- 舔狗舔到最后,她又丢钱又丢命全集章节小说免费阅读完整版(沈熹微赵庭深)-舔狗舔到最后,她又丢钱又丢命小说免费阅读
一米文库2
舔狗舔到最后,她又丢钱又丢命全集章节小说免费阅读完整版(沈熹微赵庭深)-舔狗舔到最后,她又丢钱又丢命小说免费阅读主角配角:沈熹微赵庭深小说别名:舔狗舔到最后,她又丢钱又丢命简介:孟清然这会儿趴在桌上,被一群人众星捧月的围着。她胃痛,大家都在关心她。最关心她的人,当然是裴云霄。他是孟清然的男朋友。每次考试排名,第一第二都是他俩,裴云霄对其它人冷淡,对孟清然很好。正文:孟清然这会儿趴在桌上,被一群人众
- Java中HashMap的实现原理详解
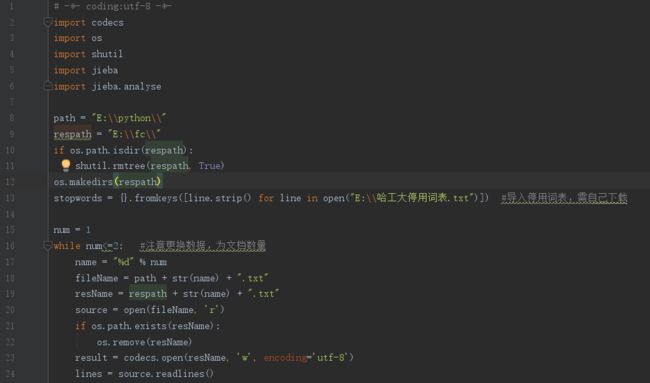
HashMap是Java集合框架中的核心类,基于哈希表实现键值对(Key-Value)存储,提供O(1)时间复杂度的快速查找。以下从数据结构、哈希机制、冲突解决、扩容策略等角度详细解析其实现原理(基于Java8)。一、核心数据结构:数组+链表+红黑树transientNode[]table;//哈希桶数组staticclassNode{//链表节点finalinthash;finalKkey;Vv
- Haproxy七层代理
陈小铃子
学习运维linux
一、负载均衡核心概念它本质上是一种反向代理技术,通过硬件或软件设备,将来自客户端的请求智能地分发到后端的多台服务器上。这样做的主要目的是:提高并发处理能力:避免单台服务器过载,提升整体服务的吞吐量。保证高可用性:当某台后端服务器发生故障时,负载均衡器可以将流量自动切换到健康的机器上,确保服务不中断。便于水平扩展:可以根据业务量增长,方便地增加后端服务器数量,实现弹性伸缩,且对用户透明。二、使用负载
- Nmap --- Ingreslock后门漏洞
唯师默蓝
目的:利用telnet连接目标主机的1524端口,直接获取root权限;原理:Ingreslock后门程序运行在1524端口,连接到1524端口就能直接获得root权限,经常用于入侵一个暴露的服务器;步骤:nmap-sV192.168.1.3,扫描目标主机端口,发现目标主机开启了1524端口;telnet192.168.1.31524连接目标主机并直接成功,在渗透进的主机中,输入whoami,查看
- 拉姆达表达式(Lambda Expressions)
xwdpepsi
C#.netlambdaclass编译器
让我们先看一个简单的拉姆达表达式:x=>x/2这个表达式的意思是:x为参数,对x进行相应的操作后的结果作为返回值。通过这个拉姆达表达式,我们可以看到:这个表达式没有任何类型信息,但这并不代表拉姆达表达式是和类型无关的。在实际运用上,编译器会根据表达式的上下文判断上述x的类型及返回值的类型。例如:usingSystem;usingSystem.Linq;publicclassLambdaTest{s
- 今天是父亲节,想写写我老爸
徐童歌
我从小父母离异,大三快毕业的时候我爸才跟现在的妈妈重组家庭。虽然跟着爷爷奶奶长大,但心底最亲的人还是我老爸。我人生中很多的价值观都受到我老爸很大的影响。特别是读书这件事,长大后也因为阅读受益颇多,人生路上面临困难不想与人说的时候都是书籍帮我走出来的。从小我爸就告诉我,有兴趣才能做好,对人要宽容大度,我一直都记在心里没有忘记,这些好品格也帮助了我很多。我老爸说,他向往的老年生活是一座小院,一个凉亭,
- Valentino耳饰怎么买便宜?便宜又好看女生耳钉在哪买
直返APP拼多多优惠券
在时尚的世界里,Valentino耳饰以其独特的设计和精湛的工艺,成为了众多时尚爱好者追捧的焦点。今天,让我们一同来领略Valentino耳饰的魅力所在。Valentino耳饰是对优雅与时尚的完美诠释。每一款耳饰都仿佛是一件艺术品,精心雕琢,细节之处尽显匠心。从华丽的宝石镶嵌到精致的金属纹理,每一个元素都在诉说着品牌的奢华与独特。戴上Valentino耳饰,瞬间便能提升整体造型的档次与气质。无论是
- 《财务自由之路》2
拥有俩娃的少女妈
图片发自App二、责任意味着什么1、你并非要对所有的事情负责,但你总是要在个人范畴内对自己对时间的判断和反映负责,这听起来简单,但做起来很不容易。并不是发生在我们身上的事情让我们痛苦,而是我们对待事情的反应。2、责任的意思就是有技巧地进行回应。你把责任给了谁,也就给了他权力。你要问自己,我们想要自己掌控将来事态的发展,还是让我们的错误以及其后果掌握将来的事态?3、拓宽你的可控领域A、可控领域,指的
- 中原焦点团队分享网初31期 李丽 坚持第26天 2021.11.6
遇见_afaf
创造成功经验——让孩子重获信心1.相信一个小小的改变会带来大变化,达到滴水穿石的效果。就像平时我们所说的多米诺骨牌效应一样,我们要关注的就是孩子那一点点的成功经验,让他不断的增加体验,就会有大的变化。2.“再保证”指的是我们对孩子表达:不管发生什么事,我都会爱你这个人,也许你的行为需要修正,但我不会因为你的行为不喜欢你。让孩子感受到不管发生什么事儿,父母永远都爱他,不管发生什么事儿,父母永远都会陪
- 2023-03-21 硬拉天花板
我是小胡胡123
在感叹人类对生命敬畏的同时,作为普通人我们需要安全健身。硬拉名人榜,你的硬拉多重,就来对号入座:硬拉35kg,刚来健身房拍照发朋友圈的软妹子硬拉50kg,糖果超甜、吃个桃桃、小鲜肉硬拉70-80kg,中国男性平均水平硬拉90kg,我要努力健身,我要成为一个猛男,要猛!硬拉100kg,我会和同事、同学、朋友说我是一个健身爱好者,我不吃蛋白粉。最近很火的PT华哥挑战是单手徒手硬拉100kg哑铃,这个对
- 使用Meteor构建实时仪表板的完整指南
杏花朵朵
Meteor实时仪表板Vue组件路由设置集合集成
背景简介随着现代Web应用对实时性和响应性的要求不断提高,开发人员需要使用强大的框架来构建能够满足这些需求的应用程序。Meteor作为一个全栈JavaScript框架,提供了一种快速开发实时Web应用的方法。本文将通过构建一个实时仪表板项目,详细探讨Meteor的特点和使用方法。Meteor简介Meteor是一个全栈JavaScript框架,用于构建Web应用程序。它的主要元素包括Web客户端、基
- 向内存在宣言
永延一号
我的存在,约束着自己。身份,社会身份、职业身份、亲族身份;一层一层,一块一块。所有别的人,包括这个社会的整体,都在用自己的声音说,“对,那就是你”。这些约束我们自身的,就是我们所认可的存在,甚至是追求的,伸出手说,“我要的更多”,更多的存在;最想要的,就是改变那些所有人的“对,那就是你”。这个存在是向外的存在,忽略了内在,忽略了时间。我们发现,自身最愉悦的时候,眼睛是亮的。不好意思,我又要提到眼睛
- Git小白 的正确使用姿势与最佳实践
-睡到自然醒~
gitelasticsearch大数据golang开发语言后端python
Git是由Linux之父LinusTorvalds在2005年创造的,目的是为了管理Linux内核的开发。Git的设计目标是实现高效的分支和合并,以及对大型项目的快速处理。1.安装Git要开始使用Git,你需要先安装Git的客户端软件。你可以从官方网站下载适合你的操作系统的安装包,或者使用你的包管理器来安装。例如,在Windows系统上,你可以下载并运行GitforWindows的安装程序。安装完
- 关于Go语言的底层,Slice,map
-睡到自然醒~
golang开发语言后端ginspringboot
1SliceSlice底层实现原理切片是基于数组实现的,它的底层是数组,它自己本身非常小,可以理解为对底层数组的抽象。因为基于数组实现,所以它的底层的内存是连续分配的,效率非常高,还可以通过索引获得数据,可以迭代以及垃圾回收优化。切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内。切片本身是一个只读对象,其工作机制类似数组指针
- 【沧海行系列】鬼域行——第十六章 乱琼碎玉
沧海行人
而我最不喜欢阴阳分明的东西了。要知道阴在阳之内,不在阳之对。我们要充分利用自己的优势,打入敌营陇南地界,早早就有人准备好了酒菜等候何平等人。为首的人回报道:“何长老,我等追查了很久,没有黄长老的痕迹啊。”何平听了,心里已经有九成把握听到的是这个回答了,但她还是叹了口气去,又问道:“上次那妖女的事可曾继续扩散?”那人又说:“这事奇就奇在这,眼下不知是什么人,平息了流言,如今知道那女子身有鉴空遗书的人
- 如何使用Ansible一键部署MinIO集群?
由于测试环境资源有限,本文旨在利用ansible实现4节点单硬盘MinIO集群一键部署。多节点多硬盘在MINIO_VOLUMES环境变量指定多个驱动器路径就行了,没啥区别。hosts文件定义[root@ansibleansible]#catinventory/hosts[all:vars]#ansible_ssh_pass:主机密码#ansible_user:主机账号ansible_become=
- 大模型微调技术的详细解析及对比
老兵发新帖
人工智能大数据
以下是四种主流大模型微调技术的详细解析及对比,结合技术原理、适用场景与性能表现进行说明:1.Full-tuning(全量微调)核心原理:加载预训练模型的所有参数,用特定任务数据(通常为指令-回答对)继续训练,更新全部权重。相当于对模型整体知识结构进行重构。操作流程:加载预训练模型;用任务数据集(如分类文本)和优化目标(如最小化误差)训练;所有参数参与梯度更新。优势:模型充分学习任务特征,效果通常最
- 如何使用React Native与Meteor集成:一个全面指南
如何使用ReactNative与Meteor集成:一个全面指南项目介绍react-native-meteor是一个强大的开源项目,它允许开发者无缝地将ReactNative应用程序与Meteor后端连接起来。此库让你能够充分利用Meteor特有的功能,如自动化的账户系统、响应式数据追踪等,为你的移动应用带来无与伦比的开发体验。通过结合ReactNative的强大UI能力和Meteor的实时Web框
- 学习安静地呆着
和语
原创分享第713天周四我们是一个多么喜欢热闹的民族啊!热热闹闹过大年!欢欢喜喜迎新年!走街串巷去拜年!串门子!赶庙会!旅游!聚会喝酒!聚堆打麻将……一切我们喜欢和习惯的过年方式都因为一场突如其来的疫情改变了!大家都只能乖乖地呆在家里!这样的生活方式对我们来说是一种挑战!很多人都特别不适应!一家人团聚在一起,互相聊聊天,读读书,互相陪伴,这些平时期待的事情,反而觉得不重要了!越不让出去,越想出去……
- 【无标题】Python---day9 模块化编程概念(模块、包、导入)及常见系统模块总结和第三方模块管理
AnAn__kang
pythonjava服务器
系列文章目录前言跟着博主学Python,今天我们来到了第九天的学习,模块化编程的概念。Python作为一门编程语言,本身就是用于对模块以及各种包的使用来达到我们自己想到创作的目的。所以今天博主就给大家盘点一下有关于各种常见的包以及如何进行导入的。一.模块Module,模块1.1基本概念定义:模块是一个Python文件,每个.py.py.py文件就是一个模块。作用:用于组织代码,避免代码重复,提高复
- 中国历史上的大奸大恶,秦始皇的近臣赵高,如何致秦朝15载而亡?
百途美BatonMe
秦始皇统一天下,结束了各诸侯国间的长期混战,迎合了“分久必合”的历史发展大趋势;然而,为了加强咸阳朝堂对全国的控制,秦帝国刚建立不久便要大兴土木。修长城、修直道、修驰道、修六国宫殿群和举办各种盛大典礼,如此的耗费巨大成为了民生不可承受之重,令这个新生的帝国很快就危机四伏了。秦始皇崩于第五次大巡狩,秦帝国局势波谲云诡秦始皇最后一次大巡狩的行进路线队伍行至今山东平原县时,秦始皇突然一病不起,病势急转直
- 【无标题】迭代器和生成器的区别及其各自实现方式和使用场景
AnAn__kang
python机器学习开发语言
系列文章目录前言小伙伴们,今天我们将进入迭代器和生成器的使用,这俩个呢对我们处理信息的时候帮助是非常大的。对于我们的电脑将减轻负重,不至于内存的损耗过大。未来我们在训练模型处理数据时,会频繁的使用生成器。一,迭代器Iterator迭代器提供了一种惰性(lazyevaluation)获取数据的方法,使得我们能够逐步访问序列中的元素,而无需一次性加载所有数据。其主要优点包括节省内存、提高性能、支持自定
- 观《哪吒》有感
李婷_3746
昨天乘培训结束时得来的来之不易的下午,和三个小伙伴去看了一场很热门的电影——《哪吒》,很感动,很震撼。影片主要讲述了魔丸出身的哪吒是如何一步一步在父母的引导下与命运做斗争,最终成为了一个有情有义、有血有肉、有奉献和担当的生命体的过程。看完整个影片,我感动于三个点:一、一命换一命的亲情可以唤醒一个人心底里最善良的良知父母为了哪吒愿意与整个村庄站在对立面,为了在孩子的生日宴会上澄清对孩子的误解和让孩子
- 74.不要害怕困难,有困难是好事,否则就谈不上对青少年进行思想教育
高个大瘦子
74.不要害怕困难,有困难是好事,否则就谈不上对青少年进行思想教育打卡时间:3月31日-4月1日1.让孩子经历克服困难的过程对他们的成长有什么益处?克服困难的过程,能培养英勇无畏的精神,陶冶人的高尚情操。在克服困难的过程中,人的心灵对别人、对善良不会变得冷酷,恰恰相反,变得温厚、富有同情心,而对邪恶则变得毫不妥协、毫不留情。2.文中特别提到了对要把小伙子们培养成英勇无畏、坚忍不拔的人,作者是怎样去
- Claude Code & Kimi K2 环境配置指南 (Windows/macOS/Ubuntu)
ClaudeCode&KimiK2环境配置指南(Windows/macOS/Ubuntu)本指南将引导您完成安装和配置ClaudeCode和KimiK2的所有必要步骤,以利用KimiK2API的强大功能。第一步:安装Node.js和Git在开始之前,您的系统需要安装好Node.js和Git。1.Node.js下载与安装:请前往Node.js官方网站下载并安装最新版本的Node.js(建议使用v18
- 生命3.0时代,面对人工智能时代的到来,我们可以做些什么
笃定的沙丁鱼
生命的定义生命的定义有很多,最为人所熟知的是在生物学上的定义,即生命是蛋白质存在的一种形式。但是,这种定义可能不太适用于未来的智能机器和外星文明,我们不能将我们对未来生命的思考局限在过去遇到过的物种,所以需要将生命定义得更广阔一些:生命是一个能保持自身复杂性并能进行复制的过程。复制的对象并不是由原子组成的物质,而是能阐明原子是如何排列的信息,这种信息由比特组成。换句话说:我们可以将生命看作一种自我
- 数据库范式设计
浪人与酒丶
@[TOC]导语在日常工作中,我们都需要遵守一定的规范,比如签到大卡、审批流程等,这些规范虽然有一定等约束感觉,却是非常有必要等,这样可以保证正确性和严谨性,但有些情况下,约束反而会带来效率的下降,比如一个可以直接操作的任务,却需要审批才能执行。数据库的设计范式我们在设计关系型数据库模型的时候,需要对关系内部各个属性之间联系对合理化程度进行定义,这就有了不同等级的规范要求,这些规范要求被称为范式(
- 2023-08-08
安得争渡
以高质量“纪检监察”答卷推动经济社会高质量发展围绕中心才能找准方向,服务大局才能体现价值。纪检监察机关作为党内的“纪律部队”,担负着保证党的政治纲领和政治目标实现的重大责任,必须始终把各项工作置于党的工作大局中去思考推进。省委十二届三次全会是系统谋划四川经济社会发展的一次重要会议,对四川未来发展有着深远战略考量和重大现实意义。必须找准服务中心大局的切入点、着力点,忠诚履职,既督又战,充分发挥监督保
- 北洋十八载之第一百四十五回 逆水行舟
林墨臻
对曹锟这番骚操作,大吴碍于情面,虽然嘴上没说,心里却是很不满意。看来三爷也就只能混到这地步了,想想人家朱重八,实力足以称王称霸,可为了达到更高的人生目标,人家是忍着,让着,等着。直到把大半个中国收入囊中,天下再无齐头并行者,才舒舒服服的坐上头把交椅。你三爷也不好好看看周围环境,没错,咱直隶现在确实是民国这盘棋里唯一的超级霸主,可周边的那些也不好惹啊。胡子张仗着背后有日本这个超级奶妈,那是忙着修桥铺
- 对信任你的人,永远别撒谎,对你撒谎的人,永远别信任(分享)
静待花开jl
图片发自App对信任你的人,永远别撒谎,对你撒谎的人永远别信任。一些时间,总会看清一些事,一些事情,总会看清一些人,我们总以为真心对人,也可以换来别人的真心对待,拚了命不让身边的人难过,可后来却发现受伤的是自己。永远不要企望别人都与你相同,我们只需坦坦荡荡,问心无愧。人心有真假,时间能见证;感情有冷暖,风雨能考验。岁月,留不住虚幻的拥有。体会到缘分善变;平淡无语,感受了人情冷暖。有心的人,不管你在
- 解读Servlet原理篇二---GenericServlet与HttpServlet
周凡杨
javaHttpServlet源理GenericService源码
在上一篇《解读Servlet原理篇一》中提到,要实现javax.servlet.Servlet接口(即写自己的Servlet应用),你可以写一个继承自javax.servlet.GenericServletr的generic Servlet ,也可以写一个继承自java.servlet.http.HttpServlet的HTTP Servlet(这就是为什么我们自定义的Servlet通常是exte
- MySQL性能优化
bijian1013
数据库mysql
性能优化是通过某些有效的方法来提高MySQL的运行速度,减少占用的磁盘空间。性能优化包含很多方面,例如优化查询速度,优化更新速度和优化MySQL服务器等。本文介绍方法的主要有:
a.优化查询
b.优化数据库结构
- ThreadPool定时重试
dai_lm
javaThreadPoolthreadtimertimertask
项目需要当某事件触发时,执行http请求任务,失败时需要有重试机制,并根据失败次数的增加,重试间隔也相应增加,任务可能并发。
由于是耗时任务,首先考虑的就是用线程来实现,并且为了节约资源,因而选择线程池。
为了解决不定间隔的重试,选择Timer和TimerTask来完成
package threadpool;
public class ThreadPoolTest {
- Oracle 查看数据库的连接情况
周凡杨
sqloracle 连接
首先要说的是,不同版本数据库提供的系统表会有不同,你可以根据数据字典查看该版本数据库所提供的表。
select * from dict where table_name like '%SESSION%';
就可以查出一些表,然后根据这些表就可以获得会话信息
select sid,serial#,status,username,schemaname,osuser,terminal,ma
- 类的继承
朱辉辉33
java
类的继承可以提高代码的重用行,减少冗余代码;还能提高代码的扩展性。Java继承的关键字是extends
格式:public class 类名(子类)extends 类名(父类){ }
子类可以继承到父类所有的属性和普通方法,但不能继承构造方法。且子类可以直接使用父类的public和
protected属性,但要使用private属性仍需通过调用。
子类的方法可以重写,但必须和父类的返回值类
- android 悬浮窗特效
肆无忌惮_
android
最近在开发项目的时候需要做一个悬浮层的动画,类似于支付宝掉钱动画。但是区别在于,需求是浮出一个窗口,之后边缩放边位移至屏幕右下角标签处。效果图如下:
一开始考虑用自定义View来做。后来发现开线程让其移动很卡,ListView+动画也没法精确定位到目标点。
后来想利用Dialog的dismiss动画来完成。
自定义一个Dialog后,在styl
- hadoop伪分布式搭建
林鹤霄
hadoop
要修改4个文件 1: vim hadoop-env.sh 第九行 2: vim core-site.xml <configuration> &n
- gdb调试命令
aigo
gdb
原文:http://blog.csdn.net/hanchaoman/article/details/5517362
一、GDB常用命令简介
r run 运行.程序还没有运行前使用 c cuntinue
- Socket编程的HelloWorld实例
alleni123
socket
public class Client
{
public static void main(String[] args)
{
Client c=new Client();
c.receiveMessage();
}
public void receiveMessage(){
Socket s=null;
BufferedRea
- 线程同步和异步
百合不是茶
线程同步异步
多线程和同步 : 如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B依言执行,再将结果给A;A再继续操作。 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回,同时其它线程也不能调用这个方法
多线程和异步:多线程可以做不同的事情,涉及到线程通知
&
- JSP中文乱码分析
bijian1013
javajsp中文乱码
在JSP的开发过程中,经常出现中文乱码的问题。
首先了解一下Java中文问题的由来:
Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,
- js实现页面跳转重定向的几种方式
bijian1013
JavaScript重定向
js实现页面跳转重定向有如下几种方式:
一.window.location.href
<script language="javascript"type="text/javascript">
window.location.href="http://www.baidu.c
- 【Struts2三】Struts2 Action转发类型
bit1129
struts2
在【Struts2一】 Struts Hello World http://bit1129.iteye.com/blog/2109365中配置了一个简单的Action,配置如下
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configurat
- 【HBase十一】Java API操作HBase
bit1129
hbase
Admin类的主要方法注释:
1. 创建表
/**
* Creates a new table. Synchronous operation.
*
* @param desc table descriptor for table
* @throws IllegalArgumentException if the table name is res
- nginx gzip
ronin47
nginx gzip
Nginx GZip 压缩
Nginx GZip 模块文档详见:http://wiki.nginx.org/HttpGzipModule
常用配置片段如下:
gzip on; gzip_comp_level 2; # 压缩比例,比例越大,压缩时间越长。默认是1 gzip_types text/css text/javascript; # 哪些文件可以被压缩 gzip_disable &q
- java-7.微软亚院之编程判断俩个链表是否相交 给出俩个单向链表的头指针,比如 h1 , h2 ,判断这俩个链表是否相交
bylijinnan
java
public class LinkListTest {
/**
* we deal with two main missions:
*
* A.
* 1.we create two joined-List(both have no loop)
* 2.whether list1 and list2 join
* 3.print the join
- Spring源码学习-JdbcTemplate batchUpdate批量操作
bylijinnan
javaspring
Spring JdbcTemplate的batch操作最后还是利用了JDBC提供的方法,Spring只是做了一下改造和封装
JDBC的batch操作:
String sql = "INSERT INTO CUSTOMER " +
"(CUST_ID, NAME, AGE) VALUES (?, ?, ?)";
- [JWFD开源工作流]大规模拓扑矩阵存储结构最新进展
comsci
工作流
生成和创建类已经完成,构造一个100万个元素的矩阵模型,存储空间只有11M大,请大家参考我在博客园上面的文档"构造下一代工作流存储结构的尝试",更加相信的设计和代码将陆续推出.........
竞争对手的能力也很强.......,我相信..你们一定能够先于我们推出大规模拓扑扫描和分析系统的....
- base64编码和url编码
cuityang
base64url
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.io.UnsupportedEncodingException;
- web应用集群Session保持
dalan_123
session
关于使用 memcached 或redis 存储 session ,以及使用 terracotta 服务器共享。建议使用 redis,不仅仅因为它可以将缓存的内容持久化,还因为它支持的单个对象比较大,而且数据类型丰富,不只是缓存 session,还可以做其他用途,一举几得啊。1、使用 filter 方法存储这种方法比较推荐,因为它的服务器使用范围比较多,不仅限于tomcat ,而且实现的原理比较简
- Yii 框架里数据库操作详解-[增加、查询、更新、删除的方法 'AR模式']
dcj3sjt126com
数据库
public function getMinLimit () { $sql = "..."; $result = yii::app()->db->createCo
- solr StatsComponent(聚合统计)
eksliang
solr聚合查询solr stats
StatsComponent
转载请出自出处:http://eksliang.iteye.com/blog/2169134
http://eksliang.iteye.com/ 一、概述
Solr可以利用StatsComponent 实现数据库的聚合统计查询,也就是min、max、avg、count、sum的功能
二、参数
- 百度一道面试题
greemranqq
位运算百度面试寻找奇数算法bitmap 算法
那天看朋友提了一个百度面试的题目:怎么找出{1,1,2,3,3,4,4,4,5,5,5,5} 找出出现次数为奇数的数字.
我这里复制的是原话,当然顺序是不一定的,很多拿到题目第一反应就是用map,当然可以解决,但是效率不高。
还有人觉得应该用算法xxx,我是没想到用啥算法好...!
还有觉得应该先排序...
还有觉
- Spring之在开发中使用SpringJDBC
ihuning
spring
在实际开发中使用SpringJDBC有两种方式:
1. 在Dao中添加属性JdbcTemplate并用Spring注入;
JdbcTemplate类被设计成为线程安全的,所以可以在IOC 容器中声明它的单个实例,并将这个实例注入到所有的 DAO 实例中。JdbcTemplate也利用了Java 1.5 的特定(自动装箱,泛型,可变长度
- JSON API 1.0 核心开发者自述 | 你所不知道的那些技术细节
justjavac
json
2013年5月,Yehuda Katz 完成了JSON API(英文,中文) 技术规范的初稿。事情就发生在 RailsConf 之后,在那次会议上他和 Steve Klabnik 就 JSON 雏形的技术细节相聊甚欢。在沟通单一 Rails 服务器库—— ActiveModel::Serializers 和单一 JavaScript 客户端库——&
- 网站项目建设流程概述
macroli
工作
一.概念
网站项目管理就是根据特定的规范、在预算范围内、按时完成的网站开发任务。
二.需求分析
项目立项
我们接到客户的业务咨询,经过双方不断的接洽和了解,并通过基本的可行性讨论够,初步达成制作协议,这时就需要将项目立项。较好的做法是成立一个专门的项目小组,小组成员包括:项目经理,网页设计,程序员,测试员,编辑/文档等必须人员。项目实行项目经理制。
客户的需求说明书
第一步是需
- AngularJs 三目运算 表达式判断
qiaolevip
每天进步一点点学习永无止境众观千象AngularJS
事件回顾:由于需要修改同一个模板,里面包含2个不同的内容,第一个里面使用的时间差和第二个里面名称不一样,其他过滤器,内容都大同小异。希望杜绝If这样比较傻的来判断if-show or not,继续追究其源码。
var b = "{{",
a = "}}";
this.startSymbol = function(a) {
- Spark算子:统计RDD分区中的元素及数量
superlxw1234
sparkspark算子Spark RDD分区元素
关键字:Spark算子、Spark RDD分区、Spark RDD分区元素数量
Spark RDD是被分区的,在生成RDD时候,一般可以指定分区的数量,如果不指定分区数量,当RDD从集合创建时候,则默认为该程序所分配到的资源的CPU核数,如果是从HDFS文件创建,默认为文件的Block数。
可以利用RDD的mapPartitionsWithInd
- Spring 3.2.x将于2016年12月31日停止支持
wiselyman
Spring 3
Spring 团队公布在2016年12月31日停止对Spring Framework 3.2.x(包含tomcat 6.x)的支持。在此之前spring团队将持续发布3.2.x的维护版本。
请大家及时准备及时升级到Spring
- fis纯前端解决方案fis-pure
zccst
JavaScript
作者:zccst
FIS通过插件扩展可以完美的支持模块化的前端开发方案,我们通过FIS的二次封装能力,封装了一个功能完备的纯前端模块化方案pure。
1,fis-pure的安装
$ fis install -g fis-pure
$ pure -v
0.1.4
2,下载demo到本地
git clone https://github.com/hefangshi/f