线性回归算法推导与实战
目录
- 前言
- 1.线性回归算法推导
-
- 1.1 深入理解回归
- 1.2 误差分析
- 1.3 最大似然估计
- 1.4 高斯分布-概率密度函数
- 1.5 误差总似然
- 1.6 最小二乘法 M S E MSE MSE
- 1.7 归纳总结升华
- 2.线性回归实战
-
- 2.1 使用正规方程进行求解
-
- 2.1.1 简单线性回归
- 2.1.2 多元线性回归
- 2.2 机器学习库 s c i k i t − l e a r n scikit-learn scikit−learn
-
- 2.2.1 s c i k i t − l e a r n scikit-learn scikit−learn 实现简单线性回归
- 2.2.2 s c i k i t − l e a r n scikit-learn scikit−learn 实现多元线性回归
- 2.3 线性回归预测房价
-
- 2.3.1 数据加载
- 2.3.2 数据查看
- 2.3.3 数据拆分
- 2.3.4 数据建模
- 2.3.5 模型验证
- 2.3.6 模型评估
前言
本文属于 线性回归算法【AIoT阶段三】(尚未更新),这里截取自其中一段内容,方便读者理解和根据需求快速阅读。本文通过公式推导+代码两个方面同时进行,因为涉及到代码的编译运行,如果你没有 N u m P y NumPy NumPy, P a n d a s Pandas Pandas, M a t p l o t l i b Matplotlib Matplotlib 的基础,建议先修文章:数据分析三剑客【AIoT阶段一(下)】(十万字博文 保姆级讲解)
1.线性回归算法推导
1.1 深入理解回归
回归简单来说就是 “回归平均值” ( r e g r e s s i o n (regression (regression t o to to t h e the the m e a n ) mean) mean)。但是这里的 m e a n mean mean 并不是把 历史数据直接当成未来的预测值,而是会把期望值当作预测值。 追根溯源 回归 这个词是一个叫高尔顿的人发明的,他通过大量观察数据发现:父亲比较高,儿子也比较高;父亲比较矮,那么儿子也比较矮!正所谓 “龙生龙凤生凤老鼠的儿子会打洞” 但是会存在一定偏差~
父亲是 1.98 1.98 1.98,儿子肯定很高,但有可能不会达到 1.98 1.98 1.98
父亲是 1.69 1.69 1.69,儿子肯定不高,但是有可能比 1.69 1.69 1.69 高
大自然让我们回归到一定的区间之内,这就是大自然神奇的力量。
高尔顿是谁?达尔文的表弟,这下可以相信他说的十有八九是对的了吧!
人类社会很多事情都被大自然这种神奇的力量只配置:身高、体重、智商、相貌……
这种神秘的力量就叫正态分布。大数学家高斯,深入研究了正态分布,最终推导出了线性回归的原理:最小二乘法!
1.2 误差分析
误差 ε i \varepsilon_i εi 等于第 i i i 个样本实际的值 y i y_i yi 减去预测的值 y ^ \hat{y} y^ ,公式可以表达为如下:
ε i = ∣ y i − y ^ ∣ \varepsilon_i = |y_i - \hat{y}| εi=∣yi−y^∣
ε i = ∣ y i − W T x i ∣ \varepsilon_i = |y_i - W^Tx_i| εi=∣yi−WTxi∣
假定所有的样本的误差都是独立的,有上下的震荡,震荡认为是随机变量,足够多的随机变量叠加之后形成的分布,它服从的就是正态分布,因为它是正常状态下的分布,也就是高斯分布!均值是某一个值,方差是某一个值。 方差我们先不管,均值我们总有办法让它去等于零 0 0 0 的,因为我们这里是有截距 b b b, 所有误差我们就可以认为是独立分布的, 1 < = i < = n 1<=i<=n 1<=i<=n,服从均值为 0 0 0,方差为某定值的高斯分布。机器学习中我们假设误差符合均值为0,方差为定值的正态分布!!!
1.3 最大似然估计
最大似然估计 ( m a x i m u m (maximum (maximum l i k e l i h o o d likelihood likelihood e s t i m a t i o n , estimation, estimation, M L E ) MLE) MLE) 一种重要而普遍的求估计量的方法。最大似然估计明确地使用概率模型,其目标是寻找能够以较高概率产生观察数据的系统发生树。最大似然估计是一类完全基于统计的系统发生树重建方法的代表。
是不是,有点看不懂,太学术了,我们举例说明~
假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占的比例最有可能是多少?

请告诉我答案!

很多小伙伴,甚至不用算,凭感觉,就能给出答案:70%!
下面是详细推导过程:
-
最大似然估计,计算
-
白球概率是p,黑球是1-p(罐子中非黑即白)
-
罐子中取一个请问是白球的概率是多少?
- p p p
-
罐子中取两个球,两个球都是白色,概率是多少?
- p 2 p^2 p2
-
罐子中取5个球都是白色,概率是多少?
- p 5 p^5 p5
-
罐子中取10个球,9个是白色,一个是黑色,概率是多少呢?
- C 10 1 = C 10 9 C_{10}^1 = C_{10}^9 C101=C109 这个两个排列组合公式是相等的
- C 10 9 p 9 ( 1 − p ) = C 10 1 p 9 ( 1 − p ) C_{10}^9p^9(1-p) = C_{10}^1p^9(1-p) C109p9(1−p)=C101p9(1−p)
-
罐子取100个球,70次是白球,30次是黑球,概率是多少?
- P = C 100 30 p 70 ( 1 − p ) 30 P = C_{100}^{30}p^{70}(1-p)^{30} P=C10030p70(1−p)30
-
最大似然估计,什么时候P最大呢?
C 100 30 C_{100}^{30} C10030是常量,可以去掉!
p > 0 , 1 − p > 0 p > 0,1- p > 0 p>0,1−p>0,所以上面概率想要求最大值,那么求导数即可!
-
P ′ = 70 ∗ p 69 ∗ ( 1 − p ) 30 + p 70 ∗ 30 ∗ ( 1 − p ) 29 ∗ ( − 1 ) P' = 70*p^{69}*(1-p)^{30} + p^{70}*30*(1-p)^{29}*(-1) P′=70∗p69∗(1−p)30+p70∗30∗(1−p)29∗(−1)
令导数为0:
-
0 = 70 ∗ p 69 ∗ ( 1 − p ) 30 + p 70 ∗ 30 ∗ ( 1 − p ) 29 ∗ ( − 1 ) 0 = 70*p^{69}*(1-p)^{30} +p^{70}*30*(1-p)^{29}*(-1) 0=70∗p69∗(1−p)30+p70∗30∗(1−p)29∗(−1)
公式化简:
-
0 = 70 ∗ ( 1 − p ) − p ∗ 30 0 = 70*(1-p) - p*30 0=70∗(1−p)−p∗30
-
0 = 70 − 100 ∗ p 0 = 70 - 100*p 0=70−100∗p
-
p = 70%
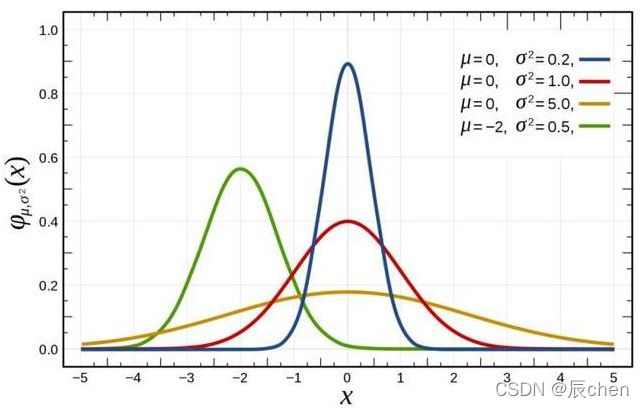
1.4 高斯分布-概率密度函数
最常见的连续概率分布是正态分布,也叫高斯分布,而这正是我们所需要的,其概率密度函数如下:

公式如下:
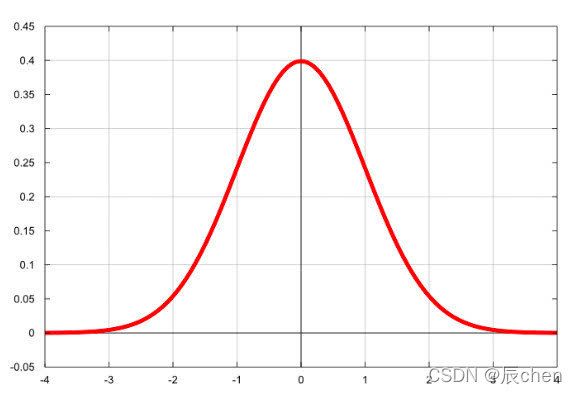
f ( x ∣ μ , σ 2 ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x|\mu,\sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x - \mu)^2}{2\sigma^2}} f(x∣μ,σ2)=2πσ1e−2σ2(x−μ)2
随着参数 μ μ μ 和 σ σ σ 变化,概率分布也产生变化。 下面重要的步骤来了,我们要把一组数据误差出现的总似然,也就是一组数据之所以对应误差出现的整体可能性表达出来了,因为数据的误差我们假设服从一个高斯分布,并且通过截距项来平移整体分布的位置从而使得 μ = 0 μ=0 μ=0,所以样本的误差我们可以表达其概率密度函数的值如下:
f ( ε ∣ μ = 0 , σ 2 ) = 1 2 π σ e − ( ε − 0 ) 2 2 σ 2 f(\varepsilon|\mu = 0,\sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(\varepsilon - 0)^2}{2\sigma^2}} f(ε∣μ=0,σ2)=2πσ1e−2σ2(ε−0)2
简化如下:
f ( ε ∣ 0 , σ 2 ) = 1 2 π σ e − ε 2 2 σ 2 f(\varepsilon| 0,\sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{\varepsilon ^2}{2\sigma^2}} f(ε∣0,σ2)=2πσ1e−2σ2ε2
1.5 误差总似然
和前面黑球白球问题类似,也是一个累乘问题~
P = ∏ i = 0 n f ( ε i ∣ 0 , σ 2 ) = ∏ i = 0 n 1 2 π σ e − ε i 2 2 σ 2 P = \prod\limits_{i = 0}^{n}f(\varepsilon_i|0,\sigma^2) = \prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{\varepsilon_i ^2}{2\sigma^2}} P=i=0∏nf(εi∣0,σ2)=i=0∏n2πσ1e−2σ2εi2
根据前面公式 ε i = ∣ y i − W T x i ∣ \varepsilon_i = |y_i - W^Tx_i| εi=∣yi−WTxi∣ 可以推导出来如下公式:
P = ∏ i = 0 n f ( ε i ∣ 0 , σ 2 ) = ∏ i = 0 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 P = \prod\limits_{i = 0}^{n}f(\varepsilon_i|0,\sigma^2) = \prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}} P=i=0∏nf(εi∣0,σ2)=i=0∏n2πσ1e−2σ2(yi−WTxi)2
公式中的未知变量就是 W T W^T WT,即方程的系数,系数包含截距~如果,把上面当成一个方程,就是概率 P P P 关于 W W W 的方程!其余符号,都是常量!
P W = ∏ i = 0 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 P_W= \prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}} PW=i=0∏n2πσ1e−2σ2(yi−WTxi)2
现在问题,就变换成了,求最大似然问题了!不过,等等~
累乘的最大似然,求解是非常麻烦的!
接下来,我们通过:求对数把累乘问题,转变为累加问题(加法问题,无论多复杂,都难不倒我了!)
1.6 最小二乘法 M S E MSE MSE
P W = ∏ i = 0 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 P_W = \prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}} PW=i=0∏n2πσ1e−2σ2(yi−WTxi)2
根据对数的单调性,对上面公式求自然底数e的对数,效果不变~
ln ( P W ) = ln ( ∏ i = 0 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 ) \ln(P_W) = \ln(\prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}}) ln(PW)=ln(i=0∏n2πσ1e−2σ2(yi−WTxi)2)
接下来 l o g log log 函数继续为你带来惊喜,数学上连乘是个大麻烦,即使交给计算机去求解它也得哭出声来。惊喜是:
- l o g a ( X Y ) = l o g a X + l o g a Y log_a(XY) = log_aX + log_aY loga(XY)=logaX+logaY
- l o g a X Y = l o g a X − l o g a Y log_a\frac{X}{Y} = log_aX - log_aY logaYX=logaX−logaY
- l o g a X n = n ∗ l o g a X log_aX^n = n*log_aX logaXn=n∗logaX
- l o g a ( X 1 X 2 … … X n ) = l o g a X 1 + l o g a X 2 + … … + l o g a X n log_a(X_1X_2……X_n) = log_aX_1 + log_aX_2 + …… + log_aX_n loga(X1X2……Xn)=logaX1+logaX2+……+logaXn
- l o g x x n = n ( n ∈ R ) log_xx^n = n(n\in R) logxxn=n(n∈R)
- l o g a 1 X = − l o g a X log_a\frac{1}{X} = -log_aX logaX1=−logaX
- l o g a N y x = y x l o g a N log_a\sqrt[x]{N^y} = \frac{y}{x}log_aN logaxNy=xylogaN
ln ( P W ) = ln ( ∏ i = 0 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 ) \ln(P_W) = \ln(\prod\limits_{i = 0}^{n}\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}}) ln(PW)=ln(i=0∏n2πσ1e−2σ2(yi−WTxi)2)
= ∑ i = 0 n ln ( 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 ) =\sum\limits_{i = 0}^{n}\ln(\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i - W^Tx_i)^2}{2\sigma^2}}) =i=0∑nln(2πσ1e−2σ2(yi−WTxi)2)
累乘问题变成累加问题~
乘风破浪,继续推导 ⟶ \longrightarrow ⟶
= ∑ i = 0 n ( ln 1 2 π σ − ( y i − W T x i ) 2 2 σ 2 ) =\sum\limits_{i = 0}^{n}(\ln\frac{1}{\sqrt{2\pi}\sigma} - \frac{(y_i - W^Tx_i)^2}{2\sigma^2}) =i=0∑n(ln2πσ1−2σ2(yi−WTxi)2)
= ∑ i = 0 n ( ln 1 2 π σ − 1 σ 2 ⋅ 1 2 ( y i − W T x i ) 2 ) =\sum\limits_{i = 0}^{n}(\ln\frac{1}{\sqrt{2\pi}\sigma} - \frac{1}{\sigma^2}\cdot\frac{1}{2}(y_i - W^Tx_i)^2) =i=0∑n(ln2πσ1−σ21⋅21(yi−WTxi)2)
上面公式是最大似然求对数后的变形,其中 π 、 σ \pi、\sigma π、σ都是常量,而 ( y i − W T x i ) 2 (y_i - W^Tx_i)^2 (yi−WTxi)2肯定大于零!上面求最大值问题,即可转变为如下求最小值问题:
L ( W ) = 1 2 ∑ i = 0 n ( y i − W T x i ) 2 L(W) = \frac{1}{2}\sum\limits_{i = 0}^n(y_i - W^Tx_i)^2 L(W)=21i=0∑n(yi−WTxi)2
L L L 代表 L o s s Loss Loss,表示损失函数,损失函数越小,那么上面最大似然就越大~
有的书本上公式,也可以这样写,用 J ( θ ) J(\theta) J(θ) 表示一个意思, θ \theta θ 的角色就是 W W W:
J ( θ ) = 1 2 ∑ i = 1 n ( y i − θ T x i ) 2 = 1 2 ∑ i = 1 n ( θ T x i − y i ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 1}^n(y_i - \theta^Tx_i)^2 = \frac{1}{2}\sum\limits_{i = 1}^n(\theta^Tx_i - y_i)^2 J(θ)=21i=1∑n(yi−θTxi)2=21i=1∑n(θTxi−yi)2
进一步提取:
J ( θ ) = 1 2 ∑ i = 1 n ( h θ ( x i ) − y i ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 1}^n(h_{\theta}(x_i) - y_i)^2 J(θ)=21i=1∑n(hθ(xi)−yi)2
其中:
y ^ = h θ ( X ) = X θ \hat{y} = h_{\theta}(X) =X \theta y^=hθ(X)=Xθ
表示全部数据,是矩阵, X X X表示多个数据,进行矩阵乘法时,放在前面
y ^ i = h θ ( x i ) = θ T x i \hat{y}_i = h_{\theta}(x_i) = \theta^Tx_i y^i=hθ(xi)=θTxi
表示第 i i i 个数据,是向量,所以进行乘法时,其中一方需要转置
因为最大似然公式中有个负号,所以最大总似然变成了最小化负号后面的部分。 到这里,我们就已经推导出来了 M S E MSE MSE 损失函数 J ( θ ) J(\theta) J(θ),从公式我们也可以看出来 M S E MSE MSE 名字的来 历, m e a n mean mean s q u a r e d squared squared e r r o r error error,上式也叫做最小二乘法!
1.7 归纳总结升华
这种最小二乘法估计,其实我们就可以认为,假定了误差服从正太分布,认为样本误差的出现是随机的,独立的,使用最大似然估计思想,利用损失函数最小化 MSE 就能求出最优解!所以反过来说,如果我们的数据误差不是互相独立的,或者不是随机出现的,那么就不适合去假设为正太分布,就不能去用正太分布的概率密度函数带入到总似然的函数中,故而就不能用 MSE 作为损失函数去求解最优解了!所以,最小二乘法不是万能的~
还有譬如假设误差服从泊松分布,或其他分布那就得用其他分布的概率密度函数去推导出损失函数了。
所以有时我们也可以把线性回归看成是广义线性回归。比如,逻辑回归,泊松回归都属于广义线性回归的一种,这里我们线性回归可以说是最小二乘线性回归。
2.线性回归实战
2.1 使用正规方程进行求解
2.1.1 简单线性回归
y = w x + b y = wx + b y=wx+b 一元一次方程,在机器学习中一元表示一个特征, b b b 表示截距, y y y 表示目标值。
import numpy as np
import matplotlib.pyplot as plt
# 转化成矩阵
X = np.linspace(0, 10, num = 30).reshape(-1, 1)
'''
np.linspace(0, 10, num = 30) 是把0~10等分为30段
为什么不实用下述代码?
X = np.random.randint(0, 10, size = (30, 1))
这是因为上面这行代码只会产生整数,而代码np.linspace(0, 10, num = 30)可以产生小数
构图更加的美观
'''
# 斜率和截距,随机生成
w = np.random.randint(1, 5, size = 1)
b = np.random.randint(1, 10, size = 1)
# 根据一元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = X * w + b + np.random.randn(30, 1)
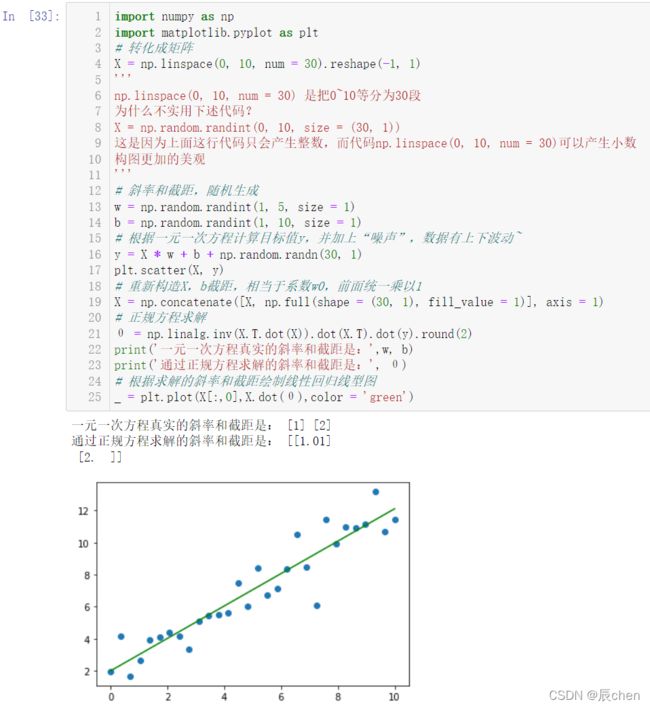
plt.scatter(X, y)
# 重新构造X,b截距,相当于系数w0,前面统一乘以1
X = np.concatenate([X, np.full(shape = (30, 1), fill_value = 1)], axis = 1)
# 正规方程求解
θ = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y).round(2)
print('一元一次方程真实的斜率和截距是:',w, b)
print('通过正规方程求解的斜率和截距是:', θ)
# 根据求解的斜率和截距绘制线性回归线型图
_ = plt.plot(X[:,0],X.dot(θ),color = 'green')
2.1.2 多元线性回归
y = w 1 x 1 + w 2 x 2 + b y = w_1x_1 + w_2x_2 + b y=w1x1+w2x2+b 二元一次方程, x 1 、 x 2 x_1、x_2 x1、x2 相当于两个特征, b b b 是方程截距
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D # 绘制三维图像
# 转化成矩阵
x1 = np.random.randint(-150, 150, size = (300, 1))
x2 = np.random.randint(0, 300, size = (300, 1))
# 斜率和截距,随机生成
w = np.random.randint(1, 5, size = 2)
b = np.random.randint(1, 10, size = 1)
# 根据二元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = x1 * w[0] + x2 * w[1] + b + np.random.randn(300, 1)
fig = plt.figure(figsize = (9, 6))
ax = Axes3D(fig)
ax.scatter(x1, x2, y) # 三维散点图
ax.view_init(elev = 10, azim = -20) # 调整视角
# 重新构造X,将x1、x2以及截距b,相当于系数w0,前面统一乘以1进行数据合并
X = np.concatenate([x1, x2, np.full(shape = (300, 1), fill_value = 1)], axis = 1)
w = np.concatenate([w, b])
# 正规方程求解
θ = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y).round(2)
print('二元一次方程真实的斜率和截距是:', w)
print('通过正规方程求解的斜率和截距是:', θ.reshape(-1))
# # 根据求解的斜率和截距绘制线性回归线型图
x = np.linspace(-150, 150, 100)
y = np.linspace(0, 300, 100)
z = x * θ[0] + y * θ[1] + θ[2]
_ = ax.plot(x,y,z ,color = 'red')

2.2 机器学习库 s c i k i t − l e a r n scikit-learn scikit−learn
这个库我们其实在 线性回归的基本概念以及正规方程 就已经有了介绍,下面的两个代码也是调用函数改写上述的两个代码。
scikit-learn官网
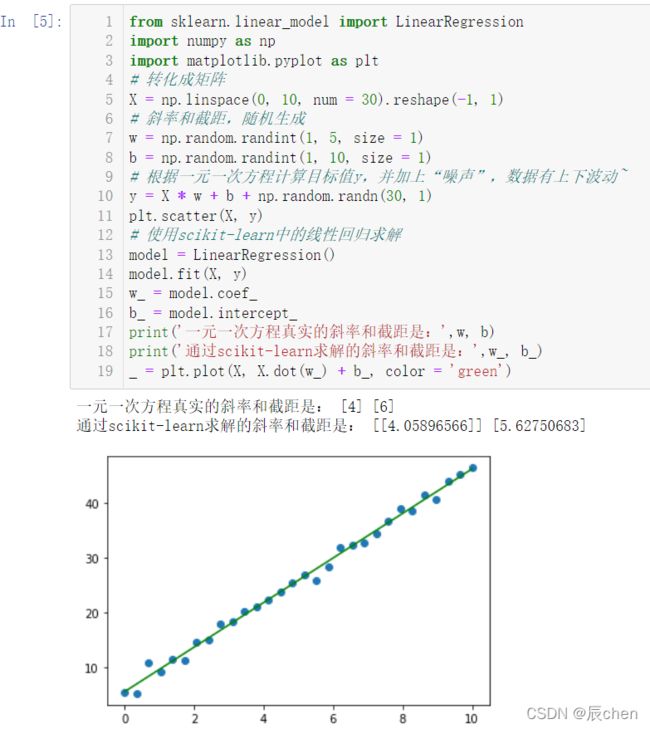
2.2.1 s c i k i t − l e a r n scikit-learn scikit−learn 实现简单线性回归
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
# 转化成矩阵
X = np.linspace(0, 10, num = 30).reshape(-1, 1)
# 斜率和截距,随机生成
w = np.random.randint(1, 5, size = 1)
b = np.random.randint(1, 10, size = 1)
# 根据一元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = X * w + b + np.random.randn(30, 1)
plt.scatter(X, y)
# 使用scikit-learn中的线性回归求解
model = LinearRegression()
model.fit(X, y)
w_ = model.coef_
b_ = model.intercept_
print('一元一次方程真实的斜率和截距是:',w, b)
print('通过scikit-learn求解的斜率和截距是:',w_, b_)
_ = plt.plot(X, X.dot(w_) + b_, color = 'green')
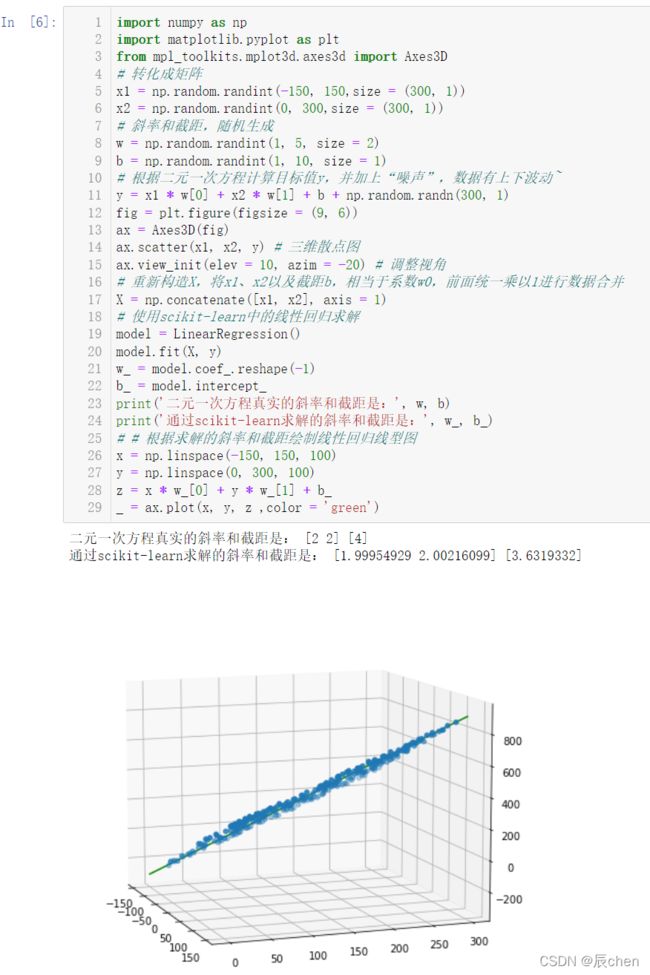
2.2.2 s c i k i t − l e a r n scikit-learn scikit−learn 实现多元线性回归
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D
# 转化成矩阵
x1 = np.random.randint(-150, 150,size = (300, 1))
x2 = np.random.randint(0, 300,size = (300, 1))
# 斜率和截距,随机生成
w = np.random.randint(1, 5, size = 2)
b = np.random.randint(1, 10, size = 1)
# 根据二元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = x1 * w[0] + x2 * w[1] + b + np.random.randn(300, 1)
fig = plt.figure(figsize = (9, 6))
ax = Axes3D(fig)
ax.scatter(x1, x2, y) # 三维散点图
ax.view_init(elev = 10, azim = -20) # 调整视角
# 重新构造X,将x1、x2以及截距b,相当于系数w0,前面统一乘以1进行数据合并
X = np.concatenate([x1, x2], axis = 1)
# 使用scikit-learn中的线性回归求解
model = LinearRegression()
model.fit(X, y)
w_ = model.coef_.reshape(-1)
b_ = model.intercept_
print('二元一次方程真实的斜率和截距是:', w, b)
print('通过scikit-learn求解的斜率和截距是:', w_, b_)
# # 根据求解的斜率和截距绘制线性回归线型图
x = np.linspace(-150, 150, 100)
y = np.linspace(0, 300, 100)
z = x * w_[0] + y * w_[1] + b_
_ = ax.plot(x, y, z ,color = 'green')
2.3 线性回归预测房价
2.3.1 数据加载
首先导包:
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
我们要实现的是对 波士顿 这个国家进行房价预测,有关 波士顿 的数据,可以直接用代码:
boston = datasets.load_boston()
我们来看一下 datasets.load_boston() 里面都有哪些数据:

数据由三部分组成:
- d a t a data data 即数据,这些数据影响了房价,统计指标
- t a r g e t target target 指房价, 24 24 24 就表示 24 24 24 万美金
- f e a t u r e _ n a m e s feature\_names feature_names 就是具体的指标,比如 C R I M CRIM CRIM:犯罪率; N O X NOX NOX:空气污染, N N N元素的含量; T A X TAX TAX :税收;这些指标都会影响到房价
我们把这些信息分开来处理:
boston = datasets.load_boston()
X = boston['data'] # 数据,这些数据影响了房价,统计指标
y = boston['target'] # 房价,24就表示24万美金
# CRIM:犯罪率
# NOX:空气污染,N含量
# TAX:税收
# 这些指标都和放假有关
feature_names = boston['feature_names'] # 具体指标
2.3.2 数据查看
# 506 表示 506 个统计样本
# 13 表示影响房价的 13 个属性
X.shape

# 506 个房子
# X -----> y 是一一对应的
# 数据 -----> 目标值对应
y.shape

2.3.3 数据拆分
# 506个数据、样本
# 拆分成两份:一份 80%用于训练,一份20%用于验证
# 拿出其中的80%,交给算法(线性回归),去进行学习、总结、拟合函数
# 20%作用:验证,测一测,看看算法,学习80%结束,是否准确
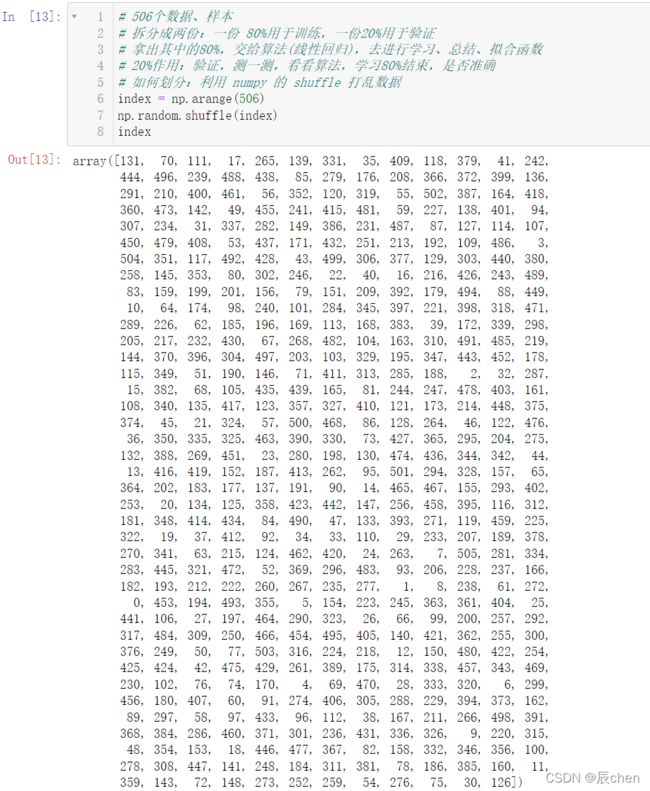
# 如何划分:利用 numpy 的 shuffle 打乱数据
index = np.arange(506)
np.random.shuffle(index)
index
506 × 80 % ≈ 405 506 \times 80\%≈405 506×80%≈405,故我们拿出打乱后的前 405 405 405 个数据用于训练算法,其余数据用于验证算法:
# 80% 训练数据
train_index = index[:405]
X_train = X[train_index]
y_train = y[train_index]
# 20% 测试数据
test_index = index[405:]
X_test = X[test_index]
y_test = y[test_index]
2.3.4 数据建模
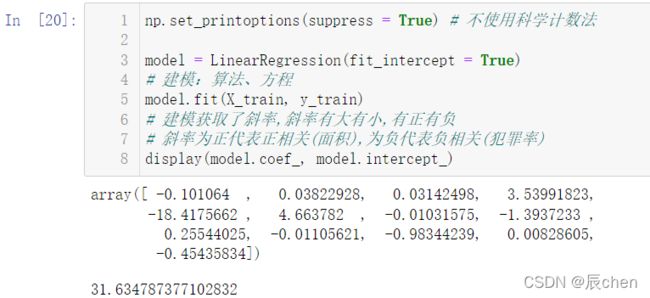
np.set_printoptions(suppress = True) # 不使用科学计数法
model = LinearRegression(fit_intercept = True)
# 建模:算法、方程
model.fit(X_train, y_train)
# 建模获取了斜率,斜率有大有小,有正有负
# 斜率为正代表正相关(面积),为负代表负相关(犯罪率)
display(model.coef_, model.intercept_)
2.3.5 模型验证
# 模型预测的结果:y_
y_ = model.predict(X_test).round(2)
# 展示前 30 个:
display(y_[:30])
# 展示真实结果的前 30 个:
display(y_test[:30])

算法的预测难免会有异常值,这是 不可避免的!
2.3.6 模型评估
# 最大值是 1,最小值可以小于 0
# 这个指标越接近 1,说明算法越优秀
model.score(X_test, y_test)

# 再来判断一下训练数据的得分
model.score(X_train, y_train)

显然,训练数据的得分是高的,这就好比我们在考试前都会做模拟题,我们如果考试卷的大部分题目都和模拟题是一样的,那么我们的分数就会高一些,如果考试的题目都是新题,那么我们的分数就会低一些
当然,我们评测数据不止这一个方法,下面简单介绍一下别的方法:
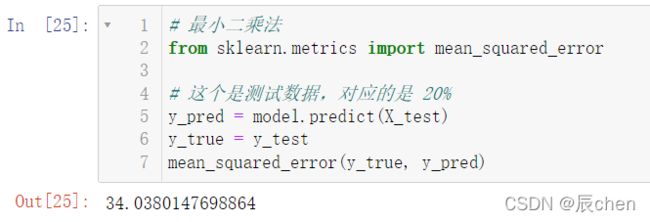
# 最小二乘法
from sklearn.metrics import mean_squared_error
# 这个是测试数据,对应的是 20%
y_pred = model.predict(X_test)
y_true = y_test
mean_squared_error(y_true, y_pred)
我们再来看那 80 % 80\% 80% 的训练数据:
# 80% 的训练数据:
mean_squared_error(y_train, model.predict(X_train))

注意我们这里的分数是 e r r o r error error,即 越小越好!