一些基本概念
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
现在从事移动端开发的程序员可能接触这个概念不多,更多听过的概念是UTF-8,后面会介绍它和Unicode的关系。Windows程序员对Unicode的概念应该比较清楚,因为微软的WinAPI中总是对有字符串相关操作的API提供两个版本的API实现,一个Unicode版本(通常以w结束,接受wchar_t类型的API),一个ANSI版本(即接收char类型的API)。下面会更详细介绍Unicode的具体概念,在此之前先看看字符编码的演进。
上面提到了ANSI(American National Standards Institute,ANSI),它代表美国国家标准学会。在字符编码上它通常指代我们熟悉的一个char范围内所能表示的字符(0-255)。它的真实名称应该是ASCII编码(American Standard Code for Information Interchange,美国信息交换标准代码),通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。如0x20表示的“空格”。通常0x80-0xff是不可见特殊字符。
多年前关于汉字编码很多人可能还比较常听到GBK和GB2312编码。他们同属多字节编码来表示汉字,即用多个byte按照一定的编码规则来表示一个汉字。GB-2312-80(即通常指的GB2312)《信息交换用汉字编码字符集 基本集》(又称 GB 或 GB0),它只收录了6,763个汉字,所以后被后续扩展编码取代,可以通常理解为被GBK取代。GBK中的K意做汉语拼音中的扩展的“扩”,指代的是后续GB xx的一系列标准(GB意为国标的汉语拼音),目前中国官方强制使用的是GB 18030-2005标准(新加坡亦采用)。GB 18030-2005 《信息技术 中文编码字符集》,依照UCS定义。GB 18030可以表示代理对(surrogate pair)之外的所有Unicode码位,因此可算为一种“统一码变换格式”Unicode Transformation Format)。目前它支持的汉字数高达70,244个。
更早一些时候(90年代以及2000初左右),有些游戏的汉化是台湾地区完成的,那我们玩这些游戏的时候总会遇到乱码,用“南极星”等内码转换软件才能正常显示,这是为什么呢?台湾地区跟中国大陆一样有自己的标准,跟GBK相对的,在台湾叫做Big5(大五码),这种编码港澳地区也通行。它在原理概念上跟GBK一样,都是采用自己的一套独立编码对汉字进行编码。
编码的混乱,标准的不统一实际上给现代计算机环境带来了很多弊端,所以统一的编码标准势在必行。
Unicode
前文已经介绍了它的概念,Unicode就是统一所有编码的终极方案,目前的主流操作系统全都支持Unicode编码。最近些年的代码编写基本也都是使用Unicode来作为字符处理的标准编码。我们来具体看看Unicode的定义和编码范围等概念。通俗来讲,Unicode将全球字符(字母文字、CJK汉字、特殊字符、emoji等)统一囊括进来对他们统一进行编码,这样就不会出现各地自行编码造成的编码不统一问题,目前Unicode已经收录了超过十万字符,所以它表示一个字符需要的存储空间已经超过了2个byte(我们通常接触的字符基本都可以用2个byte来表示)。目前Unicode最新版本是10.0,2017年6月发布,已能支持136,755个字符。
说到这里我们要介绍一下Unicode的编码方案,这个概念非常容易混淆,这就是我们通常所讲的UTF-xx(通常是UTF-8,UTF-16,UTF-32)。之所以说Unicode和Unicode编码方案容易混淆是因为程序员平时接触的实际上都是Unicode的某一种编码方案或几种,所以有时候会把某一种编码方案理解成为Unicode编码本身。那么我们理一下他们有什么区别。
通常我们说的Unicode编码指的是一个字符对应的一个确定的数值这个数值目前的范围在0x0--0x10ffff之间。举例子,比如字符a是0x61(跟ASCII码一样),再比如0x4f60表示汉字“你”,再比如0x1f4bb表示一个emoji字符(这个字符是一个笔记本电脑的图形)。也就是说如果用定长存储单元来存储的话,需要3个字节才能表示每一个Unicode字符。
UTF-8,UTF-16,UTF-32
我想上面应该把Unicode编码是什么讲清楚了,那么回到程序处理中,我们在程序处理中如何分辨一个Unicode编码字符到底有多长?一个字节两个字节还是三个字节甚至四个字节?所以在实际程序中,所有的Unicode字符都是编码存储的亦即要么是按8bit(1byte)为最小单位编码,要么按16bit(2bytes)为最小单位编码,要么按照32bit(4bytes)为最小单位存储。上面所说的就是UTF-8编码方案(8-bit Unicode Transformation Format),UTF-16编码方案(16-bit Unicode Transformation Format),UTF-32编码方案(32-bit Unicode Transformation Format)。
它们之间有什么不同么?最简单容易理解的是UTF-32编码,它用一个4bytes(通常就是一个int)来表示一个Unicode字符,这样每一个UTF-32字符都能明确表示一个唯一的Unicode字符,所以不需要什么额外的规则就可以存储好相应的Unicode字符,不过它的缺点显而易见就是浪费存储空间。linux系统上一个whar_t类型的字长就是4bytes,所以可以认为linux上采取了UTF-32编码方案。
UTF-8和UTF-16的最小单元都存在存储不下一个Unicode字符的可能,所以它们都需要按照某种规则去编码一个Unicode字符(如果需要的话)。下面看一下他们编码的规则。
UTF-8将每一个Unicode字符编码成为1-4个不等的byte,他们之间的编码规则对应规则可以见下图

我们平时接触到的英文字母同ASCII码样被编码成1个byte,中文大部分会被编码成3bytes,如前面提到的“你”字的UTF-8编码为0xa0,0xbd,0xe4。
UTF-16同UTF-8一样也是变长编码,对于一个Unicode字符被编码成1至2个单元,每个单元为2个bytes。在Unicode中0x0000-0xffff范围内的字符(也是绝大多数平时用到的字符)跟UTF-16编码是一致的,不需要额外编码。对于超出0xffff范围的Unicode字符需要进行编码。超出范围的编码范围目前在U+10000-U+10FFFF内,在此范围内的编码在UTF-16中被编码为一对16bit的单元(即32bit,4bytes),称作代理对(surrogate pair)。组成代理对的两个单元前一个称为前导代理(lead surrogates)范围为0xD800-0xDBFF,后一个称为后尾代理(trail surrogates)范围为0xDC00-0xDFFF。具体的对应关系可以见下图
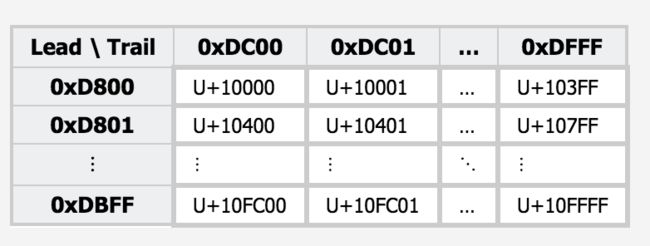
可以看出我们平时用到的字符绝大多数都在0xffff之内,所以它比较UTF-32方案节省存储空间,而且在绝大多数情况下是定长的字符,这点在字符串处理算法上比UTF-8要方便许多。但是它不想UTF-8那样兼容ASCII码,并且在传输中(不同平台,网络与本地等)存在大小头(big-end,little-end)问题。
C++11中的Unicode支持
前面介绍了各种概念,基本能把各种编码的前世今生梳理清楚了,下面我们看一下C++11在语言层面对Unicode做了哪些提升。简单来说就是引入了char16_t和char32_t类型来明确UTF-16和UTF-32编码方案对应的存储类型。在之前的标准中只有wchar_t一种类型来存储Unicode字符,在不同平台上它的字长还不一致(windows上2个bytes,linux上4个bytes),这样导致windows上对于多于2字节的字符在处理上存在问题,后来微软不得不提供了一些额外API去处理这些情况。现在新的标准中明确了各种编码存储的字长,处理起Unicode更加明确简单了。与之对应的STL库中多了相应的std::u16string和std::u32string。
直接看代码
#include
#include
class Cpp11WideCharTest
{
public:
static void execute()
{
//汉字:你好啊
const char* szgbk = "你好啊";//Clion on mac 把这个直接转换成u8编码了, 在windowss vs上应该是GBK编码,取决于编译器和编辑器编码的设置
char u8[] = u8"\u4f60\u597d\u554a";
char16_t u16[] = u"\u4f60\u597d\u554a";
char32_t u32[] = U"\u4f60\u597d\u554a";
std::cout<<"u8:"<, char32_t> utf16le_cvt;
std::string stru16bytes = utf16le_cvt.to_bytes(u32wstr);
char16_t* p16 = (char16_t*)(stru16bytes.c_str()); //观察内存可以看到大于2字节的emoji字符,从u32转到u16,做了相应的编码
//u16 to u8
//std::wstring_convert, char16_t> utf8_ucs2_cvt;
std::wstring_convert, char16_t> utf8_ucs2_cvt;
std::string stru18emoji = utf8_ucs2_cvt.to_bytes(p16);
std::u16string stru16emoji = utf8_ucs2_cvt.from_bytes(stru18emoji);
//utf8 to u32
std::wstring_convert, char32_t> u8_u32_convert;
std::string u32tou8 = u8_u32_convert.to_bytes(u32emoji); //u32 to u8
std::u32string stru32emoji = u8_u32_convert.from_bytes(stru18emoji);//u8 to u32
//uft8 to u16
std::wstring_convert, char16_t> u8_u16_convert;
std::u16string stru16emoji2 = u8_u16_convert.from_bytes(stru18emoji);
std::cout<<"end u8u16u32"< 上面代码加了一些注释,很直观可以看明白新引入的一些特性,下面的代码是各种编码方案之间的转换,注意
上面通过介绍Unicode字符编码和对它的编码方案的介绍,应该可以窥其全貌,我想通过这篇文章应该可以理清Unicode和UTF-x之间的关系了。
最后
想讨论一下Java中String的存储。由于笔者最近几年在从事android开发,所以java语言用的比较多,对于java中String的内存结构一直不是很明确,但是可以确定的是java对Unicode各种编码处理的非常好。我推测java中String的内存模型应该是UTF-16编码的,这种方式应该更容易进行字符串的各种操作。JNI层有两个API(NewString和NewStringUTF)一个接受16bit字符串一个接受8bit字符串,但是最终生成的String在java层可以得到各种编码的bytes数组(UTF-8和UTF-16)。在java层还可以通过指定codepoints直接指定Unicode码,而接受的是一个int数组,也就是java String可以指定所有Unicode编码的字符。对于超过16bit的字符来说,直接编码成了两个16bit单元存储了,即UTF-16编码。看一段代码
int codePoints[] = new int[1];
codePoints[0] = 0x1f4bb; //上面用过的emoji字符,一个笔记本电脑图形
String strJava = new String(codePoints, 0, 1);
int nSizeJava = strJava.length(); //nSizeJava = 2
这段代码实际是输入了一个Unicode字符,只不过这个字符超过了16bit的存储范围,java中的String存储它后它的lenth是2,这一点是不是说明了java中String存储Unicode的内存结构是用了UTF-16呢?