大数据——Flume学习笔记
目录
一、Flume定义
二、Flume基本架构
三、Flume常见案例
1.监控端口数据
2.监控单个目录并将数据输出到hdfs
3.avro source
4.taildir source
5.hive sink
6.hbase sink
一、Flume定义
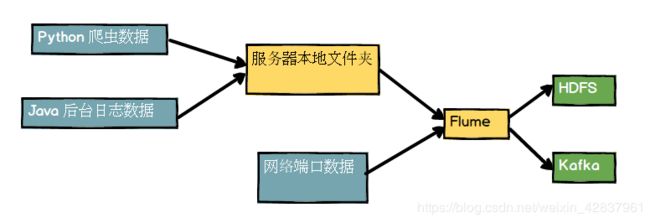
Flume 是 Cloudera 提供的一种高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。
Flume 最主要的作用是,实时读取服务器本地磁盘的数据,将数据写到 HDFS
二、Flume基本架构
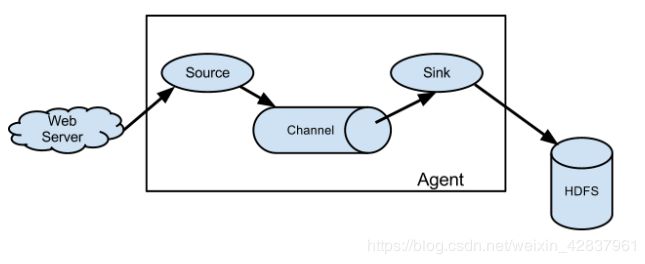
2.1 Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有三个组成部分,Source、Channel、Sink。
2.2 Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrif、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
2.3 Sink
Sink 不断地轮询 Channel 中的事件且批量移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件的目的地包括 hdfs、logger、avro、thrif、file、HBase、solr、自定义。
2.4 Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作。
Flume 常用的 Channel:Memory Channel 和 File Channel。
2.5 Event
Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。Event 由 Header 和 Body 两个部分组成。Header 用来存放该 Event 的一些属性,为 K-V 结构;Body 用来存放该条数据,形式为字节数组。
三、Flume常见案例
1.监控端口数据
1.1需求
使用 Flume 监听一个端口,收集该端口数据,并打印到控制台
1.2实现流程
a.安装netcat工具
yum -y install ncb.创建Agent Flume配置文件
#组件声明
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#初始化数据源
a1.sources.s1.type = netcat
a1.sources.s1.bind = 192.168.131.200
a1.sources.s1.port = 6666
#初始化通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 10
#初始化数据槽
a1.sinks.k1.type = logger
#关键组件
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1c.运行Flume
flume-ng agent -n a1 -c /conf -f /root/flume/flume01.conf -Dflume.root.logger=INFO,console2.监控单个目录并将数据输出到hdfs
#组件声明
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#初始化数据源
a1.sources.s1.type = spooldir
a1.sources.s1.spoolDir = /root/flume-data/logdir
a1.sources.s1.ignorePattern = ^(.)*\\.bak$
a1.sources.s1.fileSuffix = .bak
#初始化通道
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/software/flume190/mydata/checkpoint
a1.channels.dataDirs = /opt/software/flume190/mydata/data
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 10000
#初始化数据槽
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.29.144:9820/flume/events/fakeorder/%Y-%m-%d/%H
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.filePrefix = log_%Y%m%d_%H
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.threadsPoolSize = 4
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockreplicas = 1
#关联组件
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c13.avro source
#组件声明
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#初始化数据源
a1.sources.s1.type=avro
a1.sources.s1.bind=192.168.131.200
a1.sources.s1.port=7777
a1.sources.s1.threads=5
#初始化通道
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/opt/software/flume/flume190/mydata/checkpoint
a1.channels.c1.dataDirs=/opt/software/flume/flume190/mydata/data
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=10000
#初始化数据槽
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.131.200:9820/flume/events/avroevent/%Y-%m-%d/%H
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit=minute
a1.sinks.k1.hdfs.filePrefix=log_%Y%m%d_%H
a1.sinks.k1.hdfs.fileSuffix=.log
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.rollSize=134217728
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.batchSize=100
a1.sinks.k1.hdfs.threadsPoolSize=4
a1.sinks.k1.hdfs.idleTimeout=0
a1.sinks.k1.hdfs.minBlockReplicas=1
#关联组件
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c1先启侦听
#启动侦听
flume-ng agent -name a1 -c /opt/software/flume190/conf/ -f /root/flume/flume03.conf -Dflume.root.logger=INFO,console再启Agent Event
#执行命令
flume-ng avro-client -H 192.168.131.200 -p 7777 -c /conf -F /root/flume_log/test.log4.taildir source
#组件声明
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#初始化数据源:目录文件名为支持正则表达式
a1.sources.s1.type = taildir
a1.sources.s1.filegroups = f1 f2
a1.sources.s1.filegroups.f1 = /root/flume_log/tail01/pro.*\\.log
a1.sources.s1.filegroups.f2 = /root/flume_log/tail02/pro.*\\.log
a1.sources.s1.positionFile = /opt/software/flume190/data/taildir/taildir_position.conf
#初始化通道
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/software/flume190/mydata/checkpoint
a1.channels.dataDirs = /opt/software/flume190/mydata/data
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
#初始化数据槽
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.131.200:9820/flume/events/tailevent/%Y-%m-%d/%H
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.filePrefix = log_%Y%m%d_%H
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.batchSize = 1000
a1.sinks.k1.hdfs.threadsPoolSize = 4
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockreplicas = 1
#关联组件
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c15.hive sink
#flume对hive hcatalog依赖
cp /opt/software/hive312/hcatalog/share/hcatalog/*.jar ./#开启hive对事务的支持
SET hive.support.concurrency = true;
SET hive.enforce.bucketing = true; SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
SET hive.compactor.initiator.on = true;
SET hive.compactor.worker.threads = 1;#创建hive表
create table familyinfo(
family_id int,
family_name string,
family_age int,
family_gender string
)
partitioned by(intime string)
clustered by (family_gender) into 2 buckets
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as orc
tblproperties('transactional'='true');#根据当前日期时间手动添加分区
alter table familyinfo add partition(intime='21-07-05-15')#组件声明
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#taildir source
a1.sources.s1.type=taildir
a1.sources.s1.filegroups=f1
a1.sources.s1.filegroups.f1=/root/flume_log/tail03/test.log
a1.sources.s1.positionFile=/opt/software/flume190/data/test.json1
a1.sources.s1.batchSize=10
#file channel
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/opt/software/flume/flume190/mydata/checkpoint02
a1.channels.c1.dataDirs=/opt/software/flume/flume190/mydata/data
a1.channels.c1.capacity=100
a1.channels.c1.transactionCapacity=10
#hive sink
a1.sinks.k1.type=hive
a1.sinks.k1.hive.metastore=thrift://192.168.131.200:9083
a1.sinks.k1.hive.database=test
a1.sinks.k1.hive.table=familyinfo
a1.sinks.k1.hive.partition=%y-%m-%d-%H
a1.sinks.k1.useLocalTimeStamp=true
a1.sinks.k1.autoCreatePartitions=false
a1.sinks.k1.round=true
a1.sinks.k1.batchSize=10
a1.sinks.k1.roundValue=10
a1.sinks.k1.roundUnit=minute
a1.sinks.k1.serializer=DELIMITED
a1.sinks.k1.serializer.delimited=','
a1.sinks.k1.serializer.serdeSeparator=','
a1.sinks.k1.serializer.fieldnames=family_id,family_name,family_age,family_gender
#关联组件
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c16.hbase sink
#创建hbase
create 'test:stuflumehbasehbasesink','base'#组件声明
a1.sources = s1
a1.channels = c1
a1.sinks = k1
#taildir source
a1.sources.s1.type=taildir
a1.sources.s1.filegroups=f1
a1.sources.s1.filegroups.f1=/root/flume_log/tail04/test.log
a1.sources.s1.positionFile=/opt/software/flume190/data/test.json1
a1.sources.s1.batchSize=10
#file channel
a1.channels.c1.type=file
a1.channels.checkpointDir=/opt/software/flume/flume190/mydata/checkpoint02
a1.channels.dataDirs=/opt/software/flume/flume190/mydata/data
a1.channels.capacity=100
a1.channels.transactionCapacity=10
#hbase sink
a1.sinks.k1.type=hbase2
a1.sinks.k1.table = test:stuflumehbasehbasesink
a1.sinks.k1.columnFamily = base
a1.sinks.k1.serializer.regex = (.*),(.*),(.*),(.*)
a1.sinks.k1.serializer = org.apache.flume.sink.hbase2.RegexHBase2EventSerializer
a1.sinks.k1.serializer.colNames = ROW_KEY,name,age,gender
a1.sinks.k1.serializer.rowKeyIndex = 0
a1.sinks.k1.batchSize = 10
#关联组件
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c1