一.Hive 官网介绍
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Authorization
Hive Authorization
- Introduction
- Hive Authorization Options
- Use Cases
- Overview of Authorization Modes
- 1 Storage Based Authorization in the Metastore Server
- 2 SQL Standards Based Authorization in HiveServer2
- 3 Authorization using Apache Ranger & Sentry
- 4 Old default Hive Authorization (Legacy Mode)
- Addressing Authorization Needs of Multiple Use Cases
- Explain Authorization
- More Information
Introduction
Note that this documentation is referring to Authorization which is verifying if a user has permission to perform a certain action, and not about Authentication (verifying the identity of the user). Strong authentication for tools like the Hive command line is provided through the use of Kerberos. There are additional authentication options for users of HiveServer2.
Hive Authorization Options
Three modes of Hive authorization are available to satisfy different use cases.
Use Cases
It is useful to think of authorization in terms of two primary use cases of Hive.
- Hive as a table storage layer. This is the use case for Hive's HCatalog API users such as Apache Pig, MapReduce and some Massively Parallel Processing databases (Cloudera Impala, Facebook Presto, Spark SQL etc). In this case, Hive provides a table abstraction and metadata for files on storage (typically HDFS). These users have direct access to HDFS and the metastore server (which provides an API for metadata access). HDFS access is authorized through the use of HDFS permissions. Metadata access needs to be authorized using Hive configuration.
- Hive as a SQL query engine. This is one of the most common use cases of Hive. This is the 'Hive view' of SQL users and BI tools. This use case has the following two subcategories:
- Hive command line users. These users have direct access to HDFS and the Hive metastore, which makes this use case similar to use case 1. Note, that usage of Hive CLI will be officially deprecated soon in favor of Beeline.
- ODBC/JDBC and other HiveServer2 API users (Beeline CLI is an example). These users have all data/metadata access happening through HiveServer2. They don't have direct access to HDFS or the metastore.
Overview of Authorization Modes
1 Storage Based Authorization in the Metastore Server
In use cases 1 and 2a, the users have direct access to the data. Hive configurations don't control the data access. The HDFS permissions act as one source of truth for the table storage access. By enabling Storage Based Authorization in the Metastore Server, you can use this single source for truth and have a consistent data and metadata authorization policy. To control metadata access on the metadata objects such as Databases, Tables and Partitions, it checks if you have permission on corresponding directories on the file system. You can also protect access through HiveServer2 (use case 2b above) by ensuring that the queries run as the end user (hive.server2.enable.doAs option should be "true" in HiveServer2 configuration – this is a default value).
Note, that through the use of HDFS ACL (available in Hadoop 2.4 onwards) you have a lot of flexibility in controlling access to the file system, which in turn provides more flexibility with Storage Based Authorization. This functionality is available as of Hive 0.14 (HIVE-7583).
2 SQL Standards Based Authorization in HiveServer2
Although Storage Based Authorization can provide access control at the level of Databases, Tables and Partitions, it can not control authorization at finer levels such as columns and views because the access control provided by the file system is at the level of directory and files. A prerequisite for fine grained access control is a data server that is able to provide just the columns and rows that a user needs (or has) access to. In the case of file system access, the whole file is served to the user. HiveServer2 satisfies this condition, as it has an API that understands rows and columns (through the use of SQL), and is able to serve just the columns and rows that your SQL query asked for.
SQL Standards Based Authorization (introduced in Hive 0.13.0, HIVE-5837) can be used to enable fine grained access control. It is based on the SQL standard for authorization, and uses the familiar grant/revoke statements to control access. It needs to be enabled through HiveServer2 configuration.
Note that for use case 2a (Hive command line) SQL Standards Based Authorization is disabled. This is because secure access control is not possible for the Hive command line using an access control policy in Hive, because users have direct access to HDFS and so they can easily bypass the SQL standards based authorization checks or even disable it altogether. Disabling this avoids giving a false sense of security to users.
3 Authorization using Apache Ranger & Sentry
Apache Ranger and Apache Sentry are apache projects that use plugins provided by hive to do authorization.
The policies are maintained under repositories under those projects.
You also get many advanced features using them. For example, with Ranger you can view and manage policies through web interface, view auditing information, have dynamic row and column level access control (including column masking) based on runtime attributes.
4 Old default Hive Authorization (Legacy Mode)
Hive Old Default Authorization (was default before Hive 2.0.0) is the authorization mode that has been available in earlier versions of Hive. However, this mode does not have a complete access control model, leaving many security gaps unaddressed. For example, the permissions needed to grant privileges for a user are not defined, and any user can grant themselves access to a table or database.
This model is similar to the SQL standards based authorization mode, in that it provides grant/revoke statement-based access control. However, the access control policy is different from SQL standards based authorization, and they are not compatible. Use of this mode is also supported for Hive command line users. However, for reasons mentioned under the discussion of SQL standards based authorization (above), it is not a secure mode of authorization for the Hive command line.
在Ambari集群按照此文档修改两个参数,实际并无效果,hive cli方式执行SQL,仍然要求用户有HDFS目录权限。
create role test_role;
show current roles;
set role admin;
grant select on database tableautest to role test_role;
grant select on tableautest.msg_push to role test_role;
grant role test_role to user umelog;
show grant role test_role on database tableautest;
show role grant user umelog;
show grant user umelog on all;
revoke select on tableautest.msg_push from role test_role;
revoke role test_role from user umelog;
二.Ambari官网介绍Securing Apache Hive
https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.2/bk_data-access/content/managing_using_hive.html
Securing Apache Hive
Authorization determines whether a user has the required permissions to perform select operations, such as creating, reading, and writing data, as well as editing table metadata. Apache Ranger provides centralized authorization for all HDP components, and Hive also provides three authorization models. Administrators should consider the specific use case when choosing an authorization model.
There are two primary use cases for Hive:
-
Table storage layer
Many HDP components and underlying technologies, such as Apache Hive, Apache HBase, Apache Pig, Apache MapReduce, and Apache Tez rely on Hive as a table storage layer.
-
SQL query engine
Hadoop administrators, business analysts, and data scientists use Hive to run SQL queries, both from the Hive CLI and remotely through a client connecting to Hive through HiveServer2. These users often configure a data analysis tool, such as Tableau, to connect to Hive through HiveServer2.
 image
imageWhen using a JDBC or ODBC driver, the value of the hive.server2.enable.doAs configuration property in the
hive.site.xmlfile determines the user account that runs a Hive query. The value assigned to this property depends on the desired Hive authorization model and, in the case of storage-based authorization, on the desired use case.
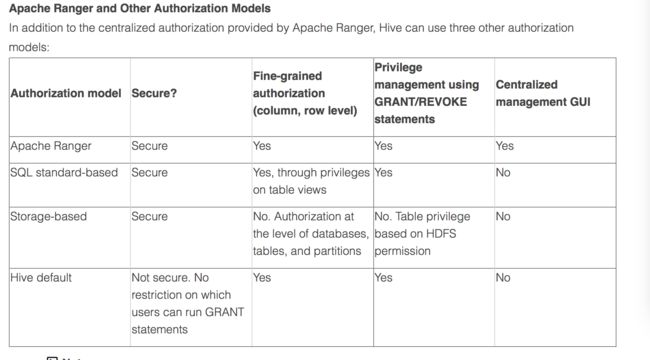
1.Authorization Using Apache Ranger Policies
https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.2/bk_data-access/content/config_authorization.html

建议使用Ranger 授权,而非Storage-based ,SQL standard-based 授权。
2.SQL Standard-Based Authorization
https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.2/bk_data-access/content/ref-34fe41bf-2db1-4cef-a58c-09f15043a7c5.1.html
3.Storage-Based Authorization
https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.2/bk_data-access/content/ref-71bf7afa-200b-4e95-9c82-0e7097dc708d.1.html
Hive 权限管理:
禁止Hive cli方式访问Hive
1,通过Ranger设置用户hive具有HDFS目录的所有权限
2,通过Ranger设置个人账户访问Hive表的权限。
开发人员启动Beeline Cli时指定自己的账号,只能在Ranger分配权限内访问Hive表,未通过Ranger分配的权限,无法访问。
比如用户A只能读取表test1, 用户B可以读取,删除表test1。
Kylin 本身提供项目和表级别的权限控制;目前通过Hive Cli 访问Hive, 可修改为Hive Beeline方式。
Presto组件设置hive.metastore.username=presto,通过Ranger将HDFS相关目录权限赋予presto。
针对Kylin组件,设置kylin用户,通过Ranger分配其所需Hive表的权限,通过beeline连接Hive。
针对Zeppelin组件,设置zeppelin用户,通过Ranger分配其所需Hive表的权限,通过beeline连接Hive。或者禁止使用。