左程云牛客算法初级班笔记
-
- 第一课
- 第二课
- 第三课
- 第四课
- 第五课
- 第六课
- 第七课
- 第八课
个人的上课笔记 记录了一些算法题细节的理解要点
第一课
估计递归大小复杂度的通式
a子过程样本量 b子过程发生了多少次 0: 除去子过程调用外Tn内部剩下的过程


子问题规模必须一样

02 34 46 小和
第二课
小于等于区域

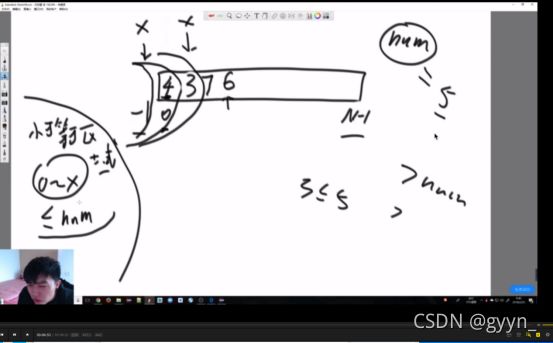
维护一个 小于等于区域 从-1下标开始
从0开始遍历数组 大于num的数不动 ;小于等于num的数 将该数和“小于等于区域”后面一个数字交换位置 将“小于等于区域”位置后移一位(即包括了这个交换后的数字)
荷兰国旗问题

从L开始
当前下标设为cur
Cur = num 不动
Cur
堆:
完全二叉树 概念
数组与完全二叉树

堆的概念
分为大根堆 小根堆
堆就是完全二叉树
大根堆:任何一棵子树的最大值都是这棵子树的头部
小根堆:任何一棵子树的最小值都是这棵子树的头部
让一个数组变成大根堆的过程:
依次把i位置上的数加进来,让它0~i之间形成大根堆
i的父节点: (i-1)/2 如果i比父节点大 就交换 然后接着看父位置 直到我不比我的父大了 停止

如果调到0位置 将会发生 arr【0】和arr【0-1/2】 仍未arr【0】 while停止
建立大根堆 复杂度:收敛于 On

一个大根堆 若其中某个数变小导致不是大根堆 从那个数的位置往下heapify的过程

考虑一个问题 一个流 往外吐数 求每次吐出数后 所有吐出数的中位数
减堆:
已经形成了一个大根堆,弹出堆顶,怎么让它再形成一个大根堆(大小减1): 堆顶弹出 把堆的最后一个数放到堆顶 把标记越界的变量heapsize减1 从0位置开始经历一个heapify
再来考虑中位数问题:
维护一个大根堆一个小根堆 保持大根堆存较小的1/2的数 小根堆存较大的1/2的数 相差不超过1 超过1 数多的堆弹出一个到小的。
例如 流吐数 如果当前数<=大根堆的堆顶就扔到大根堆里去,不平了从大根堆里拿出来一个扔到小根堆
堆排序:维护好一个大根堆 做heapsize次上面所说的弹出堆顶操作

堆这个结构的亮点: 已经形成的大小若为n,进来一个数的代价logn可以搞定
第三课
排序的稳定性
稳定:冒泡 插入 归并(merge过程遇到相等的先拷贝左边的)
不稳定: 选择
快排 不稳定

Partition过程 : 在一个数组中随机选一个数 小于它的放左边 等于它的放中间 大于的放右边
堆排序 不稳定

工程上的综合排序:
数组长: 基础类型:快排
自定义类: 归并 因为 稳定
数组短(<60):插入排序(常数项很低 小样本(60)飞快)
比较器 升序:return 第一个参数-第二个参数

- 什么是堆?
堆就是将一个集合的数据按照完全二叉树的顺序结构存储在一个一维数组中,堆在逻辑上是一棵完全二叉树,在物理结构上是一个一维数组.
按照根结点的大小分为大堆(根结点的值最大)和小堆(根结点的值最小)
1.1 堆的性质
性质:
对于任意一个结点,都要求根的值 大于或等于 其所有子树结点的值
堆是一棵完全二叉树
不基于比较的排序



有一个数组 n个数 准备N+1个桶 把数平均分成n+1份 每个桶存对应范围的数
每一个桶只维护应该进到该桶的数的最大值和最小值,还有一个bool类型:这个桶进没进来过数
遍历桶 空桶跳过 找 当前非空桶最小值和上一个非空调最大值差值最大的 值
为什么不直接找空桶两边的桶?

设计空桶是为了让 最大差值一定不来桶内部
为了否定 最大差值 来自一个桶内部的可能性
用数组结构实现大小固定的队列和栈
栈



队列

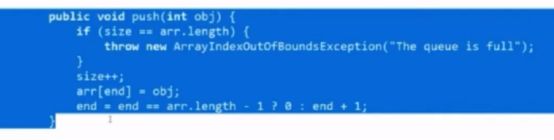
Push操作 把obj放入end指向的位置上 end如果已经来到最后一个位置 跳回到0 如果没到最后一个位置 end+1

Poll 弹出一个数 tmp先记录一下start位置 因为start要调整
Start如果已经来到最后一个位置 则回到0 否则start+1


Data弹出时 min也弹出 压入一个数时 若这个数跟小 min压入这个数否则压入上次压入的数
增加一个空间 维持一个最小值的结构
注:peek操作就是获得栈顶值 但不弹出


Min栈的栈顶就是当前最小值



队列实现栈



Java队列queue的实现 动态数组或者双向链表(就是linkedlist)
准备两个队列 data help
压数的时候只压入data
Pop的时候 只要data里不止一个数 就把data里的数压入help里去
然后data只剩一个数 然后把data弹出来返回给用户
然后进行swap操作(交换两个queue的引用。此时data就是数多的那个queue了,从而让下次pop时能进行上面的操作)
Return结果

Peek操作和pop一样 只多了一个help.add(res)
栈实现队列
准备两个栈

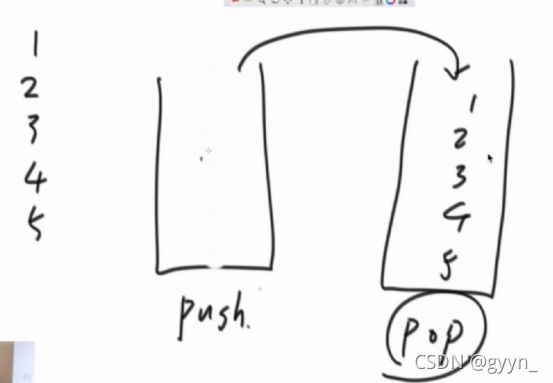
抽象出一个倒数据行为 倒数据行为可以发生在任何时刻 只要满足这两个原则:
如果pop不为空 直接return 倒不了
如果push栈决定往pop栈倒东西 一次倒完
第四课
猫狗队列少视频 书上有 后面再做

子过程:
如何打印边界(最外面一圈)
Tr tc dr dc 分别为左上角点坐标的行 列 右下的行 列



然后让左上角的点往右下移动 右下角的点向左上移动

边界: 左上角的行或者列有一个大于 右上角的行或者列

调度函数就这么短


从外层向里一圈一圈转
四个点一组 1 4 16 13

I=边长-1 也即我需要找“几”组四个点 让他们交换位置
左上角点t(tr,tc)右下角点d(dr,dc)
最上一排和它们依次的点为1 2 3 tr ,tc+i
最左13 9 5 dr-i,tc
最下14 15 16 dr,dc-i
最右 4 8 12 tr+i,dc
之字形打印矩阵

设置A B两个点 都从0 0开始,每次同时走一格 A往右到顶了往下 B往下到底了往右,AB连出一条对角线

实现一个最基本的函数,函数功能:告诉你左下点 和右上点 打印对角线上的数 再加个bool变量 区分左下到右上和右上到坐下
整个流程 用A和B走的步来约束出来 宏观调度

While循环条件:A点行来到最后一行(B点的列到最后一列是一样的)
Printlevel打印对角线

宏观解决具体打印问题 面试不要怯

0 1 2 5
2 3 4 7
4 4 4 8
5 7 7 9

从右上角的点开始 如果比要找的数大 往左移 如果小 往下移 到边界 返回false
一道题目的优秀解: 来自于这道题的数据状况 或它的问法

理解merge过程

链表问题 机试赶快过掉 可以用辅助空间
笔试要求 空间复杂度低
要求不一样
法1 用栈

法2
先用双指针找到中间的节点

然后把后半部分逆序

最后把链表恢复


傻逼视频一卡一卡的


法二

先让一个节点的下一个指针变成它的拷贝节点
、


必听

1、判断单链表有没有环
法一 用hashmap 把每个节点放进hashmap 如果放当前节点发现放入过 该节点就是入环节点
法二 用快慢指针 如果有环 一定会相遇
相遇的时候快指针回到头节点开始走 一次一步 快慢相遇时是入环节点

2、两个无环链表 判断是否相交:
法一 把链表1放到map里 遍历链表2
法二
相交链表最后一个节点一定是相等的 是Y型的 不是X型的 因为链表结构 同一个节点只有一个next指针
先的到两链表长度len1 len2 和最后一个节点end 若end为同一节点
让长的链表先走len1 -len2 步 然后让它们一起走 一定会相遇
3、两个有环链表 判断是否相交 和相交节点
只有一下三种拓扑结构
Loop:入环节点


首先判断 loop1是否=loop2
若相等

这种情况 就是无环链表相交的问题 loop节点看做end节点
Loop1!=loop2
让loop1一直往下走 也没遇到loop2 则两个链表不相交 返回空
如果loop1遇到loop2 那么就是情况3 此时返回loop1 或者loop2 都对


1、两无环
2有环无环是不可能相交的 无环的链表不管插在哪儿 插上都会变成有环
3 两有环
不用hashmap找到第一个入环节点
快慢指针:

如果快指针指向空 无环
如果 相遇 快指针指向起点 改 走一次一步 再次相遇为loop
无环链表相交:

终点不一样 不相交
接下来 让cur1指向长的 cur2 指向短的
n就是两链表长度的差

然后让长的先走n步 然后一起走 相交的就是
有环链表相交:
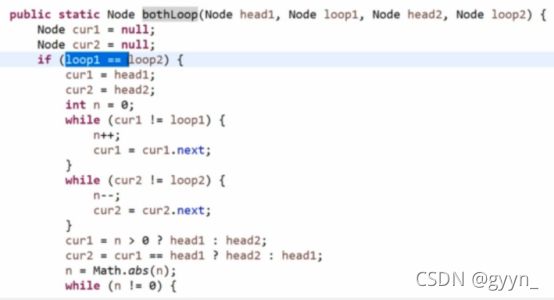

首先 判断情况2 省略
然后 让节点从loop1开始往下转 如果遇不到loop2 则不相交
遇到了 return loop1 loop2都对
第五课


其实这个方法一般这样用:
String[] arr = “11,22,33,44”.splite(",");
从而方便的得到一个字符串数组:arr={“11”, “22”, “33”, “44”};
Queue 中 add() 和 offer()都是用来向队列添加一个元素。
在容量已满的情况下,add() 方法会抛出IllegalStateException异常,offer() 方法只会返回 false





平衡二叉树:任何一个节点左子树和右子树高度差不超过1
二叉搜索树:对于这棵树上任何一颗节点为头的子树,左子树都比他小,右子树都比他大
二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。二叉搜索树作为一种经典的数据结构,它既有链表的快速插入与删除操作的特点,又有数组快速查找的优势;所以应用十分广泛,例如在文件系统和数据库系统一般会采用这种数据结构进行高效率的排序与检索操作。

第六课
https://blog.csdn.net/Mr_zhang66/article/details/109374701
哈希
Bit数组大小

哈希函数个数
实际失误率

并查集=岛问题
第七课
34分钟到52分钟全程卡

IsSameSet (A,B) A B头是否一样
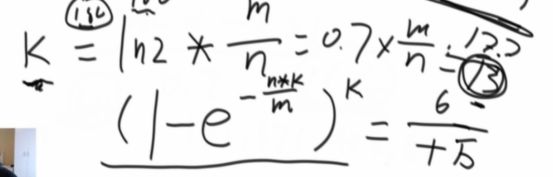
Union(3 5):少的并到多的头下面,然后搜过的链打扁平

所有的查操作都会进行优化
打扁平:

视频 00 25 00前
因为合并操作必须找到代表节点 所以只有代表结点需要存sizemap 初始化时也需要 因为开始每个都是代表结点,但是一旦被挂到别的节点下面 不用更新它的sizemap

这个是卡住的视频的截图
这一期视频寄吧卡住了 B站找别的的
折纸问题 b站 第五章 2:14:38
并查集 第六章
并查集提供两个操作 isSameSet(A,B) 和union(A,B)
集合的代表点
必须一开始就获得所有元素

但扁平的操作要写到findhead里 union每次都会先调用findhead 因为如果头一样不用合并

时间复杂度
当查询次数+合并次数很多的时候
平均下来O(1)
看到1h
岛问题
结构上,如何避免已经合并的部分重复减的问题

讲义第七课
前缀树 01 34 57

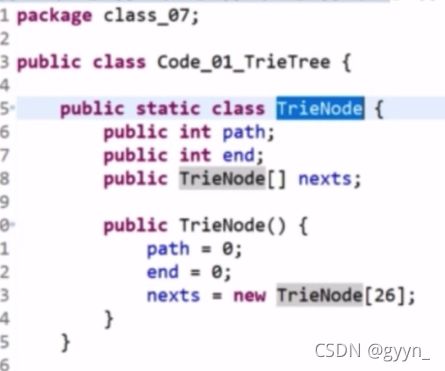

Path 经过就+1
End 以该节点结尾+1

查一个word 出现过几次

沿途path–
如果一个借点–后为0 让它指向空 后面的就全删了(jvm会处理)

以word为前缀的数量
怎么查的怎么找 返回path就行了
字母放在边上
对数器 选正确的贪心策略 不要证明
怎么看字典序:
长度相等 想象成26进制的数比较
不相等 短的后面补0 然后按上面的方法比较
贪心案例
一个字符串数组 拼接里面的所有字符串 求字典序最小的拼法
例如:
想法 :按字典序排好拼接的结果不一定对


https://www.runoob.com/java/java-string-compareto.html

谁放前面拼接起来字典序小 就让谁放前面
比较策略有传递性
传递性推导
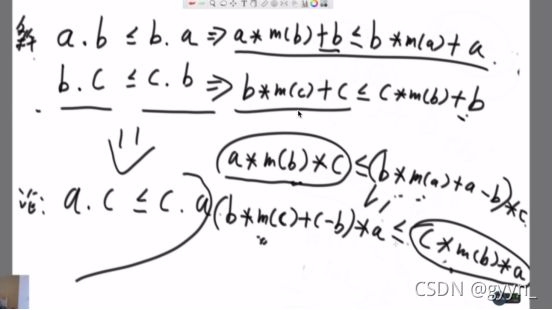

证明了我们的排序策略是有传递性的

还要证明 下面的比上面大


第八课

哈夫曼编码问题
子节点合并的代价是加起来的和








找结束时间最早的项目 淘汰掉因为它做不了的项目 然后重复这个动作


Cur 当前时刻 不断推进当前时刻 选了一个项目后 cur就变成它的end时刻
外层在遍历数组 那么时间段重合的就被排除了
策略为什么对:因为考虑两个项目 结束时间长的 后面能做的项目 短的也一定能做

贪心讲完了 拼接字符串 ipo 哈夫曼编码
贪心策略就是靠累积经验 然后用对数器验证
汉诺塔



法2

定义六个过程 左右 左中 右左 右中 。。。互相嵌套


每个位置要或不要





这种递推的题目 先列出前几项

牛不会死 去年的牛数量+三年前牛的数量(每个生一只牛) 三年中的牛 都是没成熟的不能生牛
F(n-3)就是谁帮着生

没见过的动态规划 一定可以从暴力改出来 高度套路化
暴力递归 改 动态规划

Walk返回从 i,j这个点到终点的最短路径和
暴力递归 复杂度高

重复计算多
怎么改动态规划
什么样的递归可以改:当你递归展开过程中发现有重复状态,而且这个重复状态与到达它的路径没有关系(例如是从0,1 还是1,0到达1,1的和walk(1,1)的结果都没关系。也就是上次计算出来的这个结果可以被下次另一个路径碰到时直接用)
无后效性问题
二维表可以把整个返回值装下

套路:
1、把需要的点点出来
2、回到basecase中把不被依赖的位置设置好
3、分析一个普遍位置是怎么依赖的

写出暴力版本
分析可变参数 哪几个可变参数可以代表返回值的状态 可变参数是几维的它就是一张几维的表
设置好basecase
看一个普遍位置看看它需要哪些位置 然后从basecase逆着回去 就是我填表的顺序

假设都是整数
子序列问题

这个图+7的时候画错了一部分

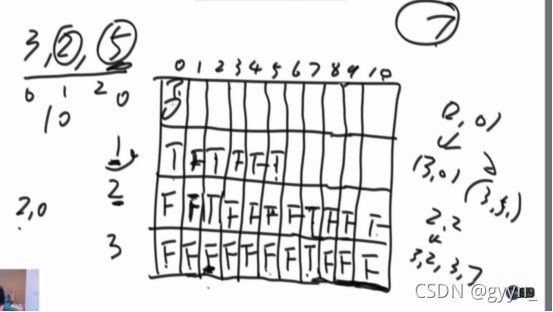
填表和题意已经没有关系了 给你一个函数就能改出来
少一个背包问题 和图一章