两个核心依赖
falsk主要依赖两个库 —— Werkzeug 和 Jinja。
Jinja2
由于大多数Web程序都需要渲染模板,与Jinja2集成可以减少大量的工作。此处不展开讨论。
Werkzeug
Flask的核心扩展就是Werkzeug。
python Web框架都需要处理WSGI交互,它是为了让Web服务器与python程序能够进行数据交流而定义的一套接口标准/规范。而Werkzeug是一个优秀的WSGI工具库。
HTTP请求 -》 WSGI规定的数据格式 -》 Web程序
从路由处理,到请求解析,再到响应封装,以及上下文和各种数据结构都离不开Werkzeug。
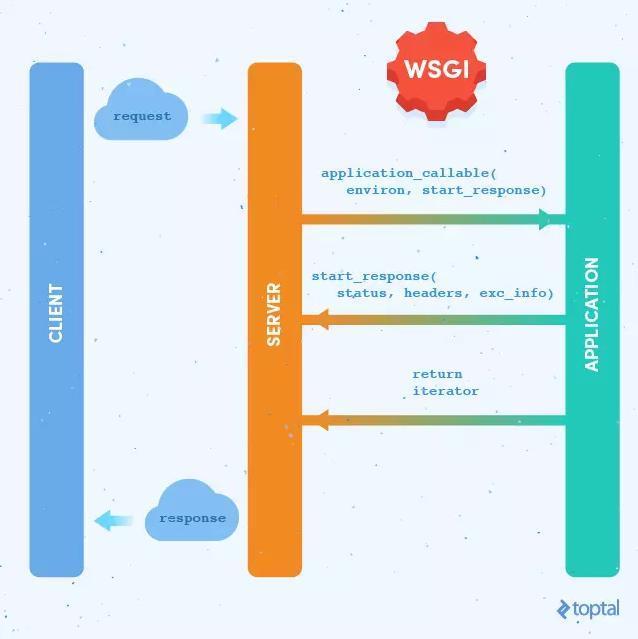
WSGI程序
根据WSGI的规定,Web程序(WSGI程序)必须是一个可调用对象。这个可调用对象接收两个参数:
- environ:包含了请求的所有信息的字典。
- start_response:需要在可调用对象中调用的函数,用来发起响应,参数是状态码,响应头部等
WSGI服务器会在调用这个可调用对象时传入这两个参数。另外这个可调用对象还要返回一个可迭代对象。
这个可调用对象可以是函数、方法、类或是实现了call方法的类实例。
以下借助简单的实例来了解最主要的两种实现:函数和类
# 函数实现
# 可调用对象 接收两个参数
def hello(environ, start_response):
# 响应信息
status = '200 OK'
response_headers = [('Content-type', 'text/html')]
# 需要在可调用函数中调用的函数
start_response(status, response_headers)
# 返回可迭代对象
return [b'Hello
']
注:WSGI规定请求和响应主体应该为字符串(bytestrings),即py2中的str。在py3中字符串默认为unicode类型,因此需要在字符串前添加b声明为bytes类型,兼容两者
# 类实现
class AppClass:
def __init__(self, environ, start_response):
self.environ = environ
self.statr = start_response
# iter方法,这个类被迭代时,调用这个方法
# 实现该方法的类就是迭代器
def __iter__(self):
status = '200 OK'
response_headers = [('Content-type', 'text/html')]
self.start(status, response_headers)
yield b'Hello
'
werkzeug中如何实现Web程序
由于flask是基于werkzeug实现的,所以先了解以下werkzeug是如何实现一个简单的web程序
from werkzeug.wrappers import Request, Response
@Request.application
def hello(request):
return Response('hello')
if __name__ == '__main__':
from werkzeug.serving import run_simple
run_simple('localhost', 5000, hello)
通过以上代码,使用run_simple规定了ip、端口号、调用对象
路由是怎么设定的?
Werkzeug怎么实现路由系统
# 路由表
m = Map()
rule1 = Rule('/', endpoint='index')
rule2 = Rule('/downloads/', endpoint='downloads/index')
m.add(rule1)
m.add(rule2)
Flask的路由系统
Flask使用中的路由系统,是通过route() 装饰器来将视图函数注册为路由。进入route函数
def route(self, rule, **options):
def decorator(f):
endpoint = options.pop("endpoint", None)
self.add_url_rule(rule, endpoint, f, **options)
return f
return decorator
可见内部调用了add_url_rule,并将函数作为参数传入。看到add_url_rule存在关键的语句
# url_map实际上就是Map类的实例
# rule就是通过route相关更正成的Rule实例
self.url_map.add(rule)
# view_functions是一个字典,存储了端点和视图函数的映射关系。可用于查询
self.view_functions[endpoint] = view_func
再进入底层就会发现,实际上就同上例的werkzeug实现
导入config配置参数
最初,我们修改配置文件会使用以下方法
app.config['DEGUB'] = True
导入参数
import config
app.config.from_object(config)
# 在config.py 文件中 存放配置参数
DEBUG = True
SECRET_KEY = os.urandom(24)
DIALECT = 'mysql'
DRIVER = 'mysqlconnector'
USERNAME = 'root'
PASSWORD = 'root'
HOST = '127.0.0.1'
PORT = '3306'
DATABASE = 'test'
如果自定义了配置文件类也可传入字符串
app.config.from_object('config.Foo')
# 以上代表 config.py文件中的 Foo类
进入from_object() 函数 [位于config.py]
def from_object(self, obj):
if isinstance(obj, string_types):
obj = import_string(obj)
for key in dir(obj):
if key.isupper():
self[key] = getattr(obj, key)
首先判断如果是字符串类型的,做相应处理获得对象。在import_string函数中
module_name, obj_name = import_name.rsplit(".", 1)
module = __import__(module_name, globals(), locals(), [obj_name])
dir()函数的作用:
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;
带参数时,返回参数的属性、方法列表。
如果参数包含方法__dir__(),该方法将被调用。
如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
获取属性后判断是否为大写,是则添加为配置参数
用类导入配置的作用
在开发和线上,往往采用的不是相同的配置文件。我们可以通过类封装几套配置文件以供使用。
可以编写一个基础类,在开发测试、线上运行都相同、都需要的配置参数。再通过继承,扩展不同环境下的不同配置参数。
则在不同的环境下,只需要改变from_object() 中的参数即可。
Flask如何处理请求
app程序对象
在一些Python web框架中,视图函数类似
@route('/')
def index():
return 'hello'
但在flask中
@app.route('/')
def index():
return 'hello'
flask 中存在一个显式的程序对象,我们需要在全局空间中创建它。设计原因主要包括:
- 相较于隐式程序对象,同一时间只能有一个实例存在,显式的程序对象允许多个程序实例存在。
- 允许通过子类化Flask类来改变程序行为。
- 允许通过工厂函数来创建程序实例,可以在不同的地方传入不同的配置来创建不同的程序实例。
- 允许通过蓝本来模块化程序。
启动app.run()
在Flask类中
当调用app.run(),程序启动。我们查看run()函数的源码
from werkzeug.serving import run_simple
try:
run_simple(host, port, self, **options)
finally:
# reset the first request information if the development server
# reset normally. This makes it possible to restart the server
# without reloader and that stuff from an interactive shell.
self._got_first_request = False
可见run_simple函数,而第三个参数是self,即flask对象。
当调用对象时,python会执行__call__方法。
进入Flask() 类可以看到
def wsgi_app(self, environ, start_response):
ctx = self.request_context(environ)
error = None
try:
try:
ctx.push()
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
except: # noqa: B001
error = sys.exc_info()[1]
raise
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)
def __call__(self, environ, start_response):
"""The WSGI server calls the Flask application object as the
WSGI application. This calls :meth:`wsgi_app` which can be
wrapped to applying middleware."""
return self.wsgi_app(environ, start_response)
当请求到来时,程序在调用app时,由于实现了__call__函数,则通过该函数调用了wsgi_app()函数
具体分析wsgi_app函数:
- 生成request请求对象和请求上下文(封装在request_context函数里)
- 将生成的请求上下文(本次请求的环境)push入栈,存储。
- 请求进入预处理(例如before_request),错误处理及请求转发到响应的过程(full_dispatch_request函数)
详情查看:
https://blog.csdn.net/bestallen/article/details/54342120
before_request\after_request
在平常使用中,我们还会使用装饰器before_request对某些请求执行前做一些相关操作。
我们进入before_request源码中,可以看到实际上就一行代码
def before_request(self, f):
self.before_request_funcs.setdefault(None, []).append(f)
return f
并且从源码中可以看到before_request_funcs只是Flask类中初始化的一个空字典。所以以上函数就是将字典设置为
{
None : [func1, func2...]
}
键为none,值为存储了before_request函数的列表
回头再看到当请求到达时,__call__调用wsgi_aqq函数
# 先是将请求相关的资源环境封装成请求上下文对象 并入栈
ctx = self.request_context(environ)
error = None
try:
try:
ctx.push()
response = self.full_dispatch_request()
进入full_dispatch_request
try:
request_started.send(self)
rv = self.preprocess_request()
if rv is None:
rv = self.dispatch_request()
再进入preprocess_request
bp = _request_ctx_stack.top.request.blueprint
funcs = self.url_value_preprocessors.get(None, ())
if bp is not None and bp in self.url_value_preprocessors:
funcs = chain(funcs, self.url_value_preprocessors[bp])
for func in funcs:
func(request.endpoint, request.view_args)
funcs = self.before_request_funcs.get(None, ())
if bp is not None and bp in self.before_request_funcs:
funcs = chain(funcs, self.before_request_funcs[bp])
for func in funcs:
rv = func()
if rv is not None:
return rv
看到后半部分,实际上就是把刚刚字典(before_request_funcs)中的的函数遍历出来执行。如果存在返回值,则直接返回。
所有如果当前的before_request函数存在并且返回了值,则之后的函数before_request函数后不会被执行,并且视图函数也不会执行,可见调用before_request的源码(前文已提到)
rv = self.preprocess_request()
# 若不存在返回值, 才执行视图函数
if rv is None:
rv = self.dispatch_request()
# 否则处理错误
except Exception as e:
rv = self.handle_user_exception(e)
# 执行后处理 生成最终的response
return self.finalize_request(rv)
再看一下finalize_request
def finalize_request(self, rv, from_error_handler=False):
'''
把视图函数返回值转换为响应,然后调用后处理函数
'''
response = self.make_response(rv) # 生成响应
try:
response = self.process_response(response) # 响应预处理
request_finished.send(self, response=response) # 发送信号
except Exception:
if not from_error_handler:
raise
self.logger.exception(
"Request finalizing failed with an error while handling an error"
)
return response
所以总结流程就是:
- preprocess_request函数执行预处理(例before_request)
- 若相关预处理函数出现返回值,提前结束
- 若正常执行完所有预处理函数,无返回值
- 调用dispatch_request,执行视图函数,将结果封装成rv
- 将视图函数生成的返回值rv传递给finalize_request,生成响应对象并且执行后处理
整理flask请求进入的逻辑
wsgi ( run_simple函数等待请求到来)
↓
调用flask的 __call__ ( 由于run_simple的self参数)
↓
__call__ 返回调用 wsgi_app()
→ ctx = self.request_context(environ) 把请求相关信息传入初始化得一个ctx对象(请求上下文)
ctx.push() 将上下文对象入栈(localStack) → Local存储(维护__storage__ = {122:{stack:[ctx,]}})
↓
视图函数从localStack(再从local)中取出上下文进行操作
[图片上传失败...(image-171246-1565862389864)]
关于Local
通过上述关系,可知local是作为一个动态的存储仓库。通过线程/进程id设置其运行环境(上下文)。
进入Local()类中 【local.py】
class Local(object):
__slots__ = ("__storage__", "__ident_func__")
def __init__(self):
object.__setattr__(self, "__storage__", {})
object.__setattr__(self, "__ident_func__", get_ident)
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__()
storage = self.__storage__
try:
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
可以看到init函数中 调用了object类的setattr。但实际上本类中也存在,甚至可以不使用setattr,直接用赋值语句 __storage__ = {}也可。那为什么要调用父类的setattr呢。
回到Local的作用:动态的存储运行环境。
Local采用__storage__作为仓库存储
那么面临两个问题:
1. 初始化__storage__
2. 动态赋值(格式为__storage__ :{122:{stack:[ctx,]}})
解决动态赋值问题,即重写赋值函数(赋值语句的实质就是调用__setattr__)
从源码中可以看到Local类重写了__setattr__函数,实现了所需的要求
那么此时该如何初始化__storage__呢
由于我们新重写的setattr函数中调用了storage,但未初始化之前就使用了它,明显错误
于是使用object的setattr函数来初始化storage,就完美的解决了以上问题。
关于LocalStack
注:在local中 __storage__的实质是字典,它的val也是字典(不同进程线程的存储空间),val的key名为stack(源码规定), val的val是列表(用栈实现)(用于管理上下文)
在单次请求中,我们真正要使用的是当前环境下的上下文,所以如果只依靠Local:
obj = Local()
obj.stack = []
obj.stack.append(上下文环境)
显然不易于维护、可扩展性差
于是使用LocalStack作为代理。查看源码LocalStack()类 (local.py)
class LocalStack(object):
def __init__(self):
self._local = Local()
def push(self, obj):
"""Pushes a new item to the stack"""
rv = getattr(self._local, "stack", None)
if rv is None:
self._local.stack = rv = []
rv.append(obj)
return rv
def pop(self):
"""Removes the topmost item from the stack, will return the
old value or `None` if the stack was already empty.
"""
stack = getattr(self._local, "stack", None)
if stack is None:
return None
elif len(stack) == 1:
release_local(self._local)
return stack[-1]
else:
return stack.pop()
@property
def top(self):
try:
return self._local.stack[-1]
except (AttributeError, IndexError):
return None
由源码可见
- LocalStack在init中创建了一个Local对象,此时storage是一个空字典
- 当调用push时,即传入线程或进程对象时,先判断是否已存在,否则新创建一个空间(列表,作为栈),入栈
- 当调用top时,返回栈顶元素
- 调用pop时若栈中只剩一个元素,则取出后删除该栈空间,否则pop栈顶元素
在上下文之前
在解释上下文之前,先看看上下文和以上的栈有什么联系
通过以上实现的栈,我们做出以下假设,用上下文存储当前请求的环境(包括request信息、session等)
# 请求上下文
class RequestContext(object):
def __init__(self):
self.request = "xx"
self.session = "oo"
# 初始化一个存储栈空间
xxx = LocalStack()
# 当请求进入时,初始化一个请求上下文、封装了当前环境
ctx = RequestContext()
# 将该请求上下文入栈
xxx.push(ctx)
# 当需要使用相关资源时,取当前栈顶元素,即可操作相关数据
obj = xxx.top()
obj.request
obj.session
具体源码下章解析
本地上下文
以上所谈及的上下文究竟是什么呢?
在多线程环境下,要想让所有视图函数都获取请求对象。
- 最直接的方法就是在调用视图函数时将所有需要的数据作为参数传递进去,但这样一来程序逻辑就变得冗余不易于维护。
- 另一种方法是将这些数据设为全局变量,但是这样必然会在不同的线程中出现混乱(非线程安全)。
本地线程(thread locals) 的出现解决了这些问题。
本地线程就是一个全局对象,使用一种特定线程且线程安全的方式来存储和获取数据。也就是说,同一个变量在不同线程内拥有各自的值,互不干扰。
实现原理其实很简单,就是根据线程的ID来存取数据。
Flask没有使用标准库的threading.local(),而是使用了Werkzeug自己实现的本地线程对象werkzeug.local.Local(),后者增加了对Greenlet(以C扩展形式接入python的轻量级协程)的优先支持。
Flask使用本地线程来让上下文代理对象全局可访问,比如:
- request
- session
- current_app
- g
这些对象被称为本地上下文对象(context locals)。
所以,在不基于线程、greenlet或单进程实现的并发服务器上,这些代理对象将无法正常工作,但仅有少部分服务器不支持。
Flask的设计初衷是为了让传统Web程序开发更加简单和迅速,二不是用来开发大型程序或异步服务器的。但Flask 的可扩展性却提供了无限的可能性,除了使用扩展,还可以子类化Flask类或为程序添加中间件。
应用上下文、请求上下文都是对象,是对一系列flask对象的封装,并且提供相关的接口方法。
- 请求上下文: request session
- 应用上下文: app g
- flask中上下文相关的代码存放在
ctx.py
请求上下文
请求上下文最主要的是提供对Request请求对象的封装。
RequestContext(object) // 请求上下文
- __init__
- push
- pop
- __enter__
- __exit__
先看源码中init函数的作用
def __init__(self, app, environ, request=None, session=None):
self.app = app
if request is None:
request = app.request_class(environ)
self.request = request
self.url_adapter = None
try:
self.url_adapter = app.create_url_adapter(self.request)
except HTTPException as e:
self.request.routing_exception = e
self.flashes = None
self.session = session
可以看到就是对当前请求相关数据的初始化,如 当前app对象、request、session、flashes等,符合上章所提到的上下文和栈的关系作用。
认识
请求到来时:
# self是app对象,environ是请求相关的原始数据(根据WSGI规定)
ctx = RequestContext(self, environ)
ctx.request = Request(environ)
ctx.session = None
# 不同的线程在内部分别持有不同的资源
{
1232:{ctx: ctx对象}
1231:{ctx: ctx对象}
2141:{ctx: ctx对象}
1235:{ctx: ctx对象}
}
视图函数:
from flask import request,session
# falsk 自动的识别当前线程,找到对应的ctx里的request、session
请求结束:
根据当前线程的唯一标记,将数据资源移除
实现
flask利用local()为线程或协程开辟资源空间,并用stack【栈】存储维护,内部再使用偏函数【functools.partial(func1, 10)】拆分各属性值。
app.run()
0. wsgi(处理请求,准备调用__call__)
1. app.__call__(准备调用wsgi_app)
2. app.wsgi_app(准备实例化RequestContext)
3. ctx = RequestContext(session, request)
- 请求相关+空session 封装到RequestContext(ctx)
4. ctx.push()
- 将ctx交给LocalStack对象
5. LocalStack,把ctx对象添加到local中
- LocalStack相当于将单个线程或协程的数据资源分割开来,并作为栈进行维护
6. Local __storage__ = {
1231: {stack: [ctx(request, session), ]}
}
- local的结构。存储了多个线程或协程的资源数据
7. session存储
根据请求中的cookie提取名为sessionid对应的值,对cookie加密+反序列化,再赋值给ctx里的session
8. 视图函数
- 利用flask已经封装好的库,调用session或request的相关资源
9. 操作结束后
把session中的数据再次写入cookie中,将ctx删除
10. 结果返回给用户浏览器
11. 断开socket连接
request哪来的
- 首先当请求进入时,
__call__调用wsgi_app - 在wsgi_app中初始化了一个请求上下文 ctx = self.request_context(environ)
- 可见是将environ作为参数传入,而在WSGI中规定 environ即保存着请求相关的数据
- 进入request_context() 函数 发现只有一行代码 return RequestContext(self, environ)
- 进入RequestContext类 看到init函数中 request = app.request_class(environ)
- 通过以上 封装了一个request对象.提供我们可以使用 request.method request.args等操作
session相关原理
通过源码可以看到session的继承中,存在dict。则session具备dict的所有操作。
class SecureCookieSession(CallbackDict, SessionMixin):
↓
class CallbackDict(UpdateDictMixin, dict):
- session数据保存到redis
- 生成一个随机字符串
- 返回一个随机字符串给用户,并作为key
- 客户端再访问时返回该随机字符串
flash
flask中存在消息闪现机制,通过flash()源码(helpers.py)可以看到,本质上是利用session实现的
# category表示消息的类别,可以按类别存入,按类别弹出
def flash(message, category="message"):
flashes = session.get("_flashes", [])
flashes.append((category, message))
session["_flashes"] = flashes
message_flashed.send(
current_app._get_current_object(), message=message, category=category
)
弹出flash信息函数
def get_flashed_messages(with_categories=False, category_filter=()):
flashes = _request_ctx_stack.top.flashes
if flashes is None:
_request_ctx_stack.top.flashes = flashes = (
session.pop("_flashes") if "_flashes" in session else []
)
if category_filter:
flashes = list(filter(lambda f: f[0] in category_filter, flashes))
if not with_categories:
return [x[1] for x in flashes]
return flashes
则最终实现的效果是 flash() 存入信息,get_flashed_messages()只能对应的弹出一次。
应用上下文
应用上下文最主要的就是提供对核心对象flask的封装。
源代码中类的主要结构为:
AppContext(object) // 应用上下文
- push
- pop
- __enter__
- __exit__
g
每个请求进入时,都会创建一个g,一次完整请求为一个生命周期。
当多线程进入时,由于g的唯一标识为线程(Local中的__storage__),所以资源互不影响。可以使用g为每次请求设置一个值。
# 例:
@app.before_request
def x1():
g.x1 = 123
@app.route('/index')
def index():
print(g.x1)
return "index"
current_app
上下文与栈
栈到底是怎么工作的
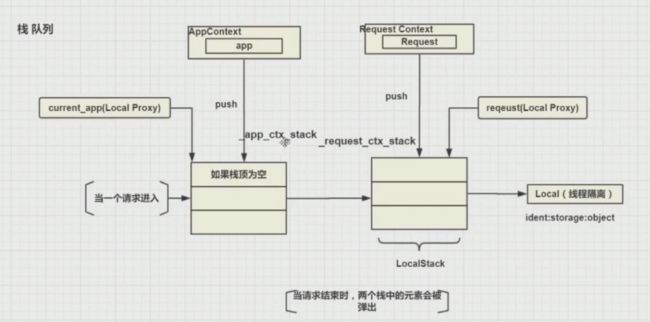
主要通过栈实现,即当一个请求进入时:
- 实例化一个requestcontext,封装了本次请求的相关信息(在Request中)
- 在请求上下文入栈之前,先检查应用上下文栈(源码可见栈名为:_app_ctx_stack)是否为空,为空则将当前app push()入栈
- 将请求上下文push()入栈(源码可见栈名为:_request_ctx_stack)
# RequestContext类中
# 可以看到先判断app_ctx是否存在,然后再push入栈request_ctx
app_ctx = _app_ctx_stack.top
if app_ctx is None or app_ctx.app != self.app:
# app_context 用于创建app_ctx对象
app_ctx = self.app.app_context()
app_ctx.push()
self._implicit_app_ctx_stack.append(app_ctx)
else:
self._implicit_app_ctx_stack.append(None)
_request_ctx_stack.push(self)
由于以上判断,所以我们在视图函数中使用current_app时,由于有请求上下文,所以不需要手动将应用上下文app_ctx入栈。如果在视图函数外,没有请求发生时,使用current_app则需要手动入栈
app_ctx = app.app_context()
app_ctx.push()
# 可使用current_app
app_ctx.pop()
何时会用到?
在实际生产中,current_app对象一般都是至与视图函数中使用
由于有正在的请求到来,所以不需要手动入栈。
但是在代码测试阶段,在进行单元测试时,或离线应用(不使用postman等工具发生完整请求)
没有实际的请求到来,又需要对代码进行测试
则需要手动将app_ctx入栈
with优化出入栈
# with优化 不需要手动push pop
with app.app_context():
# __enter__(连接)
a = current_app
d = current_app.config['DEBUG']
# __exit__(释放连接【资源】)
# (__exit__内部实现了异常处理,若成功处理了返回True,若没有成功处理,返回False还会向外部抛出异常)
# 出了with环境 app对象被pop()出栈 current_app 就找不到目标了
# with可以对实现了上下文协议的对象使用
# 上下文管理器(app context)
# 实现了__enter__(连接) __exit__(释放连接【资源】)就是上下文管理器
# 上下文表达式必须要返回一个上下文管理器
# 此时a是__enter__ 的返回值
with app.app_context() as a:
pass
# 可以自己实现上下文管理器,必须实现__enter__ __exit__方法
class MyResource:
def __enter__(self):
print('connect to resource')
# 将管理器返回再利用管理器进行相关操作
return self
def __exit__(self,exc_type, exc_value, tb):
print('close connection')
return True/False
# 返回True 表明此若产生异常内部进行处理,外部不会接收到异常
def query(self):
print('doing')
with MyResource() as r:
r.query()
# 也可以通过装饰器,省略__enter__ __exit__ (不推荐)
from contextlib import contextmanager
class MyResource:
def query(self):
print('doing')
@contextmanager
def make_myresource():
print('connect to resource')
# yield做返回,使用结束后再回到函数关闭连接
yield MyResource()
print('close connection')
with MyResource() as r:
r.query()
# 但是更好的做法是将本身不是上下文管理器的类,变为上下文管理器
# 例:输入书名 with中自动添加 《》
# 操作数据库 with中自动连接、回滚、断开
源码中的体现
从源码中可以看到无论是应用上下文还是请求上下文,都具有以下两个函数
def __enter__(self):
self.push()
return self
def __exit__(self, exc_type, exc_value, tb):
# do not pop the request stack if we are in debug mode and an
# exception happened. This will allow the debugger to still
# access the request object in the interactive shell. Furthermore
# the context can be force kept alive for the test client.
# See flask.testing for how this works.
self.auto_pop(exc_value)
if BROKEN_PYPY_CTXMGR_EXIT and exc_type is not None:
reraise(exc_type, exc_value, tb)
即在进入时将上下文入栈,使用完毕后自动pop出栈
栈中的元素
从源码中可以看到,push()的是上下文对象,但是我们真正使用的并非是上下文,而是current_app\request 等对象
源码中
current_app = LocalProxy(_find_app)
再看_find_app
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
注意到current_app是取app_ctx_stack的栈顶元素的app对象
同理request、g、session
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
LocalProxy代理
代理有什么用?
所有的数据都存储在Local中,如果直接对数据进行存取,需要建立多个类进行对数据的存取。如request类、session类、g类、current_app类。
但是由于以上类的功能相同,可以抽象出来,使用一个代理类,完成所需功能。
知识预备
# 偏函数
import functools
def index(a1, a2)
return a1 + a2
new_func = functools.partial(index, 666)
# 帮助自动传递参数
new_func(1) // 667
源码体现
在我们实际运用中,并不是直接去操作上下文。而是使用例如:current_app\request\session\g等 通过源码看到
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, "request"))
session = LocalProxy(partial(_lookup_req_object, "session"))
g = LocalProxy(partial(_lookup_app_object, "g"))
我们先进入LocalProxy类,看到init函数
def __init__(self, local, name=None):
object.__setattr__(self, "_LocalProxy__local", local)
object.__setattr__(self, "__name__", name)
if callable(local) and not hasattr(local, "__release_local__"):
# "local" is a callable that is not an instance of Local or
# LocalManager: mark it as a wrapped function.
object.__setattr__(self, "__wrapped__", local)
即为该对象设置值,而我们在实例化的时候,传递的参数是一个偏函数
那么当我们创建完代理对象后,考虑我们是怎样使用这些代理的: request.method request.args等,则实际上会调用对象的getattr。进入源码
def __getattr__(self, name):
if name == "__members__":
return dir(self._get_current_object())
return getattr(self._get_current_object(), name)
进入_get_current_object函数
def _get_current_object(self):
"""Return the current object. This is useful if you want the real
object behind the proxy at a time for performance reasons or because
you want to pass the object into a different context.
"""
if not hasattr(self.__local, "__release_local__"):
return self.__local()
try:
return getattr(self.__local, self.__name__)
except AttributeError:
raise RuntimeError("no object bound to %s" % self.__name__)
而local()实际上就是我们传递进来的偏函数(init()初始化的结果)
回头看一下传递进来的偏函数,看到源码中的_lookup_req_object
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name)
即取出栈顶的元素(上下文),再通过getattr获取到相关的内容。而erquest、session等,在前面也已经看到,是在上下文初始化时就创建的。所以该函数最终就是根据传递进来的参数(request, session, g, current_app),进入到local栈中,top拿到栈顶的上下文,然后在上下文中取出所需的资源。
三种程序状态
Flask提供的四个本地上下文对象分别在特定的程序状态下绑定实际的对象。如果我们在访问或使用它们时还没有绑定,就会看到经典的RuntimeError异常。
Flask中存在三种状态:
- 程序设置状态
- 程序运行状态
- 请求运行状态
程序设置状态
当Flask类被实例化,也就是创建程序实例app后,就进入程序设置状态。这是所有的全局对象都没有被绑定:
app = Flask(__name__)
程序运行状态
当Flask程序启动,但是还没有请求进入时,Flask进入了程序运行状态。
在这种状态下,程序上下文对象current_app和g都绑定了各自的对象。
使用flask shell命令打开的python shell默认就是这种状态,我们也在普通的Python shell中通过手动推送程序上下文来模拟:
app = Flask(__name__)
ctx = app.app_context()
ctx.push()
# current_app g /Flask flask.g
# requst session /unbound
以上我们手动使用app_context() 创建了程序上下文,然后调用push() 方法把它推送到程序上下文堆栈里。
默认情况下,当请求进入的时候,程序上下文会随着请求上下文一起被自动激活。但是在没有请求进入的场景,比较离线脚本、测试或者进行交互调试的时候,手动推送程序上下文以进入程序运行状态会非常方便。
请求运行状态
当请求进入的时候,或是使用test_request_context()方法、test_client()方法时,Flask会进入请求运行状态。因为当请求上下文被推送时,程序上下文会被自动推送,所以在这个状态下4个全局对象都会被绑定。我们可以通过手动推送请求上下文模拟:
app = Flask(__name__)
ctx = app.test_request_context()
ctx.push()
# current_app, g, request, session
# Flask flask.g Request NullSession
这也是为什么可以直接在视图函数和相应的回调函数里直接使用这些上下文对象,而不用推送上下文(Flask在处理请求时会自动推送请求上下文和程序上下文)
引用
- 《Flask Web 开发实战》
- 各类视频资料...