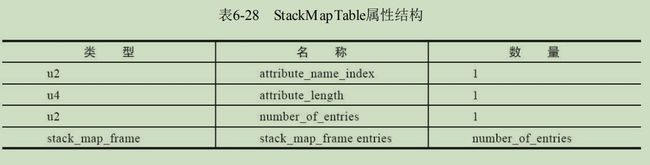
StackMapTable
Signature属性表

BootStrapMethods属性表


MethodParameters属性表
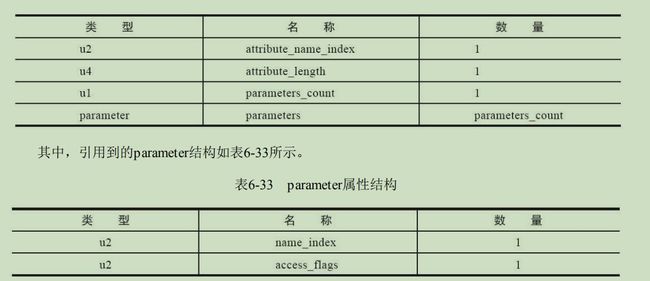
还有两个属性没有写
字节码指令简介
说明:java虚拟机采用的是面向操作数栈而非寄存器的架构。
详情:Java虚拟机规范(Java SE 7)——第六章。
名词解释:
Opcode:操作码。1字节大小;用于标识特定操作。其后跟随0~多个该操作需要的参数。
Operand:操作数。跟在操作码后面的数据。
助记符:操作码的助记符,用来简述操作的意义。其中特殊字符用作表明服务的数据类型。l代表long,s代表short,b代表byte,c代表char,f代表float,d代表double,a代表reference。也有的没有特殊字符。
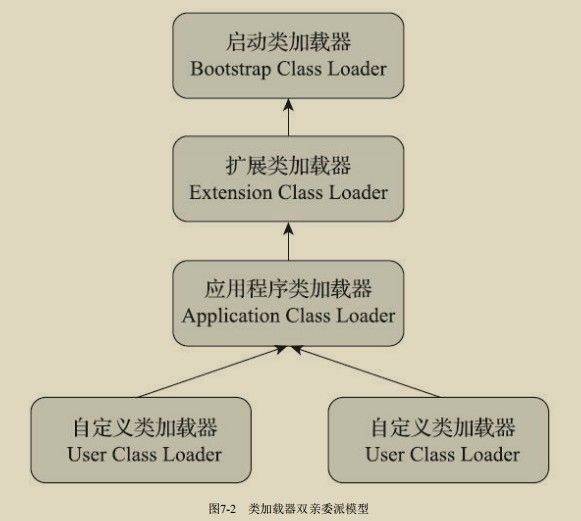
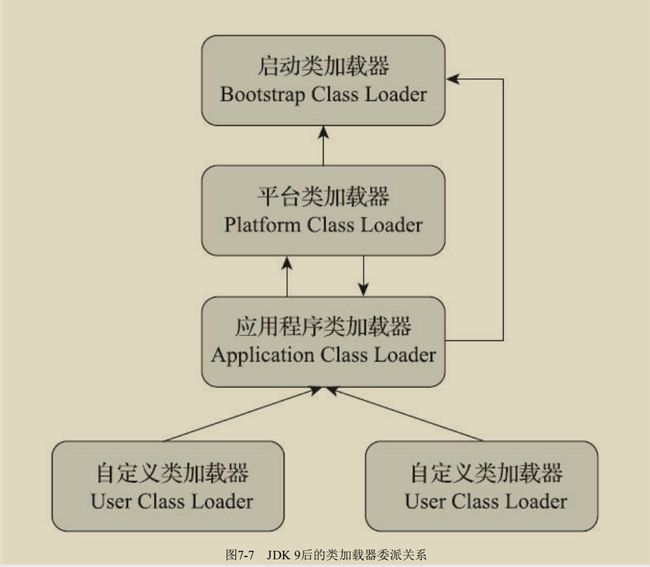
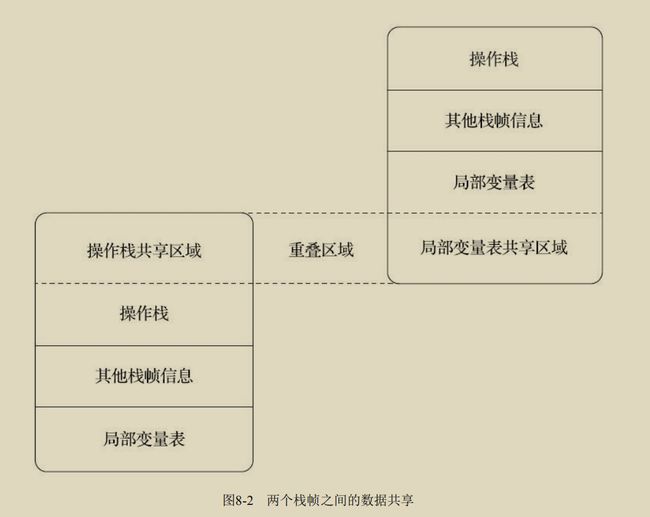
说明:限于一字节大小的指令集,对于类型大小 功能:用于将数据,在栈帧中的{局部变量表}、{操作数栈}之间相互传输。 从局部变量加载到操作栈:iload、iload_ 从操作栈存储到局部变量:istore、istore_ 将常量加载到操作数栈:bipush、sipusldc、ldc_w、ldc2_w、aconst_null、iconst_m1、 iconst_ 、lconst _ 拓展局部变量表的访问索引:wide 说明:对byte、short、char、boolean类型的算术指令,用int类型的指令来代替。《java虚拟机规范》指出, 只有xdiv 、xrem 中出现余数为0时,会抛出ArithmeticException异常。 算术指令:用x代替(i、l、f、d);iadd、ladd、fadd、dadd;xsub;xmul;xdiv; xrem(取反);xshl、xshr(位移);ior、lor(按位或);iand、land(按位与);ixor、lxor(按位异或);iinc(自增);·比较指令:dcmpg、dcmpl、fcmpg、fcmpl、lcmp; 宽化类型转换(Widening Numeric Conversion):从小范围类型转化为大范围。如int -> long/float/double;隐式即可转换。 窄化类型转换(Widening Numeric Conversion):从大范围类型转化为小范围。如float/double -> long;必须显示转换; 窄化类型转换指令:i2b、i2c、i2s、l2i、f2i、f2l、d2i、d2l和d2f。 创建类的指令:new 创建数组的指令:newarray、anewarray、multianewarray 访问类字段(static字段,也称类变量)指令:getstatic、putstatic 访问实例字段(非static字段,或称实例的变量):getfield、putfield 将数组元素加载到操作数栈的指令:baload、caload、saload、iaload、laload、faload、daload、aaload。 操作数栈的值储存到数组元素的指令:bastore’、castore、sastore、iastore、fastore、lastore、fastore、aastore 取数组长度的指令:arraylength 检查对象实例所属类型的指令:instanceof、checkcast 操作数栈 栈顶出栈:pop、pop2(顶上两个元素出栈) 复制栈顶一个、二个数值,并将复制值压入栈顶:dup、dup2;dup_x1、dup2_x1;dup2_x2、dup2_x2; 将栈中最顶端的两个数值互换:swap 说明:有条件或无条件地跳转。如之前所说,byte等数据类型会转换成int,而long、float、double则会先进行计算xcmpl、xcmpg,返回一个整数值到操作数栈中,随后在执行int的条件分支比较操作。 条件分支:ifeq、iflt、ifle、ifne、ifgt、ifge、ifnull、ifnonnull、if_icmpgt、if_icmple、if_icompge、if_acmpeq、if_acmpne 复合条件分支:tableswitch、lookupswitch 无条件分支:goto、goto_w、jsr、jsr_w、ret invokevirtual:用于调用对象(实例)的方法。 invokeinterface:用于调用接口的方法。 invokespecial:调用一些需特殊处理的方法。包括:实例初始化方法、私有方法、父类方法等。 invokestatic:调用类静态方法。 invokedynamic:用于在运行时动态解析出调用点限定符所引用的方法。 说明:调用函数与返回值无关,但是返回指令是根据类型进行区分。 ireturn:返回的类型包括int、short、char、byte、boolean。 lreturn、freturn、dreturn、areturn、return(void返回类型) athrow:显式抛出异常。 java虚拟机对异常的处理,不是由字节码指令来实现。而是由异常表来完成。 说明:用monitor(管程,或称锁)来实现方法级同步和方法内(一段指令序列)同步。‘ 同步:方法执行前持有monitor、然后调用方法,方法结束后释放monitor。执行期间,其他线程无法在获得同一个monitor管程。当发生异常时,方法内部无法处理并抛出异常到同步方法边界外后,会释放管程。 方法级同步:由虚拟机隐式来完成。虚拟机通过访问该方法常量池里面的ACC_SYNCHRONIZED访问标志是否被设置,来决定是否让该执行线程持有管程,随后再执行方法。 方法内同步:当java中,方法内部有synchronized语句,则会进行同步。 monitorenter:调用前会执行该指令 monitorexit:调用结束前会执行该指令。 在这两个指令必须配对使用。其中间的指令序列,即是被同步的。如果没有异常处理程序,虚拟机会自动生成可处理所有异常的异常处理代码,为的是monitorenter能正确配对。 如class文件格式和字节码指令。两者与硬件、操作系统、具体java虚拟机实现之间是完全独立的。虚拟机实现者可以充分优化和拓展,已获得更好的性能。 实现方式主要有两种: 类的生命周期: 《java虚拟机规范》中对初始化之前的阶段是没有强制要求的,有且仅有以下六种情况,则必须进行初始化: 遇到new、getstatic、putstatic、invokestaitc 使用java.lang.reflect(反射)包的方法对类型进行反射调用时。 当初始化类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化(接口不需要初始化其父类) 当虚拟机启动时,会根据用户指定的主类(包含main()方法),虚拟机会先初始化这个主类。 当使用JDK 7新加入的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解 析结果为REF_getStatic、REF_putStatic、REF_invokeStatic、REF_newInvokeSpecial四种类型的方法句 柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化。 当一个接口中定义了JDK 8新加入的默认方法(被default关键字修饰的接口方法)时,如果有 这个接口的实现类发生了初始化,那该接口要在其之前被初始化。 ①加载 三件事情: ②验证 《java虚拟机规范》中描述比较笼统,不是太具体。大概会完成下面四个阶段: 当确保无误时,可通过-Xverify:none来关闭,节约虚拟机验证时间。 ③准备 为类中定义的static变量分配内存,并设置变量初始值(0,而非代码中的初始值,如static int x=120,是要到创建实例才被类构造器< clinit>()初始化;注意:常量除外,常量是直接就初始化为指定值) ④解析 虚拟机将常量池内的符号引用,改成直接引用。 1.类或接口的解析: 非数组(普通类或接口):虚拟机把该类型的符号引用(全限定名)提供给类加载器,类加载器加载这个类到内存中。 数组:和非数组差不多,不过其描述符的形式为:"[Ljava/lang/Integer"。 符号引用验证:验证是否本类对引用类有访问权限,如果无,会抛出java.lang.IllegalAccessError异常。(由于JDK9引入了模块化概念,Public类型也并非一定可以访问,要看本模块是否有引用类所属模块的访问权限。 2.字段解析: 用于解析类中的字段,将字段与实际的所属类联系起来,所以会先解析其父类或实现的接口。 注意:Oracle公司的javac编译器在实现时,更加严格。当该类本身及父类、所实现接口中,都有该字段的简单名称和字段描述符时,会报错。Javac编译器将提示“The field Sub.A is ambiguous”,并且会拒绝编译这段代码。 3.方法解析: 4.接口方法解析: ⑤初始化 感觉这老师讲得太烂了,不适合初学者学习。 功能:用于根据全限定名,加载字节流到虚拟机内存中。 注意:当同一个类文件由两个类加载器加载时,其在虚拟机中不属于同一个类,因为每个类加载器有自己类名字列表空间。 启动类加载器(Bootstrap ClassLoader):启动类加载器是用C++语言实现的,是虚拟机自身的组成部分。 扩展类加载器(Extension CLassLoader):sun.misc.Launcher$ExtClassLoader中以java代码实现。 应用程序加载器(Application ClassLoader):(因其是ClassLoader.getSystemClassLoader()的返回值,也称系统类加载器)sun.misc.Launcher$AppClassLoader中以java代码实现。 说明:JDK9之前的java应用都是由启动、拓展、应用类加载器互相配合完成加载。当想要从磁盘外以及其他路径加载类或通过加载器实现类的隔离、重载等功能时,用户可以自定义类来进行拓展。其非强制性模型,但由java官方推荐使用这个模型。 层次结构:双亲委派模型中,父子关系不是继承,而是组合。如自定义类加载器可以组合应用程序类加载器。除了顶层的启动类加载器外,所有的类加载器都应该要有父辈类加载器。 工作过程(先上后下):当一个类加载器收到类加载请求,其首先会向父辈类加载器传递这个请求,而父辈类加载器也会向其父辈类加载器传递,直到最顶。当父辈在自己的类加载路径目录下找不到该类时,就会让子辈类加载器来加载,以此又往下传递。 优点: 延伸:关于热部署等方法,以及JDBC、JNDI等"破坏"了模型,但是却解决了问题。 模块:JDK9之后引入模块化系统,如jar(archive,文档)包中, 之前仅用作类库的容器,而现在其还可以包含模块的信息(实现封装隔离机制)。包括:所依赖的模块列表、导出的包列表(其他模块可使用)、开放的包列表(其他模块可反射访问的列表)、使用的服务列表、提供服务的实现列表。 类路径和模块路径(ModulePath):jdk9后将路径分为类路径和模块路径。类路径上的全部以传统jar包看待(就算包含了模块化信息);模块路径上的jar或jmod文件全部以模块看待; 访问规则: 模块化下的类加载器 变更: 拓展类加载器 被 平台类加载器 取代。 因为模块化本身具足拓展性,不需要再有 而jre也可以随时通过模块,构建出一个运行环境。如: 平台类加载器 和 应用程序加载器 取消继承自java.net.URLCLASSLoader ,转而与启动类加载器一起继承自jdk.internal.loader.BuiltinClassLoader,该类实现了模块化下的类加载逻辑,及资源可访问性处理。 如果有程序依赖这个继承关系,或者依赖于URLClassLoader的特定方法,那代码可能会在JDK9及以后版本中崩溃。 如上述,启动类加载器也变成虚拟机内部和java类库共同协作实现的类加载器了。但是调用方式还是要自定义类加载器并赋值为null. 双亲委派模型中,类加载器关系也发生变化。 系统模块: 归属:系统模块有规定的类加载器,当加载一个模块时,在向父辈传递请求之前,先判断是否是系统模块,及其归属的类加载器是哪个,并将请求交给他。若非系统模块,才交给父类传递。 BootStrap ClassLoader负责加载的模块: Platform ClassLoader负责加载的模块: Application ClassLoader负责加载的模块 概述:与物理机不同,虚拟机用软件层面的执行引擎,来对二进制字节码流进行处理。通常执行引擎运作方式为:解释执行和编译执行。不同虚拟机实现中,选择的方法可能不同,单一或者搭配,或者按等级结构分配执行引擎。 栈帧:储存了函数方法的局部变量、操作数栈、动态连接、方法返回地址等。不同栈帧作为不同方法的所有物,是完全独立的。 栈帧生命周期:从调用一个方法开始,到执行结束的过程。也是其在虚拟机栈里,入栈到出栈的过程。 当前帧栈:对执行引擎来说,只有最顶的帧栈是正在执行的帧栈,引擎所执行的所有字节码都只针对该帧栈进行操作。 细节: 栈帧结构示意图: 组成:多个槽构成。用于存储 方法参数 和 方法内部定义的局部变量。 槽:《java虚拟机规范》并没有规定其大小,而是只要能大于等于32位就行(放下32位以内的所有类型)。64位分成两个,高位在前。 虚拟机数据类型:reference=32位。注意!其和java语言数据类型不同。尤其是其中的引用reference是占一个槽,还有一个returnAddress类型也是一个槽。(returnAddress为执行一条字节码指令的地址,不常见了,其作为古老jdk上面异常处理跳转的助手) 储存结构:类似于数组,当全是32位以下类型时,第n个数据,就放在第n个槽。64位数据,则占据2槽,放在n、n+1位(高位在前)。 64位的数据,虚拟机不允许任何方式单独访问其中一个槽。校验阶段会发生异常。 方法调用过程:(对于实参到形参的传递,使用栈帧的局部变量表来完成;运行调用时,生成如下过程) 局部变量表槽复用:在一个函数方法内,当有多个作用域时,槽的数量不一定就是所有变量数量和,而是可以进行复用。如有多个"{...}"区域存在,其中的代码的作用域到"}"为止。(疑问:意思是不一次放入所有变量到局部变量表么?) 组成:一个后进先出的栈数据结构。最大栈深度,编译时已被写入Code属性的max_stacks数据项中。 功能:用于完成字节码中的操作。如:iadd指令,执行时会将操作数栈顶两个元素进行出栈,并相加,随后压入栈中。其前面要有类似两个iload指令,将int整数放入栈中。 操作数栈共享 说明:出于节约空间和共享数据理念,有部分操作数栈区域可以共享。 组成:一个引用。其指向运行时方法区:常量池里,该栈帧所属的方法。 组成:保存返回地址。 说明:动态链接、方法返回地址、其他附加信息等组合起来称为栈帧信息。 解析:当虚拟机进行解析操作时,只有类里的static、private方法会被解析成直接引用,因为其不会在运行时更改了。 方法调用指令集: invokestatic和invokespecial都可以在解析时,确定唯一的调用版本(方法的内部结构),两个指令集对应的方法,其符号引用在解析时就生成了直接引用。 非虚方法:静态方法、实例构造器 虚方法:所有其他方法。 静态类型:是编译期间确定的。注意:即使Human human=new Man(),但是human的类型还是Human,除非强制转换,只有到运行时,才会确定其变成Man类型。 实际类型:(actual type)编译期间是无法确定其类型的,只有运行时才可以。 静态分派:依静态类型,来决定方法执行版本的分派动作。发生在编译阶段。最典型应用是方法重载。 动态分派:(*难!书里8.3.2) 单分派和多分派:目前来说,静态多分派,动态单分派。 静态和动态类型语言判定:类型检查是在编译期间还是运行期间? 注意:动态类型语言与动态语言、弱类型语言并不是一个概念,需要区别对待。 说明:(Tomcat 6之前的结构)定义了多个目录,提供不同权限,并实现类库隔离。(Common、Shared、WebApp\WEB_INF、Server(Catalina类加载器)) 每一个WebApp类加载器和JSP类加载器通常会存在多个实例。 Common类加载器能加载的类都可以被Catalina类加载器和Shared类加载器使用,而Catalina类加载器和Shared类加载器自己能加载的类则与对方相互隔离。 JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个Class文件,它存在的目的就是为了被丢弃:当服务器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的JSP类加载器来实现JSP文件的HotSwap功能 注意:在Tomcat 6及之后的版本简化了默认的目录结构(/common、/shared、/server合并在/bin目录),只有指定了tomcat/conf/catalina.properties配置文件的server.loader和share.loader项后才会真正建立Catalina类加载器和Shared类加载器的实例,否则会用到这两个类加载器的地方都会用Common类加载器的实例代替
加载和存储指令
运算指令
类型转换指令
对象创建与访问指令
操作数栈管理指令
控制转移指令
方法调用和返回指令
异常处理指令
同步指令
共有设计和私有实现
虚拟机类加载机制
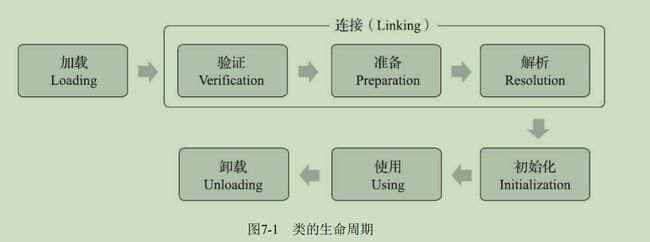
强制初始化
类加载阶段
类加载器
双亲委派模型(Parents Delegation Model)--三层类加载器
java模块化系统(Java Platform Module System,JPMS)
jlink -p $JAVA_HOME/jmods --add-modules java.base --output jre
java.base
java.datatransfer
java.desktop
java.instrement
java.logging
java.management
java.management.rmi
java.naming
java.prefs
java.rmi(远程方法调用)
java.security.sasl
java.xml
jdk.httpserver
jdk.internal.vm.ci
jdk.management
jdk.management.agent
jdk.naming.rmi
jdk.net
jdk.sctp
jdk.unsupported
crypto(加密)、incubator(孵化器)
虚拟机字节码执行引擎
运行时栈帧结构
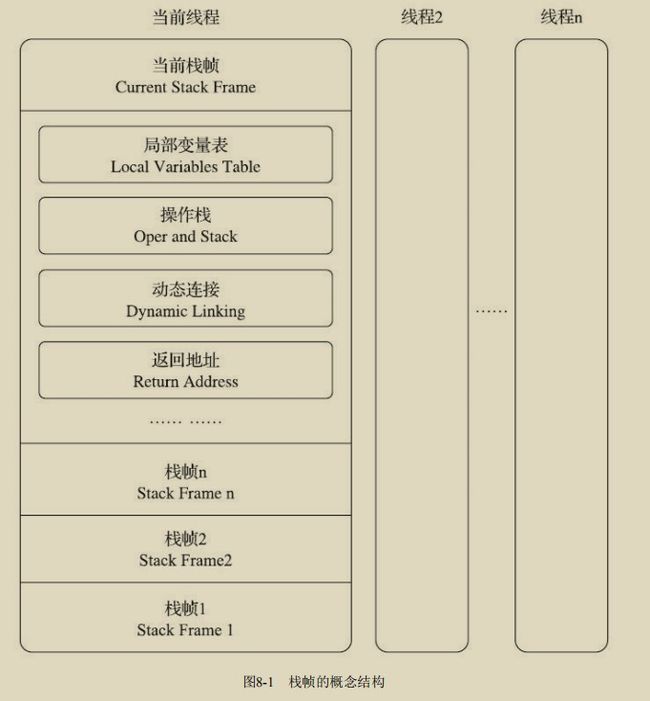
局部变量表:
操作数栈:
动态连接
方法返回地址:
方法调用
分派
// 实际类型变化
Human human = (new Random()).nextBoolean() ? new Man() : new Woman();
// 静态类型变化
sr.sayHello((Man) human)
sr.sayHello((Woman) human)
动态类型语言支持
根本学不懂,后面在学吧。
基于栈的字节码解释执行引擎
tomcatd的目录组织及自定义类加载器
