spark调用python算法_用Python语言写Spark
001
PySpark 基础
Spark 是目前大数据处理的事实标准。PySpark能让你使用Python语言来写Spark程序。
我们先做一个最简单的字符数统计程序。这样我们就知道一个PySpark程序是什么样子,以及如何运转起来。
我们准备一个文件a.csv。里面的内容如下:
a b c,1.0a b,2.0c,3.0d,4.0
然后我们打开编辑器,比如我这里是Intellij IDEA。 新建一个myfirstpyspark.py文件。
PySpark需要你有一个SparkSession对象,这是一切的开始,在这里你可以做一些配置。
from pyspark.sql import SparkSession
session = SparkSession.builder.master("local[*]").appName("test").getOrCreate()
其中"local[*]"表示我们执行的是local模式,也就是单机模式,*表示使用所有的CPU核心,如果你写成local[2]那么表示单机模式,并且使用两个核。
在很多情况下,单机模式足够我们使用,因为他已经是多线程并行运行了,这比我们自己完成一个多线程的程序来的简单,而且,Spark可以让你的代码看起来就像单机,他自动完成分布式工作。
如果愿意,还可以运行在Standalone,Yarn,Mesos等模式下,它们都是真正的分布式模式。Spark是一个典型的Master-Slave结构。Master负责解释你写的代码,Slave则负责执行你的代码。
构建好了session之后,现在可以去读文件了。
from pyspark.sql.types import *import pyspark.sql.functions as f
df = session.read.csv( "a.csv",
encoding="utf-8",
header=False,
schema=StructType(
[StructField("text", StringType()),
StructField("index", StringType())]))
这里我使用了一个较为复杂的方式构建Dataframe, Dataframe你可以简单理解为SQL的编程表达形式。不使用常规教程提及的RDD API的原因是因为Spark花了大力气将大部分东西都迁移到Dataframe上,我们也就不要倒行逆施了。实际场景中,RDD非常灵活,但是往往导致代码难以管理和维护。Dataframe API 比较受限,但是更”SQL”化,更”结构化”,大家写出来的会是基本一致的,并且性能更好。
session.read 是一个datasource API,这个时候你获得了一个“读”对象。聪明的读者可能会思索是不是还有session.write, 实际上是有的,session.write 可以让你获得了一个写的对象。
除了读取CSV文件,你还可以读取parquet, json, elasticsearch,mysql 等其他存储器。
让我们回转过来,读取一个csv文件的方式如同上面的示例代码,具体参数我会简单说明下。
header 指的是是否有头部。CSV文件通常第一行是列名。我们这里设置为False,因为构建的文件并没有这个需求。
schema 可以指定CSV每列的名字,类型。大家只要记住是这么写就OK了。这种方式非常有用。对于非结构化数据,你可以简单认为他是只有一列的结构化数据。
现在,我们已经有了一张名字叫’df’的表,这张表有两个字段,text 和 index。 现在想统计text里每个词汇出现的次数。这在pyspark里只需要一行代码就可以搞定。
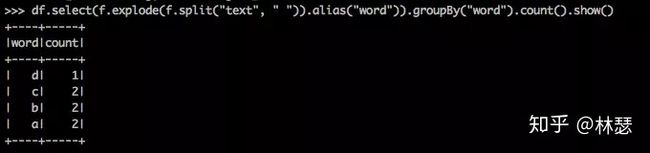
df.select(f.explode(f.split("text", " ")).alias("word")).\
groupBy("word").\
count().\
show()
最后运行的结果如下:
通过导入import pyspark.sql.functions as f 我们可以使用Spark内置的UDF函数并且使用f来进行引用,额外的收获是你可以获得更友好的代码提示。
select 你可以理解为SQL中select语法的一种编程形态。 先对text字段按空格切分,然后通过expode展开为多行,并且宠幸把行命名为word。对应的SQL为:
select explode(split("text"," ")) as word from ....
接着按word字段进行groupBy,然后count。count其实是一个简写形式,我们还可以这么写:
df.select(f.explode(f.split("text", " ")).alias("word")).\
groupBy("word").\
agg(f.count("word").alias("wordCount")).\
show()
agg 里面会填写一个聚合函数,配合groupBy使用,这和我们使用SQL的方式是一致的。现在增加个额外需求,我想排个序,应该怎么弄呢?也不是难事:
df.select(f.explode(f.split("text", " ")).alias("word")).\
groupBy("word").\
agg(f.count("word").alias("wordCount")).\
orderBy(f.desc("wordCount")).\
show()
如果觉得官方提供的UDF函数满足不了需求,我们也是可以自定义函数的。 定义一个普通的python函数:
def my_split(col):
return col.split(" ")
把my_split封装为一个UDF函数:
udf_my_split = f.udf(my_split, ArrayType(StringType()))
ArrayType(StringType()) 指的是返回类型。接着就是使用它:
df.select(f.explode(udf_my_split("text")).alias("word")). \
groupBy("word"). \
agg(f.count("word").alias("wordCount")). \
orderBy(f.desc("wordCount")). \
show()
现在我们看看如何运行这个程序。截止到现在,你的代码看起来应该是这个样子的。
# -*- coding: UTF-8 -*-import osfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import *import pyspark.sql.functions as f
spark = SparkSession.builder.master("local[*]").appName("test").getOrCreate()
df = spark.read.csv( "YOUR-PATH/a.csv",
encoding="utf-8",
header=False,
schema=StructType(
[StructField("text", StringType()),
StructField("index", StringType())]))def my_split(col):
return col.split(" ")
udf_my_split = f.udf(my_split, ArrayType(StringType()))
df.select(f.explode(udf_my_split("text")).alias("word")). \
groupBy("word"). \
agg(f.count("word").alias("wordCount")). \
orderBy(f.desc("wordCount")). \
show()
我们现在需要运行这段程序,具体方式如下:
export PYTHONIOENCODING=utf8;./bin/spark-submit \--driver-memory 2g \--master "local[*]" [YOUR-PATH]/my_first_pyspark.py
截止目前为止,我们已经能够用PySpark开发应用了,并且了解了里面的一些高级用法,比如自定义UDF函数的使用。