爬虫入门学习笔记 Day 5 + 记录遇到的小问题
目录
- 一、标签对象提取文本内容和属性值
- 二、标签切换
- 三、窗口切换
- 四、cookies操作
-
- 五、执行js代码
- 六、页面等待
-
- 1.强制分类
- 2.隐式分类(推荐使用)
- 3.显示分类(了解)
- 4.案例:(淘宝翻页)
- 七、配置对象
-
- 开启无界面模式
- 遇到的小问题
-
- 1.selenium元素定位方式语法改变了
- 2.配置对象时chrome_options参数报错
一、标签对象提取文本内容和属性值
1.获取文本:element_text
2.获取属性值:element.get_attribute(“属性名”)
代码:(在day 4学习的基础上改写for循环内的内容)
import time
from selenium import webdriver
url = 'https://bj.58.com/chuzu/?PGTID=0d200001-0000-1fd0-27cd-e5f5a55e18c9&ClickID=1'
driver = webdriver.Chrome()
driver.get(url)
#取出标题
el_list = driver.find_elements_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
for el in el_list:
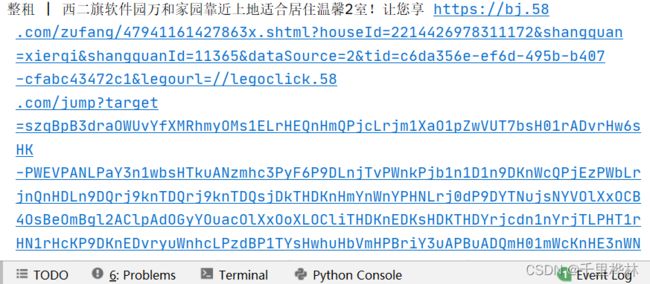
print(el.text, el.get_attribute('href'))
最后for循环输出如下:(文本+属性值)
二、标签切换
1.获取窗口句柄(列表)
句柄:指向标签页对象的标识
current_windows = driver.window_handles
2.通过窗口句柄(列表索引下标)切换标签
driver.switch_to.window(current_windows[0])
代码:
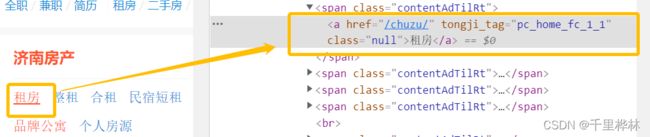
找到上图的“租房”按钮——右键,检查——copy xpath——填入find_element()
from selenium import webdriver
from selenium.webdriver.common.by import By
url = 'http://jn.58.com/'
driver = webdriver.Chrome()
driver.get(url)
#先打印出来检查一下
print(driver.current_url)
print(driver.window_handles)
#定位并且点击租房按钮
el = driver.find_element(By.XPATH,'/html/body/div[3]/div[1]/div[1]/div/div[1]/div[1]/span[1]/a')
el.click()
#点击以后再打印一下url和句柄
print(driver.current_url)
print(driver.window_handles)
以上代码是获取句柄列表的。(一开始使用find_element_by_xpath(),后面发现报错,改正方法见下面的超链接,最后改用find_element())。运行以上代码后,可以看到:
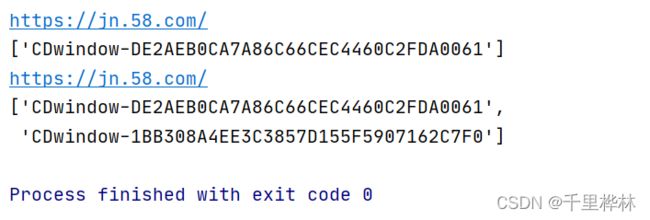
在没有点击的时候输出的句柄只有一行,点击以后有两个窗口了,所以句柄列表是两行。
从这里的url看出其实主要还是在主页操作的,页面并没有跳到新打开的页面去操作。
如果要切换窗口,就加入下面代码:
注意:复制后来打开的页面的标题的 xpath到 find_elements(),删去 li标签的索引,以选中所有的标题。

在刚才的代码后面添加:
driver.switch_to.window(driver.window_handles[-1])
el_list = driver.find_elements(By.XPATH,'/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
print(len(el_list)) #switch切换之后长度不为0
如果注释掉switch_to.window(),输出的len就是0,因为没有切换页面前,主页没有对应的标签。
三、窗口切换
用登QQ空间为例子:
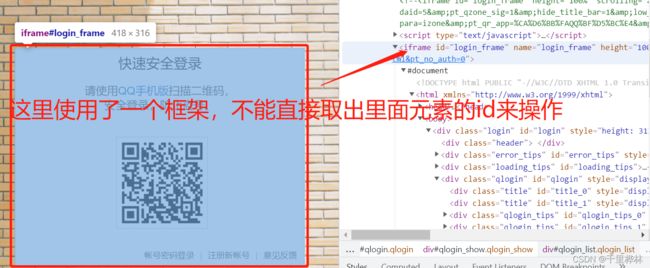
检查——查看‘账号密码登陆’按钮和账号、密码输入框的id还有登陆按钮的id。
代码:(下面的send_keys()里面要输入自己的账号和密码去登陆)
from selenium import webdriver
from selenium.webdriver.common.by import By
url = 'https://qzone.qq.com/'
driver = webdriver.Chrome()
driver.get(url)
el_frame = driver.find_element(By.XPATH,'//*[@id="login_frame"]')
driver.switch_to.frame('login_frame')
driver.find_element(By.ID,'switcher_plogin').click()
driver.find_element(By.ID,'u').send_keys('自己的账号')
driver.find_element(By.ID,'p').send_keys('自己的密码')
driver.find_element(By.ID,'login_button').click()
四、cookies操作
代码:
from selenium import webdriver
url = 'https://www.baidu.com/'
driver = webdriver.Chrome()
driver.get(url)
# print(driver.get_cookies())
# cookies = {}
# for data in driver.get_cookies():
# cookies[data['name']] = data['value']
#上面三行写成正则表达式,如下:
cookies = {data['name']:data['value'] for data in driver.get_cookies()}
print(cookies)
运行结果:
五、执行js代码
当我们遇到打开一个新的页面,所要点击的按钮不在页面中(要下拉才能看到)
滚动条的拖动:
js = ‘scrollTo(x,y)’
这里x一般为0,向下拖动的话y要输入大于0的数值。
代码:
from selenium import webdriver
import time
url = 'https://www.某个网址.com/'
driver = webdriver.Chrome()
driver.get(url)
#js语句
js = 'window.scrollTo(0,document.body.scrollHeight)'
#执行js语句
driver.execute_script(js)
time.sleep(5)
driver.quit()
六、页面等待
页面等待的3种分类:
1.强制分类
设置固定的等待时间:
time.sleep(5)
2.隐式分类(推荐使用)
设置等待时间,如果还没到时间就已经定位到了对应的元素,就进行下一步。
driver.implicitly_wait(10)
3.显示分类(了解)
明确要等待某一个元素。
4.案例:(淘宝翻页)
代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
url = 'https://www.taobao.com/'
driver = webdriver.Chrome()
driver.get(url)
time.sleep(1)
for i in range(10):
i += 1
try:
time.sleep(3)
element = driver.find_element(By.XPATH,'//div[@class="shop-inner"]/h3[1]/a')
print(element.get_attribute('href'))
break
except:
js = 'window.scrollTo(0,{})'.format(i*500)
driver.execute_script(js)
driver.quit()
七、配置对象
开启无界面模式
代码:
from selenium import webdriver
url = 'http://www.baidu.com/'
#创建配置对象
opt = webdriver.ChromeOptions()
#添加配置参数
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
#创建浏览器对象的时候添加配置对象
driver = webdriver.Chrome(options=opt)
driver.get(url)
driver.save_screenshot('无界面浏览器截图.png')
遇到的小问题
1.selenium元素定位方式语法改变了
报错: Deprecation Warning: find_element_by_* commands are deprecated. Please use find_element() instead
el = driver.find_element_by_xpath

对应我这里想要使用xpath的解决方法:
弃用by_xpath写法
同理,find_element_by_id,class等方法也是被find_element()方法所替代。
新的定位方法
最后要记得导入:
from selenium.webdriver.common.by import By
2.配置对象时chrome_options参数报错
一开始的代码:
#创建浏览器对象的时候添加配置对象
driver = webdriver.Chrome(chrome_options=opt)
报错:
Deprecation Warning: use options instead of chrome_options
可能是因为参数chrome_options已经被弃用。
将 chrome_options 替换为 options 即可。