Python爬虫学习笔记_DAY_22_Python爬虫之jsonpath的安装与语法详细介绍【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I.jsonpath的介绍
II.jsonpath的安装
III.jsonpath的基础语法介绍
IV.实战演练
I.jsonpath的介绍
首先介绍一下jsonpath是什么:
jsonpath是一种简单的方法来提取给定JSON文档的部分内容。
那么我们为什么要学习jsonpath?原因其实很简单,因为有时候我们拿到的数据是以json为格式的数据,此时我们不再能够使用之前学习的xpath对内容进行解析,因此我们需要一种方法来解析json格式的数据,它就是jsonpath!
II.jsonpath的安装
在语法介绍之前,先安装一下jsonpath库:
安装的方法是这样的:
1️⃣ 首先,我们打开pycharm,选中File - - - > setting
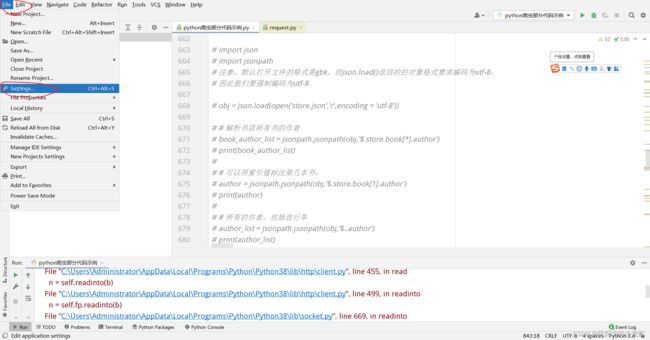
之后选择 Project:xxxx - - - > Python Interpreter

最后按照图中位置,找到自己的python的安装地址,并且进入改地址。

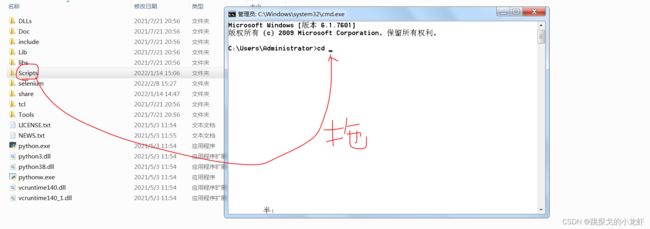
2️⃣ 之后,在地址所示的这个位置,我们按 Win + R,调出终端框,并输入 cd,之后路径还是用拖拽法把Scripts文件夹拖进cd光标后(要在cd后面间隔一个空格):
3️⃣ 最后,在终端框输入下面的指令,安装jsonpath:
pip install jsonpath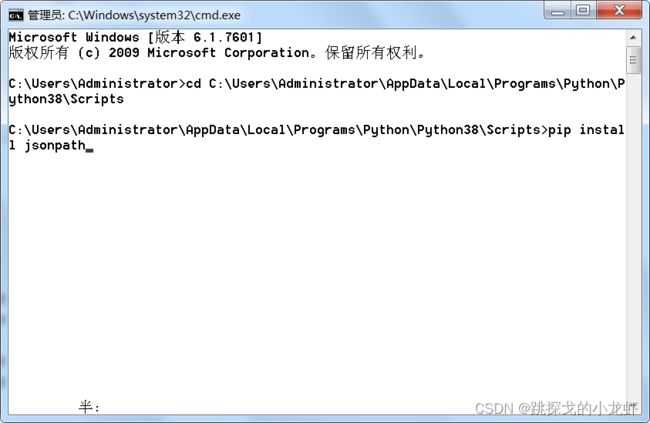
III.jsonpath的基础语法介绍
介绍语法之前,先强调一点,那就jsonpath只能处理本地的json文件,不能直接处理服务器的响应,这是它与xpath的第二点区别(第一点是处理的对象不同)。
然后我们先以下面这个json源码为例子,进行语法介绍:
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"author": "Tony",
"color": "red",
"price": 19.95
}
},
"expensive": 10
}新建一个json文件,把上面的代码拷贝进去,并命名文件,我这里命名为store.json。(或者直接点击这里下载:store.json,提取码:yrso)
1️⃣ 读取一个json文件:
首先介绍如何读入一个json文件,它的语法格式是这样的:
import json
import jsonpath
# 注意,默认打开文件的格式是gbk,但json.load()返回的的对象格式要求编码为utf-8,
# 因此我们要强制编码为utf-8
obj = json.load(open('store.json','r',encoding = 'utf-8'))这里要注意,我们调用函数之前,要先导入json库和jsonpath库;此外,我们通过json.load()函数导入我们的json文件,这个函数的传参不是文件名,而是一个文件对象。
这里多解释一下,也就是说,我们传参是:json.load(文件对象),而不是json.load('store.json'),后者是一个字符串,会报错,至于这个文件对象,我们可以直接用open()函数创建,也可以在外面先用open函数新建一个文件对象,之后将对象传入,二者均可。
对于文件操作不熟悉的朋友参见这篇博客:
Python爬虫学习笔记_DAY_10_Python文件相关操作详细介绍【Python爬虫】_跳探戈的小龙虾的博客-CSDN博客
2️⃣ 解析json文件:
导入后,我们开始学习jsonpath的语法,首先我们参考下表,对照一下jsonpath的语法与xpath:
| XPath | JSONPath | 描述 |
| / | $ | 根元素 |
| . | @ | 当前元素 |
| / | . or [] | 当前元素的子元素 |
| .. | n/a | 当前元素的父元素 |
| // | .. | 当前元素的子孙元素 |
| * | * | 通配符 |
| @ | n/a | 属性的访问字符 |
注意,第一行的/是根元素的意思,也就是说在jsonpath中,每一句jsonpath语言都要以一个$符号开头,后面的部分按照上面与xpath对照进行理解即可。(n/a表示该项不存在)
基于上面的表格,我们能够对前面提到的store.json做如下的实战演练,加强对jsonpath使用的理解:
import json
import jsonpath
# 注意,默认打开文件的格式是gbk,但json.load()返回的的对象格式要求编码为utf-8,
# 因此我们要强制编码为utf-8
obj = json.load(open('store.json','r',encoding = 'utf-8'))
# 解析书店所有书的作者
book_author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')
print(book_author_list)
# 可以用索引值标注第几本书:
author = jsonpath.jsonpath(obj,'$.store.book[1].author')
print(author)
# 所有的作者,包括自行车
author_list = jsonpath.jsonpath(obj,'$..author')
print(author_list)
# store下面所有的元素
tag_list = jsonpath.jsonpath(obj,'$.store.*')
print(tag_list)
# store下面所有的price
price_list = jsonpath.jsonpath(obj,'$.store..price')
print(price_list)
# 第三个书
book = jsonpath.jsonpath(obj,'$.store.book[2]') # 也可以写作 $..book[2]
print(book)
# 最后一本书
# @相当于this,指代当前的每一个对象
# @.length表示当前的json的字典长度
last_book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
print(last_book)
# 前两本书
# 用切片思维:
book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
# 另一种写法:
book_list = jsonpath.jsonpath(obj,'$..book[:2]')
# 过滤包含版本号isbn的书:
# 条件过滤需要在圆括号前面添加一个问号
book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
print(book_list)
# 过滤超过十元的书
book_list = jsonpath.jsonpath(obj,'$..book[?(@.price > 10)]')
print(book_list)IV.实战演练
最后,以某个在线电影购票平台 淘票票 为例,演示一下我们如何在实战中使用jsonpath,目标是获取电影所在的城市的数据:
# jsonpath实战:解析淘票票
import urllib.request
url = 'https://www.taopiaopiao.com/cityAction.json?activityId&_ksTS=1644131295449_132&jsoncallback=jsonp133&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# ':authority': 'www.taopiaopiao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1644131295449_132&jsoncallback=jsonp133&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 't=dfbc218b9596e5fe713a9257db228aca; _tb_token_=67b98bb88177; cookie2=18a239170221d3dd28df664e21f4b954; cna=hy2PGEl1sRYCAasOcD1ZjFr3; xlly_s=1; l=eBgaplzlgQqDYFdMBO5anurza77O5IRb4sPzaNbMiInca6CdtFZujNCp-6e2SdtjgtCUsetyh423FRLHR3jgWwKF_6aeVekj3xvO.; isg=BMLCu1R0F2Lb2As-T-QLuVdRE8gkk8at1HGGkwzbATXgX2LZ9CPFvQ_RD1sjDz5F; tfstk=cUECB-NB2BACx27yYJ6wURXqTjmPayCsIwGLdzm6PPu6JO2E6sYJ0jZIizAi4YH1.',
'referer': 'https://www.taopiaopiao.com/',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# split切割掉jsonp
content = content.split('(')[1].split(')')[0]
with open('taopiaopiao.json','w',encoding = 'utf-8') as fp:
fp.write(content)
import json
import jsonpath
obj = json.load(open('taopiaopiao.json','r',encoding = 'utf-8'))
city_list = jsonpath.jsonpath(obj,'$..regionName')
print(city_list)中间加了一步切割jsonp,这是因为返回的数据中,会加一个jsonp的前缀,这会使得后面的解析出现异常,因此我们要切割这部分,切割方法是打开我们下载下来的json文件,而后分析一下多出来的部分是哪些,而后按照多出来的部分切掉的原则进行切割即可!
为什么淘票票我们不用xpath,因为它返回的数据不是html格式而是json格式,而xpath只能解析html格式的数据!