
写在前面
webpack已经成了一个很流行的打包工具,在各种优秀的脚手架中,其底层都是基于webpack的封装,今天这篇文章,将带大家了解一个打包工具的底层原理,并写一个简单的自己的打包工具。如果你对webpack还不够熟悉,欢迎看我之前写下的两个关于webpack基础的文集
- webpack4入门讲解
- webpack4高级实践
开始
创建一个项目,目录和内容如下
|--src
|--index.js
|--message.js
|--word.js
word.js
export const word = 'hello'
message.js
import { word } from './word.js'
const message = `say ${word}`
export default message
index.js
import message from './message.js'
console.log(message)
实际上,我们的项目就是要输出一个'say hello'的字符串,但是上面的代码是无法直接运行在浏览器下面的,因为浏览器不认识import和export这样的语法,这时候我们就需要一个打包工具了,我们不使用webpack,来实现一个自己的打包工具,在根目录下创建'bundler.js'文件。
编写bundler
首先,我们需要对入口文件做分析
const fs = require('fs')
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
console.log(content)
}
moduleAnalyser('./src/index.js')
上面的代码中,我们通过nodejs的fs模块拿到了入口文件的内容,这样我们就可以开始对入口文件做一个分析了,在命令行中使用node命令运行一下bundler.js试一试吧
node bundler.js

我们拿到了入口文件的内容,这里是一个单纯的文本,如果想要代码高亮,可以来安装一个插件
yarn global add cli-highlight
运行
node bundler.js | highlight

分析入口文件的依赖
为了更方便的分析入口文件的,我们需要引入一个第三方模块@babel/parser
yarn add @babel/parser -S
具体用法可以参考babel官网@babel/parser,我们按照官网用法,这样修改代码
const fs = require('fs')
const paresr = require('@babel/parser')
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
console.log(paresr.parse(content, {
sourceType: 'module' // 如果你的代码是按照ESM写的,需要加该属性
}))
}
moduleAnalyser('./src/index.js')
这是再运行bundler试试

可以看到这是一个比较长的对象哈,其实这个对象就能反映出我们现在的代码,这就是所谓的抽象语法树也就是一些文章博客中经常提起的AST,其中program字段代表当前的一个代码,其中有一个body字段,我们可以打印一下看看

我们可以看到,又打印出来两个节点,其中第一个节点是一个“引用语句”第二个“表达式”,这里正对应着indexjs中的内容,这就是AST的作用。我们就可以通过AST来拿到入口文件对应的依赖关系了。
获取入口文件依赖
我们通过AST拿到了入口文件对应的文件关系,其中可以很轻松的拿到引用模块,但是如果我们通过遍历的形式来拿就显得比较麻烦了,这里我们再来引入一个第三方的模块
yarn add @babel/traverse -S
按照babel官网介绍对他进行配置如下
const fs = require('fs')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
traverse(ast, {
ImportDeclaration ({ node }) {
console.log(node)
}
})
}
moduleAnalyser('./src/index.js')
其中,traverse接受两个参数,第一个参数就是AST,我们在上面拿到的抽象语法树,第二个参数书是一个对象,对象的内容是我们要遍历的节点类型,他是一个函数,意思是每次遍历到该类型节点,都要执行一个这个函数。我们执行打包命令,看一下结果如下
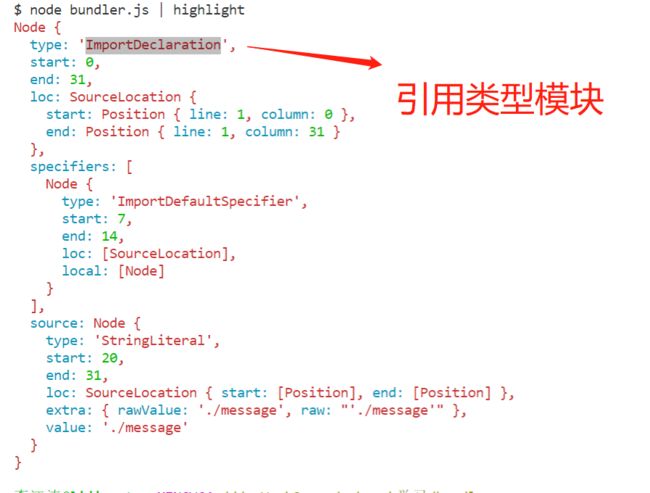
我们通过上面的操作,就可以拿到所有引用的节点了,我们的入口文件也确实是只有一个引用
import message from './message' // 引用模块
console.log(message)
下面我们对拿到的应用模块的节点做处理,我们定义一个数组,每次遍历到引用模块的节点时,将其文件名push进这个数组,从上面执行的结果中,我们可以看到,文件名在node.source.value中。改变改成下面这样并运行。
const fs = require('fs')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = []
traverse(ast, {
ImportDeclaration ({ node }) {
dependencies.push(node.source.value)
}
})
console.log(dependencies)
}
moduleAnalyser('./src/index.js')

可以看到,我们正常的拿到了入口文件源码中应用的依赖的文件名。但是现在我们拿到的文件名是相对于入口文件的一个相对路径,而要想正确的执行打包,我们必须要通过一个绝对路径或者是相对于根目录的相对路径来展示依赖路径,于是我们使用nodejs的
path模块,对其进行改造
const fs = require('fs')
++ const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = []
traverse(ast, {
ImportDeclaration ({ node }) {
++ const dirname = path.dirname(filename)
++ const newFile = './' + path.posix.join(dirname,node.source.value)
++ console.log(newFile)
dependencies.push(newFile)
}
})
}
moduleAnalyser('./src/index.js')
通过上面的操作后,我们再看执行结果,这时候就是相对于根目录的一个相对路径了。

(这里插播一条坑点,因为我是在window下开发的,所以路径是以‘\’分割的,如果你使用的是mac那么路径是用'/'分割的,一个‘\’会被当成转译字符,当你做一些数据操作的时候,会变成双斜杠,所以,这里对于windows开发用户,我们不能使用const newFile = '/' + path.join(dirname, node.source.value))!!
可以试验一下这个坑点哦,我开发的时候踩了半天坑,哈哈。
一个相对于根目录的相对路径,但是这样在后续的打包过程中还是有一些麻烦,我们再尝试修改一下代码,让dependencies变成一个对象,既存相对路径又存相对于根目录的路径。
const fs = require('fs')
const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
+++ const dependencies = {}
traverse(ast, {
ImportDeclaration ({ node }) {
const dirname = path.dirname(filename)
// const newFile = '/' + path.join(dirname, node.source.value) mac下使用这条
const newFile = './' + path.posix.join(dirname,node.source.value)
+++ dependencies[node.source.value] = newFile
}
})
console.log(dependencies)
}
moduleAnalyser('./src/index.js')
运行,得到下面的结果

这样操作以后,我们就可以找到,相对路径对应的根目录路径的关系了。
到这里,我们就可以分析出入口文件所对应的依赖关系了。具体代码如下
const fs = require('fs')
const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = {}
traverse(ast, {
ImportDeclaration ({ node }) {
const dirname = path.dirname(filename)
const newFile = './' + path.posix.join(dirname,node.source.value)
dependencies[node.source.value] = newFile
}
})
return {
filename,
dependencies
}
}
moduleAnalyser('./src/index.js')
转化ESM
我们通过上面的操作,已经分析出了入口文件所对应的依赖关系,但这是远远不够的,我们现在的文件还是通过ESM进行模块引入的,下面我们将使用babel将其转为能够在浏览器下运行的模块形式。
我们需要安装@babel/core(用来将AST转成浏览器可用的代码)和@babel/preset-env(用来将ES6代码转成ES5的),安装完成后,我们参照官网的API对其进行配置
const fs = require('fs')
const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
+++ const babel = require('@babel/core')
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = {}
traverse(ast, {
ImportDeclaration ({ node }) {
const dirname = path.dirname(filename)
const newFile = './' + path.posix.join(dirname,node.source.value)
dependencies[node.source.value] = newFile
}
})
+++ const { code } = babel.transformFromAst(ast, null, { // 通过babel转译后,会暴露一下code字段,里面是我们的代码
presets: ['@babel/preset-env']
})
console.log(code)
return {
filename,
dependencies
}
}
moduleAnalyser('./src/index.js')
我新增的代码实现了如下功能
- 将AST抽象语法树转化成代码
- 将es6代码转化成es5代码
运行一个看看结果

再来对比一下index.js内容
import message from './message'
console.log(message)
是不是就正常转译了呢?最后我们再将生成的code同依赖关系一同返回出去,最终代码如下
const fs = require('fs')
const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = {}
traverse(ast, {
ImportDeclaration ({ node }) {
const dirname = path.dirname(filename)
const newFile = './' + path.posix.join(dirname,node.source.value)
dependencies[node.source.value] = newFile
}
})
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env']
})
return {
code,
filename,
dependencies
}
}
moduleAnalyser('./src/index.js')
我们可以打印一下moduleAnalyser('./src/index.js')的执行结果,如下

这样我们从上面就得到了三个信息
- 入口文件为'./src/index.js'
- 他引用了一个和它的路径关系为./message的文件,其真实路径是./src/message.js
- 入口文件的源码转译成在浏览器上运行的代码后
到这里,我们已经完成了一个bundler的第一步,做代码分析,但我们只是分析了入口文件,下面,我们将对其他文件进行分析,对其他文件的分析,也叫Dependencies Graph(依赖图谱),在讲解下面的内容时,我们还是要对前面对单入口文件的分析过程做一个熟悉!
Dependencies Graph(依赖图谱)
上面对单个文件做了分析,实际上,项目是一层一层的依赖关系,这就需要我们一层一层的对没一个文件做分析。要想实现这样的效果,我们接着完善我们的代码。
再创建一个方法,将所有的依赖关系都存到里面。所以,我们先改造上面的代码如下
const fs = require('fs')
const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = {}
traverse(ast, {
ImportDeclaration ({ node }) {
const dirname = path.dirname(filename)
// const newFile = '/' + path.join(dirname, node.source.value)
const newFile = './' + path.posix.join(dirname,node.source.value)
dependencies[node.source.value] = newFile
}
})
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env']
})
return {
code,
filename,
dependencies
}
}
+++ const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry)
console.log(entryModule)
}
--- moduleAnalyser('./src/index.js')
+++ const graphInfo = makeDependenciesGraph('./src/index.js')
我们执行上面的代码,结果和之前没有创建这个方法时一样,只不过,我们这里通过一个入口文件作为参数,先对入口文件做上面同样的分析,之后还可以在里面做关于其他模块的分析。那么我们如何一层一层对其他模块做分析呢?看下面代码,我做了标注,大家尽量去理解
const fs = require('fs')
const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = {}
traverse(ast, {
ImportDeclaration ({ node }) {
const dirname = path.dirname(filename)
// const newFile = '/' + path.join(dirname, node.source.value)
const newFile = './' + path.posix.join(dirname,node.source.value)
dependencies[node.source.value] = newFile
}
})
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env']
})
return {
code,
filename,
dependencies
}
}
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry)
+++ const graphArray = [entryModule]
+++ for (let i = 0; i < graphArray.length; i++) { // 对文件组成数组graphArray进行遍历
const item = graphArray[i]
const { dependencies } = item // 拿到入口文件的依赖关系,如{ './message': './src/message' },并对其做进一步分析
if (dependencies) {
for (let j in dependencies) { // 使用for..in遍历对象
graphArray.push(moduleAnalyser(dependencies[j]))
}
}
}
console.log(graphArray)
}
const graphInfo = makeDependenciesGraph('./src/index.js')
上面的代码中,我们先是通过对入口文件进行分析,在分析到入口文件对应的依赖后,再将入口文件对应的依赖,push进依赖图谱的数组中,接着执行分析,这样我们就通过队列的形式,一层一层从入口文件开始,对整个项目中的依赖做了一个分析,执行上面的代码,结果如下
[
{
code: '"use strict";\n' +
'\n' +
'var _message = _interopRequireDefault(require("./message.js"));\n' +
'\n' +
'function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\n' +
'\n' +
'console.log(_message["default"]);',
filename: './src/index.js',
dependencies: { './message.js': './src/message.js' }
},
{
code: '"use strict";\n' +
'\n' +
'Object.defineProperty(exports, "__esModule", {\n' +
' value: true\n' +
'});\n' +
'exports["default"] = void 0;\n' +
'\n' +
'var _word = require("./word.js");\n' +
'\n' +
'var message = "say ".concat(_word.word);\n' +
'var _default = message;\n' +
'exports["default"] = _default;',
filename: './src/message.js',
dependencies: { './word.js': './src/word.js' }
},
{
code: '"use strict";\n' +
'\n' +
'Object.defineProperty(exports, "__esModule", {\n' +
' value: true\n' +
'});\n' +
'exports.word = void 0;\n' +
"var word = 'hello';\n" +
'exports.word = word;',
filename: './src/word.js',
}
]
可以看到哈,我们一层一层分析出了整个项目中的的依赖关系,每个文件名都对应一个依赖关系(如果有)。我们把这个数组叫做依赖图谱
现在他的数据结构是一个数组,我们需要把他转换一下数据结构,来适应后面的操作,完善makeDependenciesGraph函数
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry)
const graphArray = [entryModule]
for (let i = 0; i < graphArray.length; i++) { // 对文件组成数组graphArray进行遍历
const item = graphArray[i]
const { dependencies } = item // 拿到入口文件的依赖关系,如{ './message': './src/message' },并对其做进一步分析
if (dependencies) {
for (let j in dependencies) { // 使用for..in遍历对象
graphArray.push(moduleAnalyser(dependencies[j]))
}
}
}
const graph = {}
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
console.log(graph)
return graph
}
经过上面的操作,我们的数据结构变成了下面这样
{
'./src/index.js': {
dependencies: { './message.js': './src/message.js' },
code: '"use strict";\n' +
'\n' +
'var _message = _interopRequireDefault(require("./message.js"));\n' +
'\n' +
'function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\n' +
'\n' +
'console.log(_message["default"]);'
},
'./src/message.js': {
dependencies: { './word.js': './src/word.js' },
code: '"use strict";\n' +
'\n' +
'Object.defineProperty(exports, "__esModule", {\n' +
' value: true\n' +
'});\n' +
'exports["default"] = void 0;\n' +
'\n' +
'var _word = require("./word.js");\n' +
'\n' +
'var message = "say ".concat(_word.word);\n' +
'var _default = message;\n' +
'exports["default"] = _default;'
},
'./src/word.js': {
dependencies: {},
code: '"use strict";\n' +
'\n' +
'Object.defineProperty(exports, "__esModule", {\n' +
' value: true\n' +
'});\n' +
'exports.word = void 0;\n' +
'exports.word = word;'
}
}
到这里,我们已经把整个项目中,所有文件之间的依赖结果分析出来,下一步,我们将让这些代码变成可以运行在浏览器的代码
代码生成
我们已经拿到了依赖图谱,下一步,就是把依赖图谱生成为代码,我们在bundler.js中再创建一个函数,我们知道,js在浏览器中的运行,实际上是在一个大的闭包里面去执行的,这样就会避免污染全局变量,所以,我们要生成的代码也是这样的形式,函数内容如下
+++ const generateCode = (entry) => {
const graph = makeDependenciesGraph(entry)
return `
(function (graph) {
})(${graph})
`
}
+++ const code = generateCode('./src/index.js')
+++ console.log(code)
--- const graphInfo = makeDependenciesGraph('./src/index.js')
我们是期望把整个依赖图谱都传进我们生成的函数中的,然后对其进行操作,但实际上,通过上面的代码运行,你会发现生成的代码是
(function (graph) {
})([object Object])
这样的,因为我们是生成一个字符串的,把对象传进字符串就会出现上面的结果,所以,我们需要把依赖图谱转成字符串传进去,代码应该是这样的
const generateCode = (entry) => {
const graph = JSON.stringify(makeDependenciesGraph(entry))
return `
(function (graph) {
})(${graph})
`
}
const code = generateCode('./src/index.js')
console.log(code)
这样就可以生成下面正确的结果了
(function (graph) {
})({"./src/index.js":{"dependencies":{"./message.js":"./src/message.js"},"code":"\"use strict\";\n\nvar _message = _interopRequireDefault(require(\"./message.js\"));\n\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { \"default\": obj }; }\n\nconsole.log(_message[\"default\"]);"},"./src/message.js":{"dependencies":{"./word.js":"./src/word.js"},"code":"\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", {\n value: true\n});\nexports[\"default\"] = void 0;\n\nvar _word = require(\"./word.js\");\n\nvar message = \"say \".concat(_word.word);\nvar _default = message;\nexports[\"default\"] = _default;"},"./src/word.js":{"dependencies":{},"code":"\"use strict\";\n\nObject.defineProperty(exports, \"__esModule\", {\n value: true\n});\nexports.word = void 0;\nvar word = 'hello';\nexports.word = word;"}})
而现在,我们要去做的就是写闭包函数体里的内容,这是生成代码的关键
完善闭包函数体生成代码
我们回头看一下生成的依赖图谱中,没一个文件,都有一个require和exports方法,而这些代码在浏览器中是肯定不能执行的,所以我们第一步就是要构建一个require和exports的函数。
const generateCode = (entry) => {
const graph = JSON.stringify(makeDependenciesGraph(entry))
return `
(function (graph) {
function require (module) {
(function (code) {
eval(code)
})(graph[module].code)
}
require('${entry}')
})(${graph})
`
}
const code = generateCode('./src/index.js')
这里有点绕,咱们一步一步来,上面代码的意思是,我将入口文件地址传入require函数,通过graph[module].code拿到对应图谱下的代码(这里又是一个闭包),并通过evel做转译,实际上,此时的code是这样的,(我们从上面图谱中把index.js对应的代码拿到,并格式化)
"use strict"
var _message = _interopRequireDefault(require("./message.js"))
function _interopRequireDefault(obj) {
return obj && obj.__esModule ? obj : { "default": obj };
}
console.log(_message["default"])
我们发现,这代码里面还是有require函数,并且文件路径是相对于index.js的路径,而我们如果再次递归执行我们写的require函数的话,是没法通过相对路径拿到对应图谱中的代码的,这一点我们又要做特殊处理。
const generateCode = (entry) => {
const graph = JSON.stringify(makeDependenciesGraph(entry))
return `
(function (graph) {
function require (module) {
function localRequire (relativePath) {
return require(graph[module].dependencies[relativePath])
}
(function (require,code) {
eval(code)
})(localRequire, graph[module].code)
}
require('${entry}')
})(${graph})
`
}
这里再讲解一下这段新加的代码 ,因为我们通过自己定义的require后,通过evel转译的代码,还是要执行原生的require,并且还是引用的相对路径,为了解决这个问题,我们首先需要在evel中执行的代码里,不再使用现在的相对路径引用,这就需要我们定义一个工具函数,这个函数的作用就是把相对路径通过从依赖图谱中查找,找出对应的‘绝对路径’(实际上为相对于根目录的路径),这就是为什么我们的dependencies当时要转换成{'相对路径':'绝对路径'}的原因。这样,我们把自定义这个函数传进闭包中,就可以让evel执行的代码,使用我们转换后的路径了。
定义exports对象
实现完require功能后,我们再回头看依赖图谱,会发现,在最终的代码中是有Object.defineProperty(exports, "__esModule", ...这样的内容的,也就是说,在evel执行的源码中,是有应该有一个exports的空对象来供代码操作的,所以我们要将这个空对象传入,实际上,我们传入的这个空对象,能保证,依赖之间相互引用的时候,可以拿到上一个模块的导出结果。
代码如下
const generateCode = (entry) => {
const graph = JSON.stringify(makeDependenciesGraph(entry))
return `
(function (graph) {
function require (module) {
function localRequire (relativePath) {
return require(graph[module].dependencies[relativePath])
}
+++ var exports = {};
(function (require, exports, code) {
eval(code)
})(localRequire, exports, graph[module].code);
+++ return exports;
};
require('${entry}')
})(${graph});
`;
}
上面就是最终我们生成代码的逻辑,实际上,是一个大的字符串,这时候我们再执行打包命令,将生成的代码运行在在浏览器下,发现,代码正常运行了!
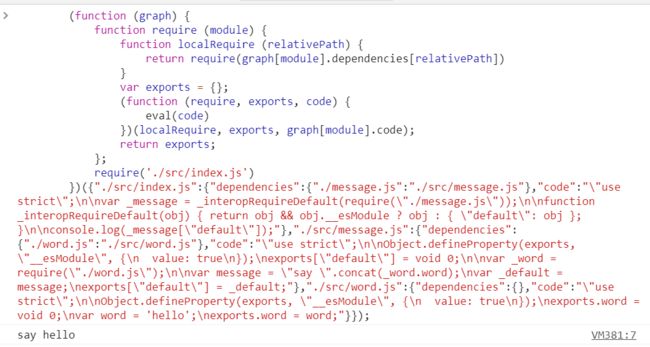
写在后面
我们通过很大篇幅,很细节的讲解,为大家演示了一个打包工具的编写,在编写的时候,也是深刻的体会打包工具的运行流程,在这个过程中,我们用到了很多的知识点,包括比较高级的babel,nodejs等,还用到了递归,闭包等,可以说对知识的储备量要求也是比较高的,我们也可以通过一个打包工具的编写,将一些知识串联起来,最主要的是,我们通过编写一个打包工具,对webpack等打包工具的运行原理,也会有一定的了解。那么你在使用webpack的时候就会对其更加的熟悉。本文涉及到了一些坑点,如果你有兴趣跟着做了,踩到坑无法脱坑的话,欢迎私信我!爱前端,爱分享,披荆斩棘,大家加油!
下面附上最终的bundler.js代码
const fs = require('fs')
const path = require('path')
const paresr = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
const moduleAnalyser = (filename) => {
const content = fs.readFileSync(filename, 'utf-8')
const ast = paresr.parse(content, {
sourceType: 'module'
})
const dependencies = {}
traverse(ast, {
ImportDeclaration ({ node }) {
const dirname = path.dirname(filename)
// const newFile = '/' + path.join(dirname, node.source.value)
const newFile = './' + path.posix.join(dirname,node.source.value)
dependencies[node.source.value] = newFile
}
})
const { code } = babel.transformFromAst(ast, null, {
presets: ['@babel/preset-env']
})
return {
code,
filename,
dependencies
}
}
const makeDependenciesGraph = (entry) => {
const entryModule = moduleAnalyser(entry)
const graphArray = [entryModule]
for (let i = 0; i < graphArray.length; i++) { // 对文件组成数组graphArray进行遍历
const item = graphArray[i]
const { dependencies } = item // 拿到入口文件的依赖关系,如{ './message': './src/message' },并对其做进一步分析
if (dependencies) {
for (let j in dependencies) { // 使用for..in遍历对象
graphArray.push(moduleAnalyser(dependencies[j]))
}
}
}
const graph = {}
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
})
return graph
}
const generateCode = (entry) => {
const graph = JSON.stringify(makeDependenciesGraph(entry))
return `
(function (graph) {
function require (module) {
function localRequire (relativePath) {
return require(graph[module].dependencies[relativePath])
}
var exports = {};
(function (require, exports, code) {
eval(code)
})(localRequire, exports, graph[module].code);
return exports;
};
require('${entry}')
})(${graph});
`;
}
const code = generateCode('./src/index.js')
console.log(code)