一、在脚本中接受原始输入
使用内置函数 input 获取用户的原始输入, input() 函数接受一个标准输入数据,返回为 string 类型。如果希望接收的数字是它原始的类型,可以使用eval(input())来接收原始输入,甚至能直接解析表达式。
举栗子:
name = input("Enter your name: ")
print("Hello there, {}!".format(name.title()))
#输入lei,会输出Hello there, Lei!
result = eval(input("Enter an expression: "))
print(result)
#输入2*3,会得出6
input到此结束,那么我们来看看eval是什么呢?
eval的功能其实已经知道了,功能是将string变成算术表达式来执行,比如eval("2*3")的结果是6这种。但是eval的功能不仅限于此,让我们来看下eval函数原型:
eval(expression, globals=None, locals=None)
能看到里面有两个默认参数,globals和locals,这两个参数如果要配合的话,都要配置成字典的形式,那么,为什么呢?
大家还记得之前我们所讲过的命名空间global全局命名空间和local局部命名空间对吧,其实python的全局名字空间存储在一个叫globals()的dict对象中;局部名字空间存储在一个叫locals()的dict对象中。我们可以用print (locals())来查看该函数体内的所有变量名和变量值。
绕回eval,那么这两个参数,也就类似命名空间globals和locals了,让我们分开来说:
- 当后两个参数都为空时,很好理解,就是一个string类型的算术表达式,计算出结果即可。等价于eval(expression)。
- 当locals参数为空,globals参数不为空时,先查找globals参数中是否存在变量,并计算。
- 当两个参数都不为空时,先查找locals参数,再查找globals参数。
举栗子:
1、在前两个参数省略的情况下,eval在globals的内建模块__builtins__内执行( 可以通过print(dir(__builtins__)) 来看有什么):
a=10;
print(eval("a+1"))
执行结果为:11
在这种情况下,后两个参数省略了,所以eval中的a是前面的10。对于eval,它会将第一个expression字符串参数的引号去掉,然后对引号中的式子进行解析和计算。
2、在globals指定的情况下,在指定的globals域中执行(记住是字典):
a=10;
g={'a':4}
print(eval("a+1",g))
执行结果为:5
在这次的代码中,我们在 eval中提供了globals参数,这时候eval的作用域就是g指定的这个字典了,也就是外面的a=10被屏蔽掉了,eval是看不见的,所以使用了a为4的值。
3、在 locals指定的情况下,在指定的locals域中执行(记住是字典) :
a=10
b=20
c=30
g={'a':6,'b':8}
t={'b':100,'c':10}
print(eval('a+b+c',g,t))
执行的结果为:116
a是6,b是100,c是10。我们首先来看一下,对于a为6我们是没有疑问的,因为在上个例子中已经说了,g会屏蔽程序中的全局变量的,而这里最主要的是为什么b是100呢?还记得我们在参数介绍的时候说过,当locals和globals起冲突时,locals是起决定作用的,这在很多编程语言里都是一样的,是作用域的覆盖问题,当前指定的小的作用域会覆盖以前大的作用域,这可以理解为一张小的纸盖在了一张大的纸上,纸是透明的,上面写的东西是不透明的,而它们重合的地方就可以理解成两个作用域冲突的地方,自然是小的显现出来了。
二、异常处理
Try 语句
我们可以使用 try 语句处理异常。你可以使用 4 个子句(除了视频中显示的子句之外还有一个子句)。
- try:这是 try 语句中的唯一必需子句。该块中的代码是 Python 在 try 语句中首先运行的代码。
- except:如果 Python 在运行 try 块时遇到异常,它将跳到处理该异常的 except 块。
- else:如果 Python 在运行 try 块时没有遇到异常,它将在运行 try 块后运行该块中的代码。
- finally:在 Python 离开此 try 语句之前,在任何情形下它都将运行此 finally 块中的代码,即使要结束程序,例如:如果 Python 在运行 except 或 else 块中的代码时遇到错误,在停止程序之前,依然会执行此finally 块。
指定异常
我们实际上可以指定要在 except 块中处理哪个错误,如下所示:
try:
# some code
except ValueError:
# some code
现在它会捕获 ValueError 异常,但是不会捕获其他异常。如果我们希望该处理程序处理多种异常,我们可以在 except 后面添加异常元组。
try:
# some code
except (ValueError, KeyboardInterrupt):
# some code
或者,如果我们希望根据异常执行不同的代码块,可以添加多个 except 块。
try:
# some code
except ValueError:
# some code
except KeyboardInterrupt:
# some code
在处理异常时,依然可以如下所示地访问其错误消息:
try:
# some code
except ZeroDivisionError as e:
# some code
print("ZeroDivisionError occurred: {}".format(e))
应该会输出如下所示的结果:
ZeroDivisionError occurred: division by zero
如果没有要处理的具体错误,依然可以如下所示地访问消息:
try:
# some code
except Exception as e:
# some code
print("Exception occurred: {}".format(e))
Exception 是所有内置异常的基础类,还想知道其他类错误可以看这里。
触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用)。
def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)# 触发异常后,后面的代码就不会再执行
注意:为了能够捕获异常,"except"语句必须有用相同的异常来抛出类对象或者字符串。
例如我们捕获以上异常,"except"语句如下所示:
try:
正常逻辑
except Exception as err:
触发自定义异常
else:
其余代码
结合后完整的例子
# 定义函数
def mye( level ):
if level < 1:
raise Exception("Invalid level!")
# 触发异常后,后面的代码就不会再执行
try:
mye(0) # 触发异常
except Exception as err:
print(1, err)
else:
print(2)
三、读写文件
读取文件
f = open('my_path/my_file.txt', 'r')
file_data = f.read()
f.close()
- 用open 打开文件,参数是文件路径字符串。open 函数会返回文件对象,Python 通过该对象与文件本身交互。
- 你可以在 open 函数中指定可选参数。参数之一是打开文件时采用的模式。 r,即只读模式。这实际上是模式参数的默认值。
- 使用 read 访问文件对象的内容。该 read 方法会接受文件中包含的文本并放入字符串中。在此示例中,我们将该方法返回的字符串赋值给变量 file_data。
- 当我们处理完文件后,使用 close 方法释放该文件占用的系统资源。
写入文件
f = open('my_path/my_file.txt', 'w')
f.write("Hello there!")
f.close()
- 以写入 ('w') 模式打开文件。如果文件不存在,Python 将为你创建一个文件。如果以写入模式打开现有文件,该文件中之前包含的所有内容将被删除。如果你打算向现有文件添加内容,但是不删除其中的内容,可以使用附加 ('a') 模式,而不是写入模式。
- 使用 write 方法向文件中添加文本。
- 操作完毕后,关闭文件。
With
with会在你使用完文件后自动关闭该文件。
with open('my_path/my_file.txt', 'r') as f:
file_data = f.read()
该 with 关键字使你能够打开文件,对文件执行操作,并在缩进代码(在此示例中是读取文件)执行之后自动关闭文件。现在,我们不需要调用 f.close() 了!你只能在此缩进块中访问文件对象 f。
四、导入模块或者包
模块module其实就是py文件(即使是库文件其实也是py文件),要导入模块荷包,需要关键字import。
包就是一个容器,用来存放其他的模块和包,包内必须含有__init__.py文件,下面我们来看一个包的结构:
PkgA/ # 顶层包
__init__.py # 初始化 PkgA
PkgB/ # PkgA 的子包 PkgB
__init__.py # 初始化 PkgB
module1.py
module2.py
PkgC/ # PkgA 的子包 PkgC
__init__.py # 初始化 PkgC
module1.py
module2.py
在包PkgA下面出现了同名的模块 module1.py和 module2.py ,通过添加子包 PkgB和 PkgC将其区分。
#语法:
import 模块名(库名)
import 模块名(库名) as 别名
import 包名.子包名.模块名
import 包名.子包名.模块名 as 别名
from 模块名 import 函数名
from 包名.子包名.模块名 import 函数名
#以上面的包为例,另外假设module1模块内有一个say函数,负责输出hello语句
# 方式一:导入函数所在模块
>>> import PkgA.PkgB.module1
>>> PkgA.PkgB.module1.say()
hello
# 方式二:从包 PkgA.PkgB 中导入函数所在模块
>>> from PkgA.PkgB import module1
>>> module1.say()
hello
# 方式三:从模块中导入函数
>>> from PkgA.PkgB.module1 import say
>>> say()
hello
导入自定义模块的3种方式
- 第一种,直接 import
(1)要导入的py文件(模块),直接放到跟要运行的py文件的当前目录下,import文件名即可
(2)你的包和模块同属于同个目录(父级目录),如下图:
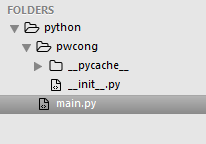
(1)main.py 和 pwcong模块同在python目录
(2) 执行文件为main.py
(3) pwcong文件夹为一个模块,该模块有个hi函数
执行文件main.py直接import模块:
# main.py
# -*- coding: utf-8 -*-
import pwcong
pwcong.hi()
- 第二种 如果执行文件和模块不在同一目录,这时候直接import是找不到自定义模块的。如下图:
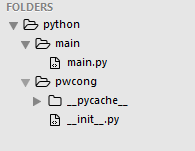
(1) 执行文件main.py在main目录下
(2)pwcong模块在python目录下
sys模块是python内置的,因此我们导入自定义模块的步骤如下:
- 先导入sys模块
- 然后通过
sys.path.append(path)函数来导入自定义模块所在的目录 - 导入自定义模块。
这时候 main.py 这样写:
import sys
sys.path.append(r"C:\Users\Pwcong\Desktop\python")
import pwcong
pwcong.hi()
- 第三种,通过pth文件找到自定义模块
这个方法原理就是利用了系统变量,python会扫描path变量的路径来导入模块,可以在系统path里面添加。但是我还是推荐使用pth文件添加。
模块和执行文件目录结构跟上图一样:

(1) 执行文件main.py在main目录下
(2)pwcong模块在python目录下
我们创建一个 module_pwcong.pth 文件,里面内容就是 pwcong模块所在的目录:
C:\Users\Pwcong\Desktop\python
将该 module_pwcong.pth 文件放到这里:
python安装目录\Python36\Lib\site-packages
例如我的:
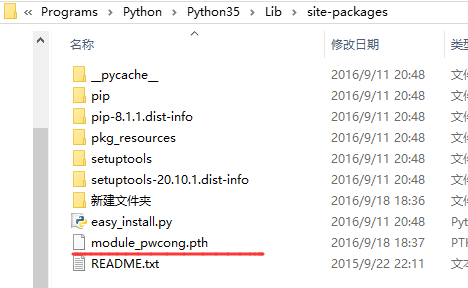
然后 main.py 导入并使用自定义模块:
# -*- coding: utf-8 -*-
import pwcong
pwcong.hi()
以上来自链接分享
五、__name__和__main__含义详解
为了避免运行从其他脚本中作为模块导入的脚本中的可执行语句,将这些行包含在 if __name__ == "__main__" 块中。或者,将它们包含在函数 main() 中并在 if __name__ == "__main__" 块中调用该函数。
每当我们运行此类脚本时,Python 实际上会为所有模块设置一个特殊的内置变量 name。当我们运行脚本时,Python 会将此模块识别为主程序,并将此模块的 name 变量设为字符串 "main"。对于该脚本中导入的任何模块,这个内置 name 变量会设为该模块的名称。因此,条件if __name__ == "__main__"会检查该模块是否为主程序。
以上是课程内的描述,但是关于if __name__ == "__main__",其实并不是描述的特别清楚,这里我推荐这个网址,来对这个问题学习的更深。
以下为引用:
python并没有一个固定的函数入口,而if __name__ == '__main__' 相当于是 Python 模拟的程序入口。Python 本身并没有规定这么写,这只是一种编码习惯。由于模块之间相互引用,不同模块可能都有这样的定义,而入口程序只能有一个。到底哪个入口程序被选中,这取决于__name__ 的值。
__name__ 是内置变量,用于表示当前模块的名字,同时还能反映一个包的结构。来举个例子,假设有如下一个包:
a
├── b
│ ├── c.py
│ └── __init__.py
└── __init__.py
目录中所有 py 文件的内容都为:
print(__name__)
我们执行 python -c "import a.b.c",输出结果:
a
a.b
a.b.c
由此可见,name 可以清晰的反映一个模块在包中的层次。
如果一个模块被直接运行,则其没有包结构,其 __name__值为 __main__。例如在上例中,我们直接运行 c.py 文件(python a/b/c.py),输出结果如下:
__main__
所以,if __name__ == '__main__' 我们简单的理解就是: 如果模块是被直接运行的,则代码块被运行,如果模块是被导入的,则代码块不被运行。
另外,在知乎上看到一个很有趣的比喻,可以理解一下:

六、标准库和第三方库
没啥讲的,要用啥谷歌搜索!标准库去查阅api文档!