网络协议抓包分析与爬虫入门
目录
- 一.wireshark抓取网络数据包
-
- 1.打开程序并检测联通性
- 2.进行抓包
- 3.抓取的信息分析
- 二.爬虫入门-抓取网页信息
-
- 1.抓取南阳理工学院ACM题目网站练习题目数据
-
- 1.操作原理
- 2.实践操作
- 2.抓取本校(重庆交通大学)新闻网站中近几年所有的信息通知的发布日期和标题
- 三.总结
- 四.参考文献
一.wireshark抓取网络数据包
1.打开程序并检测联通性
1.打开疯狂聊天软件输入呢称和房间号

2.发送一条为123的信息,可以发现已经发送成功

3.在另一台电脑上同样方式创建另一个用户,输入相同的房间号

4.输入消息“abc‘,点击发送

5.可以发现用户一已经接收到消息

2.进行抓包
1.通过分析程序源码可以看到程序通过UDP向255.255.255.255发送信息

2.此处使用用户like发送一个224334的信息

3.打开wireshark,使用ip.dst==255.255.255.255进行筛选,可以看到已经捕捉到了这条信息

3.抓取的信息分析
1.查看具体信息可以发现就是刚刚发送的信息

2.可以发现端口号为6000,通过分析源码可以得知端口号为房间号+5000,而我们的房间号为1000

3.发送英文可以直接呈现,而我们使用用户like01发送一句中文为“like帅”可以发现中文无法直接呈现而是占用3个字节,通过分析可以发现中文经过了utf-8转换,一个中文占三个字节,呈现为三个点。


总的来说,中文编码为3个字节,而西文字符只用一个。

二.爬虫入门-抓取网页信息
1.抓取南阳理工学院ACM题目网站练习题目数据
1.操作原理
1.爬虫从初始网页的URL开始,获取初始网页上的URL
2.在抓取网页的过程中,不断从当前页面上抽取新的URL放X队列
3.直到满足系统给定的停止条件
2.实践操作
1.操作代码:
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')
subject = []
for t in td:
if t.string is not None:
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n题目信息爬取完成!!!')

2.查看结果


2.抓取本校(重庆交通大学)新闻网站中近几年所有的信息通知的发布日期和标题
1.打开重庆交通大学新闻网站:http://news.cqjtu.edu.cn/xxtz.htm.

2.键盘右键F12,查看网页源代码,找到新闻标题所在位置,也就是需要爬取的内容。
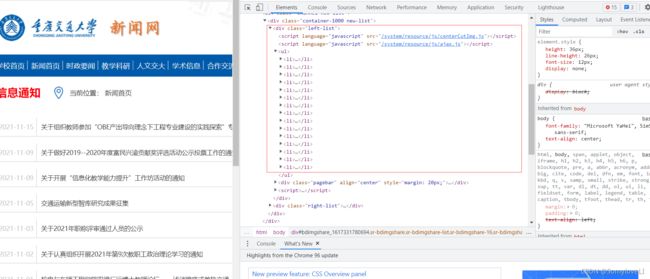

3.代码:
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
import urllib.request, urllib.error # 制定URL 获取网页数据
# 所有新闻
subjects = []
# 模拟浏览器访问
Headers = { # 模拟浏览器头部信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.53"
}
# 表头
csvHeaders = ['时间', '标题']
print('信息爬取中:\n')
for pages in tqdm(range(1, 65 + 1)):
# 发出请求
request = urllib.request.Request(f'http://news.cqjtu.edu.cn/xxtz/{pages}.htm', headers=Headers)
html = ""
# 如果请求成功则获取网页内容
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 解析网页
soup = BeautifulSoup(html, 'html5lib')
# 存放一条新闻
subject = []
# 查找所有li标签
li = soup.find_all('li')
for l in li:
# 查找满足条件的div标签
if l.find_all('div',class_="time") is not None and l.find_all('div',class_="right-title") is not None:
# 时间
for time in l.find_all('div',class_="time"):
subject.append(time.string)
# 标题
for title in l.find_all('div',class_="right-title"):
for t in title.find_all('a',target="_blank"):
subject.append(t.string)
if subject:
print(subject)
subjects.append(subject)
subject = []
# 保存数据
with open('cqjtu_news.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
print('\n信息爬取完成!!!')

4.爬取内容查看


三.总结
通过本次实验,了解到了如何使用爬虫抓取信息,并且熟悉了相关的基本操作,爬虫在很多情况下能够减少我们的工作量,避免浪费时间。同时学会抓包可以帮助我们在网络编程过程中很好的测试,可以在网络通信中抓取到任何自己需要的信息。
四.参考文献
https://blog.csdn.net/qq_47281915/article/details/121356226?spm=1001.2014.3001.5501.