程序员的数学【线性代数基础】
目录
- 前言
- 1.向量是什么
-
- 1.1 向量的定义
- 1.2 向量的表示
- 1.3 向量物理意义
- 2.行向量与列向量
- 3.向量运算
-
- 3.1 向量加减法
- 3.2 向量数乘
- 3.3 转置
- 3.4 向量内积
- 3.5 向量运算法则
- 4.向量的范数
-
- 4.1 1-范数
- 4.2 2-范数
- 4.3 P-范数
- 4.4 ∞ \infty ∞-范数
- 4.5 − ∞ -\infty −∞-范数
- 5.特殊向量
-
- 5.1 0向量
- 5.2 单位向量
- 6.矩阵是什么
- 7.常见矩阵
-
- 7.1 方阵
- 7.2 对称矩阵
- 7.3 单位矩阵
- 7.4 对角矩阵
- 8.矩阵运算
-
- 8.1 矩阵加减法
- 8.2 数乘
- 8.3 矩阵乘法
- 8.4 矩阵转置
- 8.5 矩阵运算法则
- 9.逆矩阵
-
- 9.1 逆矩阵定义
- 9.2 逆矩阵作用
- 10.行列式
- 11.伴随矩阵
-
- 11.1 代数余子式
- 11.2 伴随矩阵定义
- 11.3 伴随矩阵性质
- 11.4 伴随矩阵与逆矩阵
前言
本文其实值属于:程序员的数学【AIoT阶段二】 (尚未更新)的一部分内容,本篇把这部分内容单独截取出来,方便大家的观看,本文介绍 线性代数基础,在机器学习中经常会有矩阵、向量的定义以及计算,是公式定义、推导中必不可少的一部分内容,很多基础概念的定义中都用到了向量的概念,有关线性代数,后续还会发一篇博文:程序员的数学【线性代数高级】,本文涵盖了一些计算的问题并使用代码进行了实现,安装代码运行环境见博客:最详细的Anaconda Installers 的安装【numpy,jupyter】(图+文),如果你只是想要简单的了解有关线代的内容,那么只需要学习一下博文:NumPy从入门到高级,如果你是跟着博主学习 A I o T AIoT AIoT 的小伙伴,建议先看博文:数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解),如果你没有 P y t h o n Python Python 基础,那么还需先修博文:Python的进阶之道【AIoT阶段一(上)】(十五万字博文 保姆级讲解)
1.向量是什么
1.1 向量的定义
在数学中,向量(也称为欧几里得向量、几何向量、矢量),指具有 大小 和 方向 的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。与向量对应的量叫做数量(物理学中称标量),数量(或标量)只有大小,没有方向。

1.2 向量的表示
向量的记法:印刷体记作粗体的字母(如 a,b,u,v),书写时在字母顶上加一小箭头 → \rightarrow →。如果给定向量的起点(A)和终点(B),可将向量记作 A B → \overrightarrow{AB} AB,实际上向量有多种记法,可以用元组表示一个向量,如 ( x 1 , x 2 ) (x_1,x_2) (x1,x2) 或 < x 1 , x 2 >
V = [ x 1 x 2 ⋮ x n ] V= \left[ \begin{matrix} x_1\\ x_2\\ \vdots \\ x_n \end{matrix} \right] V=⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤
显然,上述这种写法太占篇幅,不环保!,所以我们经常会写成: V T = [ x 1 , x 2 , . . . , x n ] V^T=[x_1,x_2,...,x_n] VT=[x1,x2,...,xn],向量中的每个元素 x n x_n xn,都称作向量的一个分量。
1.3 向量物理意义
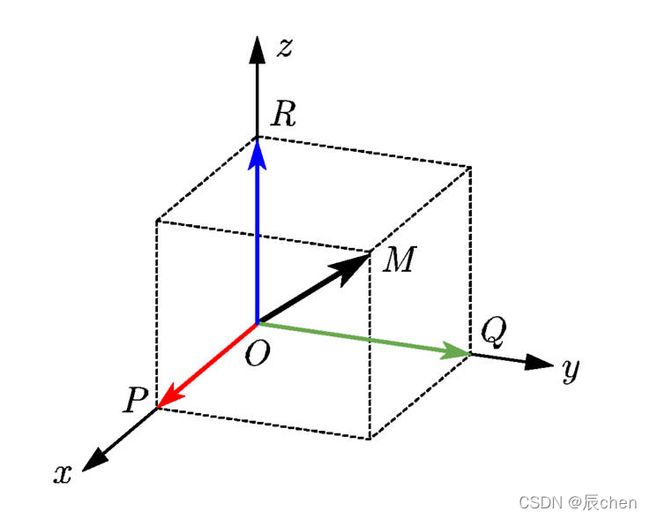
O M → = ( P , Q , R ) = O P → + O Q → + O R → \overrightarrow{OM}=(P,Q,R)=\overrightarrow{OP}+\overrightarrow{OQ}+\overrightarrow{OR} OM=(P,Q,R)=OP+OQ+OR
向量的几何意义就是空间中的点,物理意义就是速度或者力这样的矢量。
向量的分量我们称之为维度, n n n 维向量集合的全体就构成了 n n n 维欧式空间,一个 n n n 维向量其实就是一个 n n n 维欧式空间的一个点。
2.行向量与列向量
行向量在线性代数中,是一个 1 × n 1×n 1×n 的矩阵,即矩阵由一个含有 n n n 个元素的行所组成即行向量。行向量的转置是一个列向量,反之亦然。
行向量示例: V = [ x 1 , x 2 , . . . , x n ] V=[x_1,x_2,...,x_n] V=[x1,x2,...,xn]
在线性代数中,列向量是一个 n × 1 n×1 n×1 的矩阵,即矩阵由一个含有 n n n 个元素的列所组成。
列向量示例: V = [ x 1 x 2 ⋮ x n ] V= \left[ \begin{matrix} x_1\\ x_2\\ \vdots \\ x_n \end{matrix} \right] V=⎣⎢⎢⎢⎡x1x2⋮xn⎦⎥⎥⎥⎤
为简化书写、方便排版起见,有时会以加上转置符号 T T T 的行向量表示列向量。
V T = [ x 1 , x 2 , . . . , x n ] V^T=[x_1,x_2,...,x_n] VT=[x1,x2,...,xn]
在机器学习中说到向量一般都是指 列向量。
3.向量运算
3.1 向量加减法
等于它们的分量分别相加,显然两个向量的长度得是相等的,减法我们在这里不列举,很容易举一反三。
[ 1 2 3 ] + [ 4 5 6 ] = [ 5 7 9 ] \left[ \begin{matrix} 1\\ 2\\ 3 \end{matrix} \right] + \left[ \begin{matrix} 4 \\ 5 \\ 6 \end{matrix} \right] = \left[ \begin{matrix} 5\\ 7\\ 9 \end{matrix} \right] ⎣⎡123⎦⎤+⎣⎡456⎦⎤=⎣⎡579⎦⎤
3.2 向量数乘
3 × [ 1 2 3 ] = [ 3 6 9 ] 3\times\left[ \begin{matrix} 1\\ 2\\ 3 \end{matrix} \right] = \left[ \begin{matrix} 3\\ 6\\ 9 \end{matrix} \right] 3×⎣⎡123⎦⎤=⎣⎡369⎦⎤
3.3 转置
[ 1 2 3 ] T = [ 1 , 2 , 3 ] \left[ \begin{matrix} 1\\ 2\\ 3 \end{matrix} \right]^T=[1,2,3] ⎣⎡123⎦⎤T=[1,2,3]
[ 1 , 2 , 3 ] T = [ 1 2 3 ] [1,2,3]^T=\left[ \begin{matrix} 1\\ 2\\ 3 \end{matrix} \right] [1,2,3]T=⎣⎡123⎦⎤
3.4 向量内积
两个列向量 A T B A^TB ATB 等于对应位置相乘再相加。
[ 1 , 2 , 3 ] ⋅ [ 4 5 6 ] = 1 × 4 + 2 × 5 + 3 × 6 = 32 [1,2,3] \cdot \left[ \begin{matrix} 4 \\ 5 \\ 6 \end{matrix} \right]=1 \times4+2 \times5+3\times 6=32 [1,2,3]⋅⎣⎡456⎦⎤=1×4+2×5+3×6=32
3.5 向量运算法则
实数与向量运算法则,设 λ \lambda λ, μ \mu μ 是实数,则有:
- 结合率: λ ( μ A ) = ( λ μ ) A \lambda(\mu A) = (\lambda\mu)A λ(μA)=(λμ)A
- 分配率: ( λ + μ ) A = λ A + μ A (\lambda + \mu)A = \lambda A + \mu A (λ+μ)A=λA+μA
向量内积运算法则:
- 交换律: A ⋅ B = B ⋅ A A\cdot B = B\cdot A A⋅B=B⋅A
- 分配率: ( A + B ) ⋅ C = A ⋅ C + B ⋅ C (A + B)\cdot C = A\cdot C + B\cdot C (A+B)⋅C=A⋅C+B⋅C
- 结合律: ( λ A ) ⋅ B = λ ( A ⋅ B ) (\lambda A)\cdot B = \lambda(A\cdot B) (λA)⋅B=λ(A⋅B)
4.向量的范数
范数的公式是向量每个分量绝对值 P P P 次方 再用幂函数计算 P P P分之一,这里 P P P 肯定是整数 1 , 2 , 3... 1,2,3... 1,2,3...到正无穷都是可以的。向量的范数就是把向量变成一个标量,范数的表示就是两个竖线来表示,然后右下角写上 P P P。
∣ ∣ A ∣ ∣ P = [ ∑ i = 1 n ∣ a i ∣ P ] 1 P ||A||_P=[\sum_{i=1}^n|a_i|^P]^{\frac{1}{P}} ∣∣A∣∣P=[∑i=1n∣ai∣P]P1

4.1 1-范数
∣ ∣ X ∣ ∣ 1 = ∑ i = 1 n ∣ x i ∣ ||X||_1=\sum_{i=1}^n|x_i| ∣∣X∣∣1=∑i=1n∣xi∣
即向量元素绝对值之和,表示 X X X 到零点的 曼哈顿距离,如上图:红色、蓝色、黄色的线条。
4.2 2-范数
∣ ∣ X ∣ ∣ 2 = ∑ i = 1 n x i 2 ||X||_2=\sqrt{\sum_{i=1}^nx_i^2} ∣∣X∣∣2=∑i=1nxi2
即向量元素的平方和再开方,也叫 欧几里得范数,常用计算向量长度,表示 X X X 到零点的欧式距离,如上图绿色的线条
4.3 P-范数
∣ ∣ X ∣ ∣ P = [ ∑ i = 1 n ∣ x i ∣ P ] 1 P ||X||_P=[\sum_{i=1}^n|x_i|^P]^{\frac{1}{P}} ∣∣X∣∣P=[∑i=1n∣xi∣P]P1
即向量元素绝对值的 P P P 次方和的 1 P \frac{1}{P} P1 次幂,表示 X X X 到零点的 P P P 阶 闵氏距离。
4.4 ∞ \infty ∞-范数
∣ ∣ X ∣ ∣ ∞ = m a x ∣ x i ∣ ||X||_\infty=max|x_i| ∣∣X∣∣∞=max∣xi∣
当 P P P 趋向于正无穷时,即所有向量元素绝对值中的最大值。表示 切比雪夫距离。

国际象棋棋盘上两个位置间的切比雪夫距离是指王要从一个位子移至另一个位子需要走的步数。由于王可以往斜前或斜后方向移动一格,因此可以较有效率的到达目的的格子。
4.5 − ∞ -\infty −∞-范数
∣ ∣ X ∣ ∣ − ∞ = m i n ∣ x i ∣ ||X||_{-\infty}=min|x_i| ∣∣X∣∣−∞=min∣xi∣
当 P P P 趋向于负无穷时,即所有向量元素绝对值中的最小值。
5.特殊向量
5.1 0向量
就是分量全部为 0 0 0 的向量
[ 0 , 0 , ⋅ ⋅ ⋅ , 0 ] [0,0,\cdot\cdot\cdot,0] [0,0,⋅⋅⋅,0]
5.2 单位向量
就是2-范数为 1 1 1、模为 1 1 1、长度为 1 1 1 的向量。
向量 A B → \overrightarrow{AB} AB 的长度叫做向量的模,记作 ∣ A B → ∣ |\overrightarrow{AB}| ∣AB∣。
计算公式:
- 空间向量 ( x , y , z ) (x,y,z) (x,y,z) ,其中 x , y , z x,y,z x,y,z 表示三个轴上的坐标,模长为: x 2 + y 2 + z 2 \sqrt{x^2+y^2+z^2} x2+y2+z2
- 平面向量 ( x , y ) (x,y) (x,y),模长为: x 2 + y 2 \sqrt{x^2+y^2} x2+y2
根据2-范数的公式可知,2-范数就是向量的模,对于向量(列向量)来说,2-范数就是: X T X \sqrt{X^TX} XTX
6.矩阵是什么
矩阵就是二维数组,下面是一个 m m m 乘 n n n 的矩阵,它有 m m m 行, n n n 列,每行每列上面都有元素,每个元素都有行标 i i i 和列标 j j j, a i j a_{ij} aij。简称 m × n m \times n m×n 矩阵,记作:
{ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n } \left\{ \begin{matrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \\ \end{matrix} \right\} ⎩⎪⎪⎪⎨⎪⎪⎪⎧a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎭⎪⎪⎪⎬⎪⎪⎪⎫
注意 a 11 a_{11} a11 的索引是 A [ 0 , 0 ] A[0,0] A[0,0]。
这 m × n m\times n m×n 个数称为矩阵 A A A 的元素,简称为元,数 a i j a_{ij} aij 位于矩阵 A A A 的第 i i i 行第 j j j 列,称为矩阵 A A A 的 ( i , j ) (i,j) (i,j) 元, m × n m\times n m×n 矩阵 A A A 也记作 A m n A_{mn} Amn
7.常见矩阵
7.1 方阵
如果 m m m 等于 n n n,那就称为方阵:
A = [ 1 2 3 4 5 6 7 8 9 ] A= \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix} A=⎣⎡147258369⎦⎤
7.2 对称矩阵
如果对于任意的 a i j a_{ij} aij 都等于 a j i a_{ji} aji,那么这个矩阵就是对称矩阵。从定义不难看出,对称矩阵的前提是该矩阵首先是一个方阵。
A = [ 1 4 7 4 5 8 7 8 9 ] A= \begin{bmatrix} 1 & 4 & 7 \\ 4 & 5 & 8 \\ 7 & 8 & 9 \end{bmatrix} A=⎣⎡147458789⎦⎤
7.3 单位矩阵
主对角线都是 1 1 1,其它位置是 0 0 0,这称之为单位矩阵,单位矩阵写为 I I I,一定是方阵,等同于数字里面的 1 1 1。
A = [ 1 0 0 0 1 0 0 0 1 ] A= \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix} A=⎣⎡100010001⎦⎤
7.4 对角矩阵
对角矩阵,就是主对角线非 0 0 0,其它位置是 0 0 0。
[ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ λ n ] \left[ \begin{matrix} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_n \\ \end{matrix} \right] ⎣⎢⎢⎢⎡λ10⋮00λ2⋮0⋯⋯⋱⋯00⋮λn⎦⎥⎥⎥⎤
对角矩阵一定是方阵。不然没有对角线!
8.矩阵运算
8.1 矩阵加减法
矩阵的加法就是矩阵的对应位置相加,减法也是一样就是对应位置相减。
[ 1 2 3 1 6 4 ] + [ 6 0 1 7 1 5 ] = [ 7 2 4 8 7 9 ] \begin{bmatrix} 1 & 2 \\ 3 & 1 \\ 6 & 4 \end{bmatrix}+\begin{bmatrix} 6 & 0 \\ 1 & 7 \\ 1 & 5 \end{bmatrix}=\begin{bmatrix} 7 & 2 \\ 4 & 8 \\ 7 & 9 \end{bmatrix} ⎣⎡136214⎦⎤+⎣⎡611075⎦⎤=⎣⎡747289⎦⎤
8.2 数乘
3 × [ 1 2 3 4 5 6 7 8 9 ] = [ 3 6 9 12 15 18 21 24 27 ] 3\times\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}=\begin{bmatrix} 3 & 6 & 9 \\ 12 & 15 & 18 \\ 21 & 24 & 27 \end{bmatrix} 3×⎣⎡147258369⎦⎤=⎣⎡312216152491827⎦⎤
8.3 矩阵乘法
矩阵的乘法和一般的乘法是不太一样!
它是把第一个矩阵的每一行,和第二个矩阵的每一列拿过来做内积得到结果。
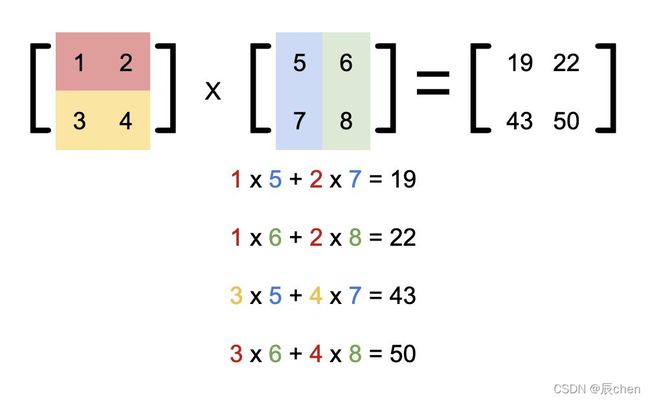
[ 1 2 1 3 1 0 ] ⋅ [ 2 5 0 4 7 2 ] = [ 9 15 6 19 ] \begin{bmatrix} 1 & 2 & 1 \\ 3 & 1 & 0 \\ \end{bmatrix} \cdot \begin{bmatrix} 2 & 5 \\ 0 & 4 \\ 7 & 2 \end{bmatrix}= \begin{bmatrix} 9 & 15 \\ 6 & 19 \\ \end{bmatrix} [132110]⋅⎣⎡207542⎦⎤=[961519]
对于矩阵乘法的两个矩阵,假设第一个矩阵为 m m m 行 n n n 列,第二个矩阵为 n n n 行 k k k 列,那么进行矩阵乘法后得到的矩阵为 m m m 行 k k k 列: m × n ⋅ n × k = m × k m \times n \cdot n \times k=m \times k m×n⋅n×k=m×k
8.4 矩阵转置
转置的操作和向量是一样的,就是把 a i j a_{ij} aij 变成 a j i a_{ji} aji,即把行和列互换一下:
[ 1 2 1 3 1 0 ] T = [ 1 3 2 1 1 0 ] \begin{bmatrix} 1 & 2 & 1 \\ 3 & 1 & 0 \\ \end{bmatrix}^T= \begin{bmatrix} 1 & 3 \\ 2 & 1 \\ 1 & 0 \end{bmatrix} [132110]T=⎣⎡121310⎦⎤
8.5 矩阵运算法则
-
矩阵加减法
满足:分配律、结合律、交换律 -
矩阵乘法
满足:分配律、结合律,不满足交换律

矩阵乘法 + 转置: ( A B ) T = B T A T (AB)^T=B^TA^T (AB)T=BTAT
9.逆矩阵
9.1 逆矩阵定义
矩阵有 A B AB AB 乘法,但是没有 A / B A/B A/B 这么一说,只有逆矩阵。
逆矩阵怎么定义的?
假设有个矩阵 A A A,注意它一定是方阵(必须是方阵),乘以矩阵 B B B 等于单位矩阵 I I I :
A B = I AB=I AB=I 或 B A = I BA=I BA=I
那么我们称这里的 B B B 为 A A A 的右逆矩阵,和左逆矩阵。
有个很重要的结论就是,如果这样的 B B B 存在的话,它的左逆和右逆一定相等,统称为 A A A 的逆矩阵 A − 1 A^{-1} A−1,则: A = B − 1 , B = A − 1 A=B^{-1},B=A^{-1} A=B−1,B=A−1
9.2 逆矩阵作用
矩阵求逆有什么用呢?
它可以帮助我们解线性方程组,比如 X W = Y XW=Y XW=Y 。两边同时乘以 X X X 的逆:
X − 1 X W = X − 1 Y X^{-1}XW=X^{-1}Y X−1XW=X−1Y
I W = X − 1 Y IW=X^{-1}Y IW=X−1Y
W = X − 1 Y W=X^{-1}Y W=X−1Y
就可以求解出方程的系数,它发明的目的也是干这样的事情用的。
举例说明:
# 三元一次方程
# 3x + 2y + 4z = 19
# 2x -y + 3z = 9
# x + y - z = 0
import numpy as np
X = np.array([[3, 2, 4],
[2, -1, 3],
[1, 1, -1]])
Y = np.array([19, 9, 0])
display(X, Y)
# np.linalg.inv表示矩阵求逆
# dot表示矩阵乘法
W = np.linalg.inv(X).dot(Y)
print('求解方程x,y,z为:', W)

从这里我们也可以看出来单位矩阵像我们乘法里面的 1 1 1。
逆矩阵相关公式:
- ( A B ) − 1 = B − 1 A − 1 (AB)^{-1}=B^{-1}A^{-1} (AB)−1=B−1A−1
- ( A − 1 ) − 1 = A (A^{-1})^{-1}=A (A−1)−1=A
- ( A T ) − 1 = ( A − 1 ) T (A^T)^{-1}=(A^{-1})^T (AT)−1=(A−1)T
10.行列式
行列式其实在机器学习中用的并不多,一个矩阵必须是方阵,才能计算它的行列式
行列式是把矩阵变成一个标量
∣ a 11 a 12 a 21 a 22 ∣ = a 11 a 22 − a 12 a 21 \left |\begin{array}{cccc} a_{11} &a_{12}\\ a_{21} &a_{22}\\ \end{array}\right|=a_{11}a_{22}-a_{12}a_{21} ∣∣∣∣a11a21a12a22∣∣∣∣=a11a22−a12a21
import numpy as np
A = np.array([[1,3],[2,5]])
display(A)
print('矩阵A的行列式是:\n',np.linalg.det(A))

行列式在求解,逆矩阵的过程中,起到了作用,行列式 不为0,才可以求解逆矩阵!
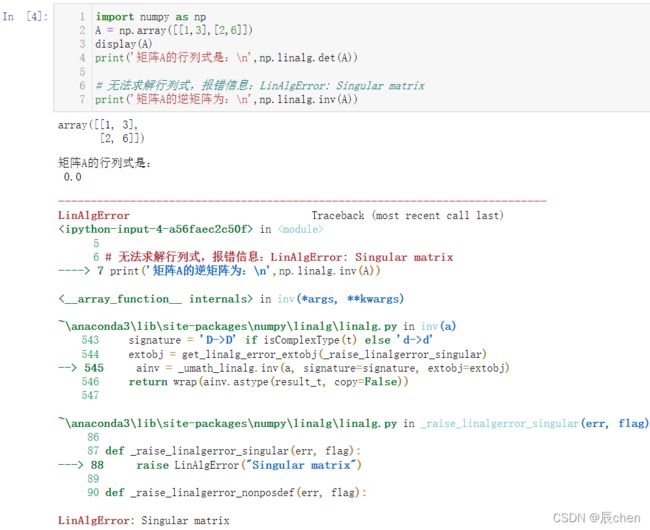
import numpy as np
A = np.array([[1,3],[2,6]])
display(A)
print('矩阵A的行列式是:\n',np.linalg.det(A))
# 无法求解行列式,报错信息:LinAlgError: Singular matrix
print('矩阵A的逆矩阵为:\n',np.linalg.inv(A))
11.伴随矩阵
11.1 代数余子式
代数余子式定义:
代数余子式计算
A = [ 1 2 3 2 2 1 3 4 3 ] A= \begin{bmatrix} 1 & 2 & 3 \\ 2 & 2 & 1 \\ 3 & 4 & 3 \end{bmatrix} A=⎣⎡123224313⎦⎤
计算过程如下:
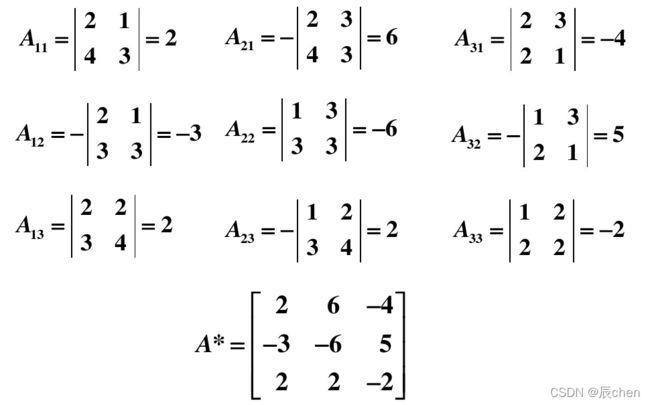
11.2 伴随矩阵定义
设有一矩阵 A A A:
A = [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] A= \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn} \\ \end{bmatrix} A=⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤
设 A i j A_{ij} Aij 是矩阵 A A A 中元素 a i j a_{ij} aij 的代数余子式,那么矩阵 A ∗ A^* A∗:
A ∗ = [ A 11 A 21 ⋯ A n 1 A 12 A 22 ⋯ A n 2 ⋮ ⋮ ⋱ ⋮ A 1 n A 2 n ⋯ A n n ] A^*= \begin{bmatrix} A_{11} & A_{21} & \cdots & A_{n1} \\ A_{12} & A_{22} & \cdots & A_{n2} \\ \vdots & \vdots & \ddots & \vdots \\ A_{1n} & A_{2n} & \cdots & A_{nn} \\ \end{bmatrix} A∗=⎣⎢⎢⎢⎡A11A12⋮A1nA21A22⋮A2n⋯⋯⋱⋯An1An2⋮Ann⎦⎥⎥⎥⎤
称为矩阵 A A A 的 伴随矩阵
11.3 伴随矩阵性质
A A ∗ = A ∗ A = ∣ A ∣ E AA^*=A^*A=|A|E AA∗=A∗A=∣A∣E
A A ∗ = A ∗ A = ∣ A ∣ E AA^*=A^*A=|A|E AA∗=A∗A=∣A∣E
I , E I,E I,E 都表示单位矩阵, ∣ A ∣ |A| ∣A∣ 代表行列式
11.4 伴随矩阵与逆矩阵
A A − 1 = I AA^{-1}=I AA−1=I
A A ∗ = ∣ A ∣ I AA^*=|A|I AA∗=∣A∣I,其中 ∣ A ∣ |A| ∣A∣ 代表行列式
A A A A ∗ ∣ A ∣ \frac{A^*}{|A|} ∣A∣A∗ = I =I =I
根据上式可得:
A − 1 = A^{-1}= A−1= A ∗ ∣ A ∣ \frac{A^*}{|A|} ∣A∣A∗
import numpy as np
# 声明矩阵
A = np.array([
[1, 2, 3],
[2, 2, 1],
[3, 4, 3]])
A_bs = [] # 伴随矩阵
n = 3 # A方阵的行、列数量
for i in range(n):
for j in range(n):
row = [0, 1, 2] # 行索引
col = [0, 1, 2] # 列索引
row.remove(i) # 去除行
col.remove(j) # 去除列
# 代数余子式
A_ij = A[np.ix_(row, col)]
A_bs.append(((-1) ** (i + j)) * np.linalg.det(A_ij))
A_bs = np.array(A_bs).reshape(3, 3).T
print('根据伴随矩阵求逆矩阵:\n', A_bs / np.linalg.det(A))
print('用NumPy模块求逆矩阵:\n', np.linalg.inv(A))
