一、架构
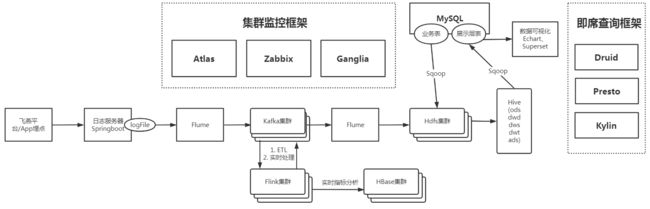
二、框架部署
2.1 准备
准备三台虚拟机,操作系统为CentOS 7.x,每台内存至少8G以上。
步骤:
- 关闭防火墙
- 创建hxr用户,设置密码,创建文件夹更改用户为hxr
- 配置ssh免密登录
- 安装jdk,设置环境变量
- 选择上海时间,并通过ntp同步互联网时间,通过crontab指令同步集群服务器时间
2.1.1 关闭防火墙
关闭防火墙并停止开机自启(CentOS7)
firewall-cmd --state # 查看防火墙状态
systemctl start firewalld # 开启防火墙
systemctl stop firewalld # 关闭防火墙
systemctl disable firewalld # 禁止防火墙开机启动
systemctl enable firewalld # 设置防火墙开机启动
2.1.2 创建hxr用户
创建新用户hxr
useradd hxr
设置密码
passwd hxr
设置用户权限
在/etc/sudoers文件中添加 hxr ALL=(ALL) NOPASSWD:ALL
表示该用户或组执行来自任何计算机的所有用户和所有组的命令都不需要密码。
执行visudo -c检查文件是否正常
创建文件夹用于框架安装
mkdir -p /opt/module /opt/software # 在/opt 目录下创建两个文件夹module和software
chown hxr:hxr /opt/module /opt/software #并将所有权给hxr
2.1.3 配置ssh免密登录
登录到hxr用户,配置免密登陆。
- 生成密钥对
ssh-keygen -t rsa
- 发送公钥到本机
将公钥发送到user@host上,即可免密登陆该host节点。该命令会将公钥写到指定节点host的.ssh/authorized_keys文件中,拥有该文件中的公钥对应私钥的节点都允许远程登录。
ssh-copy-id bigdata1
- 分别ssh登陆一下所有虚拟机
ssh bigdata2
ssh bigdata3
- 把/home/hxr/.ssh 文件夹发送到集群所有服务器
xsyncmy /home/hxr/.ssh
需要创建自定义xsyncmy脚本:见 [第四章 4.5 shell脚本],在/usr/bin目录下创建脚本。
2.1.4 安装jdk,设置环境变量
将JDK的安装包放入到/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf [安装包] -C [目标路径]
在/etc/profile.d文件夹中添加脚本env.sh (好处就是shell登录和ssh登录都会加载该环境变量)
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
2.1.5 节点间时间同步
选择上海时间,并通过ntp同步互联网时间,通过crontab指令同步集群服务器时间。
时间服务器配置
- 安装ntp
yum –y install ntp
-
修改ntp配置文件 vim /etc/ntp.conf
-
修改1(授权192.168.1.0-192.168.32.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 127.0.0.1 # 注销语句 restrict 192.168.32.0 mask 255.255.255.0 nomodify notrap # 添加语句 -
修改2(集群在局域网中,不使用其他互联网上的时间)
#server 0.centos.pool.ntp.org iburst # 注销语句 #server 1.centos.pool.ntp.org iburst # 注销语句 #server 2.centos.pool.ntp.org iburst # 注销语句 #server 3.centos.pool.ntp.org iburst # 注销语句 -
添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
#将本机作为时钟源 server 127.127.1.0 # 添加语句 fudge 127.127.1.0 stratum 10# 添加语句
-
-
修改ntpd配置文件 vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
# 让硬件时间与系统时间一起同步 SYNC_HWCLOCK=yes
-
启动ntpd服务
systemctl enable ntpd systemctl restart ntpd
- 选择Shanghai时区作为节点时区
如果在/usr/share/zoneinfo/这个目录下不存在时区配置文件Asia/Shanghai,就要用 tzselect 生成。
tzselect
拷贝该时区文件,覆盖系统本地时区配置
rm /etc/localtime
ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
其他节点配置
安装组件
sudo yum install -y ntpdate
在其他机器配置10分钟与时间服务器同步一次
crontab -e
输入如下文本后保存(设置每10秒同步一次)
*/10 * * * * /usr/sbin/ntpdate bigdata1
为了验证时间同步是否生效,可以设置
date -s "2008-8-8 8:8:8"
修改时间,date观察时间是否同步。
2.2 核心框架
| Bigdata1 | Bigdata2 | Bigdata3 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | DataNode SecondaryNameNode |
| Yarn | NodeManager | Resourcemanager NodeManager |
NodeManager |
| Zookeeper | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| Flume | Application | Application | |
| Kafka | Kafka | Kafka | Kafka |
| Hive | RunJar RunJar |
||
| Sqoop | Sqoop | ||
| Azkaban | AzkabanExecutorServer AzkabanWebServer |
||
| Hbase | HMaster HRegionServer |
HRegionServer | HRegionServer |
| Flink | YarnSessionClusterEntrypoint YarnTaskExecutorRunner |
FlinkYarnSessionCli YarnTaskExecutorRunner |
YarnTaskExecutorRunner |
| Clickhouse | |||
| Atlas | Atlas | ||
| Ganglia | ganglia | ||
| Zabbix | zabbix-server zabbix-agent |
zabbix-agent | zabbix-agent |
| Solr | jar | jar | jar |
| MySQL | MySQL | ||
| Spark-session | YarnCoarseGrainedExecutorBackend | YarnCoarseGrainedExecutorBackend | YarnCoarseGrainedExecutorBackend |
2.2.1 Hadoop 2.7.2
安装应用
将hadoop-2.7.2.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf hadoop-2.7.2.tar.gz -C /opt/module/
重命名解压后的文件为hadoop-2.7.2
定义环境变量
修改/etc/profile.d/env.sh文件
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#设置pid的存储路径,避免tmp清理时将pid删除,导致集群关闭脚本失效。
export HADOOP_PID_DIR=${HADOOP_HOME}/pids
配置文件
在bigdata1节点上的 /opt/module/hadoop-2.7.2/etc/hadoop 路径下修改如下配置文件
-
core-site.xml 添加如下配置
fs.defaultFS hdfs://bigdata1:9000 hadoop.tmp.dir /opt/module/hadoop-2.7.2/data/tmp -
hdfs-site.xml 添加如下配置
dfs.replication 3 dfs.namenode.secondary.http-address bigdata3:50090 -
yarn-site.xml 添加如下配置
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname bigdata2 yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 604800 -
mapred-site.xml 添加如下配置
mapreduce.framework.name yarn mapreduce.jobhistory.address bigdata3:10020 mapreduce.jobhistory.webapp.address bigdata3:19888 -
hadoop-env.sh 修改如下配置
export JAVA_HOME=${JAVA_HOME} -
yarn-env.sh 修改如下配置
export JAVA_HOME=${JAVA_HOME} -
mapred-env.sh 修改如下配置
export JAVA_HOME=${JAVA_HOME} -
slaves 添加如下配置
bigdata1 bigdata2 bigdata3注:需要注意不能出现空行,否则集群启动会有问题
分发Hadoop到其他节点
xsyncmy /opt/module/hadoop-2.7.2
启动集群
在bigdata1节点上格式化NameNode
bin/hdfs namenode –format
在bigdata1节点上启动hdfs
sbin/start-dfs.sh
在bigdata2节点上启动yarn
sbin/start-yarn.sh
在bigdata3节点上启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
对hadoop集群的操作:
start-dfs.sh stop-dfs.sh 打开和关闭dfs
start-yarn.sh stop-yarn.sh 打开和关闭yarn
hadoop-deamon.sh start或stop namenode或datanode 在本机上操作后台进程
yarn-deamon.sh start或stop resourcemanager或nodemanager 在本机上操作进程
hadoop-deamons.sh start或stop namenode或datanode 在集群上操作后台进程
yarn-deamons.sh start或stop resourcemanager或nodemanager 在集群上操作进程
正常情况下各节点进程如下
- bigdata1:
NameNode
NodeManager
DataNode - bigdata2:
ResourceManager
NodeManager
DataNode - bigdata3:
Secondary NameNode
NodeManager
DataNode
JobHistoryServer
如果出现问题,先停止所有hadoop进程
sbin/stop-dfs.sh
sbin/stop-yarn.sh
对集群进行格式化
rm –rf /opt/module/hadoop-2.7.2/data /opt/module/hadoop-2.7.2/logs # 删除数据和日志文件
bin/hdfs namenode -format # 格式化集群
检查配置文件等有无错误,找到并修复问题后重启集群。
验证集群是否正常工作
在/opt/module/hadoop-2.7.2目录下执行如下命令
hadoop fs –put README.txt / # 将需要进行处理的文件上传到集群中
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /README.txt /output # 调用hadoop自带的wordcount程序对文件中的单词进行wordcount
hadoop fs –get /output /opt/module/hadoop-2.7.2 # 从集群中下载输出的文件
查看下载下来的输出文件是否正常,正常则集群可以正常工作。
Web界面
bigdata1:50070 hdfs页面
bigdata2:8088 yarn页面
bigdata3:19888 历史服务器页面
hadoop的最终配置文件
core-site.xml
fs.defaultFS
hdfs://bigdata1:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
io.compression.codecs.lzo.class
com.hadoop.compression.lzo.LzoCodec
hadoop.proxyuser.hxr.groups
*
hadoop.proxyuser.hxr.hosts
*
hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
bigdata3:50090
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
bigdata3:10020
mapreduce.jobhistory.webapp.address
bigdata3:19888
mapreduce.map.memory.mb
1536
mapreduce.map.java.opts
-Xmx1024M
mapreduce.reduce.memory.mb
3072
mapreduce.reduce.java.opts
-Xmx2560M
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
bigdata2
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.pmem-check-enabled
false
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true
yarn.log-aggregation-enable
true
yarn.log.server.url
http://bigdata3:19888/jobhistory/logs
2.2.2 Zookeeper 3.4.10
安装应用
将zookeeper-3.4.10.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
重命名解压后的文件为zookeeper-3.4.10
配置文件
-
重命名/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv /opt/module/zookeeper-3.4.10/conf/zoo_sample.cfg /opt/module/zookeeper-3.4.10/conf/zoo.cfg-
修改文件中的dataDir路径
dataDir=/opt/module/zookeeper-3.4.10/zkData -
新增如下
server.1=bigdata1:2888:3888 server.2=bigdata2:2888:3888 server.3=bigdata3:2888:3888server.2是id号,只要不重复就可以。
-
-
在 /opt/module/zookeeper-3.4.10/ 目录下创建zkData,在/opt/module/zookeeper-3.4.10/zkData目录下创建myid的文件,将本机的server号写入
1 日志输出位置
在bin/zkEnv.sh中的开头添加一行
ZOO_LOG_DIR=/opt/module/zookeeper-3.4.10/logs
分发Zookeeper到其他节点
xsyncmy /opt/module/zookeeper-3.4.10
注意:需要修改其他节点的/opt/module/zookeeper-3.4.10/zkData/myid文件,为每个节点分配不同的server号(对应server.1/server.2/server.3)。
启动集群
在每个节点上启动zookeeper进程
bin/zkServer.sh start
检查每个节点的状态
bin/zkServer.sh start
关闭节点的zookeeper进程
bin/zkServer.sh stop
2.2.3 Flume 1.7.0
安装应用
将apache-flume-1.7.0-bin.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
重命名解压后的文件为flume-1.7.0
配置文件
-
修改flume-1.7.0/conf中的flume-env.sh文件
export JAVA_HOME=${JAVA_HOME} export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"-Xms和-Xmx推荐设置为一样大小,避免内存抖动。
-
conf中的log4j.properties配置文件。
flume.log.dir=/opt/module/flume-1.7.0/logs # 指定输出日志位置log4j.root.logger指定了输出模式,将flume.root.logger改了也就改了输出模式。默认输出到log4j文件中,可以在配置文件中改为输出到console中(INFO,console)。也可以在命令中加上-D参数,将输出目的地改为控制台(-Dflume.root.logger=INFO,console)。
任务文件
针对不同的业务逻辑需要配置不同的文件。在启动时作为需要作为配置参数传入内存。
例:创建/opt/module/flume-1.7.0/job/file-kafka-hdfs.conf文件
# agent
a1.sources = r1
a1.channels = c1 c2
#source
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1 c2
a1.sources.r1.positionFile = /opt/module/flume-1.7.0/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/q6/.*log
a1.sources.r1.fileHeader = false
a1.sources.r1.maxBatchCount = 1000
#设置拦截器
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.hxr.flume.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.hxr.flume.LogTypeInterceptor$Builder
#设置选择器
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.Log_Q6 = c1
a1.sources.r1.selector.mapping.Log_E5 = c2
#channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = BigData1:9092,BigData2:9092,BigData3:9092
a1.channels.c1.kafka.topic = Log_Q6
a1.channels.c1.parseAsFlumeEvent = false
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = BigData1:9092,BigData2:9092,BigData3:9092
a1.channels.c2.kafka.topic = Log_E5
a1.channels.c2.parseAsFlumeEvent = false
#sink
a1.sinks = k1 k2
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /origin_data/device_model_log/logs/q6/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = q6-
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k2.type = hdfs
a1.sinks.k2.channel = c2
a1.sinks.k2.hdfs.path = /origin_data/device_model_log/logs/e5/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = e5-
a1.sinks.k2.hdfs.rollInterval = 3600
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
a1.sinks.k2.hdfs.useLocalTimeStamp = true
#压缩格式
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.codeC = lzop
a1.sinks.k2.hdfs.fileType = CompressedStream
#拼装
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
单点启动
/opt/module/flume-1.7.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.7.0/conf -f /opt/module/flume-1.7.0/job/file-kafka-hdfs.conf
参数解释
-n:任务名称
-c:指定配置文件
-f:指定任务文件
2.2.4 Kafka 2.11
安装应用
将kafka_2.11-0.11.0.2.tgz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf kafka_2.11-0.11.0.2.tgz -C /opt/module/
重命名解压后的文件为kafka-2.11
配置文件
修改kafka-2.11/config/server.properties文件
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true #是否真正删除topic
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka-2.11/logs
#配置连接Zookeeper集群地址
zookeeper.connect=bigdata1:2181,bigdata2:2181,bigdata3:2181 #所有的kafka相关节点 都会存储在zookeeper的根目录下,可以在后面加上节点名称,将所有节点存储在该节点下。
真正删除topic
找到要删除的topic,执行命令:rmr /brokers/topics/【topic name】即可,此时topic被彻底删除。被标记为marked for deletion的topic可以在zookeeper客户端中通过命令获得:ls /admin/delete_topics/【topic name】,如果你删除了此处的topic,那么marked for deletion 标记消失。
分发Kafka到其他节点
xsyncmy /opt/module/kafka-2.11
注意:需要修改其他节点的/opt/module/kafka-2.11/config/server.properties文件中的broker.id名,不能重复。
压测
写入消息
./kafka-producer-perf-test.sh --topic test --num-records 1000000 --record-size 1000 --throughput 20000 --producer-props bootstrap.servers=bigdata1:9092
--num-records 总共需要发送的消息数,本例为1000000
--record-size 每个记录的字节数,本例为1000
--throughput 每秒钟发送的记录数,本例为20000
消费消息
bin/kafka-consumer-perf-test.sh --zookeeper bigdata1:2181 --topic test --fetch-size 1048576 --messages 1000000 --threads 1
--fetch-size 指定每次fetch的数据的大小,本例为1048576,也就是1M
--messages 总共要消费的消息个数,本例为1000000,100w
启动集群
bin/kafka-server-start.sh -daemon config/server.properties
bin/kafka-server-stop.sh
常用命令
对topic的增删改查
-
查看所有的topic
bin/kafka-topics.sh --zookeeper bigdata1:2181 --list -
创建一个名为first,分区数为3,副本数为2的topic
bin/kafka-topics.sh --zookeeper bigdata1:2181 --create --topic first --partitions 3 --replication-factor 2 -
查看名为first的topic的具体参数
bin/kafka-topics.sh --zookeeper bigdata1:2181 --describe --topic first分别表示topic名、分区号、该分区leader所在的brokerid、副本号、副本所在brokerid、可以同步的副本所在的brokerid
 image.png
image.png -
修改分区数或副本数(分区数只能增不能减,副本数可增可减)
bin/kafka-topics.sh --zookeeper bigdata1:2181 --alter --topic first --partitions 5在bigdata1的logs文件夹中可以查看该节点存储的副本文件first-n(n表示分区号)。分区0存储在broker0、1上,分区2存储在broker2、0上,分区3存储在broker0、2上、分区4存储在broker1、0上。综上,bigdata1存储了分区0、2、3、4的副本,与logs中的first副本文件对应。
 image.png
image.png image.png
image.png -
删除topic
bin/kafka-topics.sh --zookeeper bigdata1:2181 --delete --topic first如果在server.properties中将 delete.topic.enable=true,那么删除时就会将原数据删除。否则只会删除zk上的节点,原数据不会删除。
-
生产数据到topic中
bin/kafka-console-producer.sh --broker-list bigdata2:9092,bigdata3:9092 --topic first -
从topic中读取数据
bin/kafka-console-consumer.sh --bootstrap-server bigdata1:9092 --topic first [from-beginning]可以指定消费组的offset,默认是latest
-
展示当前正在消费的消费者组的信息
bin/kafka-consumer-groups.sh --bootstrap-server bigdata1:9092 --list image.png
image.png -
监控某一消费者消费了哪些topic(一个消费者组可以消费多个topic)
bin/kafka-consumer-groups.sh --bootstrap-server hadoop102:9092 --describe --group id image.png
image.png这两个脚本直接从服务器上获取元数据,得到leader的信息;底层也是调用生产者和消费者的api。
不常用命令
-
如新增了节点,需要重新分配分区,将数据均衡。资源消耗很大。
reassign-partitions.sh -
每一个partition的leader的重新选举。
preferred-replica-election.sh将leader分布在不同节点上,缓解压力。一台leader挂了,其他副本会成为leader,可能会在同一个broker有多个leader,原leader上线后变成follower,需要重新选举,将leader的分别变为均匀状态(这两个指令需要json格式的文件指定分配计划)。
2.2.5 Hive 2.3.6
安装应用
-
先在bigdata3上安装MySQL
docker run -d --restart always --name mysql -p 3306:3306 -v /root/docker/mysql/conf:/etc/mysql -v /root/docker/mysql/log:/var/log/mysql -v /root/docker/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=hxr mysql:5.6
-
将apache-hive-2.3.6-bin.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf apache-hive-2.3.6-bin.tar.gz -C /opt/module/重命名解压后的文件为hive-2.3.6。
配置文件
默认配置文件为hive-default.xml,用户自定义配置文件为hive-site.xml
-
配置/opt/module/hive-2.3.6/conf/hive-env.sh文件
# 配置HADOOP_HOME路径 export HADOOP_HOME=${HADOOP_HOME} # 配置HIVE_CONF_DIR路径 export HIVE_CONF_DIR=/opt/module/hive-2.3.6/conf -
新建hive-site.xml
配置hive-site.xml文件javax.jdo.option.ConnectionURL jdbc:mysql://bigdata3:3306/metastore?createDatabaseIfNotExist=true JDBC connect string for a JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName root username to use against metastore database javax.jdo.option.ConnectionPassword hxr password to use against metastore database hive.metastore.warehouse.dir /user/hive/warehouse location of default database for the warehouse(默认default数据库所在hdfs位置) hive.cli.print.header true 显示查询的头信息 hive.cli.print.current.db true 显示当前数据库 hive.metastore.schema.verification false datanucleus.schema.autoCreateAll true hive.metastore.uris thrift://bigdata1:9083
Hive 运行日志信息配置
修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为hive-log4j.properties,修改 log 存放位置hive.log.dir=/opt/module/hive/logs
- beeline远程登陆配置
在hadoop的core-site.xml文件中配置代理用户
hadoop.proxyuser.hxr.groups
*
hadoop.proxyuser.hxr.hosts
*
在hive的hive-site.xml文件中配置远程链接地址端口和账号密码
hive.server2.thrift.bind.host
bigdata1
hive.server2.thrift.port
10000
测试
启动metastore和hiveserver2
nohup ./hive --service metastore &
nohup ./hive --service hiveserver2 &
①本地连接
进入hive客户端
bin/hive
如果成功进入,则hive运行正常。
②beeline远程连接
beeline -u jdbc:hive2://bigdata1:10000 -n hxr
③可以通过DataGrip等数据库管理工具远程连接
连接URL为 jdbc:hive2://192.168.32.242:10000
2.2.6 Sqoop 1.4.6
安装应用
将sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
重命名解压后的文件为sqoop-1.4.6
配置文件
-
重命名sqoop-env-template.sh文件为sqoop-env.sh
mv /opt/module/sqoop-1.4.6/conf/sqoop-env-template.sh /opt/module/sqoop-1.4.6/conf/sqoop-env-template.shsqoop-env.sh修改文件sqoop-env.sh
export HADOOP_COMMON_HOME=${HADOOP_HOME} export HADOOP_MAPRED_HOME=${HADOOP_HOME} # 以下配置可以不写 export HIVE_HOME=/opt/module/hive-2.3.6 export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10 export ZOOCFGDIR=/opt/module/zookeeper-3.4.10/conf export HBASE_HOME=/opt/module/hbase -
拷贝JDBC驱动
将MySQL版本对应的驱动程序解压到/opt/module/sqoop-1.4.6/lib/ 目录下。
tar -zxvf mysql-connector-java-5.1.27.tar.gz # 解压驱动包 cp mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop-1.4.6/lib/ # 复制驱动包
测试
-
通过某一个command来验证sqoop配置是否正确
bin/sqoop help出现一些Warning警告,并伴随着帮助命令的输出。
-
测试Sqoop是否能够成功连接数据库
bin/sqoop list-databases --connect jdbc:mysql://bigdata3:3306/ --username root --password hxr如果打印出mysql中的所有数据库,则运行正常。
需要预先在bigdata3节点上安装完mysql
2.2.7 配置LZO格式压缩
hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。
配置
将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
-
core-site.xml增加配置支持LZO压缩
io.compression.codecs org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec io.compression.codec.lzo.class com.hadoop.compression.lzo.LzoCodec -
同步hadoop-lzo-0.4.20.jar 文件和core-site.xml文件
xsyncmy /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
重启集群
sbin/start-dfs.sh
sbin/start-yarn.sh
测试
查看本地库支持的
hadoop checknative -a
创建索引:LZO压缩文件的可切片特性依赖于其索引,故我们需要手动为LZO压缩文件创建索引。
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer big_file.lzo
测试输出使用lzop进行压缩
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /README.txt /outputlzo
2.2.8 TEZ 0.9.1
安装应用
将apache-tez-0.9.1-bin.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf apache-tez-0.9.1-bin.tar.gz -C /opt/module/
重命名解压后的文件为tez-0.9.1
配置文件
-
需要在hive的hive-env.sh中引入tez的所有jar包。
# Set HADOOP_HOME to point to a specific hadoop install directoryHADOOP_HOME=${HADOOP_HOME} export HADOOP_HOME=$HADOOP_HOME # Hive Configuration Directory can be controlled by: export HIVE_CONF_DIR=$HIVE_HOME/conf # Folder containing extra libraries required for hive compilation/execution can be controlled by: # export HIVE_AUX_JARS_PATH= export TEZ_HOME=/opt/module/tez-0.9.1 export TEZ_JARS="" for jar in `ls $TEZ_HOME | grep jar`;do export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar done for jar in `ls $TEZ_HOME/lib`;do export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar done export HIVE_AUX_JARS_PATH=$HADOOP_HOME/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS -
在hive-site.xml中设置引擎为tez。
hive.execution.engine tez -
在Hive的/opt/module/hive/conf下面创建一个tez-site.xml文件,添加如下内容
tez.lib.uris ${fs.defaultFS}/tez/apache-tez-0.9.1-bin.tar.gz tez.use.cluster.hadoop-libs true tez.history.logging.service.class org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService -
将/opt/module/tez-0.9.1上传到HDFS的/tez路径,使所有的hdfs节点都可以使用tez。
hadoop fs -mkdir /tez hadoop fs -put /opt/software/apache-tez-0.9.1-bin.tar.gz /tez hadoop fs -ls /tez放置的路径需要与tez-site.xml中配置的路径对应
如果是hadoop3.1.3版本,可以下载Tez 0.10.1版本进行配置.
测试
-
启动Hive
nohup hive --service metastore 1>/dev/null 2>&1 & nohup hive --service hiveserver2 1>/dev/null 2>&1 & bin/hive -
创建LZO表
hive (default)> create table student(id int,name string); -
向表中插入数据
hive (default)> insert into student values(1,"zhangsan"); -
查询数据,如果没有报错就表示成功了
hive (default)> select * from student;
优化
运行Tez时检查到用过多内存而被NodeManager杀死进程问题:
Caused by: org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1546781144082_0005 failed 2 times due to AM Container for appattempt_1546781144082_0005_000002 exited with exitCode: -103
For more detailed output, check application tracking page:http://hadoop103:8088/cluster/app/application_1546781144082_0005Then, click on links to logs of each attempt.
Diagnostics: Container [pid=11116,containerID=container_1546781144082_0005_02_000001] is running beyond virtual memory limits. Current usage: 216.3 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.
这种问题是从机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
解决方法:
-
方案一:或者是关掉虚拟内存检查。修改yarn-site.xml,修改后一定要分发,并重新启动hadoop集群。
yarn.nodemanager.vmem-check-enabled false -
方案二:mapred-site.xml中设置Map和Reduce任务的内存配置如下(value中实际配置的内存需要根据自己机器内存大小及应用情况进行修改)
mapreduce.map.memory.mb 1536 mapreduce.map.java.opts -Xmx1024M mapreduce.reduce.memory.mb 3072 mapreduce.reduce.java.opts -Xmx2560M
2.2.9 Azkaban 2.5.0
应用安装
将azkaban-web-server-2.5.0.tar.gz,azkaban-executor-server-2.5.0.tar.gz,azkaban-sql-script-2.5.0.tar.gz 安装包放入bigdata1节点的/opt/software文件夹下;
创建/opt/module/azkaban-2.5.0文件夹;
通过如下命令将安装包解压到/opt/module/azkaban-2.5.0文件夹下
tar –zxvf azkaban-web-server-2.5.0.tar.gz -C /opt/module/azkaban-2.5.0
tar –zxvf azkaban-executor-server-2.5.0.tar.gz -C /opt/module/azkaban-2.5.0
tar –zxvf azkaban-sql-script-2.5.0.tar.gz -C /opt/module/azkaban-2.5.0
重命名解压后的文件夹
mv /opt/module/azkaban-2.5.0/azkaban-web-2.5.0/ /opt/module/azkaban-2.5.0/server
mv /opt/module/azkaban-2.5.0/azkaban-executor-2.5.0/ /opt/module/azkaban-2.5.0/executor
创建数据库
mysql -uroot -phxr
mysql> create database azkaban;
mysql> use azkaban;
mysql> source /opt/module/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql
注:source后跟.sql文件,用于批量处理.sql文件中的sql语句。
生成密钥对和证书
Keytool是java数据证书的管理工具,使用户能够管理自己的公/私钥对及相关证书。
-
生成 keystore的密码及相应信息的密钥库
keytool -keystore keystore -alias jetty -genkey -keyalg RSA-keystore 指定密钥库的名称及位置(产生的各类信息将存在.keystore文件中)
-genkey(或者-genkeypair) 生成密钥对
-alias 为生成的密钥对指定别名,如果没有默认是mykey
-keyalg 指定密钥的算法 RSA/DSA 默认是DSA输入完成后即生成秘钥对,可以通过如下命令查看秘钥库中的秘钥信息,有私钥和证书(存有公钥)。
keytool -keystore keystore -list注意:
密钥库的密码至少必须6个字符,可以是纯数字或者字母或者数字和字母的组合等等
密钥库的密码最好和的密钥相同,方便记忆
-
将keystore 拷贝到 azkaban web服务器根目录中
mv keystore /opt/module/azkaban-2.5.0/server/
配置文件
-
Web服务器配置,修改/opt/module/azkaban-2.5.0/server/conf/azkaban.properties文件
#Azkaban Personalization Settings #服务器UI名称,用于服务器上方显示的名字 azkaban.name=Test #描述 azkaban.label=My Local Azkaban #UI颜色 azkaban.color=#FF3601 azkaban.default.servlet.path=/index #默认web server存放web文件的目录 web.resource.dir=/opt/module/azkaban/server/web/ #默认时区,已改为亚洲/上海 默认为美国 default.timezone.id=Asia/Shanghai #Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类(绝对路径) user.manager.xml.file=/opt/module/azkaban/server/conf/azkaban-users.xml #Loader for projects #global配置文件所在位置(绝对路径) executor.global.properties=/opt/module/azkaban/executor/conf/global.properties azkaban.project.dir=projects #数据库类型 database.type=mysql #端口号 mysql.port=3306 #数据库连接IP mysql.host=bigdata3 #数据库实例名 mysql.database=azkaban #数据库用户名 mysql.user=root #数据库密码 mysql.password=hxr #最大连接数 mysql.numconnections=100 # Velocity dev mode velocity.dev.mode=false # Azkaban Jetty server properties. # Jetty服务器属性. #最大线程数 jetty.maxThreads=25 #Jetty SSL端口 jetty.ssl.port=8443 #Jetty端口 jetty.port=8081 #SSL文件名(绝对路径) jetty.keystore=/opt/module/azkaban/server/keystore #SSL文件密码 jetty.password=000000 #Jetty主密码与keystore文件相同 jetty.keypassword=000000 #SSL文件名(绝对路径) jetty.truststore=/opt/module/azkaban/server/keystore #SSL文件密码 jetty.trustpassword=000000 # Azkaban Executor settings executor.port=12321 # mail settings mail.sender= mail.host= job.failure.email= job.success.email= lockdown.create.projects=false cache.directory=cache -
Web服务器用户配置,修改/opt/module/azkaban-2.5.0/server/conf/azkaban-users.xml 文件,增加管理员用户
-
执行服务器配置,修改/opt/module/azkaban-2.5.0/executor/conf/azkaban.properties
#Azkaban #时区 default.timezone.id=Asia/Shanghai # Azkaban JobTypes Plugins #jobtype 插件所在位置 azkaban.jobtype.plugin.dir=plugins/jobtypes #Loader for projects executor.global.properties=/opt/module/azkaban-2.5.0/executor/conf/global.properties azkaban.project.dir=projects database.type=mysql mysql.port=3306 mysql.host=bigdata3 mysql.database=azkaban mysql.user=root mysql.password=hxr mysql.numconnections=100 # Azkaban Executor settings #最大线程数 executor.maxThreads=50 #端口号(如修改,请与web服务中一致) executor.port=12321 #线程数 executor.flow.threads=30
单点启动
-
启动executor服务器
/opt/module/azkaban-2.5.0/executor/bin/azkaban-executor-start.sh -
启动web服务器
/opt/module/azkaban-2.5.0/server/bin/azkaban-web-start.sh
注意:先执行executor,再执行web,避免Web Server会因为找不到执行器启动失败
Web界面
启动完成后,访问https://bigdata1:8443,即可访问azkaban服务了。
在登录中输入刚才在azkaban-users.xml文件中新添加的户用名及密码,点击 login。
2.2.10 Flink 1.12.0
安装应用
将flink-1.12.0-bin-scala_2.12.tgz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf flink-1.12.0-bin-scala_2.12.tgz -C /opt/module/
重命名解压后的文件为flink-1.12.0
分发Flink到其他节点
xsyncmy /opt/module/flink-1.12.0
启动集群
必须保证hadoop集群正常运行。
-
添加环境变量
export HADOOP_CLASSPATH=`hadoop classpath` -
启动yarn-session
yarn-session.sh -n 2 -s 2 -jm 1024 -nm test -d如果调度器中创建了多个队列,需要指定队列
nohup ./yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm flink-on-yarn -qu flink -d 1>/opt/module/flink-1.12.0/yarn-session.log 2>/opt/module/flink-1.12.0/yarn-session.err &-n(--container):TaskManager的数量(建议不指定,会动态添加,且flink1.10中已经不再支持);
-s(--slots):每个TaskManager的slot数量,默认一个slot一个sore,默认每个taskmanager的slot个数为1,有时可以多一些taskmanager,做冗余;
-jm:JobManager的内存(MB);
-tm:每个taskmanager的内存(MB);
-nm:yarn的appName(yarn的ui上的名字);
-d:后台执行。
-
关闭yarn-session
# 找到flink集群任务的id,然后kill yarn application -kill application_1616059084025_0002
-
提交任务(和standalone模式一样)
bin/flink run -c com.iotmars.wecook.StreamWordCount -p 2 /opt/jar/flink-demo-0.0.1-SNAPSHOT-jar-with-dependencies.jar --host localhost --port 6666- -c 表示类路径
- -p 表示并行度
- 然后加上启动jar路径
- 最后添加参数
注意:如果slot不够,会导致卡死在分配资源阶段导致最后超时失败。
查看任务状态:去yarn控制台查看任务状态
取消yarn-session:yarn application --kill job_id
Web界面
可以通过http://192.168.32.243:37807访问Web页面(每次启动都会变,具体查看/opt/module/flink-1.12.0/yarn-session.log)
2.2.11 HBase 1.3.1
安装应用
将hbase-1.3.1-bin.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf hbase-1.3.1-bin.tar.gz -C /opt/module/
重命名解压后的文件为hbase-1.3.1
配置文件
-
修改conf/hbase-env.sh文件
export JAVA_HOME=/opt/module/jdk1.8.0_144 export HBASE_MANAGES_ZK=false -
修改conf/hbase-site.sh文件
hbase.rootdir hdfs://bigdata1:9000/hbase hbase.cluster.distributed true hbase.master.port 16000 hbase.zookeeper.quorum bigdata1,bigdata2,bigdata3 hbase.zookeeper.property.dataDir /opt/module/zookeeper-3.4.10/zkData
-
修改conf/regionservers文件
bigdata1 bigdata2 bigdata3 -
软连接hadoop配置文件到hbase
ln -s /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml ln -s /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
分发HBase到其他节点
xsyncmy /opt/module/hbase
启动集群
必须保证zk和hadoop集群正常运行。
-
方式一:
bin/hbase-daemon.sh start master bin/hbase-daemon.sh start regionserver -
方式二:
bin/start-hbase.sh bin/stop-hbase.sh
Web界面
http://bigdata1:16010
2.2.12 Clickhouse
见ClickHouse 21.7 基础
2.3 辅助框架
2.3.1 Ganglia
启动应用
需要先将容器中/etc/ganglia/文件夹下的配置文件复制出来,再启动。
docker run -d --name ganglia --net=host -v /root/ganglia/conf/:/etc/ganglia/ -v /root/ganglia/lib/:/var/lib/ganglia/ wookietreiber/ganglia
配置文件
修改gmond.conf
cluster {
name = "bigdata"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}
udp_send_channel {
#bind_hostname = yes # Highly recommended, soon to be default.
# This option tells gmond to use a source address
# that resolves to the machine's hostname. Without
# this, the metrics may appear to come from any
# interface and the DNS names associated with
# those IPs will be used to create the RRDs.
#mcast_join = 239.2.11.71
# 192.168.32.243是bigdata2的ip
host = 192.168.32.243
port = 8649
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71
port = 8649
bind = 192.168.32.243
retry_bind = true
# Size of the UDP buffer. If you are handling lots of metrics you really
# should bump it up to e.g. 10MB or even higher.
# buffer = 10485760
}
修改gmeta.conf
data_source "bigdata" 192.168.32.243:8649
需要再flume配置文件flume-env.sh中添加如下参数将信息发送到ganglia的监控端口,或直接在启动flume时添加如下参数:
JAVA_OPTS="-Dflume.monitoring.type=ganglia -Dflume.monitoring.hosts=192.168.32.243:8649 -Xms100m -Xmx200m"
2.3.2 Solr 5.2.1
安装应用
将solr-5.2.1.tgz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf solr-5.2.1.tgz -C /opt/module/
重命名解压后的文件为solr-5.2.1
配置文件
进入solr/bin目录,修改solr.in.sh文件
ZK_HOST="hadoop102:2181,hadoop103:2181,hadoop104:2181"
SOLR_HOST="hadoop102"
# Sets the port Solr binds to, default is 8983
#可修改端口号
SOLR_PORT=8983
分发Solr到其他节点
xsyncmy /opt/module/solr-5.2.1
注:分发完成后,分别对bigdata2、bigdata3主机/opt/module/solr-5.2.1/bin下的solr.in.sh文件,修改为SOLR_HOST=对应主机名。
集群启动
在三台节点上分别启动Solr,这个就是Cloud模式
bin/solr start
Web界面
访问8983端口,可指定三台节点中的任意一台IP
http://bigdata1:8983/solr/
UI界面出现Cloud菜单栏时,Solr的Cloud模式才算部署成功。
2.3.3 Atlas 0.8.4
需要提前安装hadoop,hive,zk,kafka,hbase,solr
安装应用
将apache-atlas-0.8.4-bin.tar.gz安装包放入bigdata1节点的/opt/software文件夹下,通过如下命令将安装包解压到/opt/module文件夹下。
tar –zxvf apache-atlas-0.8.4-bin.tar.gz -C /opt/module/
重命名解压后的文件为atlas-0.8.4
配置文件
Atlas集成Hbase
-
修改conf/atlas-application.properties
#修改atlas存储数据主机 atlas.graph.storage.hostname=bigdata1:2181,bigdata2:2181,bigdata3:2181 -
进入到conf/hbase路径,添加Hbase集群的配置文件到${Atlas_Home}
ln -s /opt/module/hbase/conf/ /opt/module/atlas/conf/hbase/ -
在/opt/module/atlas/conf/atlas-env.sh中添加HBASE_CONF_DIR
#添加HBase配置文件路径 export HBASE_CONF_DIR=/opt/module/atlas/conf/hbase/conf
Atlas集成Solr
-
进入/opt/module/atlas/conf目录,修改配置文件atlas-application.properties
#修改如下配置 atlas.graph.index.search.solr.zookeeper-url=bigdata1:2181,bigdata2:2181,bigdata3:2181 -
将Atlas自带的Solr文件夹拷贝到外部Solr集群的各个节点
cp -r /opt/module/atlas/conf/solr /opt/module/solr/进入到/opt/module/solr路径,修改拷贝过来的配置文件名称为atlas_conf
mv solr atlas_conf
在Cloud模式下,启动Solr(需要提前启动Zookeeper集群),并创建collection
bin/solr create -c vertex_index -d /opt/module/solr/atlas_conf -shards 3 -replicationFactor 2
bin/solr create -c edge_index -d /opt/module/solr/atlas_conf -shards 3 -replicationFactor 2
bin/solr create -c fulltext_index -d /opt/module/solr/atlas_conf -shards 3 -replicationFactor 2
-shards 3:表示该集合分片数为3
-replicationFactor 2:表示每个分片数都有2个备份
vertex_index、edge_index、fulltext_index:表示集合名称
注意:如果需要删除vertex_index、edge_index、fulltext_index等collection可以执行命令bin/solr delete -c ${collection_name}。
Atlas集成Kafka
进入/opt/module/atlas/conf/目录,修改配置文件atlas-application.properties
vim atlas-application.properties
######### Notification Configs #########
atlas.notification.embedded=false
atlas.kafka.zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
atlas.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
atlas.kafka.zookeeper.session.timeout.ms=4000
atlas.kafka.zookeeper.connection.timeout.ms=2000
atlas.kafka.enable.auto.commit=true
启动Kafka集群,并创建Topic
bin/kafka-topics.sh --zookeeper bigdata1:2181, bigdata2:2181, bigdata3:2181 --create --replication-factor 3 --partitions 3 --topic _HOATLASOK
bin/kafka-topics.sh --zookeeper bigdata1:2181, bigdata2:2181, bigdata3:2181 --create --replication-factor 3 --partitions 3 --topic ATLAS_ENTITIES
Atlas其他配置
进入/opt/module/atlas/conf/目录,修改配置文件atlas-application.properties
vim atlas-application.properties
######### Server Properties #########
atlas.rest.address=http://bigdata1:21000
# If enabled and set to true, this will run setup steps when the server starts
atlas.server.run.setup.on.start=false
######### Entity Audit Configs #########
atlas.audit.hbase.zookeeper.quorum=bigdata1:2181,bigdata2:2181,bigdata3:2181
vim atlas-log4j.xml
#去掉如下代码的注释
Atlas集成Hive
进入/opt/module/atlas/conf/目录,修改配置文件atlas-application.properties
vim atlas-application.properties
######### Hive Hook Configs #######
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
将atlas-application.properties配置文件加入到atlas-plugin-classloader-1.0.0.jar中
zip -u /opt/module/atlas/hook/hive/atlas-plugin-classloader-0.8.4.jar /opt/module/atlas/conf/atlas-application.properties
cp /opt/module/atlas/conf/atlas-application.properties /opt/module/hive/conf/
原因:这个配置不能参照官网,将配置文件考到hive的conf中。参考官网的做法一直读取不到atlas-application.properties配置文件,看了源码发现是在classpath读取的这个配置文件,所以将它压到jar里面。
在/opt/module/hive/conf/hive-site.xml文件中设置Atlas hook
vim hive-site.xml
hive.exec.post.hooks
org.apache.atlas.hive.hook.HiveHook
修改hive的hive-env.sh文件
#在tez引擎依赖的jar包后面追加hive插件相关jar包
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS,/opt/module/atlas/hook/hive/atlas-plugin-classloader-0.8.4.jar,/opt/module/atlas/hook/hive/hive-bridge-shim-0.8.4.jar
单点启动
bin/atlas_stop.py
bin/atlas_start.py
Web界面
访问地址:http://bigdata1:21000
错误信息查看路径:/opt/module/atlas/logs/*.out和application.log
账户:admin
密码:admin
测试
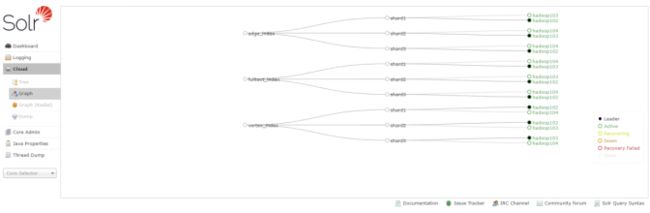
登录solr web控制台:http://hadoop102:8983/solr/#/~cloud 看到如下图显示
2.3.4 Zabbix 4.2.8
安装应用
-
每台安装yum的repo文件
sudo rpm -Uvh https://mirrors.aliyun.com/zabbix/zabbix/4.0/rhel/7/x86_64/zabbix-release-4.0-2.el7.noarch.rpm -
将文件中的镜像域名替换为阿里云
sudo sed -i 's/http:\/\/repo.zabbix.com/https:\/\/mirrors.aliyun.com\/zabbix/g' /etc/yum.repos.d/zabbix.repo -
安装
-
bigdata1:
sudo yum install -y zabbix-server-mysql zabbix-web-mysql zabbix-agent -
bigdata2和bigdata3
bigdata2: sudo yum install -y zabbix-agent bigdata3: sudo yum install -y zabbix-agent
-
-
MySQL创建数据库
mysql -h 192.168.32.244 -uroot -phxr -e"create database zabbix charset utf8 collate utf8_bin";使用zabbix的建表脚本建表
zcat /usr/share/doc/zabbix-server-mysql-4.0.29/create.sql.gz | mysql -h 192.168.32.244 -uroot -phxr zabbix -
配置Zabbix_Server
在bigdata1中的/etc/zabbix/zabbix_server.conf配置文件中添加DBHost=bigdata3 DBName=zabbix DBUser=root DBPassword=hxr在所有节点的/etc/zabbix/zabbix_server.conf配置文件中修改
# 修改 Server=bigdata1 # 注销 # ServerActive=127.0.0.1 # Hostname=Zabbix server -
配置Zabbix Web时区
在/etc/httpd/conf.d/zabbix.conf文件中添加php_value date.timezone Asia/Shanghai
-
启动Zabbix
-
bigdata1启动:
sudo systemctl start/stop zabbix-server zabbix-agent httpd (httpd是访问html等页面的入口)bigdata1设置开机自启:
sudo systemctl enable/disable zabbix-server zabbix-agent httpd -
bigdata2/3启动:
sudo systemctl start/stop zabbix-agent设置开机自启:
sudo systemctl enable/disable zabbix-agent
-
访问页面
http://192.168.32.242/zabbix
在页面中完成对Zabbix_Web的数据库等配置
如果配置出现错误,可以在配置文件/etc/zabbix/web/zabbix.conf.php中进行修改
异常日志可以查看 cat /var/log/zabbix/zabbix_server.log配置主机
在配置-> 主机-> 创建主机 中添加需要监控的主机-
配置监控项
创建完主机后,点击监控项进行监控项的创建
如监控datanode进行是否正常运行
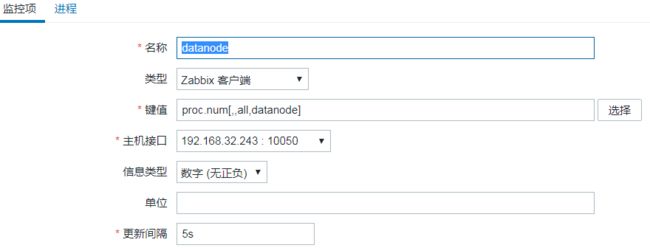 image.png
image.png -
配置触发器
点击触发器进行创建
 image.png
image.png -
通知方式设置
在管理-> 报警媒介类型 中进行通知报警的配置
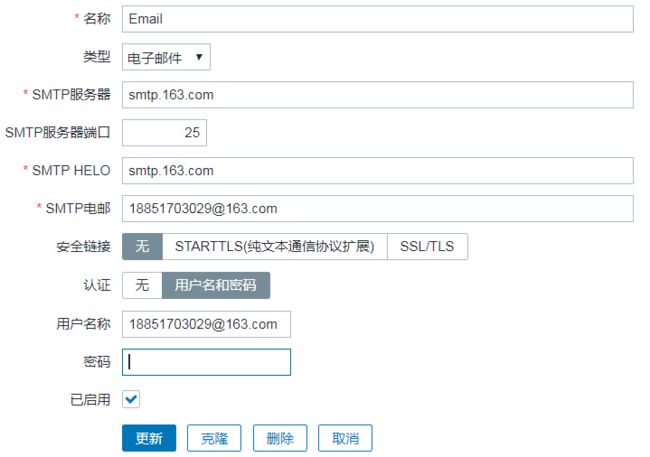 image.png
image.png -
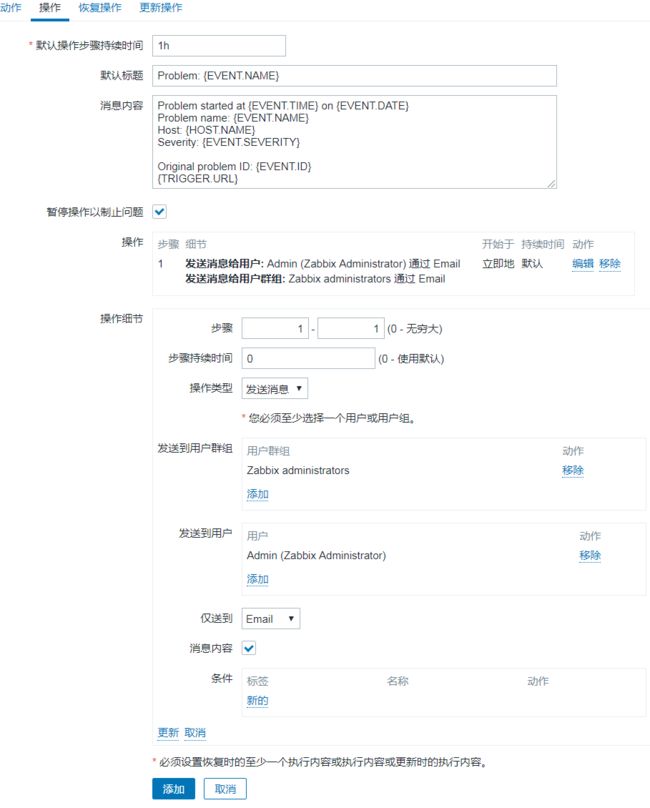
创建动作
在配置-> 动作中创建动作,为触发器设置动作(发邮件)。
 image.png
image.png
-
为用户配置邮箱
在用户的基本资料中配置
 image.png
image.png -
使用模版为每个节点进行配置
默认有很多框架的模板可以选择,如MySQL、redis等。但是没有hadoop的模板,需要自己配置。
在配置-> 模板 中进行模板配置,创建监控项、触发器,然后应用到主机上。
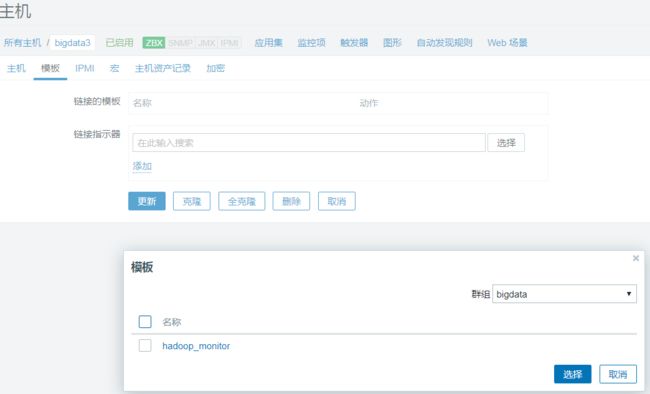 image.png
image.png
注意需要修改动作来为模板的触发器绑定动作。
四、附
4.1 UI界面
192.168.32.242:50070 192.168.32.243:8088
192.168.32.242:8443 azkaban(admin:admin)
http://192.168.32.243/ganglia ganglia(监控flume)
192.168.32.242:16010 hbase 192.168.32.242:8983 solr 192.168.32.242:21000 atlas(admin:admin)
192.168.32.244:38682 flink(每次启动都会变,具体查看/opt/module/flink-1.12.0/yarn-session.log)
http://192.168.32.242/zabbix Zabbbix(Admin:zabbix,报警邮箱[email protected])
http://192.168.101.179:6080 Ranger界面(admin/bigdata123)
http://192.168.101.180:9090 Prometheus界面
http://192.168.101.180:3000 Grafana界面 (admin/admin)
http://192.168.101.180:9363/metrics Prometheus监控上报数据
| 页面 | 地址 | 说明 |
|---|---|---|
| hdfs页面 | 192.168.32.242:50070 | |
| yarn页面 | 192.168.32.243:8088 | |
| azkaban页面 | 192.168.32.242:8443 | admin:admin |
| flume监控页面 | http://192.168.32.243/ganglia | |
| flink | 192.168.32.244:38682 | 每次启动都会变,具体查看/opt/module/flink-1.12.0/yarn-session.log |
| Zabbbix | http://192.168.32.242/zabbix | Admin:zabbix,报警邮箱[email protected] |
| hbase页面 | 192.168.32.242:16010 | |
| solr页面 | 192.168.32.242:8983 | |
| Atlas页面 | 192.168.32.242:21000 | admin:admin |
4.2 启动命令
| 组件 | 命令 | 说明 |
|---|---|---|
| hdfs | start-dfs.sh | bigdata1节点上执行 |
| yarn | start-yarn.sh | bigdata2节点上执行 |
| historyjob | mr-jobhistory-daemon.sh start historyserver | bigdata3节点上执行 |
| hive | nohup ./hive --service metastore &; nohup ./hive --service hiveserver2 &; | bigdata1节点上hive/bin目录下执行 |
| zookeeper | zk-server.sh start | bigdata1节点上执行 |
| kafka | kafka-server.sh start | bigdata1节点上执行 |
| flink集群 | export HADOOP_CLASSPATH=hadoop classpath; nohup ./yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm flink-on-yarn -qu flink -d 1>/opt/module/flink-1.12.0/yarn-session.log 2>/opt/module/flink-1.12.0/yarn-session.err &; |
bigdata1节点上的flink/bin目录下执行 |
| sqoop | 在脚本中调用 | |
| azkaban | server/bin/azkaban-web-start.sh; executor/bin/azkaban-executor-start.sh; | bigdata1节点上的azkaban目录下执行 |
| ganglia | docker start ganglia | bigdata2节点上执行 |
| zabbix | bigdata1节点上 sudo systemctl start/stop zabbix-server zabbix-agent httpd; bigdata2/3节点上 sudo systemctl start/stop zabbix-agent; |
|
| hbase | bin/start-hbase.sh | bigdata1节点上hbase目录下执行 |
| solr | solr.sh start | bigdata1节点上执行 |
| atlas | bin/atlas_start.py | bigdata1节点上执行 |
| Prometheus | nohup ./prometheus --web.enable-lifecycle --config.file=prometheus.yml > ./prometheus.log 2>&1 & | bigdata2节点上的Prometheus目录下执行 |
| Grafana | nohup ./bin/grafana-server web > ./grafana.log 2>&1 & | bigdata2节点上的Grafana目录下执行 |
4.3 各jps进程名对应的组件
| 组件 | 进程名 | 说明 |
|---|---|---|
| HDFS | NameNode SecondaryNameNode DataNode | |
| Yarn | ResourceManager NodeManager JobHistoryServer | |
| Zookeeper | QuorumPeerMain | |
| Kafka | Kafka | |
| Flume | Application | |
| Hive | RunJar | |
| Azkaban | AzkabanExecutorServer AzkabanWebServer | |
| Sqoop | Sqoop | |
| Flink(yarn-session) | FlinkYarnSessionCli YarnSessionClusterEntrypoint(为FlinkJobManager) YarnTaskExecutorRunner | |
| Hbase | HMaster HRegionServer | |
| Solr | jar | |
| Atlas | Atlas | |
| Ranger Admin | EmbeddedServer | |
| RangerUsersync | UnixAuthenticationService | |
| Spark-session | SparkSubmit,ApplicationMaster,YarnCoarseGrainedExecutorBackend |
4.4 常用端口号
| 组件 | 端口号 | 说明 |
|---|---|---|
| Hadoop | 50070:hdfs.namenode.http-address: 50075:Hdfs.datanode.http-address 50090:SecondaryNameNode辅助名称节点端口号 50010:Hdfs.datanode.address 8088:Yarn.resourcemanager.webapp.address 19888:历史服务器web访问端口 8020:namenode节点active状态下的端口号 9000端口:fileSystem默认的端口号 8032:resourcemanager(jobtracker)的服务端口号 | |
| Zookeeper | 2181:zookeeper的端口号 2888:zookeeper之间通讯的端口 3888:zookeeper推选leader的端口 8485:journalnode默认的端口号 | |
| Kafka | 9092:kafka端口号 8086:Kafka Monitor的访问网址(可在启动脚本中指定) 9000:Kafka Manager的访问网址,默认是9000,与namenode端口冲突,bin/kafka-manager -Dhttp.port=9090 | |
| Flume | 41414:flume监控的端口 | |
| Hive | 9083:hive元数据metastore的端口号(Presto需要读取hive的元数据库) 10000:hive2端口 | |
| Azkaban | 8443:所指定的jetty服务器的web端口 8081:通讯端口 | |
| Oozie | 11000:Oozie 的web端口号 | |
| Sqoop | ||
| Flink | 8081:Flink的standalone模式Web端口号 6123:Flink的jobmanager和taskmanager内部通信端口 37807:Flink的yarn-session模式Web端口号 | |
| Spark | 7077:spark的standalone的master端口 4040:local模式spark的driver的web 8080:standalone模式spark的master的web 8088:client模式的web端口 18080:spark的historyserver的web | |
| Hbase | 16010:HBASE的web端口号 16000:HBase的master的通讯端口 16020:regionserver的端口号 16030:regionserver的web端口 | |
| Solr | 8983:solr | |
| Atlas | 21000:Atlas | |
| Clickhouse | 9000:TCP端口,Clickhouse client 默认连接端口; 8123:Http端口 | |
| Kettle | 8080:kettlemaster节点 8081:kettleslave1节点 8082:kettleslave2节点 | |
| 即系查询框架 | 7070:kylin的web端口 8881:presto的httpserver(即coordinator的端口) 9095: imply的web端口(druid的ui) 21000:impala端口 25010:impala日志网页端口 | |
| 数据库 | 3306:MySQL 1521:Orical 27017:MongoDB | |
| Redis | 6379 | |
| ELK | 9300:elasticsearch官方客户端连接、内部通讯端口 9200:elasticsearch集群、控制台和http访问端口 5601:kibana服务端口 | |
| Zabbix | 10051:Zabbix_Server通讯端口 | |
| Prometheus | 9090:prometheus 9100:node-productor 9104:mysqld-exporter 3000:Grafana | |
| 平台 | 7180:CDM 8080:HDP 8888:hue未优化,8889:hue优化 |
4.5 shell脚本
xsyncmy:文件分发脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "----- 未进行传参 -----"
exit
fi
for file in $@
do
if [ -e $file ]
then
DIRNAME=`cd $(dirname ${file});pwd`
BASENAME=`basename ${file}`
USER=`whoami`
for host in bigdata2 bigdata3
do
echo ----- 文件 $DIRNAME/$BASENAME 传输到${host} -----
rsync -av ${DIRNAME}/${BASENAME} ${USER}@${host}:${DIRNAME}
done
else
echo ----- ${file}文件不存在 -----
fi
done
jps-server.sh:查看3个节点jps进程脚本
#!/bin/bash
#jps脚本
for host in bigdata1 bigdata2 bigdata3
do
echo ----- ${host} -----
ssh ${host} "jps | grep -iv jps"
done
zk-server.sh:zookeeper集群的 启动/关闭/状态检查 脚本
#!/bin/bash
#zk启动/停止脚本
case $1 in
"start")
echo ----- 开启zookeeper集群 -----
for host in bigdata1 bigdata2 bigdata3
do
ssh ${host} "/opt/module/zookeeper-3.4.10/bin/zkServer.sh start"
done
;;
"stop")
echo ----- 关闭zookeeper集群 -----
for host in bigdata1 bigdata2 bigdata3
do
ssh ${host} "/opt/module/zookeeper-3.4.10/bin/zkServer.sh stop"
done
;;
"status")
echo ----- 查看zookeeper集群状态 -----
for host in bigdata1 bigdata2 bigdata3
do
ssh ${host} "/opt/module/zookeeper-3.4.10/bin/zkServer.sh status"
done
;;
esac
kafka-server.sh (-deamon 效果同 nohup xxx 1>/dev/null 2>1 &):Kafka集群的 启动/关闭脚本
#!/bin/bash
case $1 in
"start")
for host in bigdata1 bigdata2 bigdata3
do
ssh ${host} "source /etc/profile ; export JMX_PORT=9988 ; nohup /opt/module/kafka-2.11/bin/kafka-server-start.sh /opt/module/kafka-2.11/config/server.properties 1>/dev/null 2>&1 &"
if [ $? -eq 0 ]
then
echo ----- ${host} kafka启动成功 -----
fi
done
;;
"stop")
for host in bigdata1 bigdata2 bigdata3
do
ssh ${host} "source /etc/profile ; /opt/module/kafka-2.11/bin/kafka-server-stop.sh"
if [ $? -eq 0 ]
then
echo ----- ${host} kafka关闭成功 -----
fi
done
;;
esac
flume-server.sh:Flume的 启动/关闭脚本
#!/bin/bash
case $1 in
"start")
for host in bigdata1 #bigdata2
do
# ssh ${host} "source /etc/profile ; nohup /opt/module/flume-1.7.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.7.0/conf -f /opt/module/flume-1.7.0/job/file-kafka-hdfs.conf 1>/dev/null 2>&1 &"
#ssh ${host} "source /etc/profile ; nohup /opt/module/flume-1.7.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.7.0/conf -f /opt/module/flume-1.7.0/job/log-kafka.conf 1>/dev/null 2>&1 &"
ssh bigdata1 "source /etc/profile ; nohup /opt/module/flume-1.7.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.7.0/conf -f /opt/module/flume-1.7.0/job/log-kafka.conf 1>/dev/null 2>&1 &"
#ssh ${host} "source /etc/profile ; nohup /opt/module/flume-1.7.0/bin/flume-ng agent -n a2 -c /opt/module/flume-1.7.0/conf -f /opt/module/flume-1.7.0/job/kafka-hdfs.conf 1>/dev/null 2>&1 &"
ssh bigdata2 "source /etc/profile ; nohup /opt/module/flume-1.7.0/bin/flume-ng agent -n a2 -c /opt/module/flume-1.7.0/conf -f /opt/module/flume-1.7.0/job/kafka-hdfs.conf 1>/dev/null 2>&1 &"
if [ $? -eq 0 ]
then
echo ----- ${host} flume启动成功 -----
fi
done
;;
"stop")
for host in bigdata1 #bigdata2
do
ssh ${host} "source /etc/profile ; ps -ef | awk -F \" \" '/log-kafka.conf/ && !/awk/{print \$2}' | xargs kill "
ssh ${host} "source /etc/profile ; ps -ef | awk -F \" \" '/kafka-hdfs.conf/ && !/awk/{print \$2}' | xargs kill "
if [ $? -eq 0 ]
then
echo ----- ${host} flume关闭成功 -----
fi
done
;;
esac
solr-server.sh :Solr的 启动/关闭脚本
#!/bin/bash
case $1 in
"start"){
for i in bigdata1 bigdata2 bigdata3
do
ssh $i "/opt/module/solr-5.2.1/bin/solr start"
done
};;
"stop"){
for i in bigdata1 bigdata2 bigdata3
do
ssh $i "/opt/module/solr-5.2.1/bin/solr stop"
done
};;
esac
azkaban-3.84.4 脚本
#!/bin/bash
start-web(){
ssh bigdata2 'cd /opt/module/azkaban-3.84.4/web/;bin/shutdown-web.sh'
}
stop-web(){
ssh bigdata2 'cd /opt/module/azkaban-3.84.4/web/;bin/shutdown-web.sh'
}
start-exec(){
for host in bigdata1 bigdata2 bigdata3;do
(ssh ${host} 'cd /opt/module/azkaban-3.84.4/exec/;bin/start-exec.sh')&
done
wait
}
stop-exec(){
for host in bigdata1 bigdata2 bigdata3;do
(ssh ${host} 'cd /opt/module/azkaban-3.84.4/exec/;bin/shutdown-exec.sh')&
done
wait
}
activate-exec(){
for host in bigdata1 bigdata2 bigdata3;do
ssh ${host} curl -G "${host}:12321/executor?action=activate" && echo
done
}
case $1 in
"start-web")
start-web
;;
"stop-web")
stop-web
;;
"start-exec")
start-exec
;;
"stop-exec")
stop-exec
;;
"activate-exec")
activate-exec
;;
"start")
start-exec
sleep 2
activate-exec
if [ "$?" -ne "0" ];then
stop-exec
fi
sleep 1
start-web
;;
"stop")
stop-web
stop-exec
;;
esac
4.6 其他
如果hdfs遇到权限问题是因为/根目录用户为hxr,两种解决方式①hadoop dfs -chmod -R 777 / 将根目录开放给其他用户②在操作时用hxr用户,-DHADOOP_USER_NAME=hxr
hdfs dfsadmin -safemode leave 如果进入安全模式,可以通过该命令离开
hadoop checknative -a 查看本地库支持