kafka Java客户端之 consumer API 多线程消费消息
kafka consumer 线程设计
Kafka Java Consumer采用的是单线程的设计。其入口类KafkaConsumer是一个双线程的设计,即用户主线程和心跳线程。
用户主线程,指的是启动Consumer应用程序main方法的线程,心跳线程(Heartbeat Thread)只负责定期给对应的Broker机器发送心跳请求,以表示消费者应用的存活性。
Kafka consumer不是线程安全的。所有网络I/O都发生在进行调用应用程序的线程中。用户的责任是确保多线程访问正确同步的。非同步访问将导致ConcurrentModificationException。
ConcurrentmodificationException异常的出处见以下代码:
/**
* Acquire the light lock protecting this consumer from multi-threaded access. Instead of blocking
* when the lock is not available, however, we just throw an exception (since multi-threaded usage is not
* supported).
* @throws IllegalStateException if the consumer has been closed
* @throws ConcurrentModificationException if another thread already has the lock
*/
private void acquire() {
ensureNotClosed();
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
该方法acquire 会在KafkaConsumer的大部分公有方法调用第一句就判断是否正在同一个KafkaConsumer被多个线程调用。
"正在"怎么理解呢?我们顺便看下KafkaConsumer的commitAsync 这个方法就知道了。
@Override
public void commitAsync(OffsetCommitCallback callback) {
acquire(); // 引用开始
try {
commitAsync(subscriptions.allConsumed(), callback);
} finally {
release(); //引用释放
}
}
我们看KafkaConsumer的release方法就是释放正在操作KafkaConsumer实例的引用。
/**
* Release the light lock protecting the consumer from multi-threaded access.
*/
private void release() {
if (refcount.decrementAndGet() == 0)
currentThread.set(NO_CURRENT_THREAD);
}
通过以上的代码理解,我们可以总结出来kafka多线程的要点: kafka的KafkaConsumer必须保证只能被一个线程操作。
kafka consumer多线程消费消息
为了提高应用对消息的处理效率,我们通常会使用多线程来并行消费消息,从而加快消息的处理速度。
而多线程处理消息的方式主要有两种。
方式一:每个partition创建一个线程
按Partition数量创建线程,然后每个线程里创建一个Consumer,多个Consumer对多个Partition进行消费。
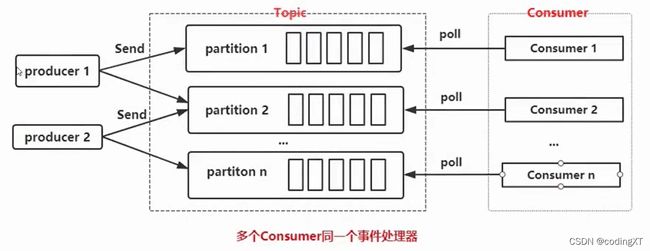
每个线程有自己的消费者实例。优点和缺点如下:
优点:
- 这是最容易实现的
- 因为它不需要在线程之间协调,所以通常它是最快的。
- 它按顺序处理每个分区(每个线程只处理它接受的消息)。
缺点:
- 更多的消费者意味着更多的TCP连接到集群(每个线程一个)。一般kafka处理连接非常的快,所以这是一个小成本。
- 更多的消费者意味着更多的请求被发送到服务器,但稍微较少的数据批次可能导致I/O吞吐量的一些下降
- 所有进程中的线程总数受到分区总数的限制。
这种属于是经典模式,实现起来也比较简单,适用于对消息的顺序和offset控制有要求的场景。代码示例:
public class ConsumerThreadSample {
private final static String TOPIC_NAME="xt";
/*
这种类型是经典模式,每一个线程单独创建一个KafkaConsumer,用于保证线程安全
*/
public static void main(String[] args) throws InterruptedException {
KafkaConsumerRunner r1 = new KafkaConsumerRunner(0);
KafkaConsumerRunner r2 = new KafkaConsumerRunner(1);
KafkaConsumerRunner r3 = new KafkaConsumerRunner(2);
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r2);
Thread t3 = new Thread(r3);
t1.start();
t2.start();
t3.start();
Thread.sleep(15000);
r1.shutdown();
r2.shutdown();
r3.shutdown();
}
public static class KafkaConsumerRunner implements Runnable{
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public KafkaConsumerRunner(int partitionNumber) {
Properties props = new Properties();
props.put("bootstrap.servers", "81.68.82.48:9092");
props.put("group.id", "groupxt");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
TopicPartition p = new TopicPartition(TOPIC_NAME, partitionNumber);
consumer.assign(Arrays.asList(p));
}
@Override
public void run() {
try {
while(!closed.get()) {
//处理消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10000));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> pRecord = records.records(partition);
System.out.println("------------------"+Thread.currentThread().getName()+"-----消费消息----------------------------");
// 处理每个分区的消息
for (ConsumerRecord<String, String> record : pRecord) {
System.out.printf("thread = %s ,patition = %d , offset = %d, key = %s, value = %s%n",
Thread.currentThread().getName(),record.partition(),record.offset(), record.key(), record.value());
}
System.out.println("-------------------"+Thread.currentThread().getName()+"-----消费消息----------------------------");
// 返回去告诉kafka新的offset
long lastOffset = pRecord.get(pRecord.size() - 1).offset();
// 注意加1
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
}catch(WakeupException e) {
if(!closed.get()) {
throw e;
}
}finally {
consumer.close();
}
}
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
}
方式二:池化,一个consumer 去拉取消息,多个Worker线程处理消息
另一种多线程的消费方式则是在一个线程池中只创建一个Consumer实例,然后通过这个Consumer去拉取数据后交由线程池中的线程去处理。如下图所示:(类似于netty的形式,一个负责建立网络通信,拉取到的数据交给其他处理器去处理)
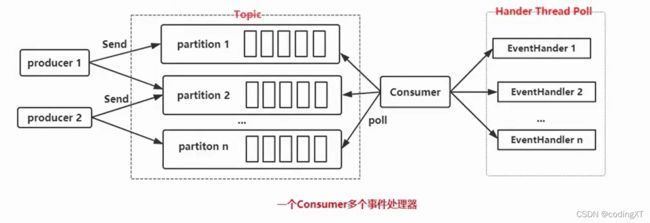
但需要注意的是在这种模式下我们无法手动控制数据的offset,也无法保证数据的顺序性,所以通常应用在流处理场景,对数据的顺序和准确性要求不高。
优点:
- 可扩展消费者和处理进程的数量。这样单个消费者的数据可分给多个处理器线程来执行,避免受分区partition的任何限制。
- 并发度高,单个consumer能力只受CPU限制
缺点:
- 跨多个处理器的顺序保证需要特别注意,因为线程是独立的执行,后来的消息可能比遭到的消息先处理,这仅仅是因为线程执行的运气。如果对排序没有问题,这就不是个问题。
- 手动提交变得更困难,因为它需要协调所有的线程以确保处理对该分区的处理完成。
两种实现方式的共同点:
- 每个consumer消费的partition个数都是由协调器协调
经过之前的例子,我们知道每拉取一次数据返回的就是一个ConsumerRecords,这里面存放了多条数据。然后我们对ConsumerRecords进行迭代,就可以将多条数据交由线程池中的多个线程去并行处理了。代码示例:
public class ConsumerRecordThreadSample {
private final static String TOPIC_NAME = "xt";
public static void main(String[] args) throws InterruptedException {
String brokerList = "kafka IP:9092";
String groupId = "groupxt";
int workerNum = 3;
CunsumerExecutor consumers = new CunsumerExecutor(brokerList, groupId, TOPIC_NAME);
consumers.execute(workerNum);
Thread.sleep(1000000);
consumers.shutdown();
}
// Consumer处理
public static class CunsumerExecutor{
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
public CunsumerExecutor(String brokerList, String groupId, String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("group.id", groupId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topic));
}
public void execute(int workerNum) {
executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy());
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (final ConsumerRecord record : records) {
executors.submit(new ConsumerRecordWorker(record));
}
}
}
public void shutdown() {
if (consumer != null) {
consumer.close();
}
if (executors != null) {
executors.shutdown();
}
try {
if (!executors.awaitTermination(10, TimeUnit.SECONDS)) {
System.out.println("Timeout.... Ignore for this case");
}
} catch (InterruptedException ignored) {
System.out.println("Other thread interrupted this shutdown, ignore for this case.");
Thread.currentThread().interrupt();
}
}
}
// 记录处理
public static class ConsumerRecordWorker implements Runnable {
private ConsumerRecord<String, String> record;
public ConsumerRecordWorker(ConsumerRecord record) {
this.record = record;
}
@Override
public void run() {
// 假如说数据入库操作
System.err.printf("thread = %s ,patition = %d , offset = %d, key = %s, value = %s%n",
Thread.currentThread().getName(),record.partition(), record.offset(), record.key(), record.value());
}
}
}
这种方法有多种玩法,例如,每个处理线程可以有自己的队列,消费者线程可以使用TopicPartition hash到这些队列中,以确保按顺序消费,并且提交也将简化。
References:
- https://www.jianshu.com/p/abbc09ed6703
- https://www.orchome.com/451#item-6
- https://blog.51cto.com/zero01/2498017
- https://blog.csdn.net/sdut406/article/details/103230456
- https://kafka.apache.org/28/javadoc/org/apache/kafka/clients/consumer/KafkaConsumer.html#multithreaded
- https://blog.csdn.net/Johnnyz1234/article/details/98318528?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=2
(写博客主要是对自己学习的归纳整理,资料大部分来源于书籍、网络资料和自己的实践,整理不易,但是难免有不足之处,如有错误,请大家评论区批评指正。同时感谢广大博主和广大作者辛苦整理出来的资源和分享的知识。)