目录
- 简介
- 安装
环境信息
2.1 安装 JDK
2.2 修改系统设置
2.3 创建用户
2.4 安装 Elastic Search
2.5 安装 Kibana
2.6 配置中文分词器 analysis ik - 概念
3.1 基本概念
3.3.1 Index
3.3.2 Document
3.3.3 Type
3.3.4 Mapping
3.2 分词
3.3 倒排索引 - 在 Kibana 中进行增删改查
4.1 创建索引
4.2 新增
4.3 查询
4.4 更新
4.5 删除
4.6 MultiGet 批量获取
4.7 Bulk 批量添加、修改、删除 - 版本控制
5.1 内部版本控制
5.2 外部版本控制 - Mapping
6.1 什么是 Mapping
6.2 Mapping 的数据类型
6.3 Mapping 的属性 - 基本查询(英文)
7.1 简单查询
7.2 term 查询和 terms 查询
7.3 控制查询返回的数量
7.4 返回版本号
7.5 match 查询
7.6 指定返回的字段
7.7 控制加载的字段
7.8 排序
7.9 前缀匹配查询
7.10 范围查询
7.11 wildcard查询
7.12 fuzzy 模糊查询
7.13 高亮搜索结果 - 基本查询(中文)
- 过滤查询(Filter )
9.1 简单过滤查询
9.2 bool 过滤查询
9.3 范围过滤
9.4 非空过滤
9.5 过滤器缓存 - 聚合查询
- 复合查询
11.1 bool 查询
11.2 constant_score 查询
下接:【ElasticSearch】从了解到使用
1. 简介
Elastic Stack
Elastic Stack 是 Elastic 公司一系列软件的集合,是一个开源的解决方案,可以收集各种类型,各种格式的源数据,同时提供数据搜索,分析和可视化的展示。

-
Elasticsearch:是一个基于 Lucene 的拥有分布式多用户能力的全文搜索引擎,它提供了 RESTful 接口。了解 RESTful API
 Elasticsearch 架构图
Elasticsearch 架构图 Kibana:配合 Elasticsearch 使用的可视化工具。
Beats:一个精简的数据采集器。
Logstash:用于数据的抽取和过滤,类似 ETL。
2. 安装
环境信息
系统:Centos 7.6
机器IP:192.168.0.233
JDK:1.8.0_211
要安装的软件
Elastic Search:7.2.0
Kinaba:7.2.0
2.1 安装 JDK
查看安装方法
要求 1.8 及以上
2.2 修改系统设置
使用 root 用户登录
修改最大线程数和句柄数,vi /etc/security/limits.conf 添加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
用户退出后重新登陆生效
修改虚拟内存大小,vi /etc/sysctl.conf 添加以下内容
vm.max_map_count=262144
使设置生效 sysctl -p
2.3 创建用户
ES 默认不能使用 root 用户启动,如果用 root 用户启动,启动时需要加上参数 -Des.insecure.allow.root=true
这里就先创建一个新用户吧
创建用户: useradd es
设置密码: passwd es
切换到新用户: su es
2.4 安装 Elastic Search
进入官网下载
解压: tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz
修改文件夹名称: mv elasticsearch-7.2.0 elasticsearch
修改配置文件: vi elasticsearch/config/elasticsearch.yml
-- 修改地址:network.host: 192.168.0.233
-- 节点名称: node.name: node-1
-- 集群设置:cluster.initial_master_nodes: ["node-1"]
运行: ./elasticsearch/bin/elasticsearch &
浏览器访问 http://192.168.0.233:9200 会得到一些信息:
{
"name": "node-1",
"cluster_name": "elasticsearch",
"cluster_uuid": "kMaKec3GQ6SZt9OpMwvRJg",
"version": {
"number": "7.2.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "508c38a",
"build_date": "2019-06-20T15:54:18.811730Z",
"build_snapshot": false,
"lucene_version": "8.0.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
2.5 安装 Kibana
进入官网下载

解压: tar -zxvf kibana-7.2.0-linux-x86_64.tar.gz
修改文件夹名称: mv kibana-7.2.0-linux-x86_64 kibana
修改配置文件: vi kibana/config/kibana.yml
-- 修改 ES 地址: elasticsearch.hosts: ["http://192.168.0.233:9200"]
-- 修改 kibana 地址:server.host: "192.168.0.233"
-- 修改语言: i18n.locale: "zh-CN"
运行: ./kibana/bin/kibana &
浏览器访问 http://192.168.0.233:5601,中文界面感觉很亲切

2.6 配置中文分词器 IK
此章节不是必须,若不需要可跳过
前往下载插件 选择对应的 7.2.0 版本

将插件放到 elasticsearch/plugins/ik 目录
[es@localhost plugins]$ pwd
/home/es/elasticsearch/plugins/ik
[es@localhost plugins]$ ls
elasticsearch-analysis-ik-7.2.0.zip
解压 unzip elasticsearch-analysis-ik-7.2.0.zip,系统没有 unzip 命令可 查看安装方法
重启 ES 可以看到下面的信息就表示插件安装成功了
[2019-07-20T19:25:29,310][INFO ][o.e.p.PluginsService ] [node-1] loaded plugin [analysis-ik]
现在可以将插件压缩包删除了 rm elasticsearch-analysis-ik-7.2.0.zip
3. 概念
3.1 基本概念
3.3.1 Index
Elastic 会索引所有字段,经过处理后写入一个倒排索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
类似于关系型数据库中的 Database。
3.3.2 Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
Document 使用 JSON 格式表示,同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
类似于关系型数据库中的数据,一个 Document 相当于一行数据。
3.3.3 Type
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。
性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type。
类似于关系型数据库中的 Table。
注意:6.x 以前版本一个 Index 可以有多个 Type;6.x 版本,一个 Index 只能有一个 Type;7.x 版本抛弃 了 Type 这个概念)。
和关系型数据库做个类比的话,他们的关系是:
Index > Database
Document > data
Type > Table
可以想象一下,有一个数据库,它的一个数据库实例(Index)只能有一张表(Type),我们直接往这个实例中插入数据(Document)。
3.3.4 Mapping
参考第6节:Mapping 和数据类型
3.2 分词
分词:从一串文本中切分出一个一个的词条,并对每个词条进行标准化
分词器包括三部分:
character filter:分词之前的预处理,过滤掉HTML标签,特殊符号转换等
tokenizer:分词
token filter:标准化
内置分词器:
- standard 分词器:
Elasticsearch 默认的分词器,它会将词汇单元转换成小写形式,并去除停用词和标点符号,支持中文采用的方法为单字切分 - simple 分词器:
首先会通过非字母字符来分割文本信息,然后将词汇单元统一为小写形式。该分析器会去掉数字类型的字符。 - Whitespace 分词器:
仅仅是去除空格,对字符没有lowcase化,不支持中文;并且不对生成的词汇单元进行其他的标准化处理。 - language 分词器:
特定语言的分词器,不支持中文
3.3 倒排索引
Elasticsearch 使用一种称为倒排索引的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
示例1:
-
假设文档集合包含五个文档,每个文档内容如图所示,在图中最左端一栏是每个文档对应的文档编号。

-
中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引

-
索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息(TF)即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。
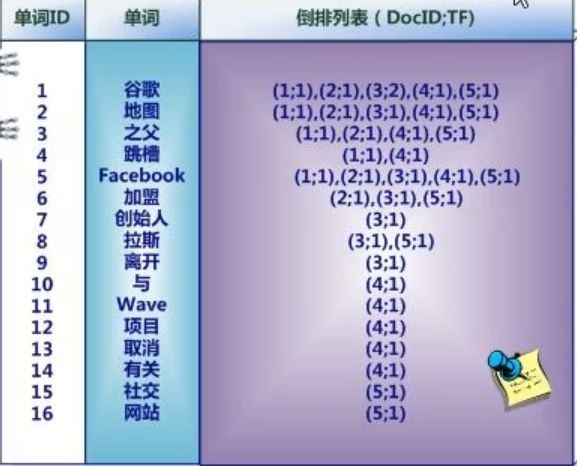
倒排列表中还可以记录单词在某个文档出现的位置信息
(1,<11>,1),(2,<7>,1),(3,<3,9>,2)
上面表示:
在 id 为1的文档中出现1次,位置为11
在 id 为2的文档中出现1次,位置为7
在 id 为3的文档中出现2次,位置为3和9
示例2:
现在有两个文档
1.The quick brown fox jumped over the lazy dog
2.Quick brown foxes leap over lazy dogs in summer
我们来手动进行分词:
| Term | Doc_1 | Doc_2 |
|---|---|---|
| Quick | X | |
| The | X | |
| brown | X | X |
| dog | X | |
| dogs | X | |
| fox | X | |
| foxes | X | |
| in | X | |
| jumped | X | |
| lazy | X | X |
| leap | X | |
| over | X | X |
| quick | X | |
| summer | X | |
| the | X |
这里搜索 quick brown 的话,就会是下面这个情况:
| Term | Doc_1 | Doc_2 |
|---|---|---|
| brown | X | X |
| quick | X | |
| Total | 2 | 1 |
可以看到文档1中两个单词都有,文档2中只有一个,说明文档1的匹配度比文档2要高。
但是这样分词有很多问题:
- Quick 和 quick 以独立的词条出现,然而用户可能认为它们是相同的词。
- fox 和 foxes 非常相似, 就像 dog 和 dogs ;他们有相同的词根。
- jumped 和 leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
- 搜索含有 Quick fox的文档是搜索不到的
实际上,ES 在建立倒排索引时,会使用标准化规则(normalization):
建立倒排索引的时候,会对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率
实际上的倒排索引:
| Term | Doc_1 | Doc_2 |
|---|---|---|
| brown | X | X |
| dog | X | X |
| fox | X | X |
| in | X | |
| jump | X | X |
| lazy | X | X |
| over | X | X |
| quick | X | X |
| summer | X | |
| the | X | X |
4. 在 Kibana 中进行增删改查
进入 Kibana 中的开发工具

4.1 创建索引
PUT /lib/
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}
}
number_of_shards 分片数量,一旦确定是不能修改的
number_of_replicas 备份数量,因为只有一台机器,就设置为0
点击绿色箭头运行

显示结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "lib"
}
创建索引时可以不给定参数,此时使用默认配置
PUT lib2
查看 lib2 的索引配置
GET lib2/_settings
{
"lib2" : {
"settings" : {
"index" : {
"creation_date" : "1563624230345",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "PhbovgGYTHyc8UlF04nqPg",
"version" : {
"created" : "7020099"
},
"provided_name" : "lib2"
}
}
}
}
查看所有索引的配置
GET _all/_settings
4.2 新增
新增一个用户信息(user)的文档
指定 id PUT /Index/Type/id(覆盖) 或 不指定 id POST /Index/Type/
在 6.x 及以前的版本中,可以自己定义 Type,比如 PUT /lib/user/1,7.x 版本只能使用 _doc 或 _create 作为 Type
指定 id:
PUT /lib/_doc/1
{
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
{
"_index" : "lib",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
不指定 id 会由 es 自动生成 id:
POST /lib/_doc/
{
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
{
"_index" : "lib",
"_type" : "_doc",
"_id" : "QUVVD2wBaGnqhTuBKxcM",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
4.3 查询
GET /Index/Index/id?_source=key1,key2···
查询 id 为 1 的文档
GET /lib/_doc/1
{
"_index" : "lib",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests" : [
"music"
]
}
}
查询 id 为 1 的文档中的 age 和 about
GET /lib/_doc/1?_source=age,about
{
"_index" : "lib",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"about" : "I like to collect rock albums",
"age" : 32
}
}
4.4 更新
更新有两种:使用新的文档将旧的覆盖掉 或者 更新内容 POST /Index/_update/id/
添加时 id 相同就会覆盖,这里覆盖把 age 改为 36
PUT /lib/_doc/1
{
"first_name": "Jane",
"last_name": "Smith",
"age": 36,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
或者使用 _update 只更新 age
POST /lib/_update/1/
{
"doc": {
"age": 33
}
}
4.5 删除
删除一个文档 DELETE /Index/_doc/id
DELETE /lib/_doc/1
删除 Index DELETE /Index
DELETE /lib
4.6 MultiGet 批量获取
GET /_mget 如果索引相同,可以写成 GET /Index/_mget
格式 :
GET /_mget
{
"docs": [
{
"_index": "Index", // 指定 index
"_id": id, // 指定 id
"_source": ["key1","key2"......] // 指定要获取的字段
},
......
]
}
索引不同的示例:
GET /_mget
{
"docs": [
{
"_index": "lib",
"_id": 123,
"_source": ["age"]
},
{
"_index": "lib2",
"_id": 234,
"_source": ["first_name", "last_name"]
},
{
"_index": "lib3",
"_id": 345
}
]
}
索引相同的示例:
GET /lib/_mget
{
"docs": [
{
"_id": 1,
"_source": ["age"]
},
{
"_id": 2,
"_source": ["first_name", "last_name"]
},
{
"_id": 3
}
]
}
如果只有 id 参数,可以写成:
GET /lib/_mget
{
"ids": [
"1",
"2",
"3"
]
}
4.7 Bulk 批量添加、修改、删除
bulk 的格式:
POST /Index/_bulk
{action:{metadata}}
{requstBody}
......
action 有四种:
- create:文档不存在时创建,如文档已经存在,则操作失败
- update:更新文档
- index:创建新文档或替换已有文档
- delete:删除一个文档
示例 1, 批量添加:
POST /lib/_bulk
{"index":{"_id":1}}
{"title":"Java","price":55}
{"index":{"_id":2}}
{"title":"Html5","price":45}
{"index":{"_id":3}}
{"title":"Php","price":35}
{"index":{"_id":4}}
{"title":"Python","price":50}
示例 2, 多种操作同时执行
POST /lib/_bulk
{"delete":{"_index":"lib2","_id":4}} // 删除操作没有请求体
{"create":{"_index":"tt","_id":"100"}}
{"name":"lisi"}
{"index":{"_index":"tt"}}
{"name":"zhaosi"}
{"update":{"_index":"lib2","_id":"4"}}
{"doc":{"price":58}}
bulk 会把要处理的数据载入内存,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件 elasticsearch.yml 中修改。
5. 版本控制
5.1 内部版本控制
ElasticSearch 采用了乐观锁来保证数据的一致性,对文档的每次操作都会使版本号 +1,ElasticSearch 的版本号的取值范围为1到2^63-1。
当用户对 document 进行操作时,并不需要对该 document 作加锁和解锁的操作,只需要指定要操作的版本即可。当版本号一致时,ElasticSearch 会允许该操作顺利执行,而当版本号存在冲突时,ElasticSearch 会提示冲突并抛出异常(VersionConflictEngineException)。
内部版本控制使用的是 _version
查看一个文档
GET /lib/_doc/1
可以看到文档的版本号为 5
{
"_index" : "lib",
"_type" : "_doc",
"_id" : "1",
"_version" : 5,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "Java",
"price" : 58
}
}
当更新的版本号错误时,会报错:
PUT /lib/_doc/1?version=4
{
"first_name": "Jane1",
"last_name": "Smith1",
"age": 34,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
{
"error": {
"root_cause": [
{
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"
}
],
"type": "action_request_validation_exception",
"reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"
},
"status": 400
}
5.2 外部版本控制
一般关系型数据库使用时间戳来做版本控制,当 Elasticsearch 需要跟关系型数据库同步时,就需要使用外部版本控制了。
Elasticsearch 在处理外部版本号时会与对内部版本号的处理有些不同。它不再是检查 _version 是否与请求中指定的数值相同,而是检查当前的 _version 是否比指定的数值小。如果请求成功,那么外部的版本号就会被存储到文档中的 _version中 。
外部版本控制使用 version_type=external
PUT /lib/_doc/1?version=11&version_type=external
{
"first_name": "Jane1",
"last_name": "Smith1",
"age": 34,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
{
"_index" : "lib",
"_type" : "_doc",
"_id" : "1",
"_version" : 88,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}
6. Mapping
6.1 什么是 Mapping
当创建 Index、Type、Document 时,ES 会自动添加对应的 Mapping,当 ES 在文档中碰到一个以前没见过的字段时,它会利用动态映射(dynamic mapping)来决定该字段的类型,并自动地对该字段添加映射。
可以通过 dynamic 设置来控制这一行为,它能够接受以下的选项:
- true:默认值。动态添加字段
- false:忽略新字段
- strict:如果碰到陌生字段,抛出异常
dynamic 设置可以适用在根对象上或者 object 类型的任意字段上。
给 lib2 创建索引类型
POST /lib2
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": {
"books": {
"properties": {
"title": {
"type": "text"
},
"name": {
"type": "text",
"index": false
},
"publish_date": {
"type": "date",
"index": false
},
"price": {
"type": "double"
},
"number": {
"type": "object",
"dynamic": true
}
}
}
}
}
使用 GET /Index/_mapping 查看 mapping
GET /lib/_mapping
{
"lib" : {
"mappings" : {
"properties" : {
"about" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"first_name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
......
}
}
}
}
Mapping 定义了 type 中的每个字段的数据类型以及这些字段如何分词等相关属性。创建索引的时候,可以预先定义字段的类型以及相关属性,这样就能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理字符串值等。
6.2 Mapping 的数据类型
核心数据类型(Core datatypes)
- 字符型:string,string类型包括 text 和 keyword
text类型被用来索引长文本,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。允许es来检索这些词语。text类型不能用来排序和聚合。
Keyword类型不需要进行分词,可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索 - 数字型:long, integer, short, byte, double, float
- 日期型:date
- 布尔型:boolean
- 二进制型:binary
复杂数据类型(Complex datatypes)
- 数组类型(Array datatype):数组类型不需要专门指定数组元素的type,例如:
字符型数组: [ "one", "two" ]
整型数组:[ 1, 2 ]
数组型数组:[ 1, [ 2, 3 ]] 等价于[ 1, 2, 3 ]
对象数组:[ { "name": "Mary", "age": 12 }, { "name": "John", "age": 10 }] - 对象类型(Object datatype):_ object _ 用于单个JSON对象;
- 嵌套类型(Nested datatype):_ nested _ 用于JSON数组;
地理位置类型(Geo datatypes)
- 地理坐标类型(Geo-point datatype):_ geo_point _ 用于经纬度坐标;
- 地理形状类型(Geo-Shape datatype):_ geo_shape _ 用于类似于多边形的复杂形状;
特定类型(Specialised datatypes)
- IPv4 类型(IPv4 datatype):_ ip _ 用于IPv4 地址;
- Completion 类型(Completion datatype):_ completion _提供自动补全建议;
- Token count 类型(Token count datatype):_ token_count _ 用于统计做了标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少。
- mapper-murmur3类型:通过插件,可以通过 _ murmur3 _ 来计算 index 的 hash 值;
- 附加类型(Attachment datatype):采用 mapper-attachments 插件,可支持_ attachments _ 索引,例如 Microsoft Office 格式,Open Document 格式,ePub, HTML 等。
6.3 Mapping 支持的属性
- "store":false
是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值 - "index": true
分词,不分词是:false,设置成false,字段将不会被索引 - "analyzer":"ik"
指定分词器,默认分词器为standard analyzer - "boost":1.23
字段级别的分数加权,默认值是1.0 - "doc_values":false
对not_analyzed字段,默认都是开启,分词字段不能使用,对排序和聚合能提升较大性能,节约内存 - fielddata":{"format":"disabled"}
针对分词字段,参与排序或聚合时能提高性能,不分词字段统一建议使用doc_value - "fields":{"raw":{"type":"string","index":"not_analyzed"}}
可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词 - "ignore_above":100
超过100个字符的文本,将会被忽略,不被索引 - "include_in_all":ture
设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项 - "index_options":"docs"
4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs - "norms":{"enable":true,"loading":"lazy"}
分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量 - "null_value":"NULL"
设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词 - "position_increament_gap":0
影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100 - "search_analyzer":"ik"
设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能 - "similarity":"BM25"
默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效 - "term_vector":"no"
默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
7. 基本查询(英文)
数据准备:
PUT /lib3
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"address": {
"type": "text"
},
"age": {
"type": "integer"
},
"interests": {
"type": "text"
},
"birthday": {
"type": "date"
}
}
}
}
PUT /lib3/_doc/1
{
"name": "lisi",
"address": "bei jing hai dian qu qing he zhen",
"age": 23,
"birthday": "1998-10-12",
"interests": "xi huan duanlian,hejiu,changge"
}
PUT /lib3/_doc/2
{
"name": "wangwu",
"address": "bei jing hai dian qu qing he zhen",
"age": 24,
"birthday": "1996-10-12",
"interests": "xi huan dalanqiu,paobu,changge"
}
PUT /lib3/_doc/3
{
"name": "zhaoliu",
"address": "bei jing hai dian qu qing he zhen",
"age": 26,
"birthday": "1999-10-12",
"interests": "xi huan shuijiao,chifan,fadai"
}
7.1 简单查询
查询 name 为 lisi 的数据
GET /lib3/_search?q=name:lisi
{
"took" : 124, // 耗时
"timed_out" : false, // 是否超时
"_shards" : { //分片信息
"total" : 3, // 分片数量
"successful" : 3, // 3个分片都查询成功了
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1, // 查询出的文档个数
"relation" : "eq"
},
"max_score" : 0.2876821, // 查出的文档和执行搜索的匹配度
"hits" : [
{
"_index" : "lib3",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "lisi",
"address" : "bei jing hai dian qu qing he zhen",
"age" : 23,
"birthday" : "1998-10-12",
"interests" : "xi huan duanlian,hejiu,changge"
}
}
]
}
}
查询有 changge 的兴趣数据,并按年龄倒序排序
GET /lib3/user/_search?q=interests:changge&sort=ag:desc
7.2 term 查询和 terms 查询
term query会去倒排索引中寻找确切的term,它并不知道分词器的存在。这种查询适合keyword 、numeric、date。
term:查询某个字段里含有某个关键词的文档
GET /lib3/_search/
{
"query": {
"term": {
"interests": "changge"
}
}
}
terms:查询某个字段里含有多个关键词的文档,只要有一个匹配就会被查出来
GET /lib3/_search
{
"query": {
"terms": {
"interests": [
"hejiu",
"changge"
]
}
}
}
7.3 控制查询返回的数量
from:从哪一个文档开始
size:需要的个数
GET /lib3/_search
{
"from": 0,
"size": 2,
"query": {
"terms": {
"interests": [
"hejiu",
"changge"
]
}
}
}
7.4 返回版本号
version: true
GET /lib3/_search
{
"version": true,
"query": {
"terms": {
"interests": [
"hejiu",
"changge"
]
}
}
}
7.5 match 查询
match query 知道分词器的存在,会对 filed 进行分词操作,然后再查询
会对 name 进行分词,会查出来两个,而 term 会把 zhaoliu lisi 看成一个词,一个都查不出来
GET /lib3/_search
{
"query": {
"match": {
"name": "zhaoliu lisi"
}
}
}
match_all:查询所有文档
GET /lib3/_search
{
"query": {
"match_all": {}
}
}
multi_match:可以指定多个字段
在 interests 和 name 中查询 lisi
GET /lib3/_search
{
"query": {
"multi_match": {
"query": "lisi",
"fields": [
"interests",
"name"
]
}
}
}
match_phrase:短语匹配查询
查询和短语一模一样的文档(标点、空格可以不一样)
GET lib3/_search
{
"query": {
"match_phrase": {
"interests": "shuijiao,chifan,fadai"
}
}
}
7.6 指定返回的字段
GET /lib3/_search
{
"_source": [
"address",
"name"
],
"query": {
"match": {
"interests": "changge"
}
}
}
7.7 控制加载的字段
和上面差不多
GET /lib3/_search
{
"query": {
"match_all": {}
},
"_source": {
"includes": [
"name",
"address"
],
"excludes": [
"age",
"birthday"
]
}
}
使用通配符 *
GET /lib3/_search
{
"_source": {
"includes": "addr*",
"excludes": [
"name",
"bir*"
]
},
"query": {
"match_all": {}
}
}
7.8 排序
使用sort实现排序 :
desc:降序,asc:升序
GET /lib3/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
7.9 前缀匹配查询
GET /lib3/_search
{
"query": {
"match_phrase_prefix": {
"name": {
"query": "zhao"
}
}
}
}
7.10 范围查询
range:实现范围查询
参数:from,to,include_lower,include_upper,boost
include_lower:是否包含范围的左边界,默认是true
include_upper:是否包含范围的右边界,默认是true
GET /lib3/_search
{
"query": {
"range": {
"birthday": {
"from": "1990-10-10",
"to": "2018-05-01"
}
}
}
}
7.11 wildcard 查询
允许使用通配符* 和 ?来进行查询
*代表0个或多个字符
?代表任意一个字符
GET /lib3/_search
{
"query": {
"wildcard": {
"name": "li?i"
}
}
}
7.12 fuzzy 模糊查询
- value:查询的关键字
- boost:查询的权值,默认值是1.0
- min_similarity:设置匹配的最小相似度,默认值为0.5,对于字符串,取值为0-1(包括0和1);对于数值,取值可能大于1;对于日期型取值为1d,1m等,1d就代表1天
- prefix_length:指明区分词项的共同前缀长度,默认是0
- max_expansions:查询中的词项可以扩展的数目,默认可以无限大
这里 changge 写成了 chagge 还是能查出来
GET /lib3/_search
{
"query": {
"fuzzy": {
"interests": "chagge"
}
}
}
GET /lib3/_search
{
"query": {
"fuzzy": {
"interests": {
"value": "chagge"
}
}
}
}
7.13 高亮搜索结果
高亮的结果会被加上 标签,放在网页上就是高亮了
GET /lib3/_search
{
"query": {
"match": {
"interests": "changge"
}
},
"highlight": {
"fields": {
"interests": {}
}
}
}
8. 基本查询(中文)
准备数据,这次指定中文分析器
ik 带有两个分词器
ik_max_word:会将文本做最细粒度的拆分,尽可能多的拆分词语
ik_smart:会做粗细粒度的拆分,已经被分出的词语将不会再次被其他词语占有
PUT /lib3
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
},
"age": {
"type": "integer"
},
"interests": {
"type": "text",
"analyzer": "ik_max_word"
},
"birthday": {
"type": "date"
}
}
}
}
PUT /lib3/_doc/1
{
"name": "李四",
"address": "北京海淀区清河镇",
"age": 23,
"birthday": "1998-10-12",
"interests": "喜欢锻炼、喝酒、唱歌"
}
PUT /lib3/_doc/2
{
"name": "王五",
"address": "黑龙江省铁岭",
"age": 24,
"birthday": "1996-10-12",
"interests": "喜欢打篮球、跑步、唱歌"
}
PUT /lib3/_doc/3
{
"name": "李六",
"address": "北京海淀区清河镇",
"age": 26,
"birthday": "1999-10-12",
"interests": "喜欢吃饭、睡觉、发呆"
}
查询和英文的差不多,这里给一个查询示例:
GET /lib3/_search
{
"query": {
"terms": {
"interests": [
"唱歌",
"喝酒"
]
}
}
}
9. 过滤查询(Filter)
filter 是不计算相关性的,同时可以cache。因此,filter速度要快于query。
数据准备
PUT /lib4
POST /lib4/_bulk
{"index": {"_id": 1}}
{"price": 40,"itemID": "ID100123"}
{"index": {"_id": 2}}
{"price": 50,"itemID": "ID100124"}
{"index": {"_id": 3}}
{"price": 25,"itemID": "ID100124"}
{"index": {"_id": 4}}
{"price": 30,"itemID": "ID100125"}
{"index": {"_id": 5}}
{"price": null,"itemID": "ID100127"}
9.1 简单过滤查询
GET /lib4/_search
{
"post_filter": {
"terms": {
"price": [
25,
40
]
}
}
}
9.2 bool 过滤查询
可以实现组合过滤查询
格式:
{
"bool": {
"must": [],
"should": [],
"must_not": []
}
}
- must:必须满足的条件 -- and
- should:可以满足也可以不满足的条件 -- or
- must_not:不需要满足的条件 -- not
GET /lib4/_search
{
"post_filter": {
"bool": {
"should": [
{
"term": {
"price": 25
}
},
{
"term": {
"itemID": "id100123"
}
}
],
"must_not": {
"term": {
"price": 30
}
}
}
}
}
嵌套使用 bool
GET /lib4/_search
{
"post_filter": {
"bool": {
"should": [
{
"term": {
"itemID": "id100123"
}
},
{
"bool": {
"must": [
{
"term": {
"itemID": "id100124"
}
},
{
"term": {
"price": 40
}
}
]
}
}
]
}
}
}
9.3 范围过滤
gt: >
lt: <
gte: >=
lte: <=
GET /lib4/_search
{
"post_filter": {
"range": {
"price": {
"gt": 25,
"lt": 50
}
}
}
}
9.4 非空过滤
GET /lib4/_search
{
"query": {
"bool": {
"filter": {
"exists": {
"field": "price"
}
}
}
}
}
GET /lib4/_search
{
"query": {
"constant_score": {
"filter": {
"exists": {
"field": "price"
}
}
}
}
}
9.5 过滤器缓存
ElasticSearch 提供了一种特殊的缓存,即过滤器缓存(filter cache),用来存储过滤器的结果,被缓存的过滤器并不需要消耗过多的内存(因为它们只存储了哪些文档能与过滤器相匹配的相关信息),而且可供后续所有与之相关的查询重复使用,从而极大地提高了查询性能。
ElasticSearch并不是默认缓存所有过滤器,以下过滤器默认不缓存:
- numeric_range
- script
- geo_bbox
- geo_distance
- geo_distance_range
- geo_polygon
- geo_shape
- and
- or
- not
10. 聚合查询
sum
GET /lib4/_search
{
"size": 0,
"aggs": {
"price_of_sum": {
"sum": {
"field": "price"
}
}
}
}
min
GET /lib4/_search
{
"size": 0,
"aggs": {
"price_of_min": {
"min": {
"field": "price"
}
}
}
}
max
GET /lib4/_search
{
"size": 0,
"aggs": {
"price_of_max": {
"max": {
"field": "price"
}
}
}
}
avg
GET /lib4/_search
{
"size": 0,
"aggs": {
"price_of_avg": {
"avg": {
"field": "price"
}
}
}
}
cardinality 基数,互不相同数据的个数
GET /lib4/_search
{
"size": 0,
"aggs": {
"price_of_cardi": {
"cardinality": {
"field": "price"
}
}
}
}
terms 分组
GET /lib4/_search
{
"size": 0,
"aggs": {
"price_group_by": {
"terms": {
"field": "price"
}
}
}
}
练习:对那些有唱歌兴趣的用户按年龄分组
GET /lib3/_search
{
"query": {
"match": {
"interests": "changge"
}
},
"size": 0,
"aggs": {
"age_group_by": {
"terms": {
"field": "age",
"order": {
"avg_of_age": "desc"
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
}
11. 复合查询
复合查询就是把各种查询条件组合在一起,也叫组合查询
11.1 bool 查询
接收以下参数:
- must:
文档必须匹配这些条件才能被包含进来。 - must_not:
文档必须不匹配这些条件才能被包含进来。 - should:
如果满足这些语句中的任意语句,将增加 _score,否则,无任何影响。它们主要用于修正每个文档的相关性得分。 - filter:
必须匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
相关性得分是如何组合的?
每一个子查询都独自地计算文档的相关性得分。一旦他们的得分被计算出来, bool 查询就将这些得分进行合并并且返回一个代表整个布尔操作的得分。
下面的查询用于查找 title 字段匹配 how to make millions 并且不被标识为 spam 的文档。那些被标识为 starred 或在2014之后的文档,将比另外那些文档拥有更高的排名。如果 两者 都满足,那么它排名将更高:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
如果没有 must 语句,那么至少需要能够匹配其中的一条 should 语句。但,如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。
如果我们不想因为文档的时间而影响得分,可以用 filter 语句来重写前面的例子:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }}
}
}
}
通过将 range 查询移到 filter 语句中,我们将它转成不评分的查询,将不再影响文档的相关性排名。由于它现在是一个不评分的查询,可以使用各种对 filter 查询有效的优化手段来提升性能。
bool 查询本身也可以被用做不评分的查询。简单地将它放置到 filter 语句中并在内部构建布尔逻辑:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
11.2 constant_score 查询
它将一个不变的常量评分应用于所有匹配的文档。它被经常用于你只需要执行一个 filter 而没有其它查询(例如,评分查询)的情况下。
{
"constant_score": {
"filter": {
"term": { "category": "ebooks" }
}
}
}
term 查询被放置在 constant_score 中,转成不评分的filter。这种方式可以用来取代只有 filter 语句的 bool 查询。