【R数据可视化手册】笔记1-条形图
【R数据可视化手册-条形图
-
-
- /data & package/
- 1/基本语法
- 2/修改参数
-
- 重排条形
- 条形的间距和宽度
- 颜色
- 3/复杂图形
-
- 簇状条形图
- Cleveland点图
- 4/待补充部分
-
/data & package/
rm(list = ls())
library(ggplot2)
library(gcookbook) ## 为使用数据
library(plyr) ## 为使用函数arrange()、ddply()、transform()数据预览

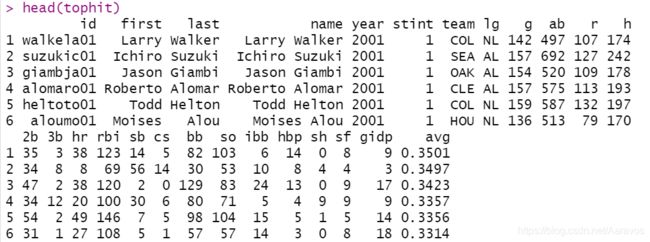
diamonds的每行数据对应一颗钻石的品质
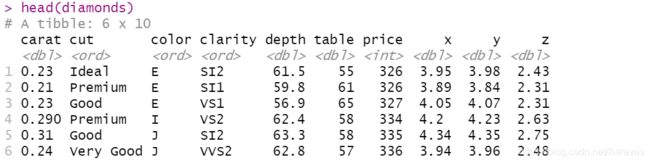
uspopchange描述美国各个州不同年份的人口变化情况
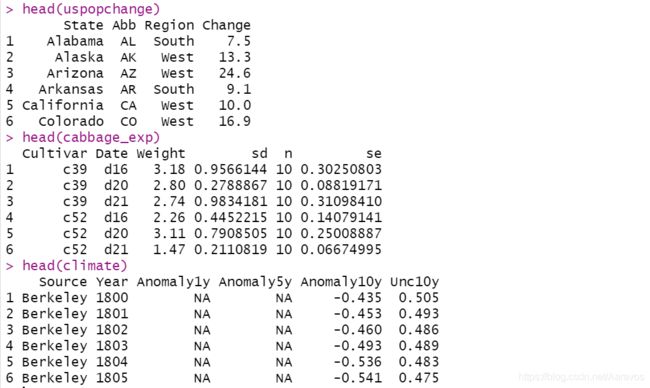
tophit中变量lg的两个取值,分别表示国家队(NL)和美国队(AL)
1/基本语法
# 真实值条形图的基本语法
ggplot(data, aes(x, y)) + geom_bar(stat = "identity")
# 向geom_bar()传递参数stat="identity"意为,y轴是对应数据的真实值
# 频数条形图的基本语法
ggplot(data, aes(x)) + geom_bar()
# 相当于向geom_bar()传递了默认值stat="bin",意为按照x的分组计算每组频数# 真实值条形图的例子
ggplot(pg_mean, aes(x = group, y = weight)) +
geom_bar(stat = "identity")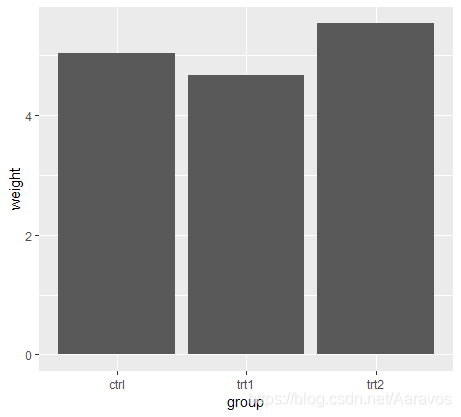
# 频数条形图的例子
ggplot(diamonds, aes(x = cut)) +
geom_bar()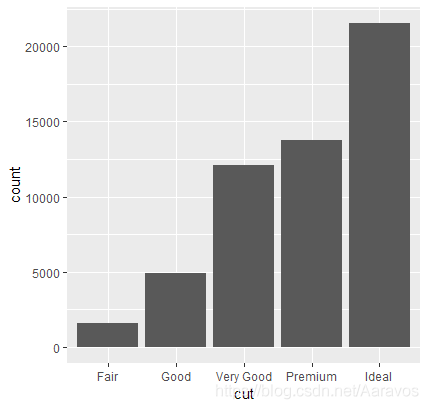
如果x对应变量为连续型变量,geom_bar()和geom_histogram()的效果类似;如果将x对应变量视为因子型,则可以使用factor()对数据进行转化;此时x轴的分类就可能不是连续的
# x轴对应因子型变量的例子
ggplot(BOD, aes(x = Time, y = demand)) +
geom_bar(stat = "identity)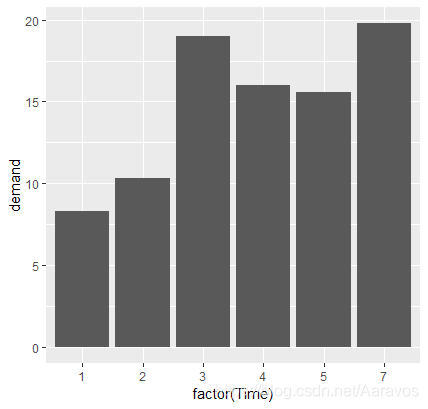
添加数据标签,需要向geom_text()传递标签的值和坐标、颜色、大小等参数;使用vjust调节y方向时,可以想像一条正方向朝下、条形顶端中心为零点的坐标轴
ggplot(cabbage_exp, aes(x = interaction(Date, Cultivar), y = Weight)) +
geom_bar(stat = "identity") +
geom_text(aes(label = Weight, y = Weight + 0.1), # 增大y轴的范围,为防止可能的标签溢出
vjust = 2, colour = "white", size = 6) # vjust调节标签的y方向位置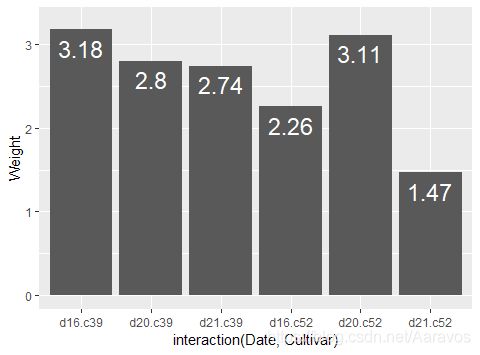
2/修改参数
重排条形
需要重新排列条形时,一般选择更改绘图数据的顺序。例如可以使用reorder()、desc()等排序函数
reorder(需要重排的变量, 排序依据的变量)
desc(向量) # 将向量元素降序排列# 重排条形的例子
upc <- subset(uspopchange, rank(Change) > 40) # 数据处理
ggplot(upc, aes(x = reorder(Abb, Change), y = Change, fill = Region)) +
geom_bar(stat = "identity", colour = "black") +
scale_fill_manual(values = c("#FF6666","#FFCC66")) +
xlab("State")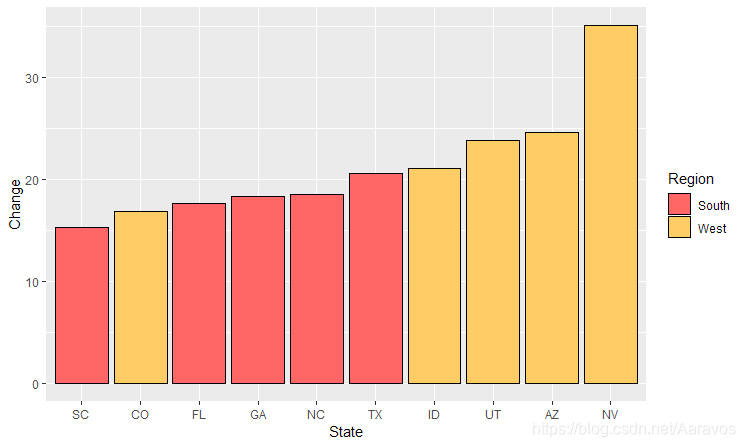
条形的间距和宽度
调节条形宽度,设置geom_bar()的参数width。width的范围是实数(0, 1),默认值width = 0.9,越大两个条形之间距离越近
# 调节条形宽度的例子
ggplot(pg_mean, aes(x = group, y = weight)) +
geom_bar(stat = "identity", width = 0.6) # 对比第一张图
颜色
R可以用数字或者英文名指定颜色。数字类型的颜色语法格式为“#XXXXXX”,X是十六进制数字;从前往后,每两位数字分别表示红、绿、蓝颜色的值;二位数字的值越大,视觉上的颜色越浅。例如#FFFFFF为白色,#000000为黑色
ggplot2的语法设置,颜色的初次映射在aes参数内,改变则在aes外进行
最简单的是调整参数fill和colour/color,fill改变填充色,colour/color改变条形边线的颜色。调色板可以使用更复杂的颜色组合。具体参见“簇状条形图”
# 改变参数fill和colour的例子
ggplot(pg_mean, aes(x = group, y= weight)) +
geom_bar(stat = "identity", fill = "lightblue", colour = "black")
对正负图形分别着色,可以新建一个二值变量,分别对应映射给y轴的变量为正/为负
# 对正负图形分别着色的例子
csub <- subset(climate, Source == "Berkeley" & Year >= 1900)
csub$pos <- csub$Anomaly10y >= 0
# ↑数据处理
ggplot(csub, aes(x = Year, y = Anomaly10y, fill = pos))+
geom_bar(stat = "identity", position = "identity")
# ↑设置position = "identity",可避免系统因对负值绘制图形报错
ggplot(csub, aes(x = Year, y = Anomaly10y, fill = pos)) +
geom_bar(stat = "identity", position = "identity", colour = "black", size = 0.25) +
scale_fill_manual(values = c("#CCEEFF", "#FFDDDD"), guide = FALSE) # 设置guide = FALSE,隐藏图例
# scale_fill_manual,对离散型x可使用自己定义的调色板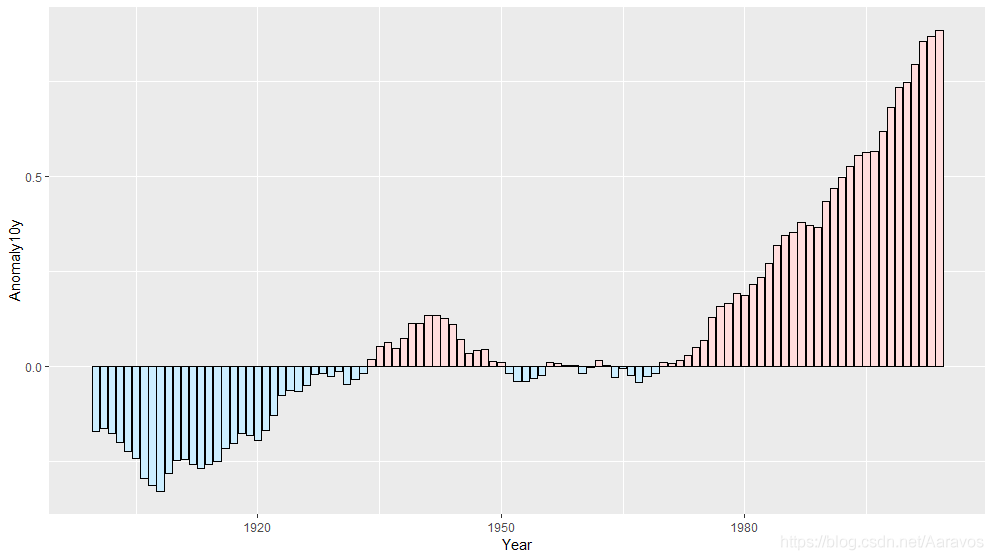
注意到图中有些条形的y轴数值差别很大,以至于一些y值接近0的条形难以分辨。因此以条形图来表示这类数据可能不是最合适的,可能可以使用”边际地毯图“(rug plot)等图形加以替代
3/复杂图形
簇状条形图
将簇的分类变量映射给fill,并向geom_bar()传递参数position = “dodge”(position = position_dodge()、参数默认为0.9的简写)
# 簇状条形图的例子
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
geom_bar(position = "dodge", stat = "identity")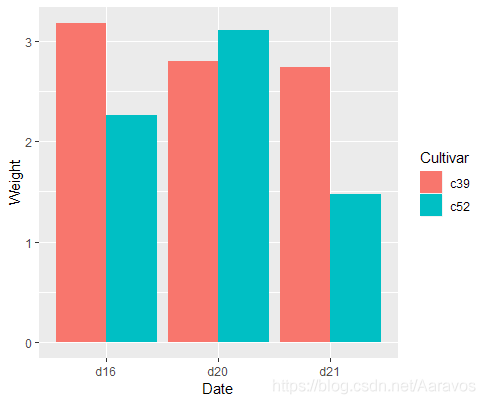
对于离散型x,向scale_fill_brewer()传递参数palette,可以直接指定RColorBrewer包中的调色板
# 调用调色板的例子
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
geom_bar(position = "dodge", stat = "identity", colour = "black") +
scale_fill_brewer(palette = "Pastel1")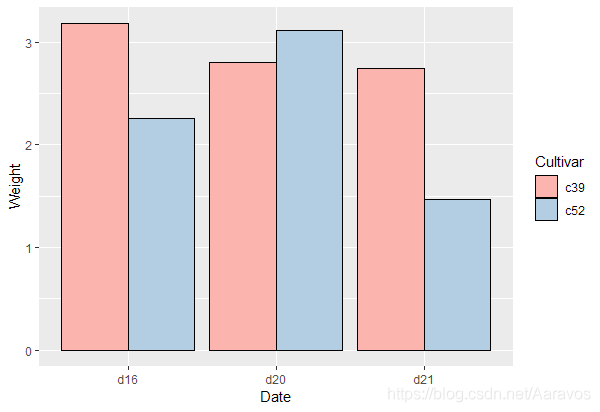 此外,加载了RColorBrewer包后,可以查看包中所有的调色板
此外,加载了RColorBrewer包后,可以查看包中所有的调色板
library(RColorBrewer)
display.brewer.all()
簇状条形图默认组内条形间距为0,通过在geom_bar()中设置width和position = position_dodge()的值以调节条形的宽度和间距;注意要使得width的值小于传递给position_dodge()的参数(可以理解为:position是每组相邻条形中心点之间的距离,width是条形的宽度)
# 调节簇状条形宽度的例子
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
geom_bar(stat = "identity", width = 0.5, position = "dodge")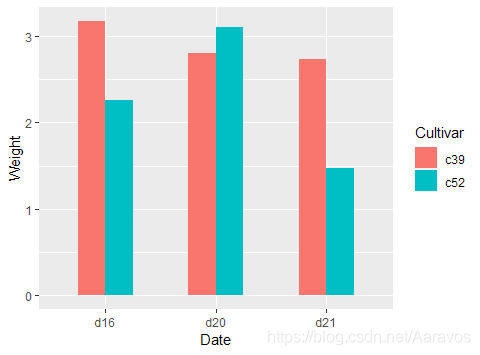
# 调整簇状条形组内间距的例子
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
geom_bar(stat = "identity", width = 0.5, position = position_dodge(0.7)) # position_dodge > width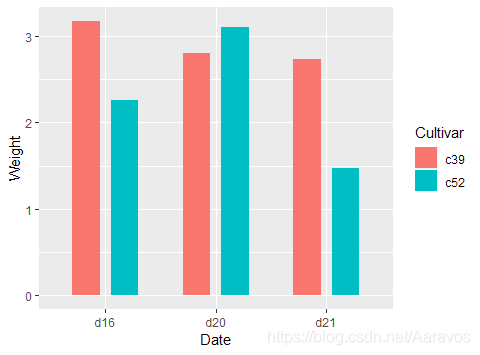
簇状条形图添加标签,需要根据已设置的条形宽度和间距,在geom_text()中设置参数position = position_dodge()的相应值
# 簇状条形图添加标签的例子
ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) +
geom_bar(stat = "identity", position = "dodge") +
geom_text(aes(label = Weight), vjust = 1.5, colour = "white",
position = position_dodge(0.9), size = 3) # 设置匹配条形的position、size
Cleveland点图
Cleveland点图是可读性更强的条形图的替代;可以直接使用geom_point()进行绘制
# Cleveland点图的基本语法
ggplolt(data, aes(x, y)) + geom_point()# Cleveland点图的例子
ggplot(tophit, aes(reorder(name, avg), y = avg)) + # 根据avg对name进行了排序
geom_point(size = 3) +
theme_bw() + # 改变主题
theme(axis.text.x = element_text(angle = 60, hjust = 1), # 旋转标签
panel.grid.major.y = element_blank(), # 删除y轴标记对应的网格线
panel.grid.minor.y = element_blank(), # 删除两个y轴标记间的网格线
panel.grid.major.x = element_line(colour = "grey60", linetype = "dashed"))
## 设置x网格线的线型、颜色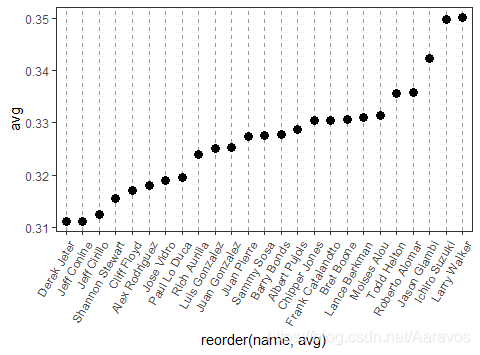
Cleveland点图更多时候以某个变量为分类变量进行绘制;下面两类Cleveland点图也称为火柴杆图
# 分类的Cleveland点图
nameorder <- tophit$name[order(tophit$lg, tophit$avg)] # 排序
tophit$name <- factor(tophit$name, levels = nameorder) # 转换为因子
ggplot(tophit, aes(x = avg, y = name)) +
geom_segment(aes(yend = name), xend = 0, colour = "grey50") +
geom_point(size = 3, aes(colour = lg)) + # 将分类变量映射给colour
theme_bw() +
theme(panel.grid.major.y = element_blank(),
legend.position = c(0.9, 0.6), # 主要调整图例的y位置
legend.justification = c(1, 0.5)) # 主要调整图例的x位置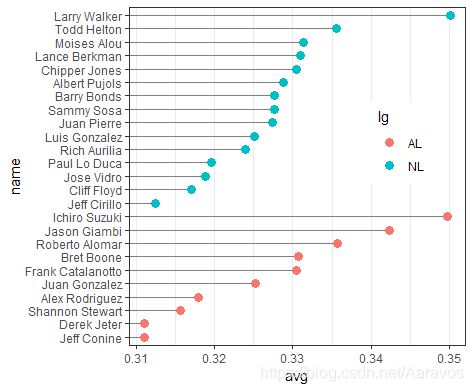
# 进一步分面的Cleveland点图
ggplot(tophit, aes(x = avg, y = name)) +
geom_segment(aes(yend = name), xend = 0, colour = "grey50") +
geom_point(size = 3, aes(colour = lg)) +
theme_bw() +
scale_colour_brewer(palette = "Set1", limits = c("NL", "AL"),
guide = FALSE) + # limits设置分面名称
theme(panel.grid.major.y = element_blank()) +
facet_grid(lg ~ ., scales = "free_y", space = "free_y") # 在y方向增加分面和名称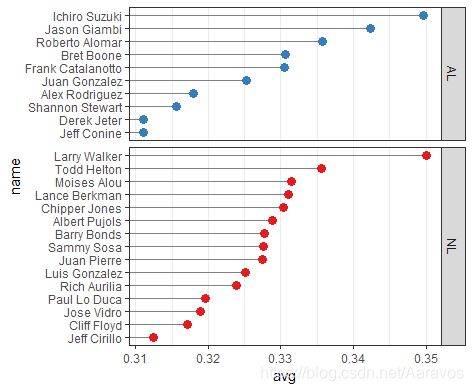
4/待补充部分
关于书中绘制堆积条形图的部分,经过尝试发现可能存在些许谬误,进一步验证后会进行补充