声明:所有文章只作为学习笔记用,转载非原创
宋宝华 https://blog.csdn.net/21cnbao/article/details/103839437
glibc是GNU发布的libc库,即c运行库。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。
linux 启动 https://www.jianshu.com/p/c961875ee123
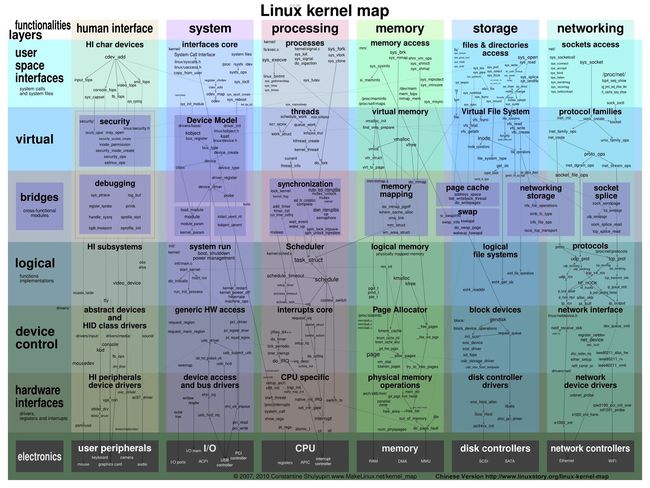
linux 运行原理图 2.6 https://10.linuxstory.net/linux-kernel-map/
子进程运行过程:
1)父进程调用fork() 产生一个新的自进程;
2)子进程调用exec() 指定自己要执行的代码;
3)子进程调用exit() 退出,进入zombie状态;
4)父进程调用wait(),等待子进程的返回,回收其所有资源;
进程地址空间
https://zhuanlan.zhihu.com/p/68398179
https://zhuanlan.zhihu.com/p/25098193
linux 进程的虚拟内存 https://blog.csdn.net/fengxinlinux/article/details/52071766
1. 每个进程的4G内存空间只是虚拟内存空间,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址
2. 所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。
3. 进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,需要用页表来记录
4.页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
5. 当进程访问某个虚拟地址,去看页表,如果发现对应的数据不在物理内存中,则缺页异常
6.缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果内存已经满了,没有空地方了,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,需要将此页写回磁盘
由MMU在运行时将虚拟地址映射成(或者说转换成)某个物理内存页面中的地址。如图所示:
https://www.cnblogs.com/linhaostudy/p/6687432.html
大多数使用虚拟存储器的系统都使用一种称为分页(paging)。虚拟地址空间划分成称为页(page)的单位
VA(虚地址),MVA(修正后虚地址),PA(物理地址)
1)VA,是程序中的逻辑地址,0x00000000~0xFFFFFFFF。
2)MVA,由于多个进程执行,逻辑地址会重合。所以,跟据进程号将逻辑地址分布到整个内存中。MVA = (PID << 25) | VA
3)PA,MVA通过MMU转换后的地址。
(1)cpu看到的是VA
(2)caches和MMU使用的是MVA,
(3)实际物理设设备使用的是PA。


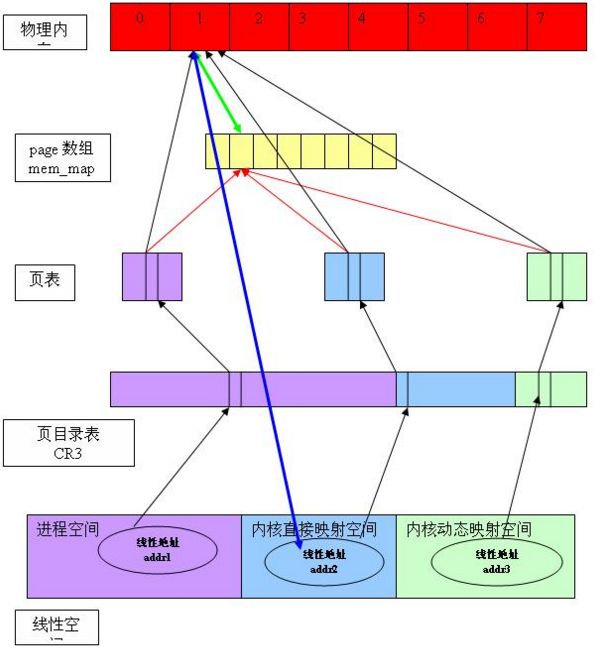
上图反映了如下信息:
1、 进程的4G 线性空间被划分成三个部分:进程空间(0-3G)、内核直接映射空间(3G– high_memory)、内核动态映射空间(VMALLOC_START - VMALLOC_END)
2、 三个空间使用同一张页目录表,通过 CR3 可找到此页目录表。但不同的空间在页目录表中页对应不同的项,因此互相不冲突
3、 内核初始化以后,根据实际物理内存的大小,计算出 high_memory、VMALLOC_START、VMALLOC_END 的值。并为“内核直接映射”空间建立好映射关系,所有的物理内存都可以通过此空间进行访问。
4、 “进程空间”和“内核动态映射空间”的映射关系是动态建立的(通过缺页异常)
假设在有三个线性地址 addr1, addr2, addr3 ,分别属于三个线性空间不同部分(0-3G、3G-high_memory、vmalloc_start-vmalloc_end),但是最终都映射到物理页面1:
1、 三个地址对应不同的页表和页表项
2、 但是页表项的高20bit肯定是1,表示物理页面的索引号是1
3、 同时,根据高20bit,可以从 mem_map[]中找到对应的struct page结构,struct page 用于管理实际的物理页面(就是实际物理页面的物理地址了,到这里就不绕弯子了,顺便想到高速缓冲的匹配命中操作是用哈希表,换算出的要访问的实际物理地址拿到哈希表的输入计算一下哈希值,看看有没命中)(红线)
4、 从线性地址最终的,根据页目录表,页表,可以找到物理地址
5、 struct page和物理地址之间很容易互相转换
6、 从物理地址,可以很容易的反推出在内核直接映射空间的线性地址(蓝线)。要想得到在进程空间或者内核动态映射空间的对应的线性地址,则需要遍历相应的“虚存区间”链表。
页表 https://blog.csdn.net/m0_37329910/article/details/85222931
进程的运行过程 https://www.cnblogs.com/klvchen/articles/11763452.html
cgroup https://blog.csdn.net/huang987246510/article/details/80765628
cgroups,其名称源自控制组群(control groups)的简写,是Linux内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)
Linux系统glibc库版本信息查看 https://www.cnblogs.com/jiftle/p/11584780.html
有时我们经常需要查看当前系统的glibc版本,可以这样查看:
/lib/libc.so.6 ---直接执行
有时:/lib/x86-64-linux/libc.so.6
把这个文件当命令执行一下
Just execute:
ldd --version --- ldd是list, dynamic, dependencies的缩写 列出动态库依赖关系。
ldd 命令 https://blog.csdn.net/nzjdsds/article/details/86759843
ldd /bin/ls
输出示例
libstdc++.so.6 => /usr/lib64/libstdc++.so.6 (0x00000039a7e00000)
libm.so.6 => /lib64/libm.so.6 (0x0000003996400000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00000039a5600000)
libc.so.6 => /lib64/libc.so.6 (0x0000003995800000)
/lib64/ld-linux-x86-64.so.2 (0x0000003995400000)
第一列:程序需要依赖什么库
第二列: 系统提供的与程序需要的库所对应的库
第三列:库加载的开始地址
====================================================================
linux 读写文件的过程 https://blog.csdn.net/KingOfMyHeart/article/details/90272050
https://blog.csdn.net/21cnbao
视频 https://www.bilibili.com/video/av79890150?from=search&seid=10039787655842011702
笔记 https://blog.csdn.net/qq_37375427/article/details/83004951?from=timeline
Linux 进程映像 https://www.jianshu.com/p/8953feee0e03
Linux的进程地址空间(一) https://zhuanlan.zhihu.com/p/66794639
Linux 消息队列、共享内存、信号量(一)消息队列 https://blog.csdn.net/qq_33225741/article/details/72861413
Linux 如何查看一个进程的堆栈
有两种方法:
第一种:pstack 进程ID
第二种,使用gdb 然后attach 进程ID,然后再使用命令 thread apply all bt
第三种:strace -f -p pid 该方法和pstack类似
第四中:gcore pid ,输出core文件,gdb cmd corefile
两种方法都可以列出进程所有的线程的当前的调用栈。
不过,使用gdb的方法,还可以查看某些信息,例如局部变量,指针等。
不过,如果只看调用栈的话,pstack还是很方便的。
strace 用法 https://blog.csdn.net/cs729298/article/details/81906375
strace 输出的时候会有用 Linux mmap内存映射 https://blog.csdn.net/weixin_34101229/article/details/91395524
https://blog.csdn.net/yusiguyuan
在计算机中,系统调用(英语:system call),又称为系统呼叫,指运行在用户空间的程序向操作系统内核请求需要更高权限运行的服务。
系统调用提供用户程序与操作系统之间的接口。操作系统的进程空间分为用户空间和内核空间:
操作系统内核直接运行在硬件上,提供设备管理、内存管理、任务调度等功能。
用户空间通过API请求内核空间的服务来完成其功能——内核提供给用户空间的这些API, 就是系统调用。
在Linux系统上,应用代码通过glibc库封装的函数,间接使用系统调用。
Linux内核目前有300多个系统调用,详细的列表可以通过syscalls手册页查看。这些系统调用主要分为几类:
文件和设备访问类 比如open/close/read/write/chmod等
进程管理类 fork/clone/execve/exit/getpid等
信号类 signal/sigaction/kill 等
内存管理 brk/mmap/mlock等
进程间通信IPC shmget/semget * 信号量,共享内存,消息队列等
网络通信 socket/connect/sendto/sendmsg 等
cpu个数,核数,线程之间的关系 https://blog.csdn.net/helloworld0906/article/details/90547159
PCB https://www.cnblogs.com/Kirino1/p/9710062.html
linux 概念及架构 https://www.jianshu.com/p/c5ae8f061cfe

了解程序开发过程
搭建开发环境,了解 Linux 上程序开发过程。
学会使用文本编辑工具 Vim,编译工具 gcc, as, 连接工具 ld, 调试工具 gdb, make 工具,会写 makefile。
用 C 语言实现并编译自己的测试程序。
尝试系统编程
试着在 Linux 上用 C 语言进行系统编程,
其中需要调用 Linux 系统库函数 (API)。
例如,实现一个需要进行网络通信、操作文件的多线程/进程程序。
以此深入了解 Linux 系统运行机制。
进程 自己的笔记:
进程--->pcb--->task_struct
进程: 进程是一个资源分配单位。弄清楚一个进程,就是搞清楚一个进程的资源。
进程控制块 PCB: 进程控制块 (Processing Control Block),是操作系统核心中一种数据结构,主要表示进程状态。
task_struct : 描述进程使用的资源(结构) ( task_struct结构体,不要死记硬背。)
pid : cat /proc/sys/kernel/pid_max 最大进程数量
进程是有父子关系的
linux 描述进程的数据结构:利用多种数据结构来描述task_struct ( 设计思想 )
链表(遍历进程,无法表示父子结构),树结构(快速查看父子结构),哈希(例如能根据pid快速定位进程相关信息)
进程的生命周期: 进程fork出来后的状态,(宏观并行,微观串行(状态切换就比较微观))
进程生命周期中的基本状态: linux里总是“白发人(父进程)”送“黑发人(子进程)”
就绪 : fork 出来就处于 《------- linux 就绪和运行的标志是一样的 -------》 运行 : 拿到cpu 就是运行态
思考: 就绪和运行之间的切换,一个程序不可能总占用cpu,比如我运行QQ,微信, 微博,其中任何一个 不可能一直占用cpu,
进程时间片和抢占(速度是非常快的,宏观的比喻我正在用QQ聊天,但是有一个更重要的紧急事情 需要做)
--------按时间片轮转 先来先服务 短时间优先 按优先级别
睡眠 : (深睡眠,浅睡眠)
深睡眠:必须要等到资源才能被唤醒(资源比如硬盘读 ),不响应任何signal唤醒。kill -9 也杀不掉
浅睡眠: 资源来了醒,浅睡眠还可以被signal唤醒
深睡眠不响应任何信号的kill -9 都杀不掉。kill -l 查看signal (信号类型就是针对一个进程的异步打断机制)
思考:为什么会有深睡眠。
停止态: 人为停止(类似于作业控制ctrl+z--job control bg/fg(继续), gdb attach debug)
cpulimit : 利用了停止态,限制pid 使用CPU利用率。cpulimit -l 百分比 -p pid
僵尸态:就是进程已经死了,资源已经释放。 非常短的临界状态,task_struct还在,等待父进程 wait4(api接口) 结束僵尸 进程。如果父进程不用wait清理,那僵尸进程永远在。清理僵尸进 程(只有父进程也杀掉,僵尸进程也会没有)。
内存泄露: 不是进程死了,内存没有释放,而是进程活着,运行越久,内存消耗越来越多。
进程运行正常状态: 围绕一根均线,震荡收敛,有起有伏的。
怎样观察内存是否泄漏: 多点采样法(8-20点,每小时采样),内存用的越来越多,必定有内存泄露。
fork :
n.餐叉; 叉(挖掘用的园艺工具); (道路、河流等的) 分岔处,分流处,岔口,岔路;
v.分岔; 岔开两条分支; 走岔路中的一条; 叉运; 叉掘;
fork()函数的返回值是返回两次的,在父进程中返回子进程的pid,在子进程中返回0
第一个fork()会生出2个进程 ,第二次fork()会生出四个进程,所以一共打印6次
p1是个task_struct p2也是个task_struct
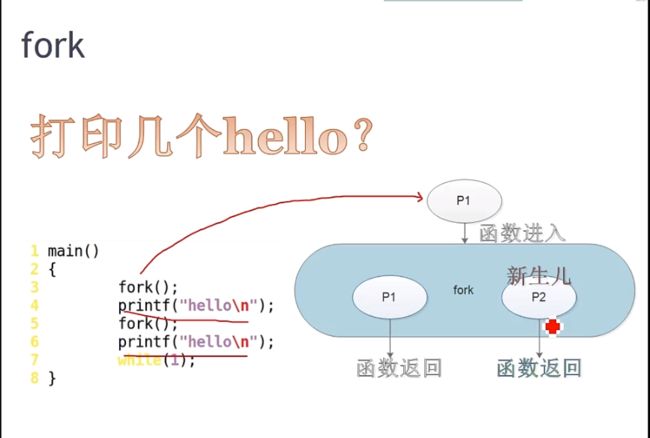
示例:打印了几次hello
main () {
fork(); printf("hello\n") ; fork() ; printf("hello\n") ;while(1);
}
fork炸弹 : :(){:|:&};:
原理就是定义一个函数,并不断递归,不停地制造后台任务。如你所见那个函数名就是个冒号,其实这完全就是在 扰乱你的视线。【话说回来好像bash里好像也有一个啥事都不干的冒号命令】
写的易懂点:
func () { #函数定义,这里把函数名改成了func}
这是bash shell的写法,首先定义了一个函数:(),花括号里面是函数体,这里递归执行函数本身,通过管道在后台再递 归运行一次本程序,最后的冒号就是立刻执行当前这个函数。这样一直运行下去,直到系统崩溃,这就是fork炸弹
Copy on Write COW技术 写入时复制 MMU= memory management unit 内存管理单元
page fault :缺页中断 RD-only 才会发生
fork()
vfork(): 父进程阻塞直到子进程 exit / exec
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。
注意:虚拟内存不只是「用磁盘空间来扩展物理内存」的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现。对虚拟内存的定义是基于对地址空间的重定义的,即把地址空间定义为「连续的虚拟内存地址」,以借此「欺骗」程序,使它们以为自己正在使用一大块的「连续」地址。
进程与虚拟地址
32位系统下每个进程都会分配4G的虚拟内存空间,而其实所有进程都共享着同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址。
这时我们需要一个东西它就是MMU(内存管理单元),它的主要作用就是完成地址的映射,也就是页表的建立、映射过程。页表就是用来记录进程中哪些内存地址上的数据在物理内存上以及它们所在的位置的一个结构。每个进程都有一个页表,当进程需要访问某个虚拟地址时,就会去访问页表,页表实现从页号到物理块号的地址映射。
引用 https://github.com/21cnbao/process-courses
# 打通Linux脉络系列:进程、线程和调度
* 第一部分深入彻底地搞清楚进程生命周期,进程生命周期创建、退出、停止,以及僵尸是个什么意思;
* 第二部分,深入分析进程创建的写时拷贝技术、以及Linux的线程究竟是怎么回事(为什么称为轻量级进程),此部分也会搞清楚进程0、进程1和托孤,以及睡眠时的等待队列;
* 第三部分,搞清楚Linux进程调度算法,不同的调度策略、实时性,完全公平调度算法;
* 第四部分,讲解Linux多核下CPU、中断、软负载均衡,cgroups调度算法以及Linux为什么不是一个实时操作系统。
# 第一部分大纲
* Linux进程生命周期(就绪、运行、睡眠、停止、僵死)
* 僵尸是个什么鬼?
* 停止状态与作业控制,cpulimit
* 内存泄漏的真实含义
* task_struct以及task_struct之间的关系
* 初见fork和僵尸
## 练习题
* fork的例子
* life-period例子,观察僵尸
* 用cpulimit控制CPU利用率
# 第二部分大纲
* fork、vfork、clone
* 写时拷贝技术
* Linux线程的实现本质
* 进程0和进程1 : 进程1(init) 是由进程0 生成的
进程0 把其它进程fork出来后 变成 IDLE进程,IDLE进程等所有进程都停止或睡眠了,就去调用进程0 。WFI --等中断状态 (类似省电模式)
/proc/1 : cat status
/proc/PID
/proc/PID/task 线程 PID

* 进程的睡眠和等待队列
等待队列 wait_queue:
睡眠是内核自己把资源

停止: 别人打晕的
睡眠:是自己睡得
深度睡眠: linux 发现你要系统调用 ,读写,要io 等资源 ,资源不来 就不醒
非阻塞O_NONBLOCK与O_NDELAY的区别 O_NONBLOCK就产生出来,它在读取不到数据时会回传-1,并且设置errno为EAGAIN。还是推荐POSIX规定的O_NONBLOCK,O_NONBLOCK可以在open和fcntl时设置。阻塞操作是指,在执行设备操作时,若不能获得资源,则进程挂起直到满足可操作的条件再进行操作。非阻塞操作的进程在不能进行设备操作时,并不挂起。被挂起的进程进入sleep状态,被从调度器的运行队列移走,直到等待的条件被满足。
在Linux驱动程序中,我们可以使用等待队列(wait queue)来实现阻塞操作。wait queue很早就作为一个基本的功能单位出现在Linux内核里了,它以队列为基础数据结构,与进程调度机制紧密结合,能够用于实现核心的异步事件通知机制。等待队列可以用来同步对系统资源的访问,上节中所讲述Linux信号量在内核中也是由等待队列来实现的。
sechedule task_interruptible
select / poll epoll https://blog.csdn.net/zxm342698145/article/details/80524331
附加 : 怎么样理解 page fault ?
https://www.jianshu.com/p/f9b8c139c2ed
* 孤儿进程的托孤,SUBREAPER
fork () 与 vfork()
vfork 共用mm struct
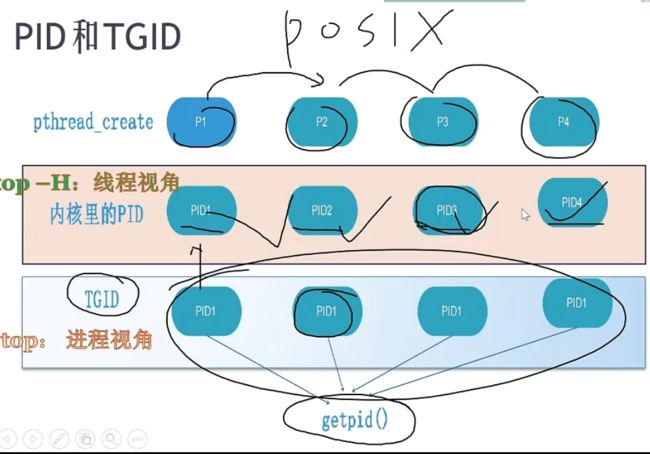
linux 通过 pthread_create (创建线程的API)创建线程 ,调用的就是clone (把所有的资源都clone一份,p2的所有指针都指向p1) linux 就是用这样的方法来实现线程的。所以在linux 中为什么线程也叫轻量级进程(LWP)的原因。
思考: Linux实现进程和线程 ,如果克隆一部分task_struct 那是什么(线程有了进程的心,)

TGID :thread group id。对于同一进程中的所有线程,tgid都是一致的,为该进程的进程ID。
Top 命令看到的就是 TGID
Top -H 看到的是线程ID
进程的托孤: 白发人送黑发人

父进程死,子进程变成孤儿
subreaper : 收割机 (火葬场)
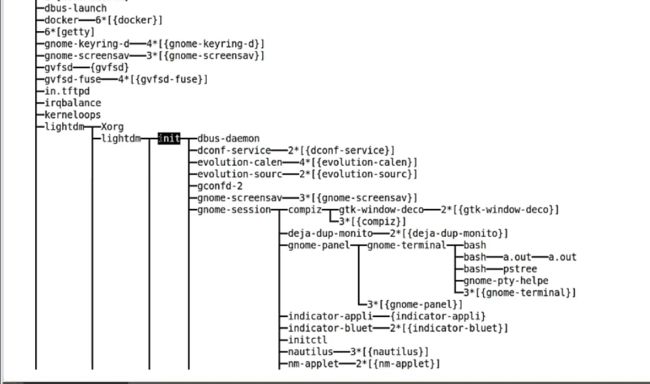
图中的init 就是个收割机
## 练习题
* fork、vfork、Copy-on-Write例子
* life-period例子,实验体会托孤
* pthread_create例子,strace它
* 彻底看懂等待队列的案例
# 第三部分大纲
调度器算法
* CPU/IO消耗型进程 https://www.cnblogs.com/beMaster/p/5380037.html
多任务操作系统分为非抢占式多任务操作系统和抢占式多任务操作系统,现代的操作系统都是抢占式多任务操作系统。
除了虚拟处理器的机制外,进程控制块(PCB)也是使得操作系统能够并发的关键。因为在进程切换时,进程控制块能够保存当前处理器的上下文,使得该进程下次被调度时,能够从上次停止的地方继续运行。
喜欢睡觉就是io消耗,喜欢干活就是cpu消耗
cpu利用率大概还是由程序本身 (一会sleep 一会儿for循环)来定, 调度算法是大家都ready的时候要占用cpu的时候(谁是优先的) 一般情况基本就是nice值是0 的普通线程
RT: runtime
cpu消耗: 都花费在cpu
该类进程在把时间都发在了执行代码上,即在该进程执行期间,马不停蹄的使用处理器资源。所以除非被抢占,否则它们通常都一直不停地运行,因此从系统响应速度考虑,调度器不应该经常让它们运行。该类进程优先级低,时间边短。
io消耗 : 都花费在io 通常伴随用户体验
而优先调度该类进程是为了让该类进程是为了尽可能地消耗其所需要的处理器资源,从而让该进程阻塞住,这样只要用户一完成I/O操作,该进程就会被唤醒,从而立刻处理I/O操作,那么在用户看来,该进程响应非常快,体现出了很好的用户友好性。
* 吞吐率 vs. 响应 : 有一定的矛盾, 响应和吞吐之间倾向哪一边,另外一边肯定会受到影响
上下文切换: 例如程序的切换
吞吐 : 有用功
响应 : 哪怕牺牲其它任务 ,也要快速响应
* SCHED_FIFO、SCHED_RR
* SCHED_NORMAL和CFS
* nice、renice
* chrt
进程是资源的封装,nice是对于线程的设置
## 练习题
* 运行2个高CPU利用率程序,调整他们的nice
* 用chrt把一个死循环程序调整为SCHED_FIFO
* 阅读ARM的big.LITTLE架构资料,并论述为什么ARM要这么做?
# 第四部分大纲
调度算法:FIFO RR NORMAL(CFS通过分子ptime 来均衡)
Linux 多核是个类似分布式系统的概念:在每个核心之间跳动
多核是每个核心劳动最高兴: 核与核之间 push_rt_task() 和 pull_rt_task() ,拉取的是task_struct
软中断负载均衡 RPS
* 多核下负载均衡
* 中断负载均衡、RPS软中断负载均衡
* cgroups和CPU资源分群分配
* Android和NEON对cgroups的采用
* Linux为什么不是硬实时的
* preempt-rt对Linux实时性的改造
## 练习题
* 用time命令跑1个含有2个死循环线程的进程
* 用taskset调整多线程依附的CPU
* 创建和分群CPU的cgroup,调整权重和quota
* cyclictest
3. 进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,需要用页表来记录
4.页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
5. 当进程访问某个虚拟地址,去看页表,如果发现对应的数据不在物理内存中,则缺页异常
6.缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果内存已经满了,没有空地方了,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,需要将此页写回磁盘
————————————————
版权声明:本文为CSDN博主「Rotation.」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fengxinlinux/article/details/52071766