词法分析器实现
一、写在前面
编译原理是软件工程的一项基础的课程,是研究软件是什么,为什么可以运行,以及怎么运行的学科,编译系统的改进将会直接对其上层的应用程序的执行效率,执行原理产生深刻的影响。编译原理的目的是将源语言翻译成目标语言。与翻译的区别就是,编译将高级语言编译成低级语言。至于达到什么样的低级语言,在不同的系统中是不同的,对于不同的机器都要用相应的指令系统,编译的目的就是将编译出来的语言用目标机的指令系统执行,一般而言是翻译到汇编语言的层次,但也有特例,比如JVM,Java虚拟机是将高级语言编译到中间语言环节,对于任何的高级语言,都翻译成相同的自己可以识别的中间语言,这样就可以在不同的机型上运行了,这种独特的创意造就了与平台无关的语言识别器——虚拟机的出现,从本质上来说也是用到了编译原理。编译原理的内容非常丰富,技术非常成熟,有着几十年的研究历史,笔者在大学学习《编译原理》的时候,侥幸在最后的期末考试中获得了满分的优异成绩,这样一门内容丰富、逻辑严谨、极度抽象和形式化的课程,笔者是怎么学的呢,无外乎两个字——兴趣。只要有兴趣,任何困难都会显得微不足道!!!转瞬之间,大学已接近尾声,在即将踏出校门的一刻,突然有种什么事情没有完成的感觉,仔细想想,自己在大学学了很多的知识,自己究竟掌握的怎么样了,是不是很好的收集和整理了?想到这里,不觉出了冷汗,因此,在以后的空闲时间就把自己学到的知识,觉得有意思的东西拿出来给大家欣赏,一是为了自己以后记忆,二是为了交流和共享。我一直相信这个时代最伟大的一种变革就是交流和共享,因为有沟通,有彼此的相互了解,相互学习才能打破人类历史几千年来的闭门造车、敝帚自珍,人人都献出一点有用的、精华的信息,随着时代的发展,几十年,上百年之后,文明将会变得更加的璀璨和瑰丽,这个世界将变得更加美好!在这个系列中,我将拿出两个贯穿编译原理的例子来让大家能够比较轻松的理解编译上的问题,一个是词法分析器,另一个是在词法分析的基础上,进行算符优先分析文法的语法分析,并且生成中间代码,执行代码的例子,这两个例子都是本人经过了十来天的编程调试,用C/C++实现的,便于理解,有着很好的学习指导意义!
二、词法分析器的实现
2.1、设计题目:手工设计c语言的词法分析器 (可以是c语言的子集)
2.2、设计内容: 处理c语言源程序,过滤掉无用符号,判断源程序中单词的合法性,并分解出正确的单词,以二元组形式存放在文件中。
2.3、设计目的: 了解高级语言单词的分类,了解状态图以及如何表示并识别单词规则,掌握状态图到识别程序的编程。
2.4、分析与设计
要想手工设计词法分析器,实现C语言子集的识别,就要明白什么是词法分析器,它的功能是什么。词法分析是编译程序进行编译时第一个要进行的任务,主要是对源程序进行编译预处理(去除注释、无用的回车换行找到包含的文件等)之后,对整个源程序进行分解,分解成一个个单词,这些单词有且只有五类,分别是标识符、保留字、常数、运算符、界符。以便为下面的语法分析和语义分析做准备。可以说词法分析面向的对象是单个的字符,目的是把它们组成有效的单词(字符串);而语法的分析则是利用词法分析的结果作为输入来分析是否符合语法规则并且进行语法制导下的语义分析,最后产生四元组(中间代码),进行优化(可有可无)之后最终生成目标代码。可见词法分析是所有后续工作的基础,如果这一步出错,比如明明是‘<=’却被拆分成‘<’和‘=’就会对下文造成不可挽回的影响。因此,在进行词法分析的时候一定要定义好这五种符号的集合。下面是我构造的一个C语言子集。
第一类:标识符 letter(letter | digit) 无穷集*
第二类:常数 (digit)+ 无穷集
第三类:保留字(32)
auto break case char const continue
default do double else enum extern
float for goto if int long
register return short signed sizeof static
struct switch typedef union unsigned void
volatile while
第四类:界符 ‘/’、‘//’、 () { } [ ] " " ' 等
第五类:运算符 <、<=、>、>=、=、+、-、、/、^、等
对所有可数符号进行编码:
< <',50> <#,51> <&,52> <&&,53> <|,54> <||,55> <%,56> <~,57> <<<,58>左移 <>>,59>右移 <[,60> <],61> <{,62> <},63> <\,64> <.,65> <:,67> "[","]","{","}" <常数99 ,数值> <标识符100 ,标识符指针>** 上述二元组中左边是单词的符号,右边为其种别码,其中常数和标识符有点特别,因为是无穷集合,因此常数用自身来表示,种别码为99,标识符用标识符符号表的指针表示(当然也可用自身显示,比较容易观察),种别码100。根据上述约定,一旦见到了种别码syn=63,就唯一确定了‘}’这个单词。 下面是一些变量的约定://全局变量,保留字表 static char reserveWord[32][20] = { "auto", "break", "case", "char", "const", "continue", "default", "do", "double", "else", "enum", "extern", "float", "for", "goto", "if", "int", "long", "register", "return", "short", "signed", "sizeof", "static", "struct", "switch", "typedef", "union", "unsigned", "void", "volatile", "while" }; //界符运算符表,根据需要可以自行增加 static char operatorOrDelimiter[36][10]={ "+","-","*","/","<","<=",">",">=","=","==", "!=",";","(",")","^",",","\"","\'","#","&", "&&","|","||","%","~","<<",">>","[","]","{", "}","\\",".","\?",":","!" }; static char IDentifierTbl[1000][50]={""};//标识符表 char resourceProject[10000];//输入的源程序存放处,最大可以存放10000个字符。 char token[20]={0};//每次扫描的时候存储已经扫描的结果。 int syn=-1;//syn即为种别码,约定‘">’的种别码为0,为整个源程序的结束符号一旦扫描到这个字符代表扫描结束
int pProject = 0;//源程序指针,始终指向当前源程序待扫描位置。
几个重要函数:
//查找保留字,若成功查找,则返回种别码
//否则返回-1,代表查找不成功,即为标识符
int searchReserve(char reserveWord[ ][20], char s[])
/*********************判断是否为字母********************/
bool IsLetter(char letter)
/*****************判断是否为数字************************/
bool IsDigit(char digit)
/********************编译预处理,取出无用的字符和注释**********************/
void filterResource(char r[],int pProject)
/****************************分析子程序,算法核心***********************/
void Scanner(int &syn,char resourceProject[],char token[],int &pProject)
下面说一下整个程序的流程:
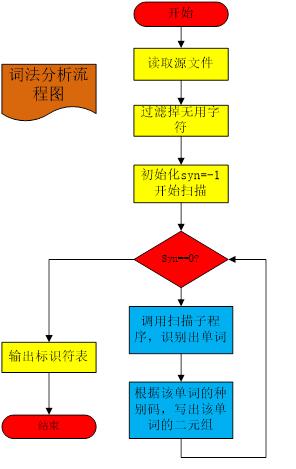
1.词法分析程序打开源文件,读取文件内容,直至遇上’$’文件结束符,然后读取结束。
2.对读取的文件进行预处理,从头到尾进行扫描,去除//和/ /的内容,以及一些无用的、影响程序执行的符号如换行符、回车符、制表符等。但是千万注意不要在这个时候去除空格,因为空格在词法分析中有用,比如说int i=3;这个语句,如果去除空格就变成了“inti=3”,这样就失去了程序的本意,因此不能在这个时候去除空格。
3.选下面就要对源文件从头到尾进行扫描了,从头开始扫描,这个时候扫描程序首先要询问当前的字符是不是空格,若是空格,则继续扫描下一个字符,直至不是空格,然后询问这个字符是不是字母,若是则进行标识符和保留字的识别;若这个字符为数字,则进行数字的判断。否则,依次对这个字符可能的情况进行判断,若是将所有可能都走了一遍还是没有知道它是谁,则认定为错误符号,输出该错误符号,然后结束。每次成功识别了一个单词后,单词都会存在token[ ]中。然后确定这个单词的种别码,最后进行下一个单词的识别。这就是扫描程序进行的工作,可以说这个程序彻底实现了确定有限自动机的某些功能,比如说识别标识符,识别数字等。为了简单起见,这里的数字只是整数。
4.主控程序主要负责对每次识别的种别码syn进行判断,对于不同的单词种别做出不同的反应,如对于标识符则将其插入标识符表中。对于保留字则输出该保留字的种别码和助记符,等等吧。直至遇到syn=0;程序结束。

2.5、流程图
下面是程序的流程图:
2.6、运行与测试
比如说,就拿这个源程序的一部分进行测试:
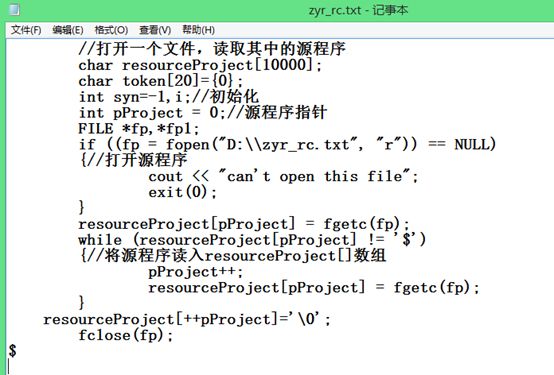
运行程序后结果为:
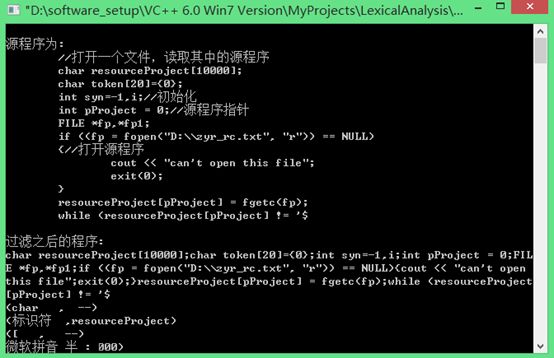
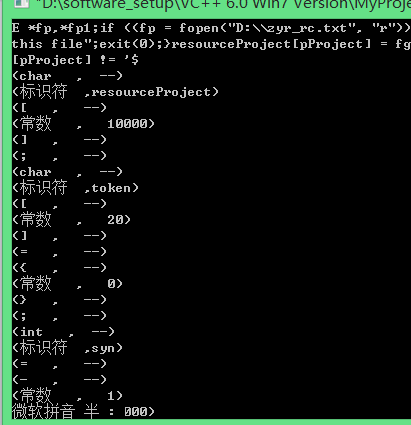
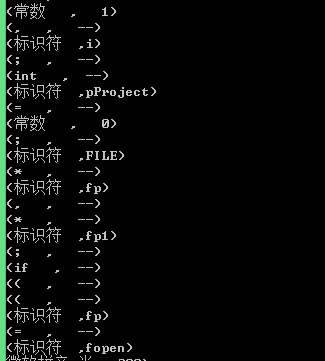
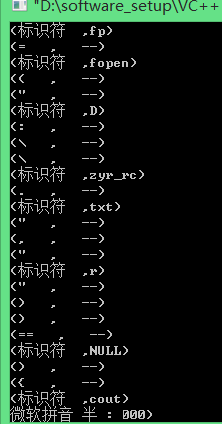


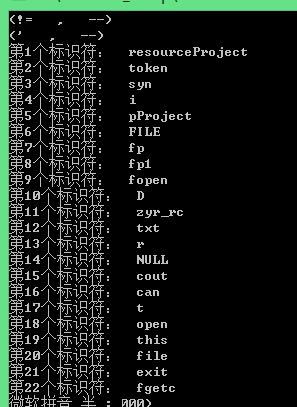
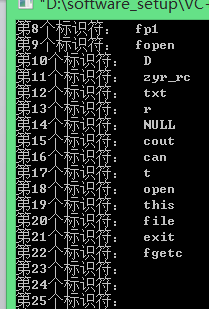
同样单词也写入了文件如下:

。。。
综上分析,达到了预期的结果。
2.7、实验体会
每做一次比较大的实验,都应该写一下实验体会,来加深自己对知识的认识。其实这次的实验,算法部分并不难,只要知道了DFA,这个模块很好写,比较麻烦的就是五种类型的字符个数越多程序就越长。但为了能识别大部分程序,我还是用了比较大的子集,结果花了一下午的功夫才写完,虽然很累吧,但看着这个词法分析器的处理能力,觉得还是值得的。同时也加深了对字符的认识。程序的可读性还算不错。程序没有实现的是对所有复合运算的分离,但原理是相同的,比如“+=“,只需在”+“的逻辑之后向前扫描就行了,因此就没有再加上了。感受最深的是学习编译原理必须要做实验,写程序,这样才会提高自己的动手能力,加深自己对难点的理解,对于以后的求first{},follow{},fisrtVT{},lastVT{}更是应该如此。
2.8、源程序
3 #include "stdio.h"
4 #include "stdlib.h"
5 #include "string.h"
6 #include "iostream"
7 using namespace std; 8 //词法分析程序
9 //首先定义种别码
10 /*
11 第一类:标识符 letter(letter | digit)* 无穷集
12 第二类:常数 (digit)+ 无穷集
13 第三类:保留字(32)
14 auto break case char const continue
15 default do double else enum extern
16 float for goto if int long
17 register return short signed sizeof static
18 struct switch typedef union unsigned void
19 volatile while
20
21 第四类:界符 ‘/*’、‘//’、 () { } [ ] " " '
22 第五类:运算符 <、<=、>、>=、=、+、-、*、/、^、
23
24 对所有可数符号进行编码:
25 <$,0>
26
27 ...
28
29 <+,33>
30 <-,34>
31 <*,35>
32
33 <<,37>
34 <<=,38>
35 <>,39>
36 <>=,40>
37 <=,41>
38 <==,42>
39
40 <;,44>
41 <(,45>
42 <),46>
43 <^,47>
44 <,,48>
45 <",49>
46 <',50>
47 <#,51>
48 <&,52>
49 <&&,53>
50 <|,54>
51 <||,55>
52 <%,56>
53 <~,57>
54 <<<,58>左移
55 <>>,59>右移
56 <[,60>
57 <],61>
58 <{,62>
59 <},63>
60 <\,64>
61 <.,65>
62
63 <:,67>
64
65 "[","]","{","}"
66 <常数99 ,数值>
67 <标识符100 ,标识符指针>
68
69
70 */
71
72 /****************************************************************************************/
73 //全局变量,保留字表
74 static char reserveWord[32][20] = { 75 "auto", "break", "case", "char", "const", "continue",
76 "default", "do", "double", "else", "enum", "extern",
77 "float", "for", "goto", "if", "int", "long",
78 "register", "return", "short", "signed", "sizeof", "static",
79 "struct", "switch", "typedef", "union", "unsigned", "void",
80 "volatile", "while"
81 };
82 //界符运算符表,根据需要可以自行增加
83 static char operatorOrDelimiter[36][10] = { 84 "+", "-", "*", "/", "<", "<=", ">", ">=", "=", "==",
85 "!=", ";", "(", ")", "^", ",", "\"", "\'", "#", "&",
86 "&&", "|", "||", "%", "~", "<<", ">>", "[", "]", "{",
87 "}", "\\", ".", "\?", ":", "!"
88 };
89
90 static char IDentifierTbl[1000][50] = { "" };//标识符表
91 /****************************************************************************************/
92
93 /********查找保留字*****************/
94 int searchReserve(char reserveWord[][20], char s[]) 95 {
96 for (int i = 0; i < 32; i++)
97 {
98 if (strcmp(reserveWord[i], s) == 0)
99 {//若成功查找,则返回种别码
100 return i + 1;//返回种别码
101 } 102 } 103 return -1;//否则返回-1,代表查找不成功,即为标识符
104 } 105 /********查找保留字*****************/
106
107 /*********************判断是否为字母********************/
108 bool IsLetter(char letter) 109 {//注意C语言允许下划线也为标识符的一部分可以放在首部或其他地方
110 if (letter >= 'a'&&letter <= 'z' || letter >= 'A'&&letter <= 'Z'|| letter=='_') 111 { 112 return true; 113 } 114 else
115 { 116 return false; 117 } 118 } 119 /*********************判断是否为字母********************/
120
121
122 /*****************判断是否为数字************************/
123 bool IsDigit(char digit) 124 { 125 if (digit >= '0'&&digit <= '9') 126 { 127 return true; 128 } 129 else
130 { 131 return false; 132 } 133 } 134 /*****************判断是否为数字************************/
135
136
137 /********************编译预处理,取出无用的字符和注释**********************/
138 void filterResource(char r[], int pProject) 139 { 140 char tempString[10000]; 141 int count = 0; 142 for (int i = 0; i <= pProject; i++) 143 { 144 if (r[i] == '/'&&r[i + 1] == '/') 145 {//若为单行注释“//”,则去除注释后面的东西,直至遇到回车换行
146 while (r[i] != '\n') 147 { 148 i++;//向后扫描
149 } 150 } 151 if (r[i] == '/'&&r[i + 1] == '*') 152 {//若为多行注释“/* 。。。*/”则去除该内容
153 i += 2; 154 while (r[i] != '*' || r[i + 1] != '/') 155 { 156 i++;//继续扫描
157 if (r[i] == '/pre>) 158 { 159 printf("注释出错,没有找到 */,程序结束!!!\n"); 160 exit(0); 161 } 162 } 163 i += 2;//跨过“*/”
164 } 165 if (r[i] != '\n'&&r[i] != '\t'&&r[i] != '\v'&&r[i] != '\r') 166 {//若出现无用字符,则过滤;否则加载
167 tempString[count++] = r[i]; 168 } 169 } 170 tempString[count] = '\0'; 171 strcpy(r, tempString);//产生净化之后的源程序
172 } 173 /********************编译预处理,取出无用的字符和注释**********************/
174
175
176 /****************************分析子程序,算法核心***********************/
177 void Scanner(int &syn, char resourceProject[], char token[], int &pProject) 178 {//根据DFA的状态转换图设计
179 int i, count = 0;//count用来做token[]的指示器,收集有用字符
180 char ch;//作为判断使用
181 ch = resourceProject[pProject]; 182 while (ch == ' ') 183 {//过滤空格,防止程序因识别不了空格而结束
184 pProject++; 185 ch = resourceProject[pProject]; 186 } 187 for (i = 0; i<20; i++) 188 {//每次收集前先清零
189 token[i] = '\0'; 190 } 191 if (IsLetter(resourceProject[pProject])) 192 {//开头为字母
193 token[count++] = resourceProject[pProject];//收集
194 pProject++;//下移
195 while (IsLetter(resourceProject[pProject]) || IsDigit(resourceProject[pProject])) 196 {//后跟字母或数字
197 token[count++] = resourceProject[pProject];//收集
198 pProject++;//下移
199 }//多读了一个字符既是下次将要开始的指针位置
200 token[count] = '\0'; 201 syn = searchReserve(reserveWord, token);//查表找到种别码
202 if (syn == -1) 203 {//若不是保留字则是标识符
204 syn = 100;//标识符种别码
205 } 206 return; 207 } 208 else if (IsDigit(resourceProject[pProject])) 209 {//首字符为数字
210 while (IsDigit(resourceProject[pProject])) 211 {//后跟数字
212 token[count++] = resourceProject[pProject];//收集
213 pProject++; 214 }//多读了一个字符既是下次将要开始的指针位置
215 token[count] = '\0'; 216 syn = 99;//常数种别码
217 } 218 else if (ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == ';' || ch == '(' || ch == ')' || ch == '^'
219 || ch == ',' || ch == '\"' || ch == '\'' || ch == '~' || ch == '#' || ch == '%' || ch == '['
220 || ch == ']' || ch == '{' || ch == '}' || ch == '\\' || ch == '.' || ch == '\?' || ch == ':') 221 {//若为运算符或者界符,查表得到结果
222 token[0] = resourceProject[pProject]; 223 token[1] = '\0';//形成单字符串
224 for (i = 0; i<36; i++) 225 {//查运算符界符表
226 if (strcmp(token, operatorOrDelimiter[i]) == 0) 227 { 228 syn = 33 + i;//获得种别码,使用了一点技巧,使之呈线性映射
229 break;//查到即推出
230 } 231 } 232 pProject++;//指针下移,为下一扫描做准备
233 return; 234 } 235 else if (resourceProject[pProject] == '<') 236 {//<,<=,<<
237 pProject++;//后移,超前搜索
238 if (resourceProject[pProject] == '=') 239 { 240 syn = 38; 241 } 242 else if (resourceProject[pProject] == '<') 243 {//左移
244 pProject--; 245 syn = 58; 246 } 247 else
248 { 249 pProject--; 250 syn = 37; 251 } 252 pProject++;//指针下移
253 return; 254 } 255 else if (resourceProject[pProject] == '>') 256 {//>,>=,>>
257 pProject++; 258 if (resourceProject[pProject] == '=') 259 { 260 syn = 40; 261 } 262 else if (resourceProject[pProject] == '>') 263 { 264 syn = 59; 265 } 266 else
267 { 268 pProject--; 269 syn = 39; 270 } 271 pProject++; 272 return; 273 } 274 else if (resourceProject[pProject] == '=') 275 {//=.==
276 pProject++; 277 if (resourceProject[pProject] == '=') 278 { 279 syn = 42; 280 } 281 else
282 { 283 pProject--; 284 syn = 41; 285 } 286 pProject++; 287 return; 288 } 289 else if (resourceProject[pProject] == '!') 290 {//!,!=
291 pProject++; 292 if (resourceProject[pProject] == '=') 293 { 294 syn = 43; 295 } 296 else
297 { 298 syn = 68; 299 pProject--; 300 } 301 pProject++; 302 return; 303 } 304 else if (resourceProject[pProject] == '&') 305 {//&,&&
306 pProject++; 307 if (resourceProject[pProject] == '&') 308 { 309 syn = 53; 310 } 311 else
312 { 313 pProject--; 314 syn = 52; 315 } 316 pProject++; 317 return; 318 } 319 else if (resourceProject[pProject] == '|') 320 {//|,||
321 pProject++; 322 if (resourceProject[pProject] == '|') 323 { 324 syn = 55; 325 } 326 else
327 { 328 pProject--; 329 syn = 54; 330 } 331 pProject++; 332 return; 333 } 334 else if (resourceProject[pProject] == '/pre>) 335 {//结束符
336 syn = 0;//种别码为0
337 } 338 else
339 {//不能被以上词法分析识别,则出错。
340 printf("error:there is no exist %c \n", ch); 341 exit(0); 342 } 343 } 344
345
346 int main() 347 { 348 //打开一个文件,读取其中的源程序
349 char resourceProject[10000]; 350 char token[20] = { 0 }; 351 int syn = -1, i;//初始化
352 int pProject = 0;//源程序指针
353 FILE *fp, *fp1; 354 if ((fp = fopen("D:\\zyr_rc.txt", "r")) == NULL) 355 {//打开源程序
356 cout << "can't open this file"; 357 exit(0); 358 } 359 resourceProject[pProject] = fgetc(fp); 360 while (resourceProject[pProject] != '/pre>) 361 {//将源程序读入resourceProject[]数组
362 pProject++; 363 resourceProject[pProject] = fgetc(fp); 364 } 365 resourceProject[++pProject] = '\0'; 366 fclose(fp); 367 cout << endl << "源程序为:" << endl; 368 cout << resourceProject << endl; 369 //对源程序进行过滤
370 filterResource(resourceProject, pProject); 371 cout << endl << "过滤之后的程序:" << endl; 372 cout << resourceProject << endl; 373 pProject = 0;//从头开始读
374
375 if ((fp1 = fopen("D:\\zyr_compile.txt", "w+")) == NULL) 376 {//打开源程序
377 cout << "can't open this file"; 378 exit(0); 379 } 380 while (syn != 0) 381 { 382 //启动扫描
383 Scanner(syn, resourceProject, token, pProject); 384 if (syn == 100) 385 {//标识符
386 for (i = 0; i<1000; i++) 387 {//插入标识符表中
388 if (strcmp(IDentifierTbl[i], token) == 0) 389 {//已在表中
390 break; 391 } 392 if (strcmp(IDentifierTbl[i], "") == 0) 393 {//查找空间
394 strcpy(IDentifierTbl[i], token); 395 break; 396 } 397 } 398 printf("(标识符 ,%s)\n", token); 399 fprintf(fp1, "(标识符 ,%s)\n", token); 400 } 401 else if (syn >= 1 && syn <= 32) 402 {//保留字
403 printf("(%s , --)\n", reserveWord[syn - 1]); 404 fprintf(fp1, "(%s , --)\n", reserveWord[syn - 1]); 405 } 406 else if (syn == 99) 407 {//const 常数
408 printf("(常数 , %s)\n", token); 409 fprintf(fp1, "(常数 , %s)\n", token); 410 } 411 else if (syn >= 33 && syn <= 68) 412 { 413 printf("(%s , --)\n", operatorOrDelimiter[syn - 33]); 414 fprintf(fp1, "(%s , --)\n", operatorOrDelimiter[syn - 33]); 415 } 416 } 417 for (i = 0; i<100; i++) 418 {//插入标识符表中
419 printf("第%d个标识符: %s\n", i + 1, IDentifierTbl[i]); 420 fprintf(fp1, "第%d个标识符: %s\n", i + 1, IDentifierTbl[i]); 421 } 422 fclose(fp1); 423 return 0; 424 }