作者:杨新霞 上海宇佑船舶架构师
小T导读: 上海宇佑船舶科技有限公司是专注于船舶及海洋信息化一体解决方案的高科技公司。公司主要专注于智慧船舶以及船舶新材料相关产品的研发、设计、生产、销售及国际贸易,为船舶行业提供新材料和智能化信息化解决方案。公司目前提供的产品和解决方案,将会填补船舶行业特别是邮轮游艇行业缺乏信息化和智能化解决方案和最新船舶新材料的空白。

在大数据时代背景下,船舶智能化已经成为船舶制造与航运领域发展的必然趋势。同时,智能船舶也是《中国制造2025》中明确重点发展的领域,代表了船舶未来的方向,关乎航运业的转型升级。
2021年4月初公司接到一个国家级船舶试验基地的智能化改造方案,在制定技术协议的过程中,业主指定要求数据采集使用TDengine数据库。选择TDengine的核心原因如下:
- 国产化要求:国产开源,对于国家信息安全有保障,符合国家大趋势发展。
- 物联网场景:团队之前正好开发过一个小型的物联网项目,当时用的是MySQL数据库,针对数据窗口统计以及返回最新数据查询纷繁复杂。在研究TDengine时发现这些问题都能够被解决。
- 学习成本低:我们的技术团队对关系型数据库(MySQL、Oracle)的SQL语法都比较熟悉,而TDengine采用的也是标准SQL语句,团队成员上手都比较快。
值得一提的是,TDengine学习成本低这一优势使得我们的团队成员,仅用了很短的时间就掌握了其使用技能,技术风险大大降低。也因此,我们没有再进行其他更多的技术选型对比,将TDengine作为我们的底层时序数据存储引擎开始投入使用。
一、技术选型
我们对TDengine的选型依据,不是凭借着测试数字的论证,而是业务实现的实践检验。
1. 与MySQL相比
团队之前正好开发过一个小型的物联网项目,当时用的是MySQL数据库,一些数据窗口的统计以及返回最新数据的查询略显复杂,但又没有更好的解决方案,在研究TDengine时发现这些问题不攻自破。考虑到我们之后要启动的物联网项目都比较大,上述这一问题存在共性,若是能够利用TDengine简化代码逻辑甚至节省物理存储空间,那公司和业主都将受益匪浅。
2. 通用大数据对比
这一点主要是查询效率和开发成本的优势。事实上,在项目启动后,我们团队对TDengine的研究已经比较深入了。后续公司的大项目都是船舶行业的物联网项目,其中一个比较大型的项目的一期是由其他公司开发的,我们接手维护。项目接手初期,对于此项目中使用通用大数据方案实现数据采集可能会产生的效率问题,业主方表示很担忧,希望我们可以早点优化这一块。于是团队开始着手研究TDengine数据库在船舶行业的应用,发现TDengine的方案比通用大数据方案更适合这一场景。
二、数据模型
1. 建模方式分析
在我们项目中,是用的TDengine推荐的“一个设备一张表”的建模方法。这一建模方式的优势,除了TDengine官网介绍的通用性的内容,还在我们项目中展现了如下几个优点:
- TDengine中超级表和子表的设计很好地解决了单个设备写入的时间戳不会重复的问题
- 一个设备一张表解决了同一类设备聚合查询的问题
- 标签的设计可以减少大量的数据冗余,由此节省了大量物理存储空间
2. 数据类型分析
由于我们存储的数据是来自船上PLC采集数据,因此,我们首先需要论证的是PLC可能的数据类型在TDengine中能否实现很好的存储。在我们对数据类型进行匹配对比后,发现TDengine没有这类障碍。对比如下:
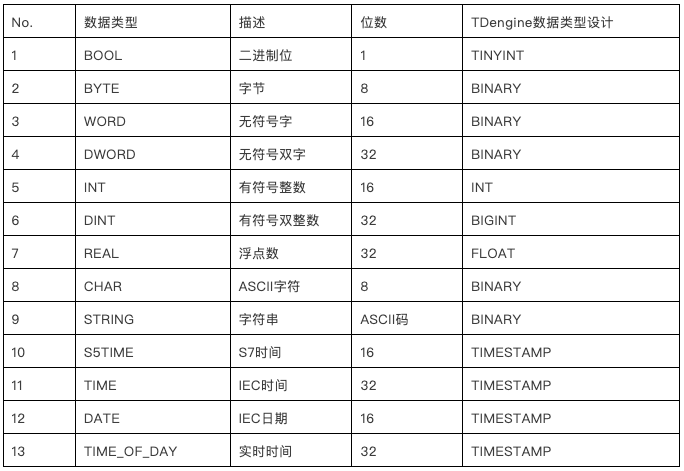
3. PLC工控数据分析
以我们业务中的船舶电站监控PLC的I/O点为例,至少具备如下数据量:
- 86个数字量输入
- 80个数字量输出
- 13路模拟量输入
- 10路模拟量输出
这里我们定的策略是,按照工业自动化控制的分类选择不同的TDengine数据类型进行存储:
- 数字量:TINYINT类型
- 开关量:INT或者FlOAT类型
- 模拟量和脉冲量:FLOAT类型
4. 业务数据分析
同时,我们针对性地分析了能够用于TDengine存储的数据,包括不限于如下内容:
- 柴油机信号:与柴油机相关的转速、油温、滑油相关的压力、冷却水相关的温度、启动空气压力、排烟总管温度等
- 发电机信号:发电机的绕组温度、发电电压、电流、有功功率、电压频率、电压与电网电压的相位差
- 电网的信号:电网相关电压、电网功率、电路电流及电流频率
三、特殊场景需求
1. 场景描述
船舶行业有一种特殊情况,即船舶在海上的时候很有可能没有网络信号,而这个时间可能会持续一个月之久,也就是船舶上的数据库最长有可能一个月内无法与岸上的数据中心同步,这就要求船舶在靠港的时候能够在短时间内完成大量的数据同步工作。 我们应用TDengine打造的技术解决方案如下所示:

2. 重点实现
- 船端实现:在船端增加应用程序,用于自动连接Kafka,并向Kafka写入数据
- Kafka实现:直接将船端和服务端的传输的内容,写入同一个Topic
- 岸端实现:对岸端服务端数据进行写入
3. 主要设计
- 技术复用设计:考虑到宇佑船舶之前使用Kafka进行同步,这个方案相对可以复用之前的技术经验
- 数据结构设计:在船端和集群端建库时,使用DB+船ID的方式作为库名,这样一来,在船端和集群端数据结构一致时,两侧的查询和高效写入SQL都比较容易处理
- 自动传输设计:本方案使用船端程序完成自动传输,使用Kafka+TDengine的更新机制保证数据断点续传(只要写入Kafka数据就会写入,而且重新写入数据会覆盖原有数据)
- 开发工作量:蓝色为需要开发的程序
四、落地效果
1. 写入性能表现
关于写入性能的确认,我们有个小的经验:在前期论证写入速度时,我们参考了TDengine官网的测试报告,并进行了部分功能的复现确认。基于此我们团队用较短的时间和较少的投入就对TDengine的性能有了大概的了解。
我们的PLC数据往TDengine中写入的时间间隔最小到100ms/点,写入性能完全能够胜任。
2. 查询性能表现
因为我们的智慧船舶系统刚开始使用TDengine,这方面的积累还比较少。除了官网介绍或者参考其他案例的一些比较普遍的查询外,TDengine毫秒级的时间窗口查询也让我们很惊喜,在数月的时间跨度上进行时间窗口查询也能在秒级完成。
我们原本计划使用通用大数据解决方案来进行此类查询,现在依托TDengine时间窗口统计功能的高效性,开发人员就可以舍弃纷繁复杂的SQL语句,极大地缩减了项目周期。
五、经验总结
我们团队在使用TDengine的落地过程中,觉得有三个经验比较重要,在此进行下分享:
- 官网学习:我们从项目开始就仔细研究官网上的技术文档,确实印证了那句话——学习新技术最省力的办法就是看官网
- 技术提问:除了从官网获取内容,我们团队也长期混迹于TDengine的官方群,只要把技术细节和问题细节描述清晰,在群里提问都能快速得到解答
- 代码示例:在项目支持过程中,TDengine的支持人员建议我们参考TDengine在Github上的测试代码,这部分代码有大量的函数示例,更加方便进行相关研究
在最近的沟通中,TDengine技术人员向我们反馈TDengine后续版本会上线TDLite功能,这个功能能够很好地解决我们系统里面[船舶离岸]这种业务场景的“端到端”数据同步问题。TDengine技术人员对我们业务需求的关注和及时反馈让我们也对这个功能充满了期待。
我们相信,凭借着TDengine数据库在内部已有项目的投产,团队积累下宝贵的实践经验,这对公司探索开发船舶行业物联网产品会大有助益,未来也希望我们能够和TDengine持续合作,形成直接面向客户的智能船舶解决方案。
想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。