五一出行你准备好了吗?Python帮你预测全国热门景点!
Show me data,用数据说话
今天我们聊一聊五一出行预测
点击下方视频,先睹为快:
今年“五一”劳动节假期时间较长,与此同时,国内疫情防控形势持续向好。自4月30日0时起,北京市疫情应急响应也从一级调至二级。五一假期期间,北京市的89家等级旅游景区开放。
再加上全国高速公路免收通行费,天气逐渐转暖,温度适宜等等。在家宅了几个月的人群都按耐不住出行游玩的想法了。与此同时,C君还是要提醒大家,目前疫情还未结束,出行时还是要避免聚集,严格做好个人防护哦!
接下来话不多说,让我们来给大家盘一盘五一出游预测数据。
五一出行预测
你准备好了吗?
近日,高德地图与中国气象局中国天气网联合发布了 《2020年五一假期出行预测报告》 ,该报告中就运用交通大数据,对全国高速拥堵趋势进行了回顾预测。
下面让我们来简单看看吧。
小长假第一天总是最堵的
从近三年五一期间全国高速的拥堵趋势来看, 小长假第一天为出程拥堵高峰 ,且第一天拥堵程度呈现逐渐走高态势, 第三天为返程高峰。

根据高德地图交通大数据预测 ,受节前通勤晚高峰及假期前一天出行影响, 预计出程拥堵高峰为4月30日,返程高峰为5月4日。

五一自驾游 西湖成最热门首选
从自驾意愿来看,预计 杭州的西湖风景名胜区、成都的都江堰景区、西安昆明池景区排名前三 ,市民自驾前往意愿较强,其中,进入都江堰景区需提前完成门票预约。

用Python分析
预测五一热门景点
想了解更多关于五一的热门景点预测吗? 下面我们就试着用Python来实现。
我们分析整理了去哪儿网上, 近一个月各大景点的门票销售数据,去重后共获得16651条,试着从中对五一期间景点热门度进行预测。
此次景点分析的过程主要分为三步:
- 数据获取
- 数据处理
- 数据可视化分析
以下是具体的步骤和代码实现:
数据获取
1
我们可以在哪去儿的门票页
http://piao.qunar.com/ticket/list.htm?keyword= ''
搜索省份关键词,就可以看到推荐的景点的一些信息。然后我们使用谷歌浏览器,按下F12打开浏览器调试窗口,查找加载数据的url(通过翻页观察):
可以很容易地发现json数据的请求地址:
https://piao.qunar.com/ticket/list.json?keyword=%E5%8C%97%E4%BA%AC&page=2
其中keyword参数可以输入搜索关键词,page参数用于控制页数进行翻页。

本次我们需要获取的主要有:景点名称、景点星级、景点评分、景点介绍、经纬度、地区、月销量、票价等。
在爬虫的过程中我们首先请求第一页的网址获取到总页数,然后进行循环翻页。
具体代码实现:
# 导入包
import requests
import json
import pandas as pd
import time
def get_qunaer_one_city(search_city):
"""
功能:给定城市和页数,获取一页的信息
"""
# 获取URL
url_1 = 'https://piao.qunar.com/ticket/list.json?keyword={}&page=1'.format(search_city)
# 添加Headers
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
# 先发起一次请求
response = requests.get(url_1, headers=headers)
data = response.json()['data']
# 所有页数
totalCount = int(data.get('totalCount') / 15)+1
# 存储数据
df_all = pd.DataFrame()
# 循环获取
for page_num in range(1, totalCount+1):
url_2 = 'https://piao.qunar.com/ticket/list.json?keyword={}&page={}'.format(search_city, page_num)
# 发起请求
try:
response = requests.get(url_2, headers=headers, timeout=3)
except ProxyError:
response = requests.get(url_2, headers=headers, timeout=3)
# 获取数据
data = response.json()['data']
# 景点名称
sightName = [i.get('sightName') for i in data['sightList']]
# 景点星级
star = [i.get('star', '无') for i in data['sightList']]
# 景点评分
score = [i.get('score', 0) for i in data['sightList']]
# 景点介绍
intro = [i.get('intro', '') for i in data['sightList']]
# 景点经纬度
point = [i.get('point') for i in data['sightList']]
# 景点地区
districts = [i.get('districts') for i in data['sightList']]
# 相关景点
childrenCount = [i.get('childrenCount', 0) for i in data['sightList']]
# 月销量
saleCount = [i.get('saleCount', 0) for i in data['sightList']]
# 门票价格
Price = [i.get('qunarPrice', 0) for i in data['sightList']]
# 保存数据
df_one = pd.DataFrame({
'sightName': sightName,
'star': star,
'score': score,
'intro': intro,
'point': point,
'districts': districts,
'childrenCount': childrenCount,
'saleCount': saleCount,
'qunarPrice': Price
})
# 追加数据
df_all = df_all.append(df_one, ignore_index=True)
# 打印进度
print('我正在获取第{}页'.format(page_num))
# 休眠一秒
time.sleep(1)
return df_all
传入省份名称即可获取一个省份的全部数据,此次我们获取了全国34个省份的数据,去重之后一共16651条,获取的数据以数据框的形式存储,结果如下所示:
df_all.head()

读入数据与数据预处理
2
对于获取的数据,我们需要进行进一步的处理以满足分析的需求,我们主要做的数据处理步骤如下:
- 删除重复值
- 从districts字段中提取省份数据
- 计算销售额,销售额=saleCount(月销量) * qunarPrice(价格)
代码如下:
# 导入包 import numpy as np import pandas as pd import os from pyecharts.charts import Bar, Pie, Map, Page, BMap, Scatter from pyecharts import options as opts
# 获取文件路径
data_files = os.listdir('./data/')
# 从磁盘中循环读取数据
df_all = pd.DataFrame()
for file in data_files:
df_one = pd.read_excel('./data/{}'.format(file))
df_all = df_all.append(df_one, ignore_index=True)
# 复制一份
df_qa = df_all.copy()
# 删除重复值
df_qa.drop_duplicates(inplace=True)
# 提取省份
df_qa['province'] = df_qa.districts.str.split('·').apply(lambda x:x[0])
# 计算销售额
df_qa['sales_volume'] = df_qa['saleCount'] * df_qa['qunarPrice']
数据可视化
3
我们使用的工具是pyecharts,我们主要对以下几个方面的信息进行可视化分析。
- 各星级景点数量
- 全国各省份景点数量Top15
- 各省份销量热力图
- 景点门票销量排行分析Top20
各星级景点数量

首先对全国景点星级的数据进行整理, 发现全国4A景点占比达到15.85%,3A为4.23%,5A最少占比仅为2.48%。而没有星级的景点比重高达77.44%。
代码实现:
# 景点星级分布
star_num = df_qa['star'].value_counts()
# 数据对
data_pair = [list(z) for z in zip(star_num.index, star_num.values.tolist())]
# 饼图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add(
series_name="num",
radius=["35%", "60%"],
data_pair=data_pair,
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
pie1.set_global_opts(legend_opts=opts.LegendOpts(pos_left="left", pos_top='30%', orient="vertical"),
title_opts=opts.TitleOpts(title='全国景点星级分布'))
pie1.set_series_opts(
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a}
{b}: {c} ({d}%)")
)
pie1.render()
全国各省份景点数量Top15
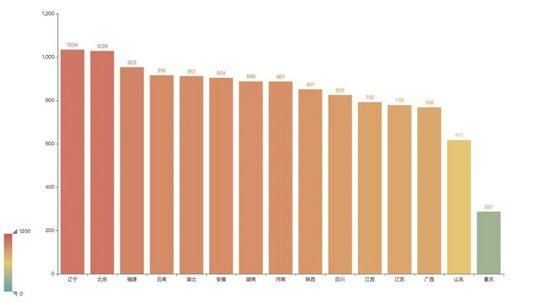
那么景点在全国的分布情况如何呢?通过整理分析可以看到, 景点数量前三的分布是辽宁、北京和福建。 令人意外的是,辽宁的景点数量居然以微弱的优势超过了北京,不过其中很多是没有星级的景点。
代码实现:
# 国内城市top15
city_top10 = df_qa.province.value_counts()[:15]
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(city_top10.index.tolist())
bar1.add_yaxis("省份", city_top10.values.tolist())
bar1.set_global_opts(title_opts=opts.TitleOpts(title="全国景点数量Top10"),
visualmap_opts=opts.VisualMapOpts(max_=1200))
bar1.render()
各省份景点门票销量热力图
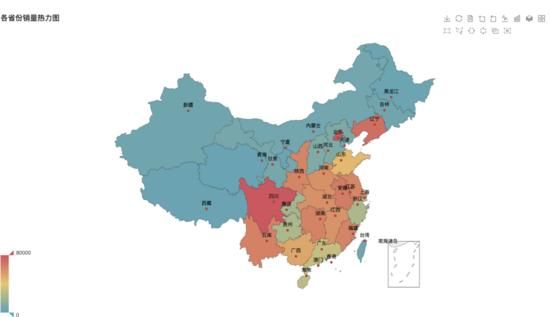
再看到各省市景门票销售的情况,从图中可以 看到四川、北京、云南、辽宁等地的景点门票销量都特别高,在全国名列前茅。
代码实现:
saleCount_num = df_qa.groupby('province')['saleCount'].sum().sort_values(ascending=False)
# 地图
map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))
map1.add("", [list(z) for z in zip(saleCount_num.index.tolist(), saleCount_num.values.tolist())],
maptype='china')
map1.set_global_opts(title_opts=opts.TitleOpts(title='各省份销量热力图'),
visualmap_opts=opts.VisualMapOpts(max_=80000))
map1.render()
景点门票销量排行分析Top20
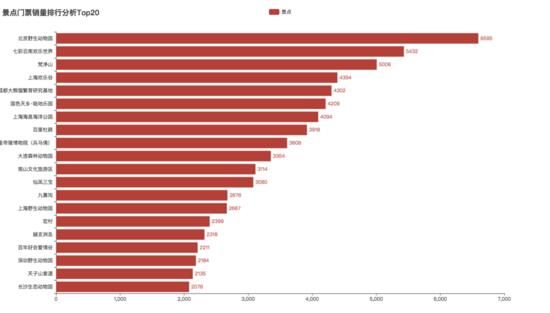
我们再来具体来看看哪些景点最受欢迎。
经过分析发现前三分别是 北京野生动物园、七彩云南欢乐世界、梵净山 。其次 上海欢乐谷、成都大熊猫基地 紧随其后。看来随着温度上升,在这次难得的五天小长假,带着一家人久违的出去逛逛动物园、爬爬山、看看大熊猫都是大家忠爱的选择。
结语
最后C君还是要提醒大家,五一”小长假的来临,不少人都有出行计划,景区也正在有序恢复开放。但同时疫情仍未结束,大家在出行时一定要注意个人防护哦~
源码获取代码文件视频教程:850591259