1、 实验背景
Wi-Fi 网络和设备的广泛分布和智能移动终端的广泛使用,基于 Wi-Fi 的内部定位技术成为研究热点。GPS 很难解决一些室内定位问题。目前,Wi-Fi 接入点(AP)分布在公共场所,例如大型商业建筑,医院和地铁站等,并且使用Wi-Fi 技术定位以提高定位精度并节省部署定位设备的成本。
2、 实验目的
- 根据实验需求,用手机软件进行数据采样并完成数据收集及录入工作。
- 将数据带入模型算法中完成对模型的训练从而有效实施对于室内定位的测试。
本文采用接收到的AP 信号的强度值(即 RSSI)作为信号指纹特征。
3、 实验原理
3.1 基于位置指纹的室内定位算法原理
基于接受信号强度RSSI的室内定位算法原理就是依靠移动智能终端从部署接入点AP接收到的RSSI,利用不同地理位置上的 RSSI具有较稳定的、特殊的、可辨别的特征,建立起 地理位置和相对应接收到的RSSI信号的映射关系。
在基于指纹的室内定位方法中,主要有离线阶段和在线阶段两部分。在离线阶段,在目标区域上合理选择均匀的参考点,在每个参考点,采集每个AP的无线信号信息,然后参考点上的RSSI指纹数据进行滤波和训练,得到RSSI高维向量与地理位置二维向量的一一对应关系,建立起指纹数据库。在实际定位时,即在线阶段,利用用户接收到的一组RSSI,通过查询指纹数据库进行对比,依靠唯一的映射关系,可以得到待确定的地理位置信息。
3.2 基于SVM 的室内定位算法原理
目前在基于指纹数据库的室内定位技术中主要采用的定位算法有概率法、 K近邻法、支持向量机算法和神经网络法。在本次实验中主要采用支持向量机算法,SVM 方法建立在统计学习 VC 维( VC dimension) 理论和结构风险最小( structural risk minimization) 原理基础上,根据有限的样本信息在分类能力 ( 对任意样本进行无错误分类) 和模型的复杂性( 对特定样本的学习精度,Accuracy) 之间寻求折衷,以期使分类器获得最好的推广能力( Generalization Ability),它是一种非参数化的有监督分类器。
3.2.1 SVM 离线训练步骤
(1)初始化离线采样标准数据类型。首先需要 每条原始采样数据标定各自的类型。对于 SVM 的原始数据而言,因为需要进行具体到每个位置点的定位, 所以对于某个采样位置点采集的数据,标定的类型应该是其采样的位置点编号。
(2)分类器构建。由于 SVM 是一种典型的两类分类器,但根据需求需要将类型扩展为多个,实现多分类的功能。因此需要对 SVM 分类方式进行扩展。目 前,构造 SVM 多分类器主要有两种方式,一种是直接分类,另一种是间接分类。对于间接分类法,可能会出现“数据集偏斜”问题,即正类别数远小于负类别数, 造成分类精度降低。所以使用直接分类法实现 SVM 多分类。
(3)SVM 参数的选取。同其他机器学习方法一 样,SVM 分类器的性能也受到多种参数的影响,主要是惩罚参数 C和核函数参数 γ。其中C代表对误差的 容忍度,C值越高,说明对错误分类容忍度越低,分类器泛化能力越低;γ是核函数内的一个参数,该参数一定程度上影响了数据映射到新的特征空间后的分布。 本次实验核函数是径向基函数,kernel = ‘rbf’ 径向基函数
其中,可以看做两个特征向量之间的平方欧几里得距离。x’为核函数中心,是一个自由参数,是函数的宽度参数 ,控制了函数的径向作用范围C-SVC的惩罚参数:C=2
Gamma: 核函数参数: gamma = ‘scale’
(4)误差计算:单测试点误差采用实际值与预测点之间的欧式距离,平均误差是将对单个测试点求和除以训练数据条数。
3.2.2 SVM在线阶段步骤
(1)数据获取移动设备主动扫描当前环境中能够探测到的所有 AP,并解析出其 MAC 地址、信号强度、信道、采集时间等信息。
(2)定位请求。手机客户端软件请求定位服务,将第一步中收集到的数据作为参数进行定位POST请求。
(3)数据预处理。服务器网关部分经过无效AP的动态监测和过滤、数据筛选、数据修正等数据预处理工作。
- 当一个 RSS 测量值和两边相邻的 RSS 值相差很大时,认为这个测量值为奇异值。
- 当两个连续的 RSS 测量值和两边相邻的 RSS 值相差很大,认为这两个测量值是奇异值。
- 在信号变化的边界处,若随后的测量值急剧下降,而在下降之前有个突然增加的值,则此值为奇异值。
(4)基于区域网格的初定位。服务器定位引擎将上报的所有数据按信号强度降序排列,选取信号强度最好的K个。然后根据这 K个AP的 MAC地址从区域网格中匹配所属区域。区域有可能一个,也可能多个。一般情况下 K =3,如果室内环境比较复杂则应增大K值以提高定位成功率,但是相应的会延长定位的响应时间。
(5)在区域网格内进行SVM精确定位。第四步已经将定位范围缩小到某一个或者某几个区域网格内,则此时只需在区域网格内进行SVM定位,确定用户更精确的位置坐标。该过程使用SVM分类器对测试样本数据进行类型预测,且只挑选出定位所包含的位置点对应的二分类器组。最终通过投票法确定移动终端的位置。若投票得出的位置点为多个,则选取这几个位置点几何上的中心点作为定位结果。
4、 数据集准备
测前准备:选择北京工商大学文二301教室进行数据采集。将该教室按大小为2mX2m的面积分成面积相等的54个区域,然后再对每个样本区域的五个点进行RSSI信号强度值的测量。针对每一个点测量18个点信号强度。
4.1 数据采集
(1)由于校园网BTBU-AUTO的信号强度以及信号AP的不确定性,我们组为了增加稳定的信号源,在原有的AP基础上增加了三台手机的热点信号源,并将手机放在固定的位置上不移动。
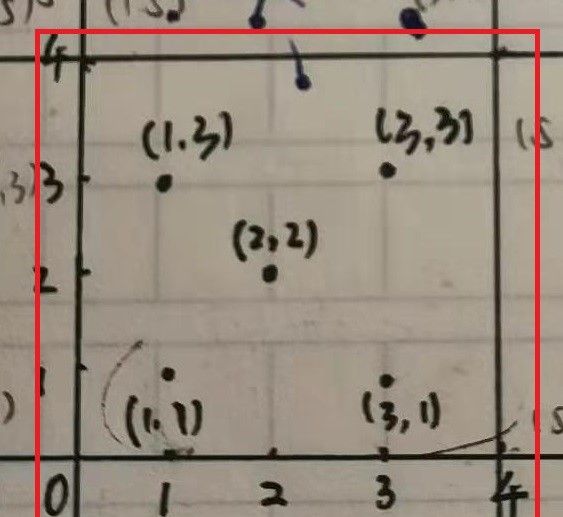
(2)利用Cellular-Z软件分别测试每一块区域中五个点的WIFI Mac地址和相应的信号强度。每块区域的采样位置如下图所示:
4.2数据录入
(1)将54块区域中的取样点分别标上相应的坐标,可见我们针对54*5个点进行RSSI的测量(将教室的中间设为圆点,为避免坐标取小数,所以将区域坐标扩大两倍均取整数)。整体坐标图如下图所示:

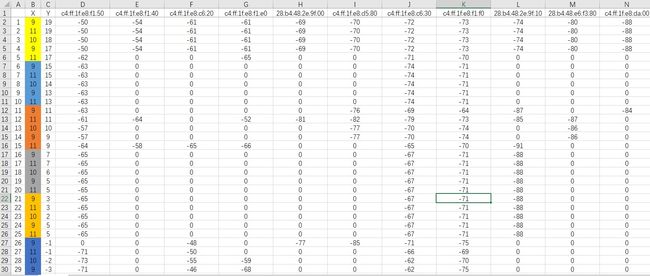
(2)利用Excel 表格按照数据采样的顺序,录入每个点的(X,Y)坐标以及在这个点测到的所有AP的mac地址和信号强度。对于每个位置有不同mac地址的情况,采用合并方法添加至维度中,若在该点没有检测到这个mac地址的信号,则该地址的强度记为0。最后的数据录入的部分结果如下图所示。
5、 实验过程
- 首先将数据分为训练集和测试,并保存到不同的文件中。
- 首先避开代码想想我们后面的工作
- 读取文件数据并保存在自己熟悉的容器中(比如python里的list等)。
- 对数据进行处理,平常是转化为向量。
- 选择合适的机器学习模型,拟合模型,并使用训练数据进行训练
- 拿到测试点的信号强度的值,对位置进行预测
3.误差计算 - 计算每一个测试点的误差并求和,最后平均值
下面是具体实现代码:
本实验直接使用了scikit-learn里提供的SVM算法,具体的话skleran.svm.SVC,感兴趣的可以访问sklearn官网
import numpy as np
import matplotlib.pyplot as plt
import xlrd # python 读excel 数据的模块
from sklearn import svm # sklearn provides supported vector machine learning algorthim
from sklearn import ensemble
from sklearn import tree
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
def Get_Average(list):
sum = 0
for item in list:
sum += item
return sum / len(list)
# 训练集
#open_workbook: Open a spreadsheet file for data extraction
# An instance of the :class:`~xlrd.book.Book` class.(返回的是一个实例)
TrainData = xlrd.open_workbook('realData/Training3.xlsx') # 打开excel 文件读取数据源:
table = TrainData.sheets()[0] #通过索引顺序获取 返回一个xlrd.sheet.Sheet对象
nrows = table.nrows # 获取有效行数
ncols = table.ncols # 获取有效的列数
# 第一列为编号, 第二例, 第三列为坐标, 创建要用到的list
TrainX = [([0] * (ncols - 3)) for p in range(nrows - 1)]
TrainY = [([0] * 1) for p in range(nrows - 1)]
TrainCoor = [([0] * 2) for p in range(nrows - 1)]
# 初始化我们的三个list
for i in range(nrows - 1):
TrainY[i][0] = table.cell(i + 1, 0).value # 拿到每一列的数据[i][0]==》编号
for j in range(ncols - 3):
TrainX[i][j] = table.cell(i + 1, j + 3).value # 获取所有rssi
for k in range(2):
TrainCoor[i][k] = table.cell(i + 1, k + 1).value # 拿到坐标的值
# print(TrainY) # 编号
# print(TrainX) # 所有的RSSI
# print(TrainCoor) 坐标
X = np.array(TrainX)
Y = np.array(TrainY)
# 测试集
TestData = xlrd.open_workbook('realData/TestTingData3.xlsx')
testTable = TestData.sheets()[0]
testNrows = testTable.nrows
testNcols = testTable.ncols
TestX = [([0] * (testNcols - 3)) for p in range(testNrows - 1)]
TestCoor = [([0] * 2) for p in range(testNrows - 1)]
for i in range(testNrows - 1):
for j in range(testNcols - 3):
TestX[i][j] = testTable.cell(i + 1, j + 3).value
for h in range(2):
TestCoor[i][h] = testTable.cell(i + 1, h + 1).value
onlineX = np.array(TestX)
# print(TestCoor)
actualCoor = np.array(TestCoor)
'''
Desc: 分类 Scikit-Learn库已经实现了所有基本机器学习的算法
参数说明: kernel(核函数类型 rbf:径像核函数/高斯核)
c:错误项的惩罚系数,C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率降低。
gamma: 核函数系数 1 /(n_features *X.var())作为gamma的值
'''
classifier = svm.SVC(kernel='rbf', C=1.0, gamma='scale')
# 根据给定的训练数据拟合SVM模型
# ravel: 将多维数组降位一维
# fit 是训练函数: 给出RSSI和标签即可训练(标签是坐标)
classifier.fit(X, Y.ravel()) #
y_pre = classifier.predict(onlineX)
# plt.xlabel('Type')
# plt.ylabel('value')
# plt.scatter(y_pre, y_pre)
# plt.show()
plt.xlabel("横坐标")
plt.ylabel("纵坐标")
plt.title('训练集点和测试集点的分布')
Error = []
for i in range(testNrows - 1):
curPre = int(y_pre[i]) # 拿到预测结果, 并转为int
PredictCoor = [TrainCoor[curPre - 1][0], TrainCoor[curPre - 1][1]] # 第1个类别对应TrainCoor[0]的数据,以此类推
x = PredictCoor[0]
y = PredictCoor[1]
plt.scatter(x, y, s=50, c='r', marker='x')
print(np.linalg.norm(PredictCoor - actualCoor[i, :]))
Error.append(np.linalg.norm(PredictCoor - actualCoor[i, :])) # 第i个维度中所有维度的数据(二维)
print(i, end=" ")
print("模型预测:", PredictCoor, end=" ") # 预测的位置
print("实际值:", actualCoor[i, :], end=" ") # 实际位置
print("直线距离:", np.linalg.norm(PredictCoor - actualCoor[i, :])) # 求二范数:空间上两个向量矩阵的直线距离
print("平准误差:", Get_Average(Error))
# 画散点图
# plt.figure()
for dot in TrainCoor:
x = dot[0]
y = dot[1]
plt.scatter(x, y, s=50, alpha=0.5)
for tdot in TestCoor:
x1 = tdot[0]
y1 = tdot[1]
plt.scatter(x1, y1, s=50, c='k', marker='>')
plt.show()
实验运行结果截图:
本次实验中每个区域里拿出四点作为训练数据,一个点作为测试数据。

在下方的折点图中源点表示训练点,黑色的三角形是测试点,x号是预测点。

6、实验结果与过程分析
6.1 实验结果分析
1.由于54个点比较多没有全部点的结果放上去, 从图5.1中的9个点看出测试点与实验预测点最大距离为6,最小为1.4。对54个测试点的误差求和去平均值得到平均误差4.2.
2.从图5.2中直观的看出总区域是35*20,被划分为54个子区域。从图上训练点,测试点,预测点位置可看出,估计是位置移动对信号强度变化影响不明显或者坐标标记数据记录的影响,导致有些子区域的点预测在别的区域。
6.2 在实验过程中遇到的问题
(1)热点信号问题
在测量数据过程中,由于手机设定问题,热点开一段时间就自动关闭了,导致了测量过程中,固定AP消失的现象。
解决方案:为了让热点一直处于开启状态,我们利用了平板电脑、电脑等设备连接上已经开启的热点。对于出错的数据进行了重新的测量。
(2)区域划分时粒度问题
由于我们将教室分为2mX2m的区域太小,并且区域之间距离相近,所以导致了每块区域之间的AP信号强度比较接近,没有明显的差异。
解决方案:寻找了一个大教室,并且缩小不同区域之间采样点之间的距离。
(3)数据录入时的问题(X,Y坐标)
由于我们组在测试数据时并没有将每一点相应的坐标位置记录,而是在每个区域中所有数据采集完之后标的坐标,这样就导致了每个区域中坐标和相应点的信号强度值混乱,导致了结果有一些小的偏差。
解决方案:经过与老师和其他组的同学进行讨论,得知坐标与每个区域中点的匹配程度,对最后每个区域的定位影响较小,所以没有重新去测量数据。
(4)测试集和训练集的选取问题
在刚开始时,我们小组选择的是将前40个区域的数据作为训练集,后14个区域的数据作为测试集,但是最后得出的定位结果误差很大。在经过讨论后,发现我们组的训练集和测试集选取有错误,测试集没有体现所划分的54个区域的特征,并且测试集也没有涵盖所有的区域。
解决方案:重新抽取测试集和训练集。训练集:将每个区域中的第二个点抽取出来做测试集,剩下的4个点留作训练集。
6.3 以后的改进
在上述实验过程中,由于场地限制以及AP信号的限制,导致了最后的训练精度有些小的偏差,所以在以后的实验中,将会在空间比较大的地方进行数据采集和实验(比如:操场、商场等地),并且在测试过程中,采用更加稳定和更多数量的AP信号,来加强训练的精度。
组员: 尼加提 马书涵 麻春蕊 谷情 田润
数据集和项目代码在gitub仓库里室内定位