李慧子
R语言是一门功能强大、广受欢迎的数据挖掘类软件。由于工作需要和个人兴趣,本人利用闲暇时间,采用边学习边实践的方法,完成了R语言的快速入门。现将学习过程中归纳的知识点分享给大家,一方面可以让对R还比较陌生的朋友能够迅速了解R语言的整体框架与数据处理流程,另一方面也是为让自己更好地吸收理解。我主要学习参考的是《R语言数据分析与挖掘实战》、《R语言实战》这两本工具书,前者的特色是有丰富的案例研究,而后者更偏向知识点的讲解和梳理。总之各有千秋,可以结合起来学习。相关知识点的思维导图如下:
1、R语言学习的知识框架

2、R语言框架涵盖的知识点
(1)R语言基本知识

R最激动人心的一部分功能是通过可选模块的下载和安装来实现的。目前有5500多个包(package)的用户贡献模块可从http://cran.r-project.org/web/packages下载。这些包提供了横跨各种领域的新功能,包括分析地理数据、处理蛋白质谱等。
库(library):计算机上存储包的目录成为库,函数library()可以显示库中有哪些包。
包的安装:install.packages(“”)
包的载入:library()
包的使用:help(package=“package_name”)可以输出某个包的简短描述以及包中的函数名称和数据集名称的列表。
(2)创建、导入数据集

1.数据类型
①向量:用于存储数值型、字符型或逻辑型数据的一维数组。单个向量中的数据必须拥有相同的数据类型。
创建向量函数:c()
例子:a<-c(1,2,5,3)
②矩阵:一个二维数组,每个元素拥有相同的数据类型。
创建矩阵函数:matrix(vector,nrow,ncol,byrow=logical_value,dimnames=list(,))
例子:y<-matrix(1:20,nrow=5,ncol=4)#创建一个5*4的矩阵#
③数组:与矩阵类似,但是维度可以大于2。
创建数组函数:array()
④数据框:不同的列可以包含不同模式(数值型、字符型等)的数据,是R中最常处理的数据结构。
创建数据框函数:data.frame(col1,col2,col3,…)
⑤因子:变量可归结为名义型、有序型或连续型变量。名义变量和有序变量在R中称为因子。
创建因子函数:factor()
例子:diabetes<-c(“Type1”, “Type2”, “Type1”, “Type1”)
Diabetes<-factor(diabetes)#将此向量存储为(1,2,1,1),并在内部将其关联为1= Type1,2= Type2#
数值型变量可以用levels和labels参数来编码成因子。
⑥列表:对象的有序集合。
列表创建函数:list()
2.导入数据集
读取Excel文件的最好方式,就是在Eexel中将其导出为一个逗号分隔文件(csv)
读取数据函数:read.csv('./data/book3.csv',he=T)
网页上的文字可以使用函数readlines()来下载到一个R的字符向量中,然后使用grep()和gsub()一类的函数处理。对于结构复杂的网页,可以使用RCurl包和XML包来提取信息。
3.数据集的标注
包括为变量名添加描述性标签,以及为类别性变量中的编码添加值标签。
例如:names(patientdata)[2]<-“Age at hospitalization(in years)”#将age重命名为“Age at hospitalization(in years”#
Patientdata$gender<-factor(patientdata$gender,levels=c(1,2),labels=c(“male”, “female”))#创建值标签,1表示男性,2表示女性#
(3)数据探索
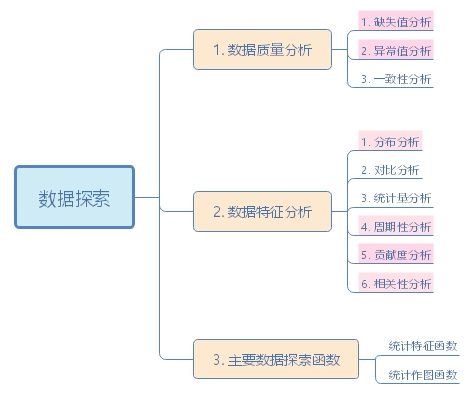
要点归纳
1.数据质量分析

例子:对餐饮销售额数据进行缺失值和异常值分析
编写代码对数据缺失值个数、缺失率以及缺失值所在的位置进行分析。

可以看到缺失值个数输出结果为1,占样本总量的0.497%,缺失值位于第15行,2015年2月14日销量数据缺失。
编写代码绘制箱形图,对数据异常值进行分析。


箭头所示的是一个标准差的区间,可以看出箱形图中超过上下界的8个销售额数据可能为异常值,需要引起注意并结合具体业务分析。
2.数据特征分析
贡献度分析
贡献度分析又称帕累托分析。就餐饮企业来说,应用贡献度分析可以重点改善某菜系盈利最高的前80%的菜品,或者重点发展综合影响最高的80%的部门。这种结果可以通过帕累托图直观地呈现出来。
例子:对餐饮系统对应的菜品盈利数据进行帕累托分析。代码及反馈结果如下


可以发现,菜品A1-A7共7个菜品,占菜品总类数的70%,总盈利约占该月盈利额的85%。根据帕累托原则,应该增加对菜品A1-A7的成本投入,减少对菜品A8-A10的投入以获得更高的盈利额。
(4)数据预处理
在海量原始数据中存在不量不完整、有异常、不一致的数据,在使用前需要进行数据清洗。数据清洗完成后接着进行数据集成、变换、规约等一系列的处理,该过程就是数据预处理。在数据挖掘的过程中,数据预处理工作量占到了整个过程的60%。
数据预处理的主要内容包括数据清理、数据集成、数据变换和数据规约。这里主要对数据清理进行重点标示。

缺失值处理:
1. 删除法
删除行:na.omit()
删除变量:data[,-p]
2. 替换法
数值型变量用均值替换,非数值型变量,则使用其他全部有效观测值的中位数或者众数进行替换。
3. 插补法
回归插补:利用回归模型,将需要插值补缺的变量作为因变量,其他相关变量作为自变量,通过回归函数lm()预测出因变量的值来对缺失变量进行补缺。
多重插补:原理是从一个包含缺失值的数据集中生成一组完整的数据,如此进行多次,从而产生缺失值的一个随机样本,R中的mice函数可以用来进行多重插补。
例子:对某餐厅一段时间的销量表中的缺失值,用均值替换、回归插补、多重插补进行
缺失值插补,将异常值按缺失值处理。
首先对缺失值、异常值进行识别。R语言代码如下:
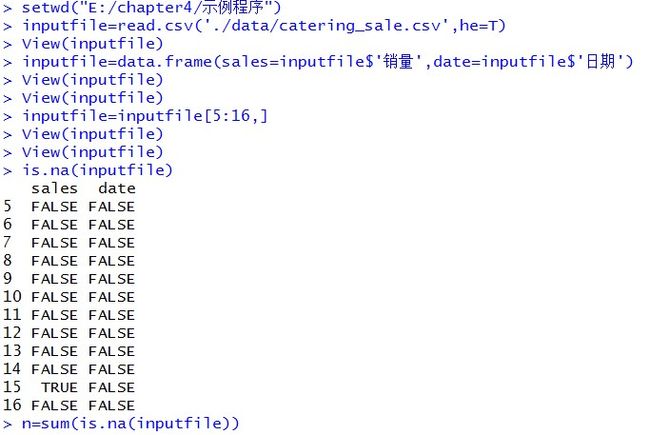
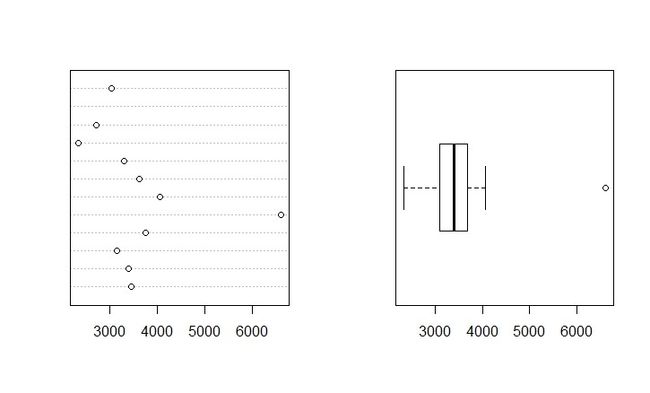
用is.na()函数对缺失值进行识别,从结果可发现第15行销售数据存在缺失。然后继续用单变量散点图和箱形图识别数据中的异常值。R语言代码如下:

R反馈回的结果如下图:
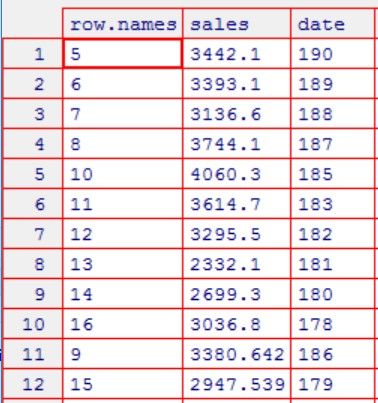
将异常值处理成缺失值。代码如下:
对缺失值进行处理。代码如下:

① 行删除法处理缺失值

处理完数据如下:

② 均值替换法处理缺失值

处理完数据如下:

③ 回归插补法处理缺失值

处理完数据如下:
(5)简单的数据建模

第一篇笔记先写到这哈,感觉R语言涉及的知识面还是挺广的,学习之路还很长。最后,想自己动手操作一番,需要餐饮案例数据的朋友可以私信我。相互促进,交流心得。