目录
- 前言
- 初始化BlockManagerMaster与RPC端点
- 主RPC端点BlockManagerMasterEndpoint
- 构造方法与属性成员
- 接受并回复RPC消息
- 例:处理BlockManager注册
- 例:处理BlockManager心跳
- 从RPC端点BlockManagerSlaveEndpoint
- BlockManagerMaster
- 总结
前言
通过前面几篇文章的讲解,我们就把Spark Core存储体系中的内存存储和磁盘存储逻辑基本上讲完了,而负责将这些组件统一管理并发挥作用的就是BlockManager,那么从本文开始,我们就来逐渐探索它的细节……
No,还不急,本文还是来看先于BlockManager初始化的组件,即BlockManagerMaster。顾名思义,它是负责管理各个BlockManager的。之前提到过一句,BlockManager是典型的主从架构设计,不管Driver还是Executor上都要有BlockManager实例,那么必然就得存在一个协调组件——Spark中就是BlockManagerMaster了。
既然BlockManager散落在不同的节点上,它们之间如何互通有无?当然就是借助很久之前讲过的RPC环境了。所以,如果看官对RPC端点RpcEndpoint、RPC端点引用RpcEndpointRef这些概念已经感到生疏了的话,就回去翻一翻吧。
初始化BlockManagerMaster与RPC端点
BlockManagerMaster在SparkEnv中创建,对应的代码如下。
代码#29.1 - o.a.s.SparkEnv.create()方法中创建BlockManagerMaster
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
def registerOrLookupEndpoint(
name: String, endpointCreator: => RpcEndpoint):
RpcEndpointRef = {
if (isDriver) {
logInfo("Registering " + name)
rpcEnv.setupEndpoint(name, endpointCreator)
} else {
RpcUtils.makeDriverRef(name, conf, rpcEnv)
}
}
由这一小段代码可以看出,BlockManagerMaster初始化时会接受一个RpcEndpoint作为参数,该RPC端点的类型为BlockManagerMasterEndpoint。如果当前节点是Driver所在节点,就调用RpcEnv.setupEndpoint()方法注册此RPC端点到RPC环境中。反之,如果当前节点是Executor所在节点,就调用RpcUtils.makeDriverRef()方法【进而调用的是RpcEnv.setupEndpointRef()方法】创建对Driver中BlockManagerMasterEndpoint的引用。
既然有了“主”节点持有的BlockManagerMasterEndpoint,那么“从”节点如果不持有一个RPC端点的话,仍然无法进行通信,因此相对地也会初始化名外BlockManagerSlaveEndpoint的组件。它的初始化则位于BlockManager的代码里,下一篇文章会看到,现在就不着急了。
接下来我们看BlockManagerMasterEndpoint的实现。
主RPC端点BlockManagerMasterEndpoint
构造方法与属性成员
代码#29.2 - o.a.s.storage.BlockManagerMasterEndpoint的构造方法与属性成员
private[spark]
class BlockManagerMasterEndpoint(
override val rpcEnv: RpcEnv,
val isLocal: Boolean,
conf: SparkConf,
listenerBus: LiveListenerBus)
extends ThreadSafeRpcEndpoint with Logging {
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
private val askThreadPool = ThreadUtils.newDaemonCachedThreadPool("block-manager-ask-thread-pool")
private implicit val askExecutionContext = ExecutionContext.fromExecutorService(askThreadPool)
private val topologyMapper = {
val topologyMapperClassName = conf.get(
"spark.storage.replication.topologyMapper", classOf[DefaultTopologyMapper].getName)
val clazz = Utils.classForName(topologyMapperClassName)
val mapper =
clazz.getConstructor(classOf[SparkConf]).newInstance(conf).asInstanceOf[TopologyMapper]
logInfo(s"Using $topologyMapperClassName for getting topology information")
mapper
}
// ......
}
可见,该RPC端点需要RPC环境、SparkConf和事件总线的支持。下面将属性逐一解说一下:
- blockManagerInfo:维护BlockManager的ID与其信息的映射关系。BlockManagerId类是对Driver/Executor ID、节点地址、端口等信息的简单封装,而BlockManagerInfo类则是定义在BlockManagerMasterEndpoint下方的私有类,维护BlockManager的一些基本信息,如ID、最后一次通信时间、块列表、堆内/堆外内存大小等。这两个类后面也会简略看一下。
- blockManagerIdByExecutor:维护Executor ID与BlockManager ID的映射关系。
- blockLocations:维护块ID与持有对应块的BlockManager ID的映射关系。
- askThreadPool/askExecutionContext:目前没有实际的用途,从名称推测看,是用来处理RPC请求的线程池及其对应的ExecutionContext。
- topologyMapper:通过反射创建的TopologyMapper类实例,用来记录节点对应的拓扑信息。默认的DefaultTopologyMapper是空实现,另外还有FileBasedTopologyMapper可以通过文件指定拓扑。它可能是方便今后来做机架感知等功能的,目前(2.3.3版本)仍然没有具体的用途。
接受并回复RPC消息
这个自然是通过覆写RpcEndpoint.receiveAndReply()方法来实现。它的方法体比较长(RPC消息类型很多)。
代码#29.3 - o.a.s.storage.BlockManagerMasterEndpoint.receiveAndReply()方法
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RegisterBlockManager(blockManagerId, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint) =>
context.reply(register(blockManagerId, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint))
case _updateBlockInfo @
UpdateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size) =>
context.reply(updateBlockInfo(blockManagerId, blockId, storageLevel, deserializedSize, size))
listenerBus.post(SparkListenerBlockUpdated(BlockUpdatedInfo(_updateBlockInfo)))
case GetLocations(blockId) =>
context.reply(getLocations(blockId))
case GetLocationsAndStatus(blockId) =>
context.reply(getLocationsAndStatus(blockId))
case GetLocationsMultipleBlockIds(blockIds) =>
context.reply(getLocationsMultipleBlockIds(blockIds))
case GetPeers(blockManagerId) =>
context.reply(getPeers(blockManagerId))
case GetExecutorEndpointRef(executorId) =>
context.reply(getExecutorEndpointRef(executorId))
case GetMemoryStatus =>
context.reply(memoryStatus)
case GetStorageStatus =>
context.reply(storageStatus)
case GetBlockStatus(blockId, askSlaves) =>
context.reply(blockStatus(blockId, askSlaves))
case GetMatchingBlockIds(filter, askSlaves) =>
context.reply(getMatchingBlockIds(filter, askSlaves))
case RemoveRdd(rddId) =>
context.reply(removeRdd(rddId))
case RemoveShuffle(shuffleId) =>
context.reply(removeShuffle(shuffleId))
case RemoveBroadcast(broadcastId, removeFromDriver) =>
context.reply(removeBroadcast(broadcastId, removeFromDriver))
case RemoveBlock(blockId) =>
removeBlockFromWorkers(blockId)
context.reply(true)
case RemoveExecutor(execId) =>
removeExecutor(execId)
context.reply(true)
case StopBlockManagerMaster =>
context.reply(true)
stop()
case BlockManagerHeartbeat(blockManagerId) =>
context.reply(heartbeatReceived(blockManagerId))
case HasCachedBlocks(executorId) =>
blockManagerIdByExecutor.get(executorId) match {
case Some(bm) =>
if (blockManagerInfo.contains(bm)) {
val bmInfo = blockManagerInfo(bm)
context.reply(bmInfo.cachedBlocks.nonEmpty)
} else {
context.reply(false)
}
case None => context.reply(false)
}
}
BlockManager RPC消息的类型统一在对象BlockManagerMessages中来定义,并且它们的名称可以自解释,这里就不再专门列出源码了。下面挑选两个处理方法作为例子来看看是怎样处理的。
例:处理BlockManager注册
代码#29.4 - o.a.s.storage.BlockManagerMasterEndpoint.register()方法
private def register(
idWithoutTopologyInfo: BlockManagerId,
maxOnHeapMemSize: Long,
maxOffHeapMemSize: Long,
slaveEndpoint: RpcEndpointRef): BlockManagerId = {
val id = BlockManagerId(
idWithoutTopologyInfo.executorId,
idWithoutTopologyInfo.host,
idWithoutTopologyInfo.port,
topologyMapper.getTopologyForHost(idWithoutTopologyInfo.host))
val time = System.currentTimeMillis()
if (!blockManagerInfo.contains(id)) {
blockManagerIdByExecutor.get(id.executorId) match {
case Some(oldId) =>
logError("Got two different block manager registrations on same executor - "
+ s" will replace old one $oldId with new one $id")
removeExecutor(id.executorId)
case None =>
}
logInfo("Registering block manager %s with %s RAM, %s".format(
id.hostPort, Utils.bytesToString(maxOnHeapMemSize + maxOffHeapMemSize), id))
blockManagerIdByExecutor(id.executorId) = id
blockManagerInfo(id) = new BlockManagerInfo(
id, System.currentTimeMillis(), maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint)
}
listenerBus.post(SparkListenerBlockManagerAdded(time, id, maxOnHeapMemSize + maxOffHeapMemSize,
Some(maxOnHeapMemSize), Some(maxOffHeapMemSize)))
id
}
该方法的执行流程如下:
- 构造BlockManagerId实例。
- 如果BlockManagerInfo中没有维护这个BlockManagerId,但是却存在与它对应的Executor,那么就移除该Executor(认为它已经死掉了)。
- 将新的BlockManagerId和BlockManagerInfo放入对应的映射中。
- 向事件总线发送SparkListenerBlockManagerAdded信息,飙戏BlockManager注册成功,并最终返回它的ID。
例:处理BlockManager心跳
代码#29.5 - o.a.s.storage.BlockManagerMasterEndpoint.heartbeatReceived()方法
private def heartbeatReceived(blockManagerId: BlockManagerId): Boolean = {
if (!blockManagerInfo.contains(blockManagerId)) {
blockManagerId.isDriver && !isLocal
} else {
blockManagerInfo(blockManagerId).updateLastSeenMs()
true
}
}
这个方法就比较简单。如果blockManagerInfo中包含有对应的ID,就更新BlockManagerInfo中对应的最后一次心跳时间lastSeenMs。接下来看BlockManagerSlaveEndpoint。
从RPC端点BlockManagerSlaveEndpoint
BlockManagerSlaveEndpoint的实现比上面那位要简单不少,但总体逻辑大同小异。构造BlockManagerSlaveEndpoint时需要传入对本节点上BlockManager的引用,这是很自然的,否则就没办法将RPC消息与对块的操作打通了。下面直接看它覆写的receiveAndReply()方法。
代码#29.6 - o.a.s.storage.BlockManagerSlaveEndpoint.receiveAndReply()方法
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RemoveBlock(blockId) =>
doAsync[Boolean]("removing block " + blockId, context) {
blockManager.removeBlock(blockId)
true
}
case RemoveRdd(rddId) =>
doAsync[Int]("removing RDD " + rddId, context) {
blockManager.removeRdd(rddId)
}
case RemoveShuffle(shuffleId) =>
doAsync[Boolean]("removing shuffle " + shuffleId, context) {
if (mapOutputTracker != null) {
mapOutputTracker.unregisterShuffle(shuffleId)
}
SparkEnv.get.shuffleManager.unregisterShuffle(shuffleId)
}
case RemoveBroadcast(broadcastId, _) =>
doAsync[Int]("removing broadcast " + broadcastId, context) {
blockManager.removeBroadcast(broadcastId, tellMaster = true)
}
case GetBlockStatus(blockId, _) =>
context.reply(blockManager.getStatus(blockId))
case GetMatchingBlockIds(filter, _) =>
context.reply(blockManager.getMatchingBlockIds(filter))
case TriggerThreadDump =>
context.reply(Utils.getThreadDump())
case ReplicateBlock(blockId, replicas, maxReplicas) =>
context.reply(blockManager.replicateBlock(blockId, replicas.toSet, maxReplicas))
}
其中有一部分消息是同步处理的,其他的是异步处理的(因为上面的四个Remove消息对应的操作耗时都相对较长)。由于所有的动作都对应到BlockManager的方法调用,所以我们在讲解BlockManager时,再来看这部分的具体实现。
BlockManagerMaster
对主从RPC端点有了一定了解之后,就可以真正来看BlockManagerMaster是做什么的了。它的实现实际上比我们想象的简单太多,仅仅是对所有RPC消息代理了BlockManagerMasterEndpoint的EndpointRef.ask()/askSync()方法,向RPC端点发送与BlockManager相关的各类消息。由于消息类型很多,所以只看3个有代表性的。
代码#29.7 - o.a.s.storage.BlockManagerMaster.removeExecutor()/removeExecutorAsync()/registerBlockManager()方法
def removeExecutor(execId: String) {
tell(RemoveExecutor(execId))
logInfo("Removed " + execId + " successfully in removeExecutor")
}
def removeExecutorAsync(execId: String) {
driverEndpoint.ask[Boolean](RemoveExecutor(execId))
logInfo("Removal of executor " + execId + " requested")
}
def registerBlockManager(
blockManagerId: BlockManagerId,
maxOnHeapMemSize: Long,
maxOffHeapMemSize: Long,
slaveEndpoint: RpcEndpointRef): BlockManagerId = {
logInfo(s"Registering BlockManager $blockManagerId")
val updatedId = driverEndpoint.askSync[BlockManagerId](
RegisterBlockManager(blockManagerId, maxOnHeapMemSize, maxOffHeapMemSize, slaveEndpoint))
logInfo(s"Registered BlockManager $updatedId")
updatedId
}
其中,driverEndpoint就是BlockManagerMasterEndpoint的端点引用,slaveEndpoint就是BlockManagerSlaveEndpoint的端点引用。这些方法的实现都大同小异,因此也就不再废话了。
总结
一张图总结,如下。
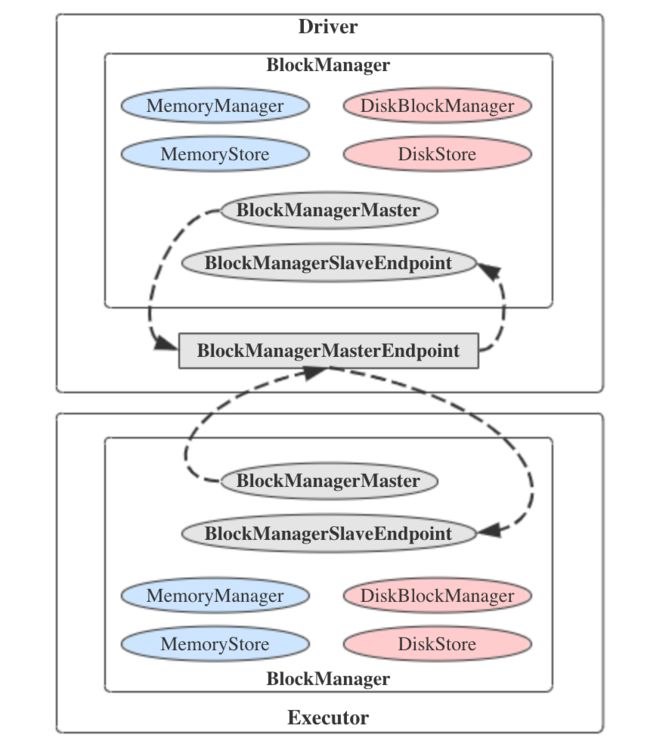
由本文的分析可见,BlockManagerMaster的名字有些许误导性:实际上在每个节点都会有一个BlockManagerMaster,而不是Driver上有BlockManagerMaster,Executor上有BlockManagerSlave(当然它是不存在的)。BlockManager的主从则是靠RPC端点体系来体现的。之所以叫这个名字,可能是为了避免出现“块管理器管理器”(BlockManagerManager)这样更奇怪的名字吧。
晚安。