如何使用 Yolo v5 对象检测算法进行自定义对象检测
介绍
在本文中,将向你解释如何使用 Yolo v5 算法检测和分类60+个不同类型的道路交通标志。
我们将从非常基础的开始,涵盖每个步骤,如准备数据集、训练和测试等。在本文中,我们将使用 Windows 10系统。
让我们更多地讨论 YOLO 及其架构。
YOLO 是You Only Look Once的首字母缩写。我们使用的是Ultralytics于2020年6月推出的版本 5,它是目前可用的最先进的目标识别算法。
YOLOv5 是一种新颖的卷积神经网络(CNN),可以非常准确地实时检测对象。这种方法使用单个神经网络来处理整个图片,然后将其分成多个部分并预测每个部分的边界框和概率。这些边界框由预期概率加权。
该方法“只看一次”图像,因为它仅在一次前向传播通过神经网络后进行预测。然后在非最大抑制之后传递检测到的项目(这确保对象检测算法只识别每个对象一次)。
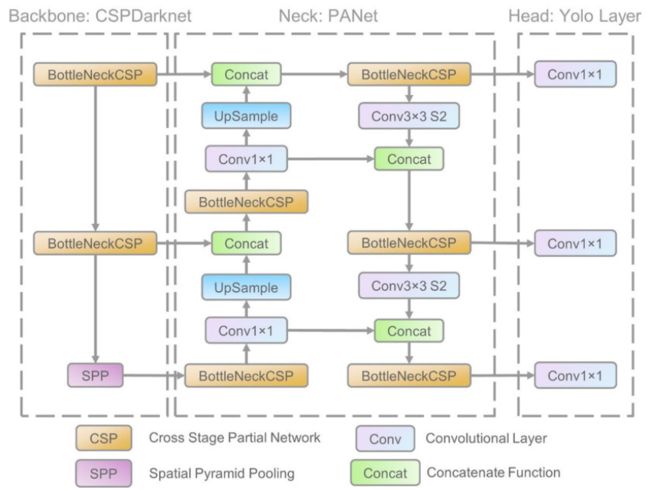
它的架构主要由三部分组成,即:
1. Backbone: Backbone 主要用于从输入图像中提取关键特征。CSP(Cross Stage Partial Networks)在 YOLO v5 中用作主干,以从输入图像中提取丰富的有用特征。
2. Neck: Neck 主要用于创建特征金字塔。当涉及到对象缩放时,特征金字塔有助于模型泛化。它有助于识别不同大小和比例的同一物体。
特征金字塔在帮助模型有效地处理之前看不见的数据方面是非常有益的。其他模型,如FPN、BiFPN和PANet,使用各种各样的特征金字塔方法。
PANet 在 YOLO v5 中用作 Neck 来获取特征金字塔。
3. Head: 模型Head主要负责最后的检测步骤。它使用锚框来构建具有类别概率、对象性分数和边界框的最终输出向量。
YOLO v5 模型的头部与之前的 YOLO V3 和 V4 版本相同。
Yolo v5 的优缺点
它比 YOLOv4 小 88%(27 MB vs 244 MB)
它比 YOLOv4 快 180%(140 FPS vs 50 FPS)
它在同一任务上大致与 YOLOv4 一样准确(0.895 mAP vs 0.892 mAP)
但主要的问题是YOLOv5没有像其他YOLO版本一样发布官方论文。此外,YOLO v5 仍在开发中,我们会经常收到Ultralytics 的更新,未来开发者可能会更新一些设置。
目录
在 Windows 10 中设置虚拟环境。
克隆 Yolo v5 的 GitHub 仓库。
数据集的准备和预处理。
训练模型。
预测和现场测试。
创建虚拟环境
我们将首先通过在 Windows 命令提示符中运行该命令来设置虚拟环境
1.安装Virtualenv(运行以下命令安装虚拟环境)
$ pip install virtualenv2.创建环境(运行以下命令创建虚拟环境)
$ py -m venv YoloV5_VirEnv3.使用该命令激活它(运行以下命令以激活该环境)
$ YoloV5_VirEnvScriptsactivate你也可以使用停用它(如果要停用该环境,请运行以下命令)
$ deactivate设置 YOLO
激活虚拟环境后,克隆这个由Ultralytics创建和维护的 GitHub 存储库:https://github.com/ultralytics/yolov5
$ git clone https://github.com/ultralytics/yolov5$ cd yolov5目录结构
yolov5/
.github/
data/
models/
utils/
.dockerignore
.gitattributes
.gitignore
.pre-commit-config.yaml
CONTRIBUTING.md
detect.py
Dockerfile
export.py
hubconf.py
LICENSE
README.md
requirements.txt
setup.cfg
train.py
tutorial.ipynb
val.py
安装必要的库:首先,我们将安装做图像处理所需的所有必要的库(OpenCV &Pillow),图像分类 (Tensorflow&PyTorch) , 进行矩阵操作(Numpy)
$ pip install -r requirements.txt数据集的准备
从该链接下载完整的标记数据集:https://drive.google.com/file/d/1gQD1OovQDyjMlUEWl6IEn2mzgS6KNppX/view?usp=sharing
然后解压 zip 文件并将其移动到 yolov5/ 目录。
1144images_dataset/
train/
test/
在yolov5/目录中创建一个名为 data.yaml 的文件 ,并将以下代码粘贴到其中。
该文件将包含你的标签以及训练和测试数据集的路径。
train: 1144images_dataset/train
val: 1144images_dataset/test
nc: 77
names: ['200m',
'50-100m',
'Ahead-Left',
'Ahead-Right',
'Axle-load-limit',
'Barrier Ahead',
'Bullock Cart Prohibited',
'Cart Prohobited',
'Cattle',
'Compulsory Ahead',
'Compulsory Keep Left',
'Compulsory Left Turn',
'Compulsory Right Turn',
'Cross Road',
'Cycle Crossing',
'Compulsory Cycle Track',
'Cycle Prohibited',
'Dangerous Dip',
'Falling Rocks',
'Ferry',
'Gap in median',
'Give way',
'Hand cart prohibited',
'Height limit',
'Horn prohibited',
'Humpy Road',
'Left hair pin bend',
'Left hand curve',
'Left Reverse Bend',
'Left turn prohibited',
'Length limit',
'Load limit 5T',
'Loose Gravel',
'Major road ahead',
'Men at work',
'Motor vehicles prohibited',
'Nrrow bridge',
'Narrow road ahead',
'Straight prohibited',
'No parking',
'No stoping',
'One way sign',
'Overtaking prohibited',
'Pedestrian crossing',
'Pedestrian prohibited',
'Restriction ends sign',
'Right hair pin bend',
'Right hand curve',
'Right Reverse Bend',
'Right turn prohibited',
'Road wideness ahead',
'Roundabout',
'School ahead',
'Side road left',
'Side road right',
'Slippery road',
'Compulsory sound horn',
'Speed limit',
'Staggred intersection',
'Steep ascent',
'Steep descent',
'Stop',
'Tonga prohibited',
'Truck prohibited',
'Compulsory turn left ahead',
'Compulsory right turn ahead',
'T-intersection',
'U-turn prohibited',
'Vehicle prohibited in both directions',
'Width limit',
'Y-intersection',
'Sign_C',
'Sign_T',
'Sign_S',
'No entry',
'Compulsory Keep Right',
'Parking',
]我们将使用总共 77 个不同的类
使用 Yolo v5 训练模型
现在,运行该命令以最终训练你的数据集。你可以根据 PC 的规格更改批次大小。训练时间将取决于你电脑的性能,最好使用 Google Colab。
你还可以训练不同版本的 YOLOv5 算法,可以在这里找到:https://blog.roboflow.com/yolov5-improvements-and-evaluation
所有这些都将采用不同的计算能力,并提供 FPS(每秒帧数)和精度的不同组合。
在本文中,我们将使用YOLOv5s版本,因为它是最简单的。
$ python train.py --data data.yaml --cfg yolov5s.yaml --batch-size 8 --name Model现在内部运行 runs/train/Model/,你将找到最终训练好的模型。
runs/train/Model/
weights/
best.pt
last.pt
227359 events.out.tfevents.1638984167.LAPTOP-7CJ5UG09.6292.0
hyp.yaml
opt.yaml
results.txt
results.png
train_batch0.jpg
train_batch1.jpg
train_batch2.jpgbest.pt 包含用于最终检测和分类的最终模型。
results.txt 文件将包含你在每个时期实现的准确度和损失的摘要。
其他图像包含一些绘图和图表,可用于更多分析。
Model Yolo v5 的测试
将你的 yolov5/目录移到别处,并克隆那个存储库。
这个repo将包含测试模型的代码:https://github.com/aryan0141/RealTime_Detection-And-Classification-of-TrafficSigns
$ git clone https://github.com/aryan0141/RealTime_Detection-And-Classification-of-TrafficSigns$ cd RealTime_Detection-And-Classification-of-TrafficSigns目录结构
RealTime_Detection-And-Classification-of-TrafficSigns/
Codes
Model
Results
Sample Dataset
Test
classes.txt
Documentation.pdf
README.md
requirements.txt
vidd1.mp4现在复制我们在上面训练的模型并将其粘贴到此目录中。
注意:我已经在Model/目录中包含了一个经过训练的模型,但你也可以将其替换为经过训练的模型。
移动到代码所在的目录中。
$ cd Codes/将你的视频或图像放在**Test/**目录中。我还提供了一些示例视频和图像供你参考。
用于测试图像
$ python detect.py --source ../Test/test1.jpeg --weights ../Model/weights/best.pt用于测试视频
$ python detect.py --source ../Test/vidd1.mp4 --weights ../Model/weights/best.pt对于网络摄像头
$ python detect.py --source 0 --weights ../Model/weights/best.pt你的最终图像和视频存储在Results/目录中。
示例图像
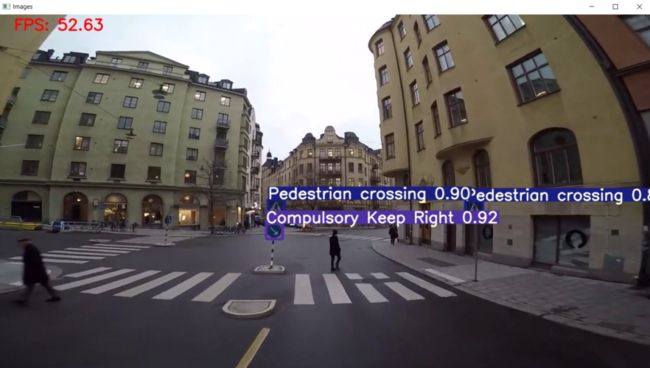
每秒帧数(FPS)取决于你使用的 GPU。我在 Nvidia MX 350 2GB 显卡上获得了大约 50FPS。
GitHub
这是 Github, 可以找到本文中使用的完整代码。
https://github.com/aryan0141/RealTime_Detection-And-Classification-of-TrafficSigns
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
