一次线上游戏卡死的解决历程
GitChat 作者:杨彪
原文:一次线上游戏卡死的解决历程
关注微信公众号:GitChat 技术杂谈 ,一本正经的讲技术
【不要错过文末活动】
事故的发生详细过程
故事是发生在几个月前的线上真实案例,我将在本文中以故事形式为大家还原这次解决游戏卡死的经历过程,其中有很多线上实战经验和技巧都值得分享借鉴的,也有作者自创的处理线上问题“四部曲”–望问闻切,还有最经典的“甩锅”秘诀。不管白猫黑猫,能立马解决线上问题的就是好猫,线上问题实战经验最重要。下来就让我先来回顾下这次事故发生的背景吧。
公司的游戏获得了Google Play的最佳新游推荐位展示,这代表着公司游戏可以在Google Play首页持续一周的全球推荐。如果对Google Play还不了解的小伙伴们可以看看下图,展示了Google Play推荐位的效果:
就是在这样一个重大利好消息推动下,项目研发组紧急加班加点地赶制进度和进行游戏压力测试(以后有机会详细写篇游戏压力测试机器人实现方案),最后内网测试环境(Testing Environment)和预生产环境(Staging Environment)一切都测试正常,随时等待更新线上正式坏境了。
像以往一样,游戏发布了停服更新公告(由于新增加了联盟战和几个大的活动,担心不停服更新有问题),执行完停服、备份、更新等一系列自动化流程后,服务器状态变为“更新完毕,白名单可进入”状态,然后通知QA进行上线前的最后一次生产环境(Production Environment)测试。整个项目的同学和QA同学以白名单身份在线上生产环境测试了近半个小时,没有任何bug和异常,我们就信心满满的准备开服了。
游戏对外开放后,我们像往常一样边观察边继续做着新的工作,突然公司运营同学过来说游戏怎么感觉好卡,我们的第一反应是你网卡了吧(因为游戏服务器在国外,中间有一道不可逾越的qiang),我也没太在意还是继续做着别的事情,后来QA同学也说游戏好卡啊,我自己也登陆游戏试了下,确实挺卡,每一次操作都要等待好久,不过到现在我还是没有意识到服务器卡了,只是让运维同学查看游戏服的log有没有报错,而日志显示似乎一切都正常(后面会解释为什么日志还正常地输出)。
慢慢地游戏内的聊天中开始有玩家反馈这次更新后游戏太卡,而且反馈的用户越来越多,我这才意识到问题的严重性了,游戏服肯定哪里操作太慢反应迟钝了(之前可能因为游戏公测到现在大半年还没出现过事故,所以有点掉以轻心了)。
公司BOSS也过来问怎么回事,正值Google Play推荐导量的时期,公司上下非常重视。当然我知道越是面对大问题,有经验的人就越要冷静,我直觉得给BOSS说:“服务器有点卡了,小问题,马上就能弄好的,别着急”。其实当时我心里也没底,不知道问题在哪,不过根据自己以往经验和实践操作,只要按照“四步曲”流程化的执行一遍,肯定能找到点线索和眉目的。
更多的线上应急和技术攻关可以参照我和朋友合著的《分布式服务架构:原理、设计与实战》一书中的第六章“Java服务的线上应急和技术攻关”,该章中介绍了海恩法则和墨菲定律,以及线上应急目标、原则和方法,同时提供了大量的Linux和JVM命令,也有很多平时工作中常用的自定义脚步文件和实际案例。
接下来我们一起,一步步地解决游戏卡死的问题,文章中很多截图只是本次文章演示说明,不是当时的现场截图,不过我会说明清楚尽量还原线上真实过程。
事故的处理过程还原
解决线上问题的“四部曲”
望:就是观察的意思,出了问题最重要一点就是观察线上问题发生的规律,切忌有病乱投医,一上来就先各种偿试各种改的。除了观察现象外,我们还要观察各种日志、监控和报警系统,具体如何搭建“大数据日志监控系统”请参照作者书的第四章。
问:就是问清楚现在问题发生的情况,这个很重要,后面会重点介绍具体需要问清楚的哪些问题。
闻:就是认真听取别人的意见,有时线上出了问题,我们大多数心里还是比较抵触别人说这说那的,不过在这种情况下,我们更应该多听,找到可能引起问题的情况或有关的事情,同时也为后面的“甩锅”技巧打开思路。
切:就是动手实践验证了,通过前面的观察、询问问题,我们心中应该能有些假设和猜测的线索了,这时候就需要动手在测试环境或预生产环境上进一步验证我们的假设是否成立了。
下面这张图概括的介绍了“望问闻切”各阶段需要关心和注重的事情:

前面通过对“四部曲”的介绍,大家可能会觉得很抽象,不过它是我们解决线上问题的指导方针、核心思想,那我们在实际项目中又是如何“望问闻切”的呢?
首先是如何发现问题
发现问题通常通过自动化的监控和报警系统来实现,线上游戏服搭建了一个完善、有效的日志中心、监控和报警系统,通常我们会对系统层面、应用层面和数据库层面进行监控。
对系统层面的监控包括对系统的CPU利用率、系统负载、内存使用情况、网络I/O负载、磁盘负载、I/O 等待、交换区的使用、线程数及打开的文件句柄数等进行监控,一旦超出阈值, 就需要报警。对应用层面的监控包括对服务接口的响应时间、吞吐量、调用频次、接口成功率及接口的波动率等进行监控。
对资源层的监控包括对数据库、缓存和消息队列的监控。我们通常会对数据库的负载、慢 SQL、连接数等进行监控;对缓存的连接数、占用内存、吞吐量、响应时间等进行监控;以及对消息队列的响应时间、吞吐量、负载、积压情况等进行监控。
其次是如何定位问题
定位问题,首先要根据经验来分析,如果应急团队中有人对相应的问题有经验,并确定能够通过某种手段进行恢复,则应该第一时间恢复,同时保留现场,然后定位问题。
在应急人员定位过程中需要与业务负责人、技术负责人、核心技术开发人员、技术专家、
架构师、运营和运维人员一起,对产生问题的原因进行快速分析。在分析过程中要先考虑系统最近发生的变化,需要考虑如下问题。
问题系统最近是否进行了上线?
依赖的基础平台和资源是否进行了上线或者升级?
依赖的系统最近是否进行了上线?
运营是否在系统里面做过运营变更?
网络是否有波动?
最近的业务是否上量?
服务的使用方是否有促销活动?
然后解决问题
解决问题的阶段有时在应急处理中,有时在应急处理后。在理想情况下,每个系统会对各种严重情况设计止损和降级开关,因此,在发生严重问题时先使用止损策略,在恢复问题后再定位和解决问题。解决问题要以定位问题为基础,必须清晰地定位问题产生的根本原因,再提出解决问题的有效方案,切记在没有明确原因之前,不要使用各种可能的方法来尝试修复问题,这样可能还没有解决这个问题又引出另一个问题。
最后消除造成的影响
在解决问题时,某个问题可能还没被解决就已恢复,无论在哪种情况下都需要消除问题产生的影响。
技术人员在应急过程中对系统做的临时性改变,后证明是无效的,则要尝试恢复到原来的状态。
技术人员在应急过程中对系统进行的降级开关的操作,在事后需要恢复。
运营人员在应急过程中对系统做的特殊设置如某些流量路由的开关,需要恢复。
对使用方或者用户造成的问题,尽量采取补偿的策略进行修复,在极端情况下需要一一核实。
对外由专门的客服团队整理话术统一对外宣布发生故障的原因并安抚用户,话术尽量贴近客观事实,并从用户的角度出发。
当我们详细地了解了如何发现问题、定位问题、解决问题和消除造成的影响后,接下来让我们看下本次解决线上游戏卡死过程中是如何具体的应用的。
排查游戏卡死的过程
第一步,找运维看日志
如果日志监控系统中有报错,谢天谢地,很好定位问题,我们只需要根据日志报错的堆栈信息来解决。如果日志监控系统中没有任何异常信息,那么接下来就得开始最重要的保存现场了。
第二步,保存现场并恢复服务
日志系统中找不到任何线索的情况下,我们需要赶紧保存现场快照,并尽快恢复游戏服务,以达到最大程度止损的目的。
通常JVM中保存现场快照分为两种:
保存当前运行线程快照。
保存JVM内存堆栈快照。其方法如下:
保存当前运行线程快照,可以使用
jstack [pid]命令实现,通常情况下需要保存三份不同时刻的线程快照,时间间隔在1-2分钟。保存JVM内存堆栈快照,可以使用
jmap –heap、jmap –histo、jmap -dump:format=b,file=xxx.hprof等命令实现。
快速恢复服务的常用方法:
隔离出现问题的服务,使其退出线上服务,便于后续的分析处理。
偿试快速重启服务,第一时间恢复系统,而不是彻底解决问题。
对服务降级处理,只使用少量的请求来重现问题,以便我们可以全程跟踪观察,因为之前可能没太注意这个问题是如何发生的。
通过上面一系列的操作后,保存好现场环境、快照和日志后,我们就需要通过接下来的具体分析来定位问题了。
第三步,分析日志定位问题
这一步是最关键的,也是需要有很多实战经验的,接下来我将一步步还原当时解决问题的具体操作步聚。
诊断服务问题,就像比医生给病人看病一样,需要先查看一下病人的脸色如何、摸一摸有没有发烧、或再听听心脏的跳动情况等等。同样的道理,我们需要先查看服务器的“当前症状”,才能进一步对症下药。
首先使用top命令查看服务器负载状况
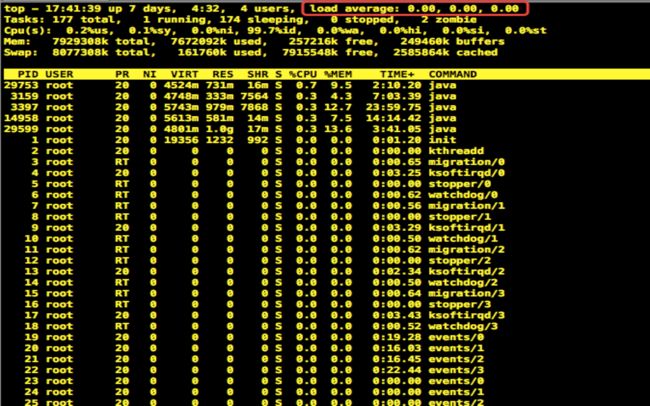
load average一共有三个平均值:1分钟系统负荷、5分钟系统负荷,15分钟系统负荷。哪我们应该参考哪个值?
如果只有1分钟的系统负荷大于1.0,其他两个时间段都小于1.0,这表明只是暂时现象,问题不大。
如果15分钟内,平均系统负荷大于1.0,表明问题持续存在,不是暂时现象。所以,你应该主要观察”15分钟系统负荷”,将它作为服务器正常运行的指标。说明:我们当时服务器负载显示并不高,所以当时第一反应就排除了承载压力的问题。
接下来再使用top命令+1查看CPU的使用情况
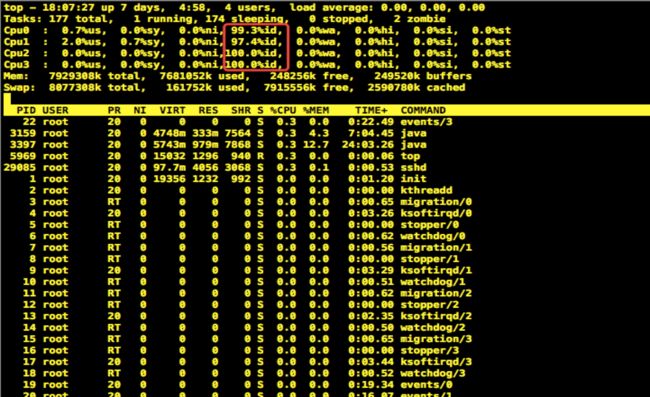
我们主要关注红框中指标,它表示当前cpu空闲情况,而其它各指标具体含义如下:
0.7%us:用户态进程占用CPU时间百分比,不包含renice值为负的任务占用的CPU的时间。
0.0%sy:内核占用CPU时间百分比。
0.0%ni:改变过优先级的进程占用CPU的百分比。
99.3%id:空闲CPU时间百分比。
0.0%wa:等待I/O的CPU时间百分比。
0.0%hi:CPU硬中断时间百分比。
0.0%si:CPU软中断时间百分比。
说明:我们线上服务器为8核16G的配置,当时只有一个cpu显示繁忙,id(空闲时间百分比)为50%左右,其余显示90%多。从这里看似乎没有什么太大的问题。
既然cpu负载和使用都没太大问题,那是什么卡住了服务呢?直觉告诉我,可能是线程死锁或等待了什么耗时的操作,我们接下来就来查看线程的使用情况。不过在查看线程使用情况之前,我们首先看看JVM有没有出现内存泄漏(即OOM问题,我的书中有介绍一个实际OOM的案例),因为如果JVM大量的出现FGC也会造成用户线程卡住服务变慢的情况。
使用jstat –gcutil pid查看堆中各个内存区域的变化以及GC的工作状态
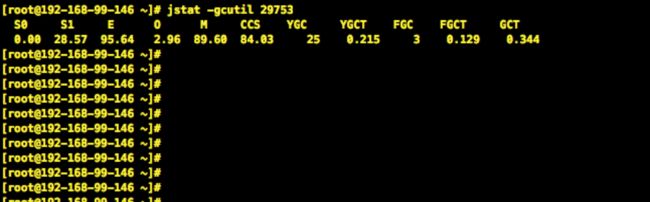
S0:幸存1区当前使用比例
S1:幸存2区当前使用比例
E:伊甸园区使用比例
O:老年代使用比例
M:元数据区使用比例
CCS:压缩使用比例
YGC:年轻代垃圾回收次数
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
说明:当时服务也没有出现大量的FGC情况,所以排除了有OOM导致的用户线程卡死。
- 接下来使用top命令+H查看线程的使用情况
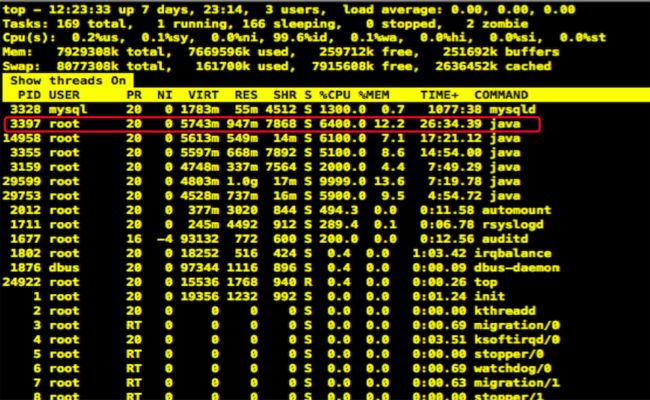
PID:进程的ID
USER:进程所有者
PR:进程的优先级别,越小越优先被执行
NInice:值
VIRT:进程占用的虚拟内存
RES:进程占用的物理内存
SHR:进程使用的共享内存
S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数
%CPU:进程占用CPU的使用率
%MEM:进程使用的物理内存和总内存的百分比
TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。
COMMAND:进程启动命令名称
说明:通过查看线程%CPU指标,明显能看到某个java线程执行非常占用CPU,因此断定该线程当时出现了问题。那么我们接下来如何找到这个线程当时在干嘛呢?请看以下三步聚。(图片只是示意图,不是当时线上截图)
- 使用jstack pid打印进程中线程堆栈信息,我们可以使用如下三步找出最繁忙的线程信息。
查看进程中各线程占用cpu状态, 选出最繁忙的线程id,使用命令top -Hp pid
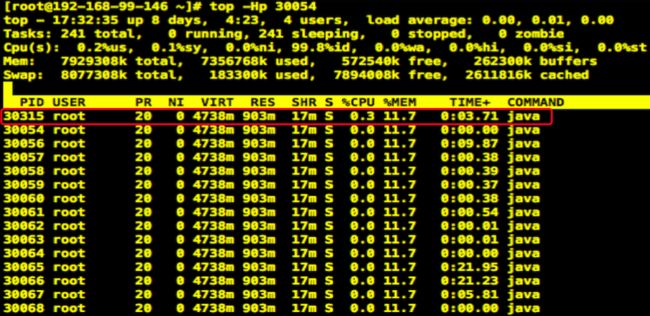
把线程id转成16进制,使用命令printf “%x\n”{线程id}

打印当前线程运行的堆栈信息,查找线程id为0x766B的线程堆栈信息
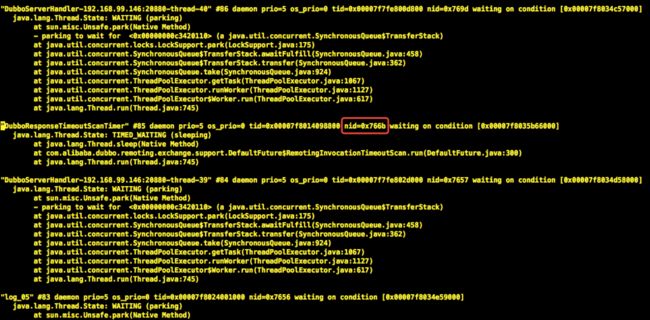
说明:线上通过打印繁忙线程,查看线程的执行堆栈,并没有找到被卡住的业务代码,每次都是执行成功的。当时就非常纳闷,为什么一直只是这一个线程在不停地消耗着CPU,突然一个编程的小技巧帮我找到了问题的罪魁祸首——线程中任务分配不均导致的服务响应变慢。
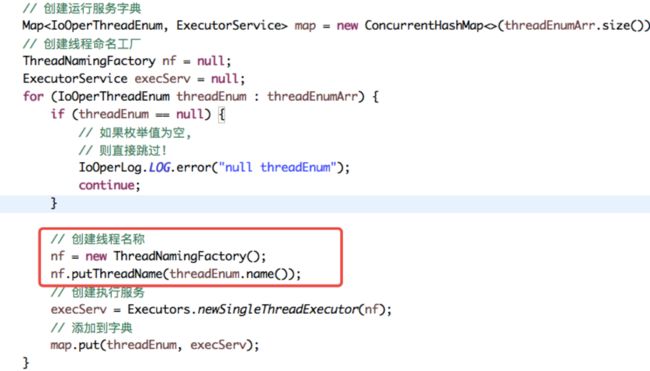
小技巧:为不同的业务线程自定义名称,比如打印日志的线程为
log_xxx,接收消息请求的线程为msg_xxx,游戏业务线程为game_xxx等。java中具体如何为线程命令如下图所示:
- 罪魁祸首——分布式唯一ID生成器

通过上面红框中的代码我们可以看到,线程任务的分配规则是通过用户的uuid模上线程池的长度,这样实现的目的是想让同一个用户的所有请求操作都分配到同一个线程中去完成(线程亲和性),这样的实现是为了从用户角度保证线程的安全性,不会出现多线程下数据的不一致性。
而问题就出现在这个uuid取模上了,我们使用的是Twitter的分布式自增ID算法snowflake,而它生成的所有id刚好与我设置的线程池大小64取模后为0(具体原因不明),导致所有用户的所有请求全部分配到了一个线程中排队执行了。这也是为什么在查看线程堆栈信息时感觉都在正常执行,而打印的所有线程中只看到编号为0的线程在执行,其它都空闲等待。
说明:此功能实现是在上线前两天,运营同学告诉说,有玩家反馈前一刻领取到的钻石在下一刻莫名消失了,我的第一反应肯定是多线程造成的,所以就临时采取了这种线程亲和方式统一解决了线程安全的问题。现在找到了问题产生的原因,接下来看是如何解决的。
- 使用MurmurHash散列下解决ID生成不均匀的问题
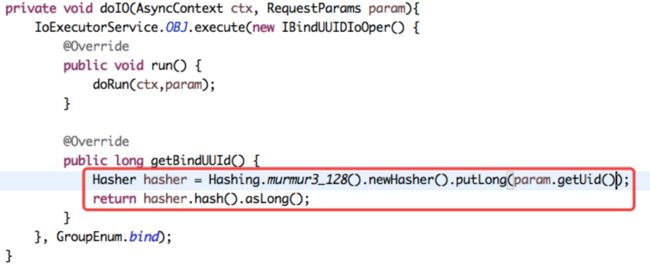
第四步,Hotfix后继续观察情况
在测试环境或预生产环境修改测试后,如果问题不能再复现了,可以根据公司的Hotfix流程进行线上bug更新,并继续观察。如果一切都正常后,需要消除之前可能造成的影响。
一键查看最繁忙线程堆栈脚本
此命令通过结合Linux操作系统的ps命令和JVM自带的jstack命令,来查找Java进程内CPU利用率最高的线程,一般适用于服务器负载较高的场景,并需要快速定位负载高的成因。
此脚本最初来自于互联网,后来为了让其在不同的类UNIX环境下运行,所以我做了一些修改,该命令在我每一次定位负载问题时都起到了重要作用。
命令格式:
./show-busiest-java-threads -p 进程号 -c 显示条数
./show-busiest-java-threads -h使用示例:
./show-busiest-java-threads -p 30054 -c 3
示例输出:

脚本源码见《分布式服务架构:原理、设计与实战》书中241页,更多服务化治理脚本请参照书中的第六章“Java服务的线上应急和技术攻关”。
对本次线上事故的总结
在技术方面,线上问题大致分为以下三类。
CPU繁忙型
线程中出现死循环、线程阻塞,JVM中频繁的垃圾回收,或者线程上下文切换导致。
常用命令
top、jstack [pid]和Btrace等工具排查解决。
内存溢出型
堆外内存: JNI的调用或NIO中的DirectByteBuffer等使用不当造成的。
堆内内存:程序中创建的大对象、全局集合、缓存、 ClassLoader加载的类或大量的线程消耗等容易引起。
常用的命令有
jmap –heap、jmap –histo、jmap -dump:format=b,file=xxx.hprof等查看JVM内存情况的。
IO读写型
文件IO:可以使用命令
vmstat、lsof –c -p pid等。网络IO: 可以使用命令
netstat –anp、tcpdump -i eth0 ‘dst host 239.33.24.212’ -w raw.pcap和wireshark工具等。
以上只是简单的介绍了下相关问题分类和常用命令工具,由于篇幅有限更多内容请参照《分布式服务架构:原理、设计与实战》书中“线上应急和技术攻关”一章,详细介绍了各种情况下技术命令的使用。
在制度方面的应急处理和响应保障
制定事故的种类和级别
S级事故,核心业务重要功能不可用且大面积影响用户,响应时间:立即。
A级事故,核心业务重要功能不可用,但影响用户有限;周边业务功能不可用且大面积影响用户体验,响应时间:小于15分钟。
B级事故,周边业务功能不可用,轻微影响用户体验,响应时间:小于4小时。
说明:每个公司定义的事故种类和级别都不一样,具体情况具体分析,只要公司有了统一化的标准,当我们遇到线上问题时才不会显的杂乱无章,知道事情的轻重缓急,以及如何处理和什么时候处理。
对待事故的态度
保存现场并减少损失,第一时间恢复服务,减少线上损失,保存好现在所有信息用于问题分析定位。
积极主动的解决问题,线上问题第一时间解决,也是展现个人能力的最佳时机。
主动承担部分责任,承担自己能承担的责任,毕竟事故涉及KPI考核等问题,有时也需要混淆问题原因,拒绝老实人背锅。
不要轻信经验,线上无小事,而大多引起线上事故的问题一般都是小问题,所以一定不要轻信经验,每一项改动都必须经过测试。
说明:当线上出现问题后,大多数人第一反应可能是“这不关我事,我写的东西没问题”,面对线上问题不要怕承担责任,反而正是我们表现个人能力的最好时机。平时大家可能做了非常多的工作,勤勤恳恳的努力奉献着,最后BOSS连你的名字可能都没记住,尴尬!!但是一旦线上遇到问题,可能直接就造成很大的经济损失,全项目组甚至全公司都在关注的时候,你勇于站出来完美的解决了该问题,收获的成就会是相当大的。当然在这个过程中,我们也要学会“合理地甩锅”,具体的“甩锅”请听我直播。
实录:《杨彪:线上游戏卡死问题实战解析》
【GitChat达人课】
- 前端恶棍 · 大漠穷秋 :《Angular 初学者快速上手教程 》
- Python 中文社区联合创始人 · Zoom.Quiet :《GitQ: GitHub 入味儿 》
- 前端颜值担当 · 余博伦:《如何从零学习 React 技术栈 》
- GA 最早期使用者 · GordonChoi:《GA 电商数据分析实践课》
- 技术总监及合伙人 · 杨彪:《Gradle 从入门到实战》
- 混元霹雳手 · 江湖前端:《Vue 组件通信全揭秘》
- 知名互联网公司安卓工程师 · 张拭心:《安卓工程师跳槽面试全指南》