尚医通项目记录
后台管理系统
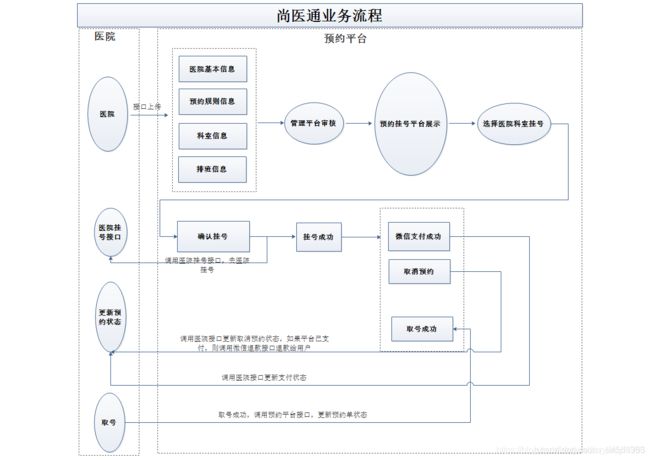
上传医院信息接口
首先实现的是医院基本信息,在后台管理网站上,可以由管理员管理和操作医院的一些信息,如医院名称、联系人、医院编号等

具体技术:
- 整合了swagger作为接口测试
- 封装结果集,使的返回的结果都遵循统一格式。(状态码+信息+数据)
- @RequestBody注解,前端可以用Json格式传数据给后端
- @RestController,采用Restfu风格传递路径和参数
@PostMapping("findPageHospSet/{current}/{limit}")
public Result findPageHospSet(@PathVariable Long current,
@PathVariable Long limit,
@RequestBody(required = false) HospitalSetQueryVo hospitalSetQueryVo)
- @PostMapping、@GetMapping 和 @RequestMapping都一样,用来传递路径和参数(@RequestMapping(method = RequestMethod.GET)就是GetMapping,post同理)
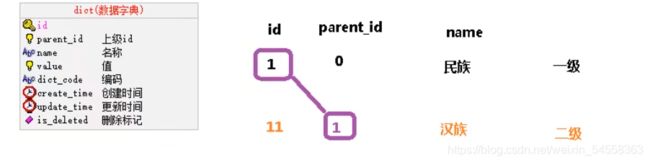
数据字典
一些注解:
- @ComponentScan 的作用就是根据定义的扫描路径,把符合扫描规则的类装配到spring容器中
- @Mapper:在接口类上添加了@Mapper,在编译之后会生成相应的接口实现类(Mapper层就是DAO层,是数据持久化层,写一些数据库语句什么的,在这个项目中因为是MybatisPlus,所以没有写多少sql语句)
- @MapperScan:指定要变成实现类的接口所在的包,然后包下面的所有接口在编译之后都会生成相应的实现类
- @TableField:MybatisPlus中的注解
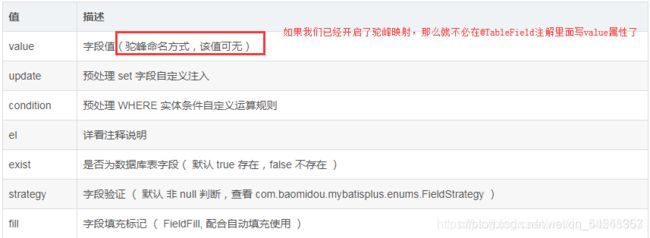
关注exist,当model实体类中存在一个字段(因为elementUI中需要一个“hasChildren”字段),但是数据库表中没有,就可以在实体类中加注解:

表示数据库中没有这个字段
数据字典最终结果:

利用EasyExcel导入和导出数据字典
注意看设置了一些http中的参数
//导出字典数据接口
@Override
public void exportDictData(HttpServletResponse response) {
//设置下载信息
response.setContentType("application/vnd.ms-excel");
response.setCharacterEncoding("utf-8");
String fileName = "dict";
response.setHeader("Content-disposition","attachment:filename="+fileName+".xlsx");
//查询数据库
List<Dict> dictList = baseMapper.selectList(null);
//dict --> dictEeVo
List<DictEeVo> dictEeVoList = new ArrayList<>();
for(Dict dict: dictList){
DictEeVo dictEeVo = new DictEeVo();
BeanUtils.copyProperties(dict,dictEeVo);
dictEeVoList.add(dictEeVo);
}
//调用方法进行写操作
try {
EasyExcel.write(response.getOutputStream(), DictEeVo.class).sheet("dict")
.doWrite(dictEeVoList);
} catch (IOException e) {
e.printStackTrace();
}
}
//导入数据字典
@CacheEvict(value = "dict", allEntries = true) //导入数据后,缓存“dict”中的所有内容清空
@Override
public void importDictData(MultipartFile file) {
try {
EasyExcel.read(file.getInputStream(),DictEeVo.class, new DictListener(baseMapper)).sheet().doRead();
} catch (IOException e) {
e.printStackTrace();
}
}
数据字典缓存
因为数据字典不经常修改,是一些省份和民族信息,所以可以放在缓存里,加快读取速度
redis配置类:
@Configuration
@EnableCaching
public class RedisConfig {
// @EnableCaching:标记注解 @EnableCaching,开启缓存,并配置Redis缓存管理器。
// @EnableCaching 注释触发后置处理器,检查每一个Spring bean 的 public 方法是否存在缓存注解。
// 如果找到这样的一个注释,自动创建一个代理拦截方法调用和处理相应的缓存行为。
/**
* 自定义key规则,自动生成对应规则的key
*
* @return
*/
@Bean
public KeyGenerator keyGenerator() {
return new KeyGenerator() {
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder sb = new StringBuilder();
sb.append(target.getClass().getName());
sb.append(method.getName());
for (Object obj : params) {
sb.append(obj.toString());
}
return sb.toString();
}
};
}
/**
* 设置RedisTemplate规则
*
* @param redisConnectionFactory
* @return
*/
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
//序列号key value
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
/**
* 设置CacheManager缓存规则
*
* @param factory
* @return
*/
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
一些注解:
- @cacheable:只会执行一次,当标记在一个方法上时表示该方法是支持缓存的,Spring会在其被调用后将其返回值缓存起来,以保证下次利用同样的参数来执行该方法时可以直接从缓存中获取结果。
- @cacheput:@CachePut标注的方法在执行前不会去检查缓存中是否存在之前执行过的结果,而是每次都会执行该方法,并将执行结果以键值对的形式存入指定的缓存中。,一般用在添加的方法上
- @CacheEvict是用来标注在需要清除缓存元素的方法或类上的。当标记在一个类上时表示其中所有的方法的执行都会触发缓存的清除操作。
上传科室排班的接口

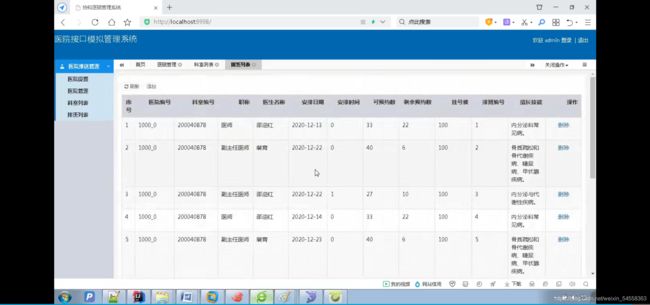
这个接口是对医院的工作人员开放的(本项目中模拟了一个医院的内部网站,医院的管理人员通过这个网站上的接口传递一些信息给我们的后台管理平台)
每个医院本身有自己的系统,通过调用我们给处的接口,可以上传医院信息、科室信息、排班信息到我们的平台上,方便患者查看挂号,同时医院当然也可以查询自己上传的以上信息。
此部分的数据库为mongodb。
MongoDB和MySQL的区别:
MySQL与MongoDB都是开源的常用数据库,但是MySQL是传统的关系型数据库,MongoDB则是非关系型数据库,也叫文档型数据库,是一种NoSQL的数据库。它们各有各的优点,关键是看用在什么地方。所以我们所熟知的那些SQL语句就不适用于MongoDB了,因为SQL语句是关系型数据库的标准语言。
一、关系型数据库-MySQL
1、在不同的引擎上有不同的存储方式。
2、查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。
3、开源数据库的份额在不断增加,mysql的份额页在持续增长。
4、缺点就是在海量数据处理的时候效率会显著变慢。
二、非关系型数据库-MongoDB
非关系型数据库(nosql ),属于文档型数据库。先解释一下文档的数据库,即可以存放xml、json、bson类型系那个的数据。这些数据具备自述性,呈现分层的树状数据结构。数据结构由键值(key=>value)对组成。
1、存储方式:虚拟内存+持久化。
2、查询语句:是独特的MongoDB的查询方式。
3、适合场景:事件的记录,内容管理或者博客平台等等。
4、架构特点:可以通过副本集,以及分片来实现高可用。
5、数据处理:数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写。
6、成熟度与广泛度:新兴数据库,成熟度较低,Nosql数据库中最为接近关系型数据库,比较完善的DB之一,适用人群不断在增长。
三、MongoDB优势与劣势
优势:
1、在适量级的内存的MongoDB的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快。
2、MongoDB的高可用和集群架构拥有十分高的扩展性。
3、在副本集中,当主库遇到问题,无法继续提供服务的时候,副本集将选举一个新的主库继续提供服务。
4、MongoDB的Bson和JSon格式的数据十分适合文档格式的存储与查询。
劣势:
1、 不支持事务操作。MongoDB本身没有自带事务机制,若需要在MongoDB中实现事务机制,需通过一个额外的表,从逻辑上自行实现事务。
2、 应用经验少,由于NoSQL兴起时间短,应用经验相比关系型数据库较少。
3、MongoDB占用空间过大。
管理医院信息
在这个模块中,由于要同时用到不同的service模块(按照现实来说可能是不同服务器上的微服务),需要用到远程调用,这里就用到注册中心,本项目用的是Nacos
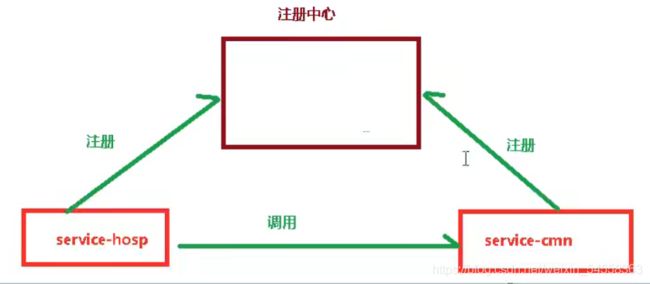
@EnableDiscoveryClient:加在主启动类上,将本服务注册到注册中心中(Nacos、Zookeeper、Consul等),配合properties文件中设置当前服务的地址端口号,就完成了注册
要完成跨服务调用,还需要Feign。feign是声明式的web service客户端,它让微服务之间的调用变得更简单了,类似controller调用service。
SpringbootApplication启动类加上@FeignClient注解,以及@EnableDiscoveryClient。
创建一个借口,加上@FeignClient(value = “service-cmn”) 注解,value后面是已注册服务的名字。声明完为feign client后,其他spring管理的类,如service就可以直接注入使用了
@FeignClient(value = "service-cmn")
@Repository
public interface DictFeignClient {
//根据dictcode和value查询
@GetMapping("/admin/cmn/dict/getName/{dictCode}/{value}")
public String getName(@PathVariable("dictCode") String dictCode, @PathVariable("value") String value);
//根据value查询
@GetMapping("/admin/cmn/dict/getName/{value}")
public String getName(@PathVariable("value") String value);
}
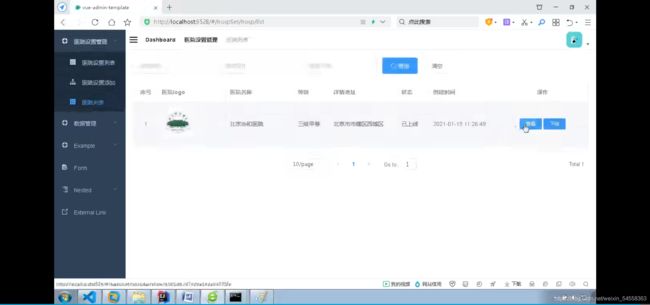
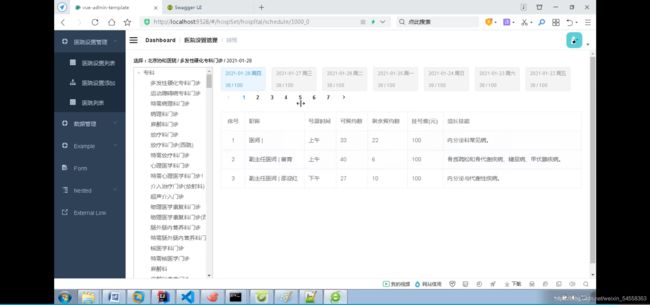
管理排班信息

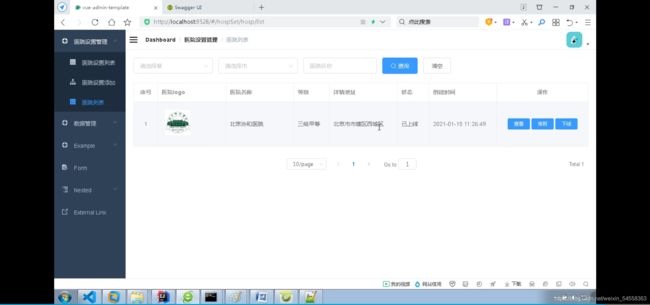
点击排班,会显示排班信息
服务网关
本项目用的是SpringCloud中的GateWay
用户审批用户管理
用户进行实名认证后,在后台可以管理用户和审批用户
前台用户系统
参考北京市统一预约挂号平台
一些简单的功能:如搜索医院名称、点击医院选择科室排班等,就不再赘述。主要讲登陆注册相关的。
登录功能
手机号登录和微信扫码登录
网关过滤器
既然有登录问题,就有权限问题,网站中有部分网址是内部人员才能访问,有些是用户登录后才能访问,还有些是可以直接访问。实现这个功能是用GateWay中的filter,继承GlobalFilter然后重写一些方法即可具体实现代码(在GateWay服务中):
@Component
public class AuthGlobalFilter implements GlobalFilter, Ordered {
private AntPathMatcher antPathMatcher = new AntPathMatcher();
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
String path = request.getURI().getPath();
System.out.println("==="+path);
// 主要是下面这部分代码,处理了权限问题
//内部服务接口,不允许外部访问
if(antPathMatcher.match("/**/inner/**", path)) {
ServerHttpResponse response = exchange.getResponse();
return out(response, ResultCodeEnum.PERMISSION);
}
//api接口,异步请求,校验用户必须登录
if(antPathMatcher.match("/api/**/auth/**", path)) {
Long userId = this.getUserId(request);
if(StringUtils.isEmpty(userId)) {
ServerHttpResponse response = exchange.getResponse();
return out(response, ResultCodeEnum.LOGIN_AUTH);
}
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 0;
}
/**
* api接口鉴权失败返回数据
* @param response
* @return
*/
private Mono<Void> out(ServerHttpResponse response, ResultCodeEnum resultCodeEnum) {
Result result = Result.build(null, resultCodeEnum);
byte[] bits = JSONObject.toJSONString(result).getBytes(StandardCharsets.UTF_8);
DataBuffer buffer = response.bufferFactory().wrap(bits);
//指定编码,否则在浏览器中会中文乱码
response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");
return response.writeWith(Mono.just(buffer));
}
/**
* 获取当前登录用户id
* @param request
* @return
*/
private Long getUserId(ServerHttpRequest request) {
String token = "";
List<String> tokenList = request.getHeaders().get("token");
if(null != tokenList) {
token = tokenList.get(0);
}
if(!StringUtils.isEmpty(token)) {
return JwtHelper.getUserId(token);
}
return null;
}
}
JWT
参考介绍
Json web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其它业务逻辑所必须的声明信息,该token也可直接被用于认证,也可被加密。
本项目用JWT来生成token
OAuth2
官方指南
具体流程在官方指南里面写的很明白了,这里总结一下就是:
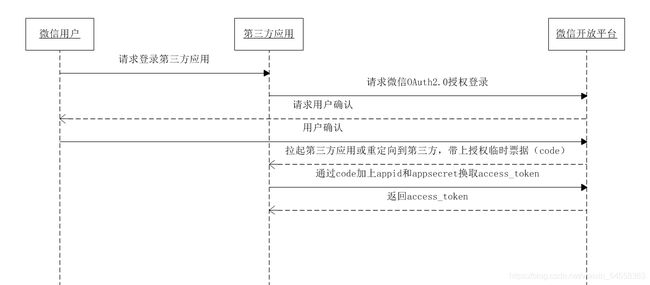
- 第三方发起微信授权登录请求,微信用户允许授权第三方应用后,微信会拉起应用或重定向到第三方网站,并且带上授权临时票据code参数;
- 通过code参数加上AppID和AppSecret等,通过API换取access_token;
- 通过access_token进行接口调用,获取用户基本数据资源或帮助用户实现基本操作。
手机号验证码登录
整合JWT,生成token。
总体流程:
- 用户输入手机号,点击获取验证码
- 阿里云短信服务,给用户发送生成的验证码,同时把验证码放到redis中,设置过期时间。
- 用户收到验证码并输入,服务器拿到并与redis中对应用户的验证码比对。如果不相同抛出异常,如果相同则登录成功
微信扫码登录
微信的开发指南
根据开发指南,填入相应信息传回前端,在前端就可以显示二维码给用户了。
//1 生成微信扫描二维码
//返回生成二维码需要参数
@GetMapping("getLoginParam")
@ResponseBody
public Result genQrConnect() {
try {
Map<String, Object> map = new HashMap<>();
map.put("appid", ConstantWxPropertiesUtils.WX_OPEN_APP_ID);
map.put("scope","snsapi_login");
String wxOpenRedirectUrl = ConstantWxPropertiesUtils.WX_OPEN_REDIRECT_URL;
wxOpenRedirectUrl = URLEncoder.encode(wxOpenRedirectUrl, "utf-8");
map.put("redirect_uri",wxOpenRedirectUrl);
map.put("state",System.currentTimeMillis()+"");
return Result.ok(map);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
return null;
}
}
微信扫码登录成功后,会重定向至手机号验证码登录界面。用户用手机号登录后,如果是第一次登录,会将用户的微信和手机号在数据库中绑定在一起。
上传图片文件到阿里云OSS
实名认证与后台审核
如果没有进行过实名认证,要挂号需要先进行实名认证
管理就诊人(增删改查)
可以用自己的账号给家人挂号
预约挂号详情信息
点击一个科室,显示可预约的挂号信息,点击某个信息显示相关内容
选择科室,预约挂号
如果商品服务和订单服务是两个不同的微服务,在下单的过程中订单服务需要调用商品服务进行扣库存操作。按照传统的方式,下单过程要等到调用完毕之后才能返回下单成功,如果网络产生波动等原因使得商品服务扣库存延迟或失败,就会带来交叉的用户体验。如果在高并发的场景下,这样的处理显然是不合适的,那么如何优化呢?就要使用消息队列
消息队列提供一个异步通信机制,消息的发送者不必一直等到消息被成功处理才返回,而是立即就返回。消息中间件负责处理网络通信,如果网络连接不可用,消息可被暂存于队列之中,当网络畅通的时候将消息转发给相应的程序或服务,当然前提是这些服务订阅了该队列。
在服务之间使用消息中间件,既可以提高并发量,又可以降低服务之间的耦合度
微信扫码下单
这部分模块主要是调用微信的一些服务,不做赘述
值得一提的是,生成的微信二维码放在Redis中,两小时过期