学习R包
R包的安装和加载
- 镜像设置
- 鼠标点击设置
在RStudio程序设置中点击Tools-Packages,设置CRAN镜像,可以通过options()$repos来检验。 - 使用代码设置
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/")) #清华源
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/") #中科大源
可以通过options()$BioC_mirror来检验。
- 使用R的配置文件
.Rprofile
用file.edit()来编辑文件:
file.edit('~/.Rprofile')
再添加
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/")
保存重启后,再运行options()$repos和options()$BioC_mirror检验。
- 安装
install.packages(“包”) #安装包存在于CRAN网站
BiocManager::install(“包”) #安装包存在于biocductor
- 加载
下面两个命令均可。
library(包)
require(包)
例:安装并加载dplyr包
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/")
install.packages("dplyr")
library(dplyr)
dplyr基础函数
示例数据使用内置数据集iris的简化版。
test <- iris[c(1:2,51:52,101:102),]
运行结果如下:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
101 6.3 3.3 6.0 2.5 virginica
102 5.8 2.7 5.1 1.9 virginica
1. mutate() #新增列
mutate(test, new = Sepal.Length * Sepal.Width
运行结果如下:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species new
1 5.1 3.5 1.4 0.2 setosa 17.85
2 4.9 3.0 1.4 0.2 setosa 14.70
3 7.0 3.2 4.7 1.4 versicolor 22.40
4 6.4 3.2 4.5 1.5 versicolor 20.48
5 6.3 3.3 6.0 2.5 virginica 20.79
6 5.8 2.7 5.1 1.9 virginica 15.66
2. select() #按列筛选
- 按列号筛选
(1)筛选单列select(test,1)
Sepal.Length
1 5.1
2 4.9
51 7.0
52 6.4
101 6.3
102 5.8
(2)筛选多列select(test,c(1,5)) #筛选第一列及第五列
Sepal.Length Species
1 5.1 setosa
2 4.9 setosa
51 7.0 versicolor
52 6.4 versicolor
101 6.3 virginica
102 5.8 virginica
- 按列名筛选
(1)直接输入列名筛选
select(test, Petal.Length, Petal.Width)
(2)在创建的包含列名的新变量中筛选
vars <- c("Petal.Length", "Petal.Width") #创建包含要筛选列名的变量
select(test, one_of(vars)) #one_of为声明选择对象
两种方式的结果如下:
Petal.Length Petal.Width
1 1.4 0.2
2 1.4 0.2
51 4.7 1.4
52 4.5 1.5
101 6.0 2.5
102 5.1 1.9
3. filter() #筛选行
(1)用行名直接筛选
filter(test, Species == "setosa")
结果如下:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
(2)对筛选的行名做进一步限制
filter(test, Species == "setosa"&Sepal.Length > 5 )
结果如下:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
(3)筛选不同的行
filter(test, Species %in% c("setosa","versicolor"))
结果如下:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 7.0 3.2 4.7 1.4 versicolor
4 6.4 3.2 4.5 1.5 versicolor
4. arrange() #对表格排序
arrange(test, Sepal.Length)#默认从小到大排序
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 4.9 3.0 1.4 0.2 setosa
2 5.1 3.5 1.4 0.2 setosa
3 5.8 2.7 5.1 1.9 virginica
4 6.3 3.3 6.0 2.5 virginica
5 6.4 3.2 4.5 1.5 versicolor
6 7.0 3.2 4.7 1.4 versicolor
arrange(test, desc(Sepal.Length))#用desc从大到小排序
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.0 3.2 4.7 1.4 versicolor
2 6.4 3.2 4.5 1.5 versicolor
3 6.3 3.3 6.0 2.5 virginica
4 5.8 2.7 5.1 1.9 virginica
5 5.1 3.5 1.4 0.2 setosa
6 4.9 3.0 1.4 0.2 setosa
5. summarise() #数据汇总
> summarise(test, mean(Sepal.Length), sd(Sepal.Length))
#对指定行计算平均值和标准差
mean(Sepal.Length) sd(Sepal.Length)
1 5.916667 0.8084965
######################
> group_by(test, Species)
#按照Species分组
# A tibble: 6 x 5
# Groups: Species [3]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
*
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 7 3.2 4.7 1.4 versicolor
4 6.4 3.2 4.5 1.5 versicolor
5 6.3 3.3 6 2.5 virginica
6 5.8 2.7 5.1 1.9 virginica
##########################
> summarise(group_by(test, Species),mean(Sepal.Length), sd(Sepal.Length))
#按species分组后再计算每组Sepal.Length的平均值和标准差
# A tibble: 3 x 3
Species `mean(Sepal.Length)` `sd(Sepal.Length)`
1 setosa 5 0.141
2 versicolor 6.7 0.424
3 virginica 6.05 0.354
dplyr实用技能
1. 管道操作 %>%
test %>% group_by(Species) %>% summarise(mean(Sepal.Length), sd(Sepal.Length))#管道从左向右进行
结果如下:
# A tibble: 3 x 3
Species `mean(Sepal.Length)` `sd(Sepal.Length)`
1 setosa 5 0.141
2 versicolor 6.7 0.424
3 virginica 6.05 0.354
2. count统计某列的unique值
count(test,Species)
结果如下:
# A tibble: 3 x 2
Species n
1 setosa 2
2 versicolor 2
3 virginica 2
dplyr处理关系数据
将两个表连接,注意不要引入factor。
以下两图来自“各种join一目了然——CSDN(CalmReason)”
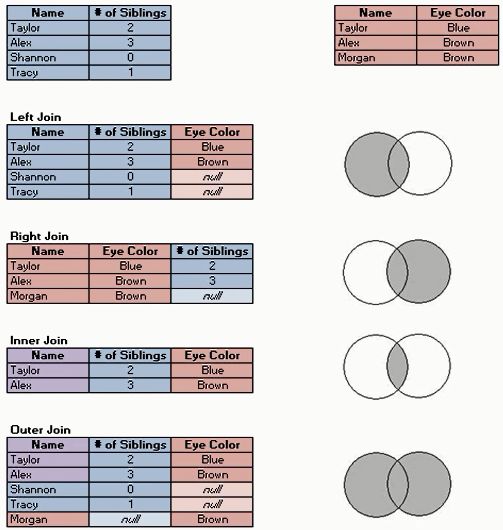

创建表格
options(stringsAsFactors = F) #不引入factor
test1 <- data.frame(x = c('b','e','f','x'),
z = c("A","B","C",'D'),
stringsAsFactors = F)
test2 <- data.frame(x = c('a','b','c','d','e','f'),
y = c(1,2,3,4,5,6),
stringsAsFactors = F)
test1
x z
1 b A
2 e B
3 f C
4 x D
test2
x y
1 a 1
2 b 2
3 c 3
4 d 4
5 e 5
6 f 6
- 内连接inner_join
inner_join(test1, test2, by = "x")
x z y
1 b A 2
2 e B 5
3 f C 6
- 左连接left_join,意为以左边的表格为准,右表与选择连接的列名一致的填写右表数据,不一致的为NA。
left_join(test1, test2, by = 'x')
x z y
1 b A 2
2 e B 5
3 f C 6
4 x D NA
left_join(test2, test1, by = 'x')
x y z
1 a 1
2 b 2 A
3 c 3
4 d 4
5 e 5 B
6 f 6 C
- 右连接right_join,与左连接类似,左连接的左右两表互换位置得到的结果与右连接一致。
right_join(test1, test2, by = 'x')
x z y
1 a 1
2 b A 2
3 c 3
4 d 4
5 e B 5
6 f C 6
- 全连接full_join,取并集,缺失数据为NA
full_join( test1, test2, by = 'x')
x z y
1 b A 2
2 e B 5
3 f C 6
4 x D NA
5 a 1
6 c 3
7 d 4
- 半连接semi_join,返回能够与y表匹配的x表所有记录semi_join
semi_join(x = test1, y = test2, by = 'x')
x z
1 b A
2 e B
3 f C
- 反连接anti_join,返回无法与y表匹配的x表的所记录anti_join
anti_join(x = test2, y = test1, by = 'x')
x y
1 a 1
2 c 3
3 d 4
- 简单合并
创建表格:
> test1 <- data.frame(x = c(1,2,3,4), y = c(10,20,30,40))
> test1
x y
1 1 10
2 2 20
3 3 30
4 4 40
> test2 <- data.frame(x = c(5,6), y = c(50,60))
> test2
x y
1 5 50
2 6 60
> test3 <- data.frame(z = c(100,200,300,400))
> test3
z
1 100
2 200
3 300
4 400
合并表格
> bind_rows(test1, test2) #合并行,需要两个表格列数相同
x y
1 1 10
2 2 20
3 3 30
4 4 40
5 5 50
6 6 60
> bind_cols(test1, test3) #合并列,需要两个表格行数相同
x y z
1 1 10 100
2 2 20 200
3 3 30 300
4 4 40 400
如果行数或列数不相同会报错。